MariaDB ofrece capacidades integradas de fragmentación de múltiples hosts con el motor de almacenamiento Spider. Spider admite el particionamiento y las transacciones XA y permite que las tablas remotas de diferentes instancias de MariaDB se manejen como si estuvieran en la misma instancia. La tabla remota puede ser de cualquier motor de almacenamiento. El enlace de la tabla se logra mediante el establecimiento de la conexión desde un servidor MariaDB local a un servidor MariaDB remoto, y el enlace se comparte para todas las tablas que forman parte de la misma transacción.
En esta publicación de blog, lo guiaremos a través de la implementación de un clúster de dos fragmentos de MariaDB mediante ClusterControl. Vamos a implementar un puñado de servidores MariaDB (para redundancia y disponibilidad) para alojar una tabla particionada basada en un rango de una clave de fragmento seleccionada. La clave de fragmento elegida es básicamente una columna que almacena valores con un límite inferior y superior, como en este caso, valores enteros entre 0 y 1 000 000, lo que la convierte en la mejor clave candidata para equilibrar la distribución de datos entre dos fragmentos. Por lo tanto, dividiremos los rangos en dos particiones:
-
0 - 499999:Fragmento 1
-
500000 - 1000000:Fragmento 2
El siguiente diagrama ilustra nuestra arquitectura de alto nivel de lo que vamos a implementar:
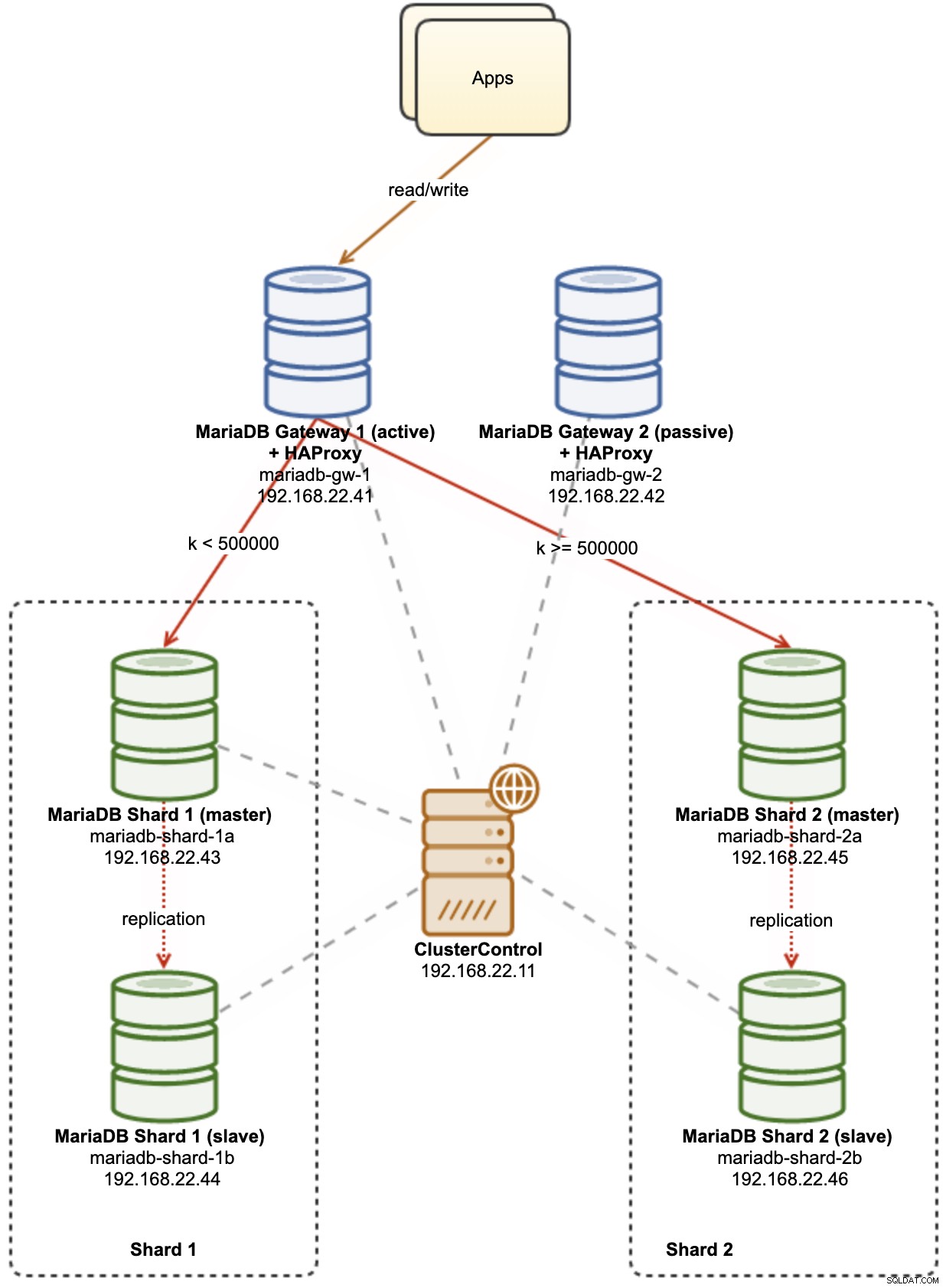
Algunas explicaciones del diagrama:
-
mariadb-gw-1:instancia de MariaDB que ejecuta el motor de almacenamiento Spider, actúa como un enrutador de fragmentos. Damos un nombre a este host como MariaDB Gateway 1 y este será el servidor principal (activo) de MariaDB para llegar a los fragmentos. La aplicación se conectará a este host como una conexión MariaDB estándar. Este nodo se conecta a los fragmentos a través de HAProxy escuchando en los puertos 127.0.0.1 3307 (fragmento 1) y 3308 (fragmento 2).
-
mariadb-gw-2:instancia de MariaDB que ejecuta el motor de almacenamiento Spider, actúa como un enrutador de fragmentos. Damos un nombre a este host como MariaDB Gateway 2 y este será el servidor MariaDB secundario (pasivo) para llegar a los fragmentos. Tendrá la misma configuración que mariadb-gw-1. La aplicación se conectará a este host solo si el MariaDB principal está inactivo. Este nodo se conecta a los fragmentos a través de HAProxy escuchando en los puertos 127.0.0.1 3307 (fragmento 1) y 3308 (fragmento 2).
-
mariadb-shard-1a:maestro de MariaDB que sirve como nodo de datos principal para la primera partición. Los servidores de puerta de enlace de MariaDB solo deben escribir en el maestro del fragmento.
-
mariadb-shard-1b:Réplica de MariaDB que sirve como nodo de datos secundario para la primera partición. Asumirá la función de maestro en caso de que el maestro del fragmento se caiga (la conmutación por error automática es administrada por ClusterControl).
-
mariadb-shard-2a:maestro de MariaDB que sirve como nodo de datos principal para la segunda partición. Los servidores de puerta de enlace de MariaDB solo escriben en el maestro del fragmento.
-
mariadb-shard-2b:Réplica de MariaDB que sirve como nodo de datos secundario para la segunda partición. Asumirá la función de maestro en caso de que el maestro del fragmento se caiga (la conmutación por error automática es administrada por ClusterControl).
-
ClusterControl:una herramienta centralizada de implementación, administración y monitoreo para nuestros fragmentos/clústeres de MariaDB.
Implementación de clústeres de bases de datos mediante ClusterControl
ClusterControl es una herramienta de automatización para administrar el ciclo de vida de su sistema de administración de bases de datos de código abierto. Vamos a utilizar ClusterControl como una herramienta centralizada para implementaciones de clústeres, administración de topologías y monitoreo para el propósito de esta publicación de blog.
1) Instale ClusterControl.
2) Configure el SSH sin contraseña del servidor ClusterControl a todos los nodos de la base de datos. En el nodo ClusterControl:
(clustercontrol)$ whoami
root
$ ssh-keygen -t rsa
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com3) Dado que vamos a implementar 4 conjuntos de clústeres, es una buena idea usar la herramienta CLI de ClusterControl para esta tarea en particular para agilizar y simplificar el proceso de implementación. Primero verifiquemos si podemos conectarnos con las credenciales predeterminadas ejecutando el siguiente comando (la credencial predeterminada se configura automáticamente en /etc/s9s.conf):
(clustercontrol)$ s9s cluster --list --long
Total: 0Si no recibimos ningún error y vemos un resultado similar al anterior, podemos continuar.
4) Tenga en cuenta que los pasos 4, 5, 6 y 7 se pueden ejecutar a la vez, ya que ClusterControl admite la implementación en paralelo. Comenzaremos implementando el primer servidor MariaDB Gateway usando ClusterControl CLI:
(clustercontrol)$ s9s cluster --create \
--cluster-type=mysqlreplication \
--nodes="192.168.22.101?master" \
--vendor=mariadb \
--provider-version=10.5 \
--os-user=root \
--os-key-file=/root/.ssh/id_rsa \
--db-admin="root" \
--db-admin-passwd="SuperS3cr3tPassw0rd" \
--cluster-name="MariaDB Gateway 1"5) Implementar el segundo servidor de MariaDB Gateway:
(clustercontrol)$ s9s cluster --create \
--cluster-type=mysqlreplication \
--nodes="192.168.22.102?master" \
--vendor=mariadb \
--provider-version=10.5 \
--os-user=root \
--os-key-file=/root/.ssh/id_rsa \
--db-admin="root" \
--db-admin-passwd="SuperS3cr3tPassw0rd" \
--cluster-name="MariaDB Gateway 2"6) Implemente una replicación MariaDB de 2 nodos para el primer fragmento:
(clustercontrol)$ s9s cluster --create \
--cluster-type=mysqlreplication \
--nodes="192.168.22.111?master;192.168.22.112?slave" \
--vendor=mariadb \
--provider-version=10.5 \
--os-user=root \
--os-key-file=/root/.ssh/id_rsa \
--db-admin="root" \
--db-admin-passwd="SuperS3cr3tPassw0rd" \
--cluster-name="MariaDB - Shard 1"7) Implemente una replicación de MariaDB de 2 nodos para el segundo fragmento:
(clustercontrol)$ s9s cluster --create \
--cluster-type=mysqlreplication \
--nodes="192.168.22.121?master;192.168.22.122?slave" \
--vendor=mariadb \
--provider-version=10.5 \
--os-user=root \
--os-key-file=/root/.ssh/id_rsa \
--db-admin="root" \
--db-admin-passwd="SuperS3cr3tPassw0rd" \
--cluster-name="MariaDB - Shard 2"Mientras la implementación está en curso, podemos monitorear la salida del trabajo desde CLI:
(clustercontrol)$ s9s job --list --show-running
ID CID STATE OWNER GROUP CREATED RDY TITLE
25 0 RUNNING admin admins 07:19:28 45% Create MySQL Replication Cluster
26 0 RUNNING admin admins 07:19:38 45% Create MySQL Replication Cluster
27 0 RUNNING admin admins 07:20:06 30% Create MySQL Replication Cluster
28 0 RUNNING admin admins 07:20:14 30% Create MySQL Replication ClusterY también desde la interfaz de usuario de ClusterControl:
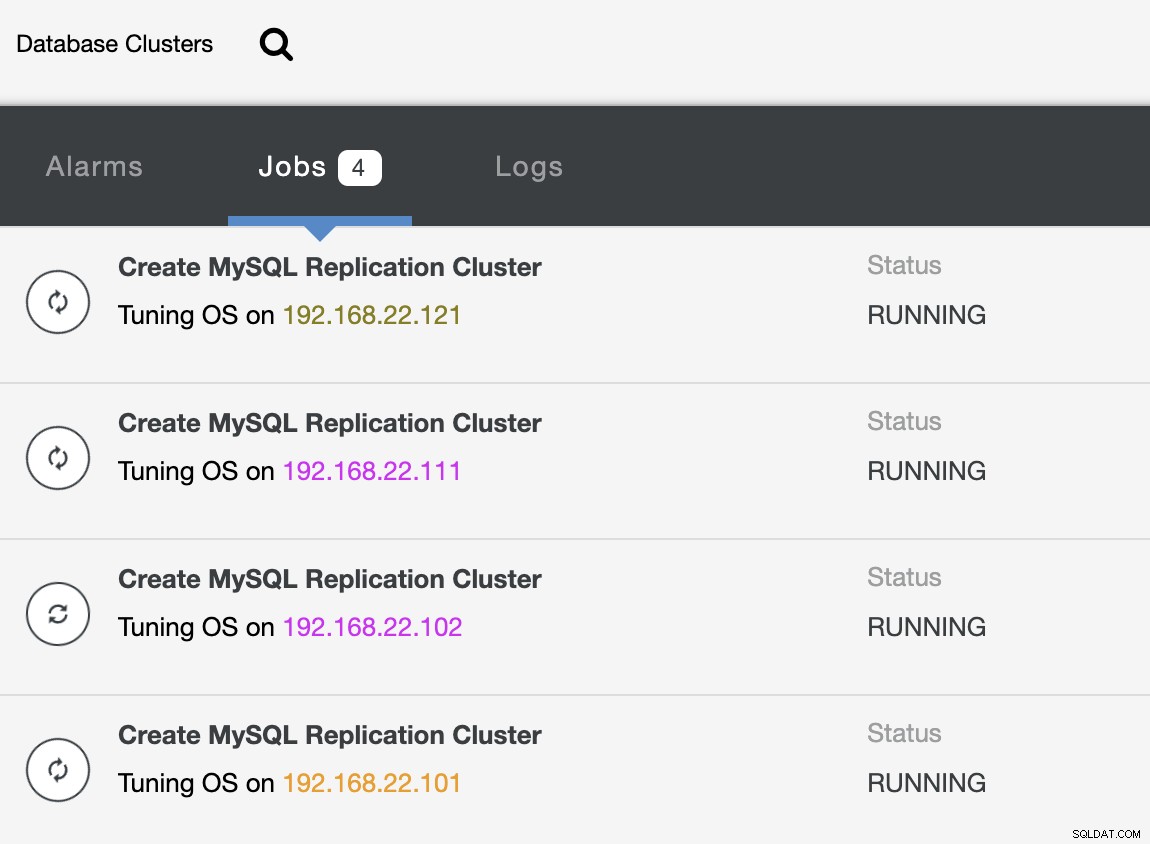
Una vez que se complete la implementación, debería ver algo que enumera los clústeres de bases de datos así en el panel de control de ClusterControl:
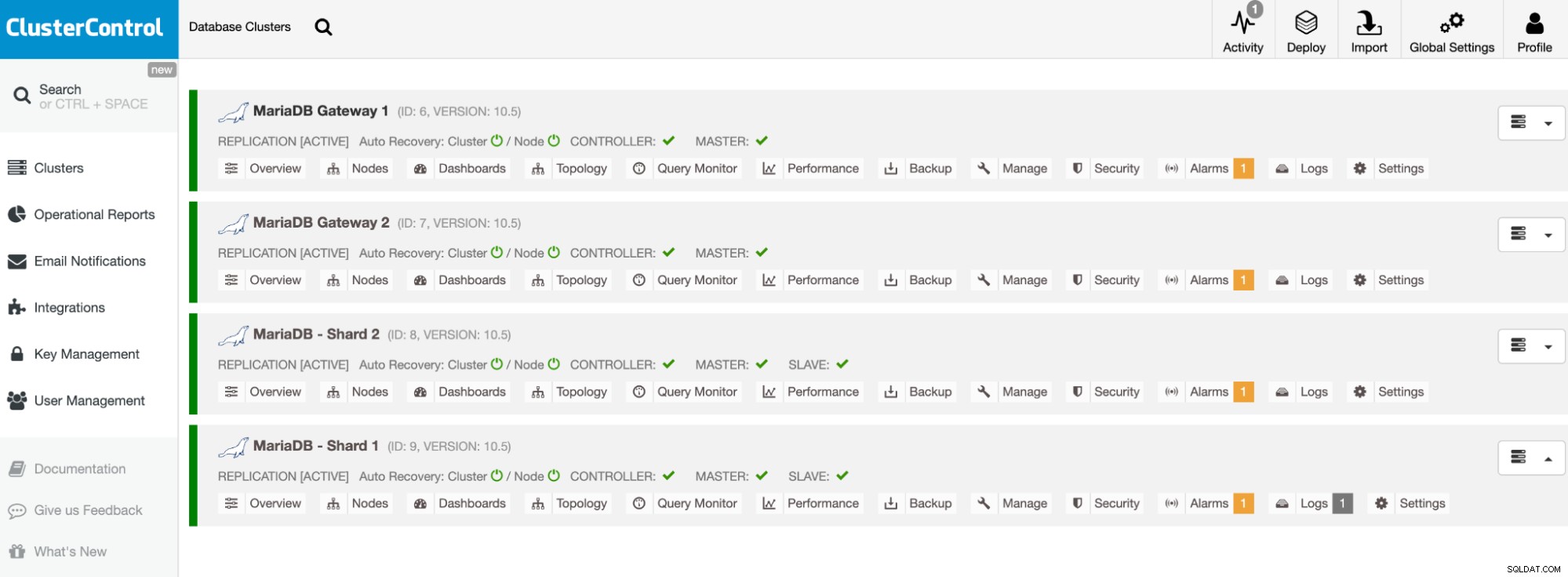
Nuestros clústeres ahora están implementados y ejecutan la última versión de MariaDB 10.5. A continuación, debemos configurar HAProxy para proporcionar un punto final único a los fragmentos de MariaDB.
Configurar HAProxy
HAProxy es necesario como punto final único para la replicación maestro-esclavo del fragmento. De lo contrario, si un maestro se cae, uno tiene que actualizar la lista de servidores de Spider usando la declaración CREAR O REEMPLAZAR SERVIDOR en los servidores de puerta de enlace, y realizar ALTER TABLE y pasar un nuevo parámetro de conexión. Con HAProxy, podemos configurarlo para escuchar en el host local del servidor de puerta de enlace y monitorear diferentes fragmentos de MariaDB con diferentes puertos. Configuraremos HAProxy en ambos servidores de puerta de enlace de la siguiente manera:
-
127.0.0.1:3307 -> Shard1 (los servidores backend son mariadb-shard-1a y mariadb-shard- 1b)
-
127.0.0.1:3308 -> Shard2 (los servidores backend son mariadb-shard-2a y mariadb-shard- 2b)
En caso de que el maestro del fragmento se caiga, ClusterControl conmutará por error el esclavo del fragmento como el nuevo maestro y HAProxy redirigirá las conexiones al nuevo maestro en consecuencia. Vamos a instalar HAProxy en los servidores de puerta de enlace (mariadb-gw-1 y mariadb-gw-2) usando ClusterControl, ya que configurará automáticamente los servidores backend (configuración de mysqlchk, permisos de usuario, instalación de xinetd) con algunos trucos como se muestra a continuación.
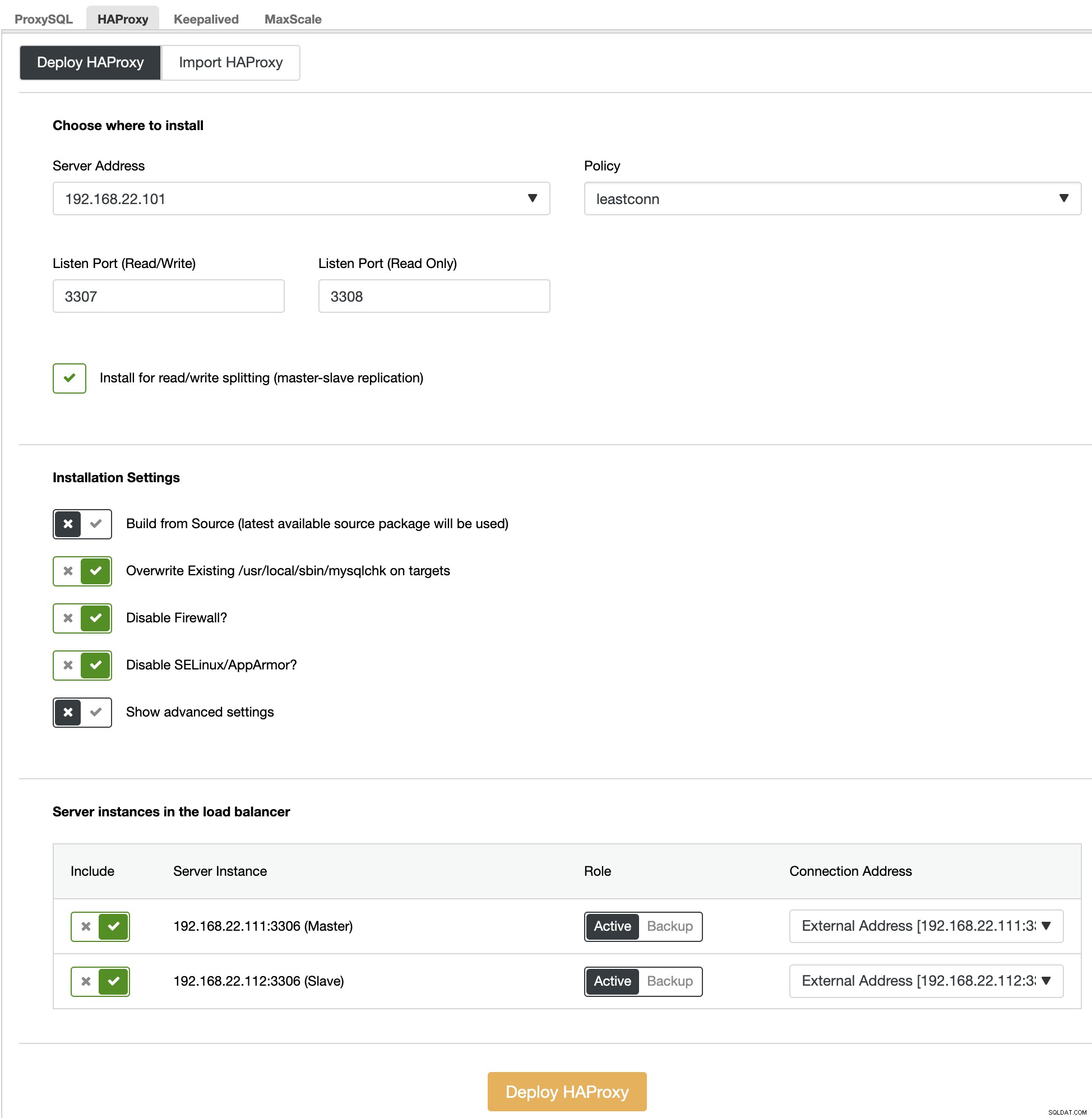
En primer lugar, en la interfaz de usuario de ClusterControl, elija el primer fragmento, MariaDB - Fragmento 1 -> Administrar -> Equilibradores de carga -> HAProxy -> Implementar HAProxy y especifique la dirección del servidor como 192.168.22.101 ( mariadb-gw-1), similar a la siguiente captura de pantalla:
Del mismo modo, pero este para el fragmento 2, vaya a MariaDB - Fragmento 2 -> Administrar -> Equilibradores de carga -> HAProxy -> Implementar HAProxy y especificar la dirección del servidor como 192.168.22.102 (mariadb-gw-2). Espere hasta que finalice la implementación para ambos nodos HAProxy.
Ahora necesitamos configurar el servicio HAProxy en mariadb-gw-1 y mariadb-gw-2 para equilibrar la carga de todos los fragmentos a la vez. Usando el editor de texto (o la interfaz de usuario de ClusterControl -> Administrar -> Configuraciones), edite las últimas 2 directivas de "escucha" de /etc/haproxy/haproxy.cfg para que se vean así:
listen haproxy_3307_shard1
bind *:3307
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check connect port 9200
tcp-check expect string master\ is\ running
balance leastconn
option tcp-check
default-server port 9200 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 192.168.22.111 192.168.22.111:3306 check # mariadb-shard-1a-master
server 192.168.22.112 192.168.22.112:3306 check # mariadb-shard-1b-slave
listen haproxy_3308_shard2
bind *:3308
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check connect port 9200
tcp-check expect string master\ is\ running
balance leastconn
option tcp-check
default-server port 9200 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 192.168.22.121 192.168.22.121:3306 check # mariadb-shard-2a-master
server 192.168.22.122 192.168.22.122:3306 check # mariadb-shard-2b-slaveReinicie el servicio HAProxy para cargar los cambios (o use ClusterControl -> Nodos -> HAProxy -> Reiniciar nodo):
$ systemctl restart haproxyDesde la interfaz de usuario de ClusterControl, podemos verificar que solo un servidor backend está activo por fragmento (indicado por las líneas verdes), como se muestra a continuación:
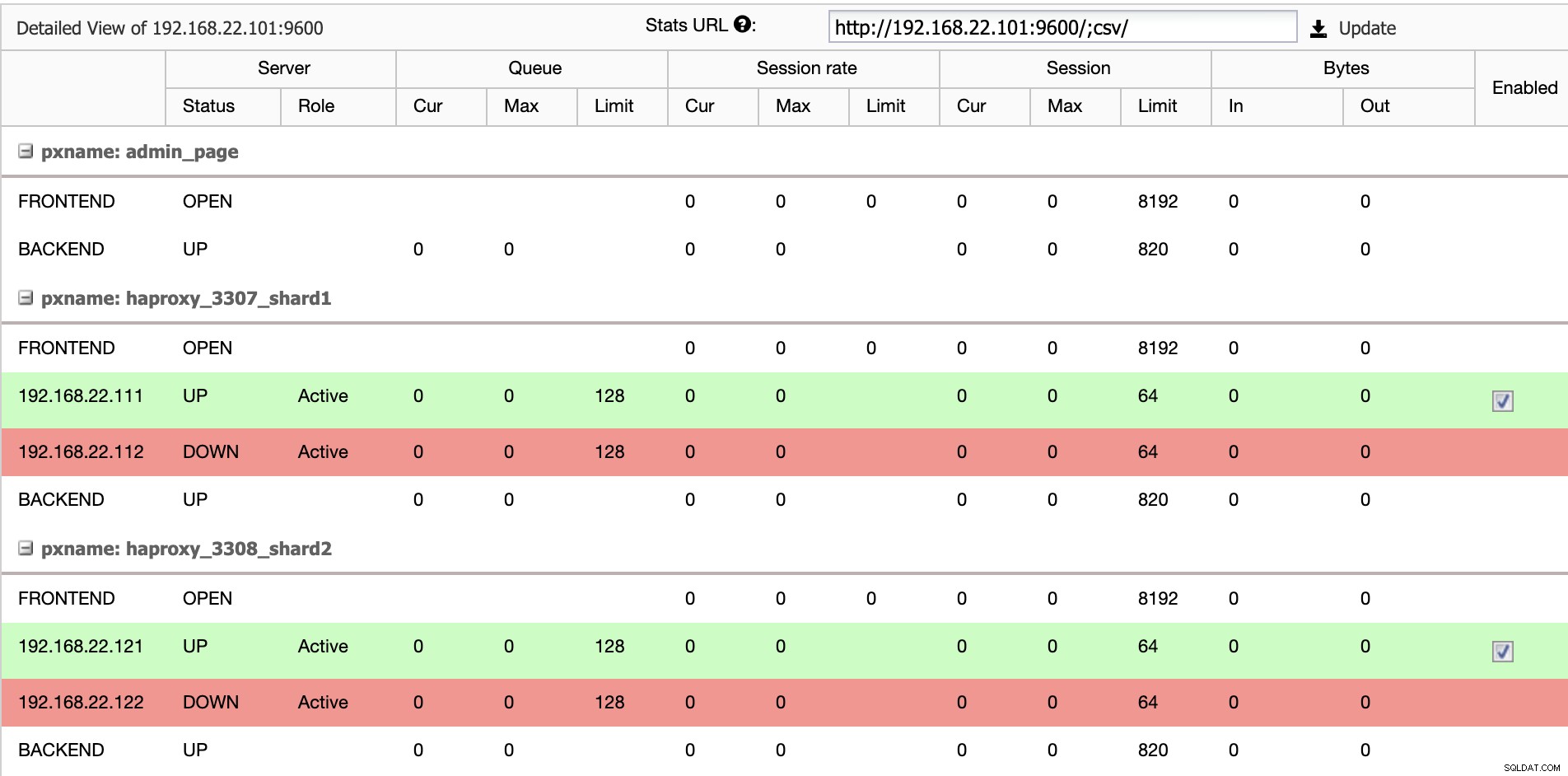
En este punto, la implementación de nuestro clúster de base de datos ya está completa. Podemos proceder a configurar el sharding de MariaDB utilizando el motor de almacenamiento Spider.
Preparación de servidores de puerta de enlace MariaDB
En ambos servidores MariaDB Gateway (mariadb-gw-1 y mariadb-gw-2), realice las siguientes tareas:
Instalar el complemento Spider:
MariaDB> INSTALL PLUGIN spider SONAME 'ha_spider.so';Verifique si el motor de almacenamiento es compatible:
MariaDB> SELECT engine,support FROM information_schema.engines WHERE engine = 'spider';
+--------+---------+
| engine | support |
+--------+---------+
| SPIDER | YES |
+--------+---------+Opcionalmente, también podemos verificar si el complemento se carga correctamente desde la base de datos information_schema:
MariaDB> SELECT PLUGIN_NAME,PLUGIN_VERSION,PLUGIN_STATUS,PLUGIN_TYPE FROM information_schema.plugins WHERE plugin_name LIKE 'SPIDER%';
+--------------------------+----------------+---------------+--------------------+
| PLUGIN_NAME | PLUGIN_VERSION | PLUGIN_STATUS | PLUGIN_TYPE |
+--------------------------+----------------+---------------+--------------------+
| SPIDER | 3.3 | ACTIVE | STORAGE ENGINE |
| SPIDER_ALLOC_MEM | 1.0 | ACTIVE | INFORMATION SCHEMA |
| SPIDER_WRAPPER_PROTOCOLS | 1.0 | ACTIVE | INFORMATION SCHEMA |
+--------------------------+----------------+---------------+--------------------+Agregue la siguiente línea debajo de la sección [mysqld] dentro del archivo de configuración de MariaDB:
plugin-load-add = ha_spiderCree el primer "nodo de datos" para el primer fragmento al que debería poder accederse a través de HAProxy 127.0.0.1 en el puerto 3307:
MariaDB> CREATE OR REPLACE SERVER Shard1
FOREIGN DATA WRAPPER mysql
OPTIONS (
HOST '127.0.0.1',
DATABASE 'sbtest',
USER 'spider',
PASSWORD 'SpiderP455',
PORT 3307);Cree el segundo "nodo de datos" para el segundo fragmento al que debería poder accederse a través de HAProxy 127.0.0.1 en el puerto 3308:
CREATE OR REPLACE SERVER Shard2
FOREIGN DATA WRAPPER mysql
OPTIONS (
HOST '127.0.0.1',
DATABASE 'sbtest',
USER 'spider',
PASSWORD 'SpiderP455',
PORT 3308);Ahora podemos crear una tabla Spider que necesita ser dividida. En este ejemplo, vamos a crear una tabla llamada sbtest1 dentro de la base de datos sbtest y particionada por el valor entero en la columna 'k':
MariaDB> CREATE SCHEMA sbtest;
MariaDB> CREATE TABLE sbtest.sbtest1 (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`, `k`)
)
ENGINE=Spider
COMMENT 'wrapper "mysql", table "sbtest1"'
PARTITION BY RANGE (k) (
PARTITION shard1 VALUES LESS THAN (499999) COMMENT = 'srv "Shard1"',
PARTITION shard2 VALUES LESS THAN MAXVALUE COMMENT = 'srv "Shard2"'
);Tenga en cuenta que las cláusulas COMMENT ='srv "ShardX"' de la declaración CREATE TABLE son críticas, donde pasamos información de conexión sobre el servidor remoto. El valor debe ser idéntico al nombre del servidor como en la sentencia CREATE SERVER. Vamos a llenar esta tabla usando el generador de carga Sysbench como se muestra más abajo.
Cree el usuario de la base de datos de la aplicación para acceder a la base de datos y permitirlo desde los servidores de la aplicación:
MariaDB> CREATE USER example@sqldat.com'192.168.22.%' IDENTIFIED BY 'passw0rd';
MariaDB> GRANT ALL PRIVILEGES ON sbtest.* TO example@sqldat.com'192.168.22.%';En este ejemplo, dado que esta es una red interna confiable, solo usamos un comodín en la declaración para permitir cualquier dirección IP en el mismo rango, 192.168.22.0/24.
Ahora estamos listos para configurar nuestros nodos de datos.
Preparación de servidores Shard de MariaDB
En ambos servidores maestros MariaDB Shard (mariadb-shard-1a y mariadb-shard-2a), realice las siguientes tareas:
1) Crear la base de datos de destino:
MariaDB> CREATE SCHEMA sbtest;2) Cree el usuario 'spider' y permita las conexiones desde los servidores de puerta de enlace (mariadb-gw-1 y mariadb-gw2). Este usuario debe tener todos los privilegios en la tabla fragmentada y también en la base de datos del sistema MySQL:
MariaDB> CREATE USER 'spider'@'192.168.22.%' IDENTIFIED BY 'SpiderP455';
MariaDB> GRANT ALL PRIVILEGES ON sbtest.* TO example@sqldat.com'192.168.22.%';
MariaDB> GRANT ALL ON mysql.* TO example@sqldat.com'192.168.22.%';En este ejemplo, dado que esta es una red interna confiable, solo usamos un comodín en la declaración para permitir cualquier dirección IP en el mismo rango, 192.168.22.0/24.
3) Cree la tabla que va a recibir los datos de nuestros servidores de puerta de enlace a través del motor de almacenamiento Spider. Esta tabla "receptora" puede estar en cualquier motor de almacenamiento compatible con MariaDB. En este ejemplo, usamos el motor de almacenamiento InnoDB:
MariaDB> CREATE TABLE sbtest.sbtest1 (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`, `k`)
) ENGINE = INNODB;Eso es todo. No olvides repetir los pasos en el otro fragmento.
Pruebas
Para probar el uso de Sysbench para generar algunas cargas de trabajo de base de datos, en el servidor de aplicaciones, tenemos que instalar Sysbench de antemano:
$ yum install -y https://repo.percona.com/yum/percona-release-latest.noarch.rpm
$ yum install -y sysbenchGenerar algunas cargas de trabajo de prueba y enviarlas al primer servidor de puerta de enlace, mariadb-gw-1 (192.168.11.101):
$ sysbench \
/usr/share/sysbench/oltp_insert.lua \
--report-interval=2 \
--threads=4 \
--rate=20 \
--time=9999 \
--db-driver=mysql \
--mysql-host=192.168.11.101 \
--mysql-port=3306 \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=passw0rd \
--tables=1 \
--table-size=1000000 \
runPuede repetir la prueba anterior en mariadb-gw-2 (192.168.11.102) y las conexiones de la base de datos deben enrutarse al fragmento correcto en consecuencia.
Al mirar el primer fragmento (mariadb-shard-1a o mariadb-shard-1b), podemos decir que esta partición solo contiene filas donde la clave del fragmento (columna k) es menor que 500000:
MariaDB [sbtest]> SELECT MIN(k),MAX(k) FROM sbtest1;
+--------+--------+
| min(k) | max(k) |
+--------+--------+
| 200175 | 499963 |
+--------+--------+En otro fragmento (mariadb-shard-2a o mariadb-shard-2b), contiene datos desde 500000 hasta 999999 como se esperaba:
MariaDB [sbtest]> SELECT MIN(k),MAX(k) FROM sbtest1;
+--------+--------+
| min(k) | max(k) |
+--------+--------+
| 500067 | 999948 |
+--------+--------+Mientras que para el servidor MariaDB Gateway (mariadb-gw-1 o mariadb-gw-2), podemos ver todas las filas similares a si la tabla existe dentro de esta instancia de MariaDB:
MariaDB [sbtest]> SELECT MIN(k),MAX(k) FROM sbtest1;
+--------+--------+
| min(k) | max(k) |
+--------+--------+
| 200175 | 999948 |
+--------+--------+Para probar el aspecto de alta disponibilidad, cuando un maestro de fragmento no está disponible, por ejemplo, cuando el maestro (mariadb-shard-2a) del fragmento 2 deja de funcionar, ClusterControl realizará automáticamente la promoción de esclavo en el esclavo (mariadb-shard-2b) para ser un amo. Durante este período, probablemente podría ver este error:
ERROR 1429 (HY000) at line 1: Unable to connect to foreign data source: Shard2Y aunque no esté disponible, obtendrá el siguiente error posterior:
ERROR 1158 (08S01) at line 1: Got an error reading communication packetsEn nuestra medición, la conmutación por error tomó alrededor de 23 segundos después de que comenzó y una vez que se promueve el nuevo maestro, debería poder escribir en la tabla desde el servidor de la puerta de enlace como de costumbre.
Conclusión
La configuración anterior es una prueba de principio sobre cómo se puede usar ClusterControl para implementar una configuración fragmentada de MariaDB. También puede mejorar la disponibilidad del servicio de una configuración de fragmentación de MariaDB con su función de recuperación automática de nodos y clústeres, además de todas las funciones de supervisión y administración estándar de la industria para respaldar su infraestructura de base de datos general.