La ejecución de bases de datos en la infraestructura de la nube se está volviendo cada vez más popular en estos días. Aunque una máquina virtual en la nube puede no ser tan confiable como un servidor de nivel empresarial, los principales proveedores de la nube ofrecen una variedad de herramientas para aumentar la disponibilidad del servicio. En esta publicación de blog, le mostraremos cómo diseñar su base de datos MySQL o MariaDB para alta disponibilidad, en la nube. Analizaremos específicamente Amazon Web Services y Google Cloud Platform, pero la mayoría de los consejos también se pueden usar con otros proveedores de la nube.
Tanto AWS como Google ofrecen servicios de bases de datos en sus nubes, y estos servicios se pueden configurar para alta disponibilidad. Es posible tener copias en diferentes zonas de disponibilidad (o zonas en GCP) para aumentar sus posibilidades de sobrevivir a una falla parcial de los servicios dentro de una región. Aunque un servicio alojado es una forma muy conveniente de ejecutar una base de datos, tenga en cuenta que el servicio está diseñado para comportarse de una manera específica y que puede o no cumplir con sus requisitos. Entonces, por ejemplo, AWS RDS for MySQL tiene una lista bastante limitada de opciones en lo que respecta al manejo de la conmutación por error. Las implementaciones Multi-AZ vienen con un tiempo de conmutación por error de 60 a 120 segundos según la documentación. De hecho, dado que la instancia de MySQL "en la sombra" tiene que comenzar a partir de un conjunto de datos "corrupto", esto puede demorar aún más, ya que podría requerirse más trabajo para aplicar o revertir las transacciones de los registros de rehacer de InnoDB. Hay una opción para promover un esclavo para que se convierta en maestro, pero no es factible ya que no puede volver a esclavizar a los esclavos existentes del nuevo maestro. En el caso de un servicio administrado, también es intrínsecamente más complejo y más difícil rastrear los problemas de rendimiento. Más información sobre RDS para MySQL y sus limitaciones en esta publicación de blog.
Por otro lado, si decides administrar las bases de datos, estás en un mundo diferente de posibilidades. Una serie de cosas que puede hacer en bare metal también son posibles en instancias de EC2 o Compute Engine. No tiene la sobrecarga de administrar el hardware subyacente y, sin embargo, conserva el control sobre cómo diseñar el sistema. Hay dos opciones principales al diseñar para la disponibilidad de MySQL:replicación de MySQL y Galera Cluster. Discutámoslos.
Replicación MySQL
La replicación de MySQL es una forma común de escalar MySQL con múltiples copias de los datos. Asíncrono o semisincrónico, permite propagar cambios ejecutados en un solo escritor, el maestro, a réplicas/esclavos, cada uno de los cuales contendría el conjunto de datos completo y puede promoverse para convertirse en el nuevo maestro. La replicación también se puede usar para escalar las lecturas, dirigiendo el tráfico de lectura a las réplicas y descargando el maestro de esta manera. La principal ventaja de la replicación es la facilidad de uso:es tan conocida y popular (también es fácil de configurar) que existen numerosos recursos y herramientas para ayudarlo a administrarla y configurarla. Nuestro propio ClusterControl es uno de ellos:puede usarlo para implementar fácilmente una configuración de replicación de MySQL con balanceadores de carga integrados, administrar cambios de topología, conmutación por error/recuperación, etc.
Un problema importante con la replicación de MySQL es que no está diseñado para manejar divisiones de red o fallas del maestro. Si un maestro deja de funcionar, debe promocionar una de las réplicas. Este es un proceso manual, aunque se puede automatizar con herramientas externas (por ejemplo, ClusterControl). Tampoco hay un mecanismo de quórum y no hay soporte para cercar instancias maestras fallidas en la replicación de MySQL. Desafortunadamente, esto puede generar problemas graves en entornos distribuidos:si promocionó un nuevo maestro mientras el anterior vuelve a estar en línea, puede terminar escribiendo en dos nodos, creando una deriva de datos y causando problemas graves de coherencia de datos.
Veremos algunos ejemplos más adelante en esta publicación, que le muestran cómo detectar divisiones de red e implementar STONITH o algún otro mecanismo de cercado para su configuración de replicación de MySQL.
Clúster Galera
Vimos en la sección anterior que la replicación de MySQL carece de vallado y soporte de quórum:aquí es donde brilla Galera Cluster. Tiene un soporte de quórum incorporado, también tiene un mecanismo de vallado que evita que los nodos particionados acepten escrituras. Esto hace que Galera Cluster sea más adecuado que la replicación en configuraciones de varios centros de datos. Galera Cluster también admite múltiples escritores y puede resolver conflictos de escritura. Por lo tanto, no está limitado a un solo escritor en una configuración de varios centros de datos, es posible tener un escritor en cada centro de datos, lo que reduce la latencia entre su aplicación y el nivel de la base de datos. No acelera las escrituras, ya que cada escritura aún debe enviarse a cada nodo de Galera para la certificación, pero aún es más fácil que enviar escrituras desde todos los servidores de aplicaciones a través de WAN a un solo maestro remoto.
A pesar de lo bueno que es Galera, no siempre es la mejor opción para todas las cargas de trabajo. Galera no es un reemplazo directo para MySQL/InnoDB. Comparte características comunes con MySQL "normal":utiliza InnoDB como motor de almacenamiento, contiene el conjunto de datos completo en cada nodo, lo que hace que JOIN sea factible. Aún así, algunas de las características de rendimiento de Galera (como el rendimiento de las escrituras que se ven afectadas por la latencia de la red) difieren de lo que esperaría de las configuraciones de replicación. El mantenimiento también se ve diferente:el manejo de cambios de esquema funciona ligeramente diferente. Algunos diseños de esquema no son óptimos:si tiene puntos de acceso en sus tablas, como contadores que se actualizan con frecuencia, esto puede generar problemas de rendimiento. También hay una diferencia en las mejores prácticas relacionadas con el procesamiento por lotes:en lugar de ejecutar consultas en transacciones grandes, desea que sus transacciones sean pequeñas.
Nivel de proxy
Es muy difícil y engorroso crear una configuración de alta disponibilidad sin proxies. Claro, puede escribir código en su aplicación para realizar un seguimiento de las instancias de la base de datos, incluir en la lista negra las que no están en buen estado, realizar un seguimiento de los maestros que se pueden escribir, etc. Pero esto es mucho más complejo que simplemente enviar tráfico a un solo punto final, que es donde entra en juego un proxy. ClusterControl le permite implementar ProxySQL, HAProxy y MaxScale. Daremos algunos ejemplos utilizando ProxySQL, ya que nos brinda una buena flexibilidad para controlar el tráfico de la base de datos.
ProxySQL se puede implementar de un par de formas. Para empezar, se puede implementar en hosts separados y Keepalived se puede usar para proporcionar una IP virtual. La IP virtual se moverá en caso de que falle una de las instancias de ProxySQL. En la nube, esta configuración puede ser problemática ya que agregar una IP a la interfaz generalmente no es suficiente. Tendría que modificar la configuración y los scripts de Keepalived para que funcionen con IP elástica (o estática, como sea que lo llame su proveedor de nube). Luego, uno usaría la API o CLI de la nube para reubicar esta dirección IP en otro host. Por esta razón, sugerimos colocar ProxySQL con la aplicación. Cada servidor de aplicaciones estaría configurado para conectarse al ProxySQL local, usando sockets Unix. Como ProxySQL utiliza un proceso ángel, los bloqueos de ProxySQL se pueden detectar/reiniciar en un segundo. En caso de falla del hardware, ese servidor de aplicaciones en particular dejará de funcionar junto con ProxySQL. Los servidores de aplicaciones restantes aún pueden acceder a sus respectivas instancias locales de ProxySQL. Esta configuración particular tiene características adicionales. Seguridad:ProxySQL, a partir de la versión 1.4.8, no es compatible con SSL del lado del cliente. Solo puede configurar una conexión SSL entre ProxySQL y el backend. Colocar ProxySQL en el host de la aplicación y usar sockets Unix es una buena solución. ProxySQL también tiene la capacidad de almacenar consultas en caché y, si va a utilizar esta función, tiene sentido mantenerla lo más cerca posible de la aplicación para reducir la latencia. Sugerimos usar este patrón para implementar ProxySQL.
Configuraciones típicas
Echemos un vistazo a ejemplos de configuraciones de alta disponibilidad.
Centro de datos único, replicación MySQL
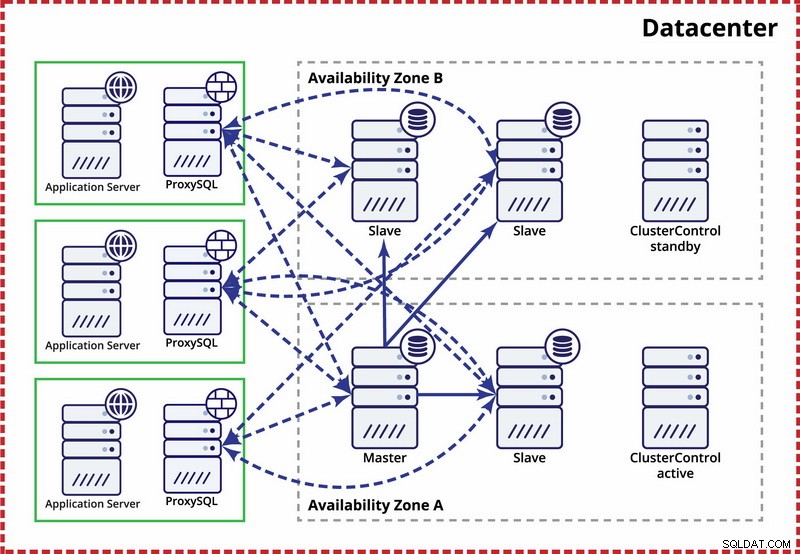
La suposición aquí es que hay dos zonas separadas dentro del centro de datos. Cada zona tiene energía, redes y conectividad redundantes y separadas para reducir la probabilidad de que dos zonas fallen simultáneamente. Es posible configurar una topología de replicación que abarque ambas zonas.
Aquí usamos ClusterControl para administrar la conmutación por error. Para resolver el escenario de cerebro dividido entre zonas de disponibilidad, colocamos el ClusterControl activo con el maestro. También ponemos en la lista negra a los esclavos en la otra zona de disponibilidad para asegurarnos de que la conmutación por error automatizada no resulte en dos maestros disponibles.
Múltiples centros de datos, replicación MySQL
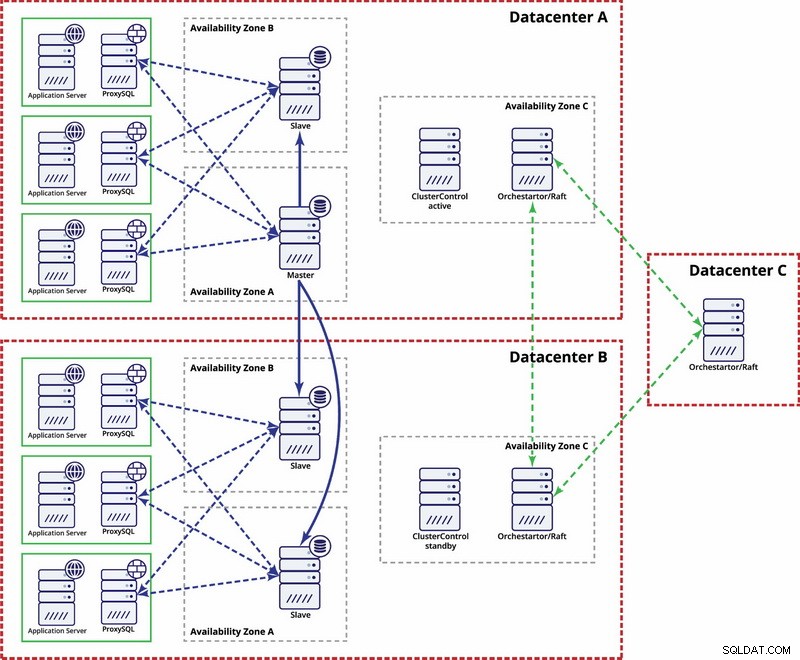
En este ejemplo, usamos tres centros de datos y Orchestrator/Raft para el cálculo del quórum. Es posible que deba escribir sus propios scripts para implementar STONITH si el maestro está en el segmento particionado de la infraestructura. ClusterControl se utiliza para funciones de gestión y recuperación de nodos.
Múltiples centros de datos, Galera Cluster
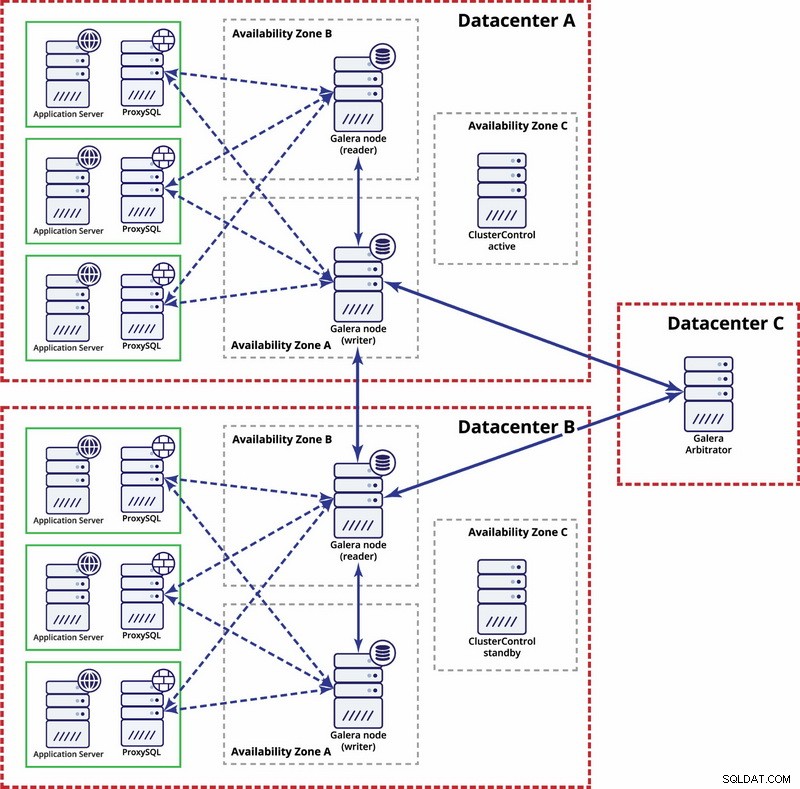
En este caso, usamos tres centros de datos con un árbitro Galera en el tercero; esto hace posible manejar fallas en todo el centro de datos y reduce el riesgo de partición de la red, ya que el tercer centro de datos se puede usar como retransmisión.
Para obtener más información, consulte el documento técnico "Cómo diseñar entornos de bases de datos de código abierto de alta disponibilidad" y vea la repetición del seminario web "Diseño de bases de datos de código abierto para alta disponibilidad".



