Una de las características interesantes de Galera es el aprovisionamiento automático de nodos y el control de membresía. Si un nodo falla o pierde la comunicación, se expulsará automáticamente del clúster y no funcionará. Siempre que la mayoría de los nodos sigan comunicándose (Galera llama a esta PC - componente principal), existe una gran posibilidad de que el nodo fallido pueda volver a unirse, resincronizarse y reanudar la replicación automáticamente una vez que se restablezca la conectividad.
Generalmente, todos los nodos de Galera son iguales. Tienen el mismo conjunto de datos y la misma función que los maestros, capaces de manejar lectura y escritura simultáneamente, gracias a la comunicación grupal de Galera y al complemento de replicación basado en certificación. Por lo tanto, en realidad no hay conmutación por error desde el punto de vista de la base de datos debido a este equilibrio. Solo desde el lado de la aplicación que requeriría conmutación por error, para omitir los nodos no operativos mientras el clúster está particionado.
En esta publicación de blog, analizaremos cómo Galera Cluster realiza la recuperación de nodos y clústeres en caso de que ocurra una partición de la red. Solo como una nota al margen, hemos cubierto un tema similar en esta publicación de blog hace algún tiempo. Codership ha explicado el concepto de recuperación de Galera con gran detalle en la página de documentación, Fallo y recuperación del nodo.
Error de nodo y expulsión
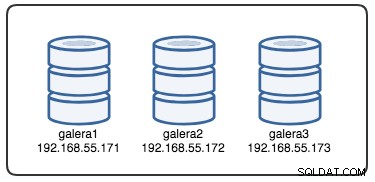
Para comprender la recuperación, primero debemos comprender cómo Galera detecta la falla del nodo y el proceso de desalojo. Pongamos esto en un escenario de prueba controlado para que podamos comprender mejor el proceso de desalojo. Supongamos que tenemos un Galera Cluster de tres nodos como se ilustra a continuación:
El siguiente comando se puede usar para recuperar nuestras opciones de proveedor de Galera:
mysql> SHOW VARIABLES LIKE 'wsrep_provider_options'\GEs una lista larga, pero solo debemos centrarnos en algunos de los parámetros para explicar el proceso:
evs.inactive_check_period = PT0.5S;
evs.inactive_timeout = PT15S;
evs.keepalive_period = PT1S;
evs.suspect_timeout = PT5S;
evs.view_forget_timeout = P1D;
gmcast.peer_timeout = PT3S;En primer lugar, Galera sigue el formato ISO 8601 para representar la duración. P1D significa que la duración es de un día, mientras que PT15S significa que la duración es de 15 segundos (tenga en cuenta el designador de tiempo, T, que precede al valor de tiempo). Por ejemplo, si uno quisiera aumentar evs.view_forget_timeout a 1 día y medio, uno configuraría P1DT12H o PT36H.
Teniendo en cuenta que todos los hosts no se han configurado con ninguna regla de firewall, usamos el siguiente script llamado block_galera.sh en galera2 para simular una falla de red hacia/desde este nodo:
#!/bin/bash
# block_galera.sh
# galera2, 192.168.55.172
iptables -I INPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I INPUT -m tcp -p tcp --dport 3306 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 3306 -j REJECT
# print timestamp
dateAl ejecutar el script, obtenemos el siguiente resultado:
$ ./block_galera.sh
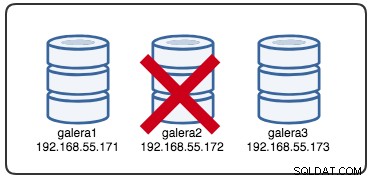
Wed Jul 4 16:46:02 UTC 2018La marca de tiempo informada se puede considerar como el comienzo de la partición del clúster, donde perdemos galera2, mientras que galera1 y galera3 todavía están en línea y accesibles. En este punto, nuestra arquitectura Galera Cluster se parece a esto:
Desde la perspectiva del nodo particionado
En galera2, verá algunas impresiones dentro del registro de errores de MySQL. Vamos a dividirlos en varias partes. El tiempo de inactividad comenzó alrededor de las 16:46:02 hora UTC y después de gmcast.peer_timeout=PT3S , aparece lo siguiente:
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 8b2041d6 with addr tcp://192.168.55.173:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.173:4567
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 737422d6 with addr tcp://192.168.55.171:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 0Cuando pasó evs.suspect_timeout =PT5S , galera2 sospecha que ambos nodos galera1 y galera3 están muertos:
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 8b2041d6
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactive
2018-07-04 16:46:07 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 0
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspecting node: 737422d6
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveLuego, Galera revisará la vista del clúster actual y la posición de este nodo:
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,54) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,55) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})Con la nueva vista de clúster, Galera realizará el cálculo de quórum para decidir si este nodo es parte del componente principal. Si el nuevo componente ve "primario =no", Galera degradará el estado del nodo local de SINCRONIZADO a ABIERTO:
2018-07-04 16:46:09 140454288942848 [Note] WSREP: New COMPONENT: primary = no, bootstrap = no, my_idx = 0, memb_num = 1
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Flow-control interval: [16, 16]
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Trying to continue unpaused monitor
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Received NON-PRIMARY.
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Shifting SYNCED -> OPEN (TO: 2753699)Con el último cambio en la vista del clúster y el estado del nodo, Galera devuelve la vista del clúster posterior al desalojo y el estado global como se muestra a continuación:
2018-07-04 16:46:09 140454222194432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753699, view# -1: non-Primary, number of nodes: 1, my index: 0, protocol version 3
2018-07-04 16:46:09 140454222194432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.Puede ver que el siguiente estado global de galera2 ha cambiado durante este período:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 1 |
| WSREP_CLUSTER_STATUS | non-Primary |
| WSREP_EVS_DELAYED | 737422d6-7db3-11e8-a2a2-bbe98913baf0:tcp://192.168.55.171:4567:1,8b2041d6-7f62-11e8-87d5-12a76678131f:tcp://192.168.55.173:4567:2 |
| WSREP_LOCAL_STATE_COMMENT | Initialized |
| WSREP_READY | OFF |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+En este punto, todavía se puede acceder al servidor MySQL/MariaDB en galera2 (la base de datos está escuchando en 3306 y Galera en 4567) y puede consultar las tablas del sistema mysql y enumerar las bases de datos y las tablas. Sin embargo, cuando salta a las tablas que no son del sistema y realiza una consulta simple como esta:
mysql> SELECT * FROM sbtest1;
ERROR 1047 (08S01): WSREP has not yet prepared node for application useInmediatamente obtendrá un error que indica que WSREP está cargado pero no está listo para ser utilizado por este nodo, según lo informado por wsrep_ready estado. Esto se debe a que el nodo pierde su conexión con el componente principal y entra en un estado no operativo (el estado del nodo local cambió de SINCRONIZADO a ABIERTO). Las lecturas de datos de nodos en un estado no operativo se consideran obsoletas, a menos que establezca wsrep_dirty_reads=ON para permitir lecturas, aunque Galera todavía rechaza cualquier comando que modifique o actualice la base de datos.
Finalmente, Galera seguirá escuchando y reconectando con otros miembros de fondo infinitamente:
2018-07-04 16:47:12 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 30
2018-07-04 16:47:13 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 30
2018-07-04 16:48:20 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 60
2018-07-04 16:48:22 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 60El flujo del proceso de desalojo por parte de la comunicación del grupo Galera para el nodo particionado durante el problema de la red se puede resumir de la siguiente manera:
- Se desconecta del clúster después de gmcast.peer_timeout .
- Sospecha de otros nodos después de evs.suspect_timeout .
- Recupera la nueva vista de clúster.
- Realiza el cálculo de quórum para determinar el estado del nodo.
- Degrada el nodo de SINCRONIZADO a ABIERTO.
- Intenta volver a conectarse al componente principal (otros nodos de Galera) en segundo plano.
Desde la perspectiva del componente principal
En galera1 y galera3 respectivamente, después de gmcast.peer_timeout=PT3S , aparece lo siguiente en el registro de errores de MySQL:
2018-07-04 16:46:05 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.172:4567
2018-07-04 16:46:06 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') reconnecting to 62116b35 (tcp://192.168.55.172:4567), attempt 0Después de pasar evs.suspect_timeout =PT5S , se sospecha que galera2 está muerta por galera3 (y galera1):
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 62116b35
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveGalera verifica si los otros nodos responden a la comunicación grupal en galera3, encuentra que galera1 está en estado primario y estable:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-04 16:46:11 139955510687488 [Note] WSREP: Node 737422d6 state primGalera revisa la vista de clúster de este nodo (galera3):
2018-07-04 16:46:11 139955510687488 [Note] WSREP: view(view_id(PRIM,737422d6,55) memb {
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
62116b35,0
})
2018-07-04 16:46:11 139955510687488 [Note] WSREP: save pc into diskGalera luego elimina el nodo particionado del componente principal:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: forgetting 62116b35 (tcp://192.168.55.172:4567)El nuevo componente principal ahora consta de dos nodos, galera1 y galera3:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 1, memb_num = 2El componente principal intercambiará el estado entre sí para acordar la nueva vista del clúster y el estado global:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-07-04 16:46:11 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: sent state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 0 (192.168.55.171)
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 1 (192.168.55.173)Galera calcula y verifica el quórum del intercambio estatal entre miembros en línea:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 27,
members = 2/2 (joined/total),
act_id = 2753703,
last_appl. = 2753606,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Flow-control interval: [23, 23]
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Trying to continue unpaused monitorGalera actualiza la nueva vista de clúster y el estado global después del desalojo de galera2:
2018-07-04 16:46:11 139955214169856 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753703, view# 28: Primary, number of nodes: 2, my index: 1, protocol version 3
2018-07-04 16:46:11 139955214169856 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-04 16:46:11 139955214169856 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-04 16:46:11 139955214169856 [Note] WSREP: Assign initial position for certification: 2753703, protocol version: 3
2018-07-04 16:46:11 139956691814144 [Note] WSREP: Service thread queue flushed.
Clean up the partitioned node (galera2) from the active list:
2018-07-04 16:46:14 139955510687488 [Note] WSREP: cleaning up 62116b35 (tcp://192.168.55.172:4567)En este punto, tanto galera1 como galera3 informarán un estado global similar:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 2 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | 1491abd9-7f6d-11e8-8930-e269b03673d8:tcp://192.168.55.172:4567:1 |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+------------------------------------------------------------------+Enumeran el miembro problemático en wsrep_evs_delayed estado. Dado que el estado local es "Sincronizado", estos nodos están operativos y puede redirigir las conexiones del cliente desde galera2 a cualquiera de ellos. Si este paso es un inconveniente, considere usar un balanceador de carga ubicado frente a la base de datos para simplificar el punto final de conexión de los clientes.
Recuperación y unión de nodos
Un nodo Galera particionado seguirá intentando establecer conexión con el Componente Primario infinitamente. Vaciemos las reglas de iptables en galera2 para permitir que se conecte con los nodos restantes:
# on galera2
$ iptables -FUna vez que el nodo sea capaz de conectarse a uno de los nodos, Galera comenzará a restablecer la comunicación del grupo automáticamente:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 8b2041d6 tcp://192.168.55.173:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 8b2041d6 at tcp://192.168.55.173:4567 stableEl nodo galera2 luego se conectará a uno de los componentes principales (en este caso es galera1, ID de nodo 737422d6) para obtener la vista del clúster actual y el estado de los nodos:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: Node 737422d6 state prim
2018-07-09 10:46:34 140075962705664 [Note] WSREP: view(view_id(PRIM,1491abd9,142) memb {
1491abd9,0
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
})
2018-07-09 10:46:34 140075962705664 [Note] WSREP: save pc into diskGalera luego realizará intercambio de estado con el resto de los miembros que pueden formar el Componente Primario:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 0, memb_num = 3
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE_EXCHANGE: sent state UUID: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: sent state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 0 (192.168.55.172)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 1 (192.168.55.171)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 2 (192.168.55.173)El intercambio estatal permite que galera2 calcule el quórum y produzca el siguiente resultado:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 71,
members = 2/3 (joined/total),
act_id = 2836958,
last_appl. = 0,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bcGalera luego promoverá el estado del nodo local de ABIERTO a PRIMARIO, para iniciar y establecer la conexión del nodo con el Componente primario:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Trying to continue unpaused monitor
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting OPEN -> PRIMARY (TO: 2836958)Como se indica en la línea anterior, Galera calcula la brecha sobre qué tan lejos está el nodo del clúster. Este nodo requiere transferencia de estado para ponerse al día con el conjunto de escritura número 2836958 desde 2761994:
2018-07-09 10:46:34 140075929970432 [Note] WSREP: State transfer required:
Group state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
Local state: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994
2018-07-09 10:46:34 140075929970432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958, view# 72: Primary, number of nodes:
3, my index: 0, protocol version 3
2018-07-09 10:46:34 140075929970432 [Warning] WSREP: Gap in state sequence. Need state transfer.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Assign initial position for certification: 2836958, protocol version: 3Galera prepara el agente de escucha IST en el puerto 4568 de este nodo y solicita a cualquier nodo sincronizado del clúster que se convierta en donante. En este caso, Galera elige automáticamente galera3 (192.168.55.173), o también podría elegir un donante de la lista en wsrep_sst_donor (si está definido) para la operación de sincronización:
2018-07-09 10:46:34 140075996276480 [Note] WSREP: Service thread queue flushed.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: IST receiver addr using tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Prepared IST receiver, listening at: tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) requested state transfer from '*any*'. Selected 2.0 (192.168.55.173)(SYNCED) as donor.Luego cambiará el estado del nodo local de PRIMARIO a UNIÓN. En esta etapa, galera2 recibe la solicitud de transferencia de estado y comienza a almacenar en caché los conjuntos de escritura:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting PRIMARY -> JOINER (TO: 2836958)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Requesting state transfer: success, donor: 2
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache history reset: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994 -> 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache DEBUG: RingBuffer::seqno_reset(): full resetEl nodo galera2 comienza a recibir los conjuntos de escritura faltantes del gcache del donante seleccionado (galera3):
2018-07-09 10:46:34 140075954312960 [Note] WSREP: 2.0 (192.168.55.173): State transfer to 0.0 (192.168.55.172) complete.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Receiving IST: 74964 writesets, seqnos 2761994-2836958
2018-07-09 10:46:34 140075593627392 [Note] WSREP: Receiving IST... 0.0% ( 0/74964 events) complete.
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 2.0 (192.168.55.173) synced with group.
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:41 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-09 10:46:44 140075593627392 [Note] WSREP: Receiving IST... 36.0% (27008/74964 events) complete.
2018-07-09 10:46:54 140075593627392 [Note] WSREP: Receiving IST... 71.6% (53696/74964 events) complete.
2018-07-09 10:47:02 140075593627392 [Note] WSREP: Receiving IST...100.0% (74964/74964 events) complete.
2018-07-09 10:47:02 140075929970432 [Note] WSREP: IST received: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:47:02 140075954312960 [Note] WSREP: 0.0 (192.168.55.172): State transfer from 2.0 (192.168.55.173) complete.Una vez que se reciban y apliquen todos los conjuntos de escritura faltantes, Galera promocionará galera2 como UNIÓN hasta el seqno 2837012:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINER -> JOINED (TO: 2837012)
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) synced with group.El nodo aplica los conjuntos de escritura almacenados en caché en su cola esclava y termina de ponerse al día con el clúster. Su cola esclava ahora está vacía. Galera promocionará galera2 a SYNCED, lo que indica que el nodo ya está operativo y listo para servir a los clientes:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINED -> SYNCED (TO: 2837012)
2018-07-09 10:47:02 140076605892352 [Note] WSREP: Synchronized with group, ready for connectionsEn este punto, todos los nodos vuelven a estar operativos. Puede verificar usando las siguientes declaraciones en galera2:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+----------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+----------------+
| WSREP_CLUSTER_SIZE | 3 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+----------------+El wsrep_cluster_size informado como 3 y el estado del grupo es Primario, lo que indica que galera2 es parte del Componente Primario. El wsrep_evs_delayed también se ha borrado y el estado local ahora está sincronizado.
El flujo del proceso de recuperación para el nodo particionado durante el problema de la red se puede resumir de la siguiente manera:
- Restablece la comunicación del grupo con otros nodos.
- Recupera la vista del clúster de uno de los componentes principales.
- Realiza el intercambio de estado con el componente principal y calcula el quórum.
- Cambia el estado del nodo local de ABIERTO a PRIMARIO.
- Calcula la brecha entre el nodo local y el clúster.
- Cambia el estado del nodo local de PRIMARY a JOINER.
- Prepara el oyente/receptor IST en el puerto 4568.
- Solicita la transferencia estatal a través de IST y elige un donante.
- Comienza a recibir y aplicar el conjunto de escritura faltante del gcache del donante elegido.
- Cambia el estado del nodo local de JOINER a JOINED.
- Se pone al día con el clúster aplicando los conjuntos de escritura almacenados en caché en la cola secundaria.
- Cambia el estado del nodo local de JOINED a SYNCED.
Fallo del clúster
Un Galera Cluster se considera fallido si no hay ningún componente principal (PC) disponible. Considere un Galera Cluster similar de tres nodos como se muestra en el siguiente diagrama:
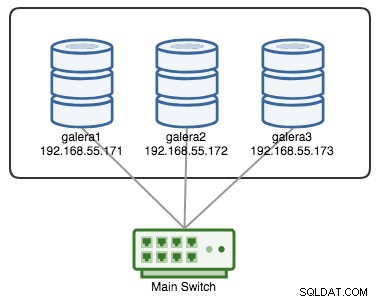
Un clúster se considera operativo si todos los nodos o la mayoría de los nodos están en línea. En línea significa que pueden verse a través del tráfico de replicación de Galera o la comunicación grupal. Si no entra ni sale tráfico del nodo, el clúster enviará una baliza de latido para que el nodo responda de manera oportuna. De lo contrario, se colocará en la lista de retrasos o sospechas según cómo responda el nodo.
Si un nodo deja de funcionar, digamos el nodo C, el clúster permanecerá operativo porque los nodos A y B todavía están en quórum con 2 votos de 3 para formar un componente principal. Debería obtener el siguiente estado de clúster en A y B:
mysql> SHOW STATUS LIKE 'wsrep_cluster_status';
+----------------------+---------+
| Variable_name | Value |
+----------------------+---------+
| wsrep_cluster_status | Primary |
+----------------------+---------+Si digamos que un interruptor principal se estropeó, como se ilustra en el siguiente diagrama:
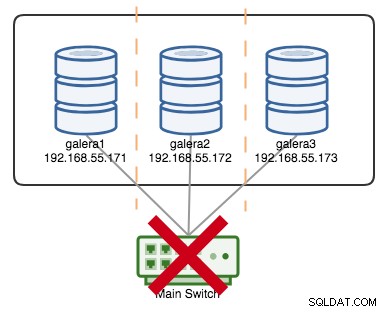
En este punto, todos los nodos pierden la comunicación entre sí y el estado del clúster se informará como no principal en todos los nodos (como sucedió con galera2 en el caso anterior). Cada nodo calcularía el quórum y descubriría que es la minoría (1 voto de 3), perdiendo así el quórum, lo que significa que no se forma ningún componente principal y, en consecuencia, todos los nodos se niegan a proporcionar datos. Esto se considera una falla del clúster.
Una vez que se resuelva el problema de la red, Galera restablecerá automáticamente la comunicación entre los miembros, intercambiará los estados de los nodos y determinará la posibilidad de reformar el componente principal comparando el estado de los nodos, los UUID y los seqnos. Si existe la probabilidad, Galera fusionará los componentes principales como se muestra en las siguientes líneas:
2018-06-27 0:16:57 140203784476416 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 2, memb_num = 3
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: sent state msg: 5885911b-795c-11e8-8683-931c85442c7e
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 0 (192.168.55.171)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 1 (192.168.55.172)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 2 (192.168.55.173)
2018-06-27 0:16:57 140203784476416 [Warning] WSREP: Quorum: No node with complete state:
Version : 4
Flags : 0x3
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.171'
Incoming addr: '192.168.55.171:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.172'
Incoming addr: '192.168.55.172:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.173'
Incoming addr: '192.168.55.173:3306'
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Full re-merge of primary 5224a024-791b-11e8-a0ac-8bc6118b0f96 found: 3 of 3.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 5,
members = 3/3 (joined/total),
act_id = 112725,
last_appl. = 112722,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Flow-control interval: [28, 28]
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Trying to continue unpaused monitor
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Restored state OPEN -> SYNCED (112725)
2018-06-27 0:16:57 140202564110080 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:112725, view# 6: Primary, number of nodes: 3, my index: 2, protocol version 3A good indicator to know if the re-bootstrapping process is OK is by looking at the following line in the error log:
[Note] WSREP: Synchronized with group, ready for connectionsClusterControl Auto Recovery
ClusterControl comes with node and cluster automatic recovery features, because it oversees and understands the state of all nodes in the cluster. Automatic recovery is by default enabled if the cluster is deployed using ClusterControl. To enable or disable the cluster, simply clicking on the power icon in the summary bar as shown below:

Green icon means automatic recovery is turned on, while red is the opposite. You can monitor the recovery progress from the Activity -> Jobs dialog, like in this case, galera2 was totally inaccessible due to firewall blocking, thus forcing ClusterControl to report the following:
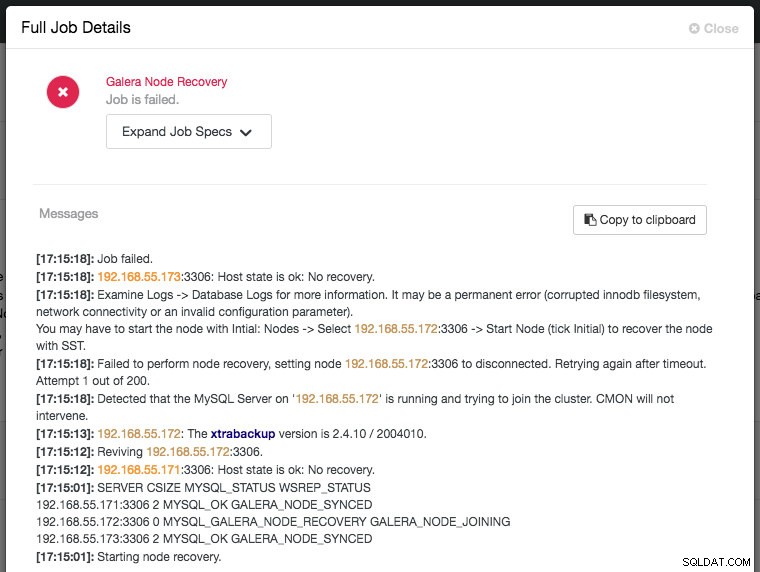
The recovery process will only be commencing after a graceful timeout (30 seconds) to give Galera node a chance to recover itself beforehand. If ClusterControl fails to recover a node or cluster, it will first pull all MySQL error logs from all accessible nodes and will raise the necessary alarms to notify the user via email or by pushing critical events to the third-party integration modules like PagerDuty, VictorOps or Slack. Manual intervention is then required. For Galera Cluster, ClusterControl will keep on trying to recover the failure until you mark the node as under maintenance, or disable the automatic recovery feature.
ClusterControl's automatic recovery is one of most favorite features as voted by our users. It helps you to take the necessary actions quickly, with a complete report on what has been attempted and recommendation steps to troubleshoot further on the issue. For users with support subscriptions, you can look for extra hands by escalating this issue to our technical support team for assistance.
Conclusión
Galera automatic node recovery and membership control are neat features to simplify the cluster management, improve the database reliability and reduce the risk of human error, as commonly haunting other open-source database replication technology like MySQL Replication, Group Replication and PostgreSQL Streaming/Logical Replication.