En la sección de comentarios de uno de nuestros blogs, un lector preguntó sobre el impacto de wsrep_slave_threads en el rendimiento y la escalabilidad de E/S de Galera Cluster. En ese momento, no pudimos responder fácilmente esa pregunta y respaldarla con más datos, pero finalmente logramos configurar el entorno y ejecutar algunas pruebas.
Nuestro lector señaló los puntos de referencia que mostraban que el aumento de wsrep_slave_threads no tuvo ningún impacto en el rendimiento del clúster de Galera.
Para explicar cuál es el impacto de esa configuración, configuramos un pequeño grupo de tres nodos (m5d.xlarge). Esto nos permitió utilizar SSD nvme adjunto directamente para el directorio de datos de MySQL. Al hacer esto, minimizamos la posibilidad de que el almacenamiento se convierta en un cuello de botella en nuestra configuración.
Configuramos el grupo de búfer de InnoDB en 8 GB y rehacemos los registros en dos archivos, 1 GB cada uno. También aumentamos innodb_io_capacity a 2000 e innodb_io_capacity_max a 10000. Esto también tenía como objetivo garantizar que ninguna de esas configuraciones afectara nuestro rendimiento.
Todo el problema con estos puntos de referencia es que hay tantos cuellos de botella que hay que eliminarlos uno por uno. Solo después de hacer algunos ajustes de configuración y después de asegurarse de que el hardware no será un problema, uno puede tener la esperanza de que aparezcan algunos límites más sutiles.
Generamos ~90 GB de datos usando sysbench:
sysbench /usr/share/sysbench/oltp_write_only.lua --threads=16 --events=0 --time=600 --mysql-host=172.30.4.245 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=3306 --tables=28 --report-interval=1 --skip-trx=off --table-size=10000000 --db-ps-mode=disable --mysql-db=sbtest_large prepareLuego se ejecutó el benchmark. Probamos dos configuraciones:wsrep_slave_threads=1 y wsrep_slave_threads=16. El hardware no era lo suficientemente potente como para beneficiarse de aumentar aún más esta variable. También tenga en cuenta que no hicimos una evaluación comparativa detallada para determinar si wsrep_slave_threads debe configurarse en 16, 8 o quizás 4 para obtener el mejor rendimiento. Estábamos interesados en ver si podemos mostrar un impacto en el clúster. Y sí, el impacto fue claramente visible. Para empezar, algunos gráficos de control de flujo.
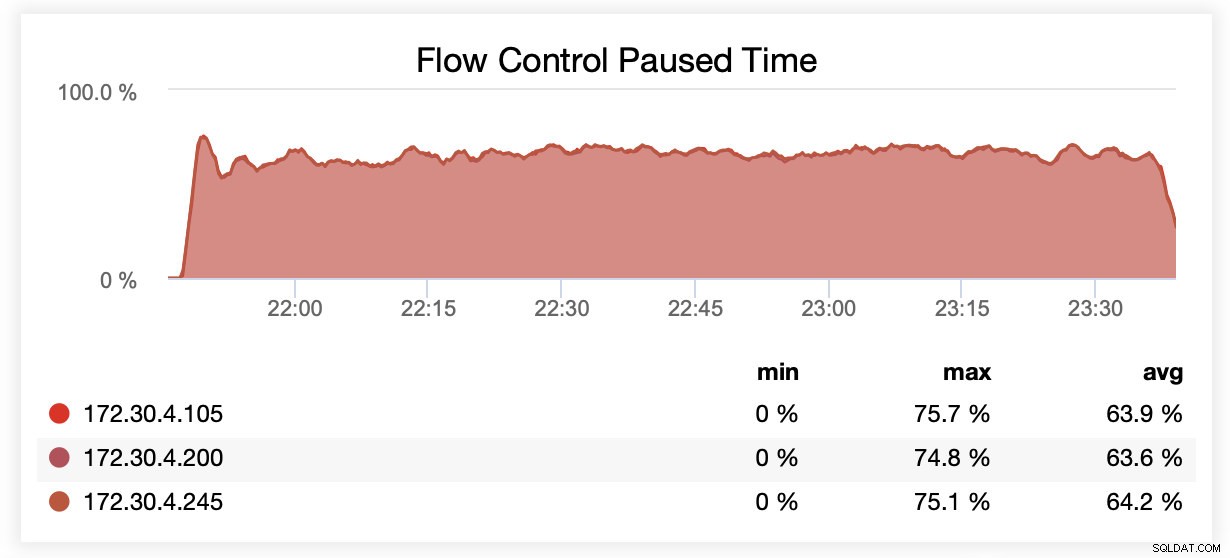
Mientras se ejecutaba con wsrep_slave_threads=1, en promedio, los nodos estaban en pausa debido al control de flujo ~64 % del tiempo.
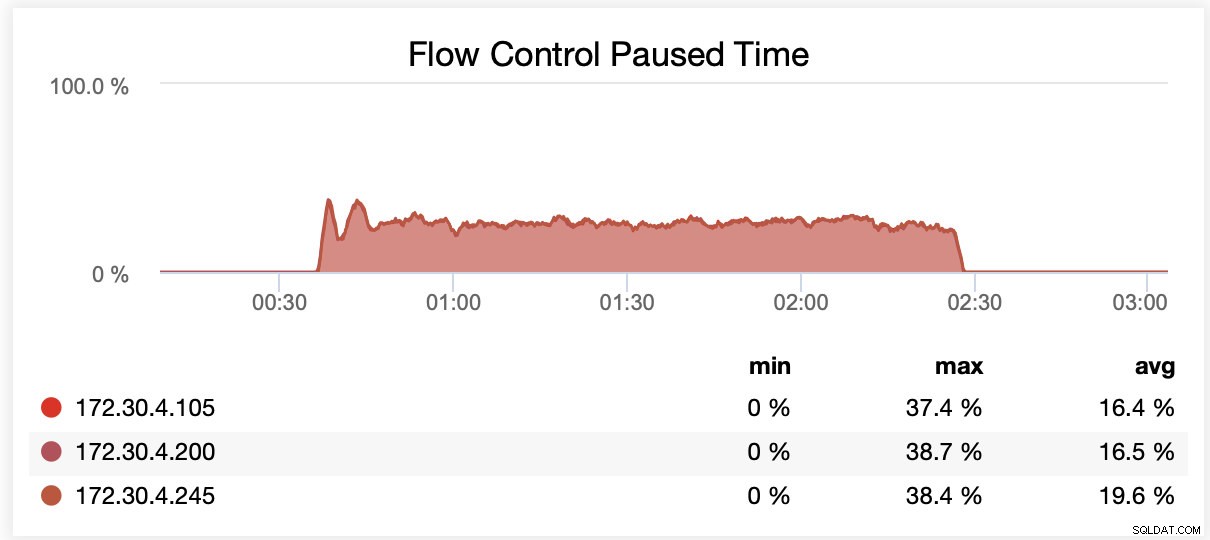
Mientras se ejecutaba con wsrep_slave_threads=16, en promedio, los nodos estaban en pausa debido al control de flujo ~20 % del tiempo.
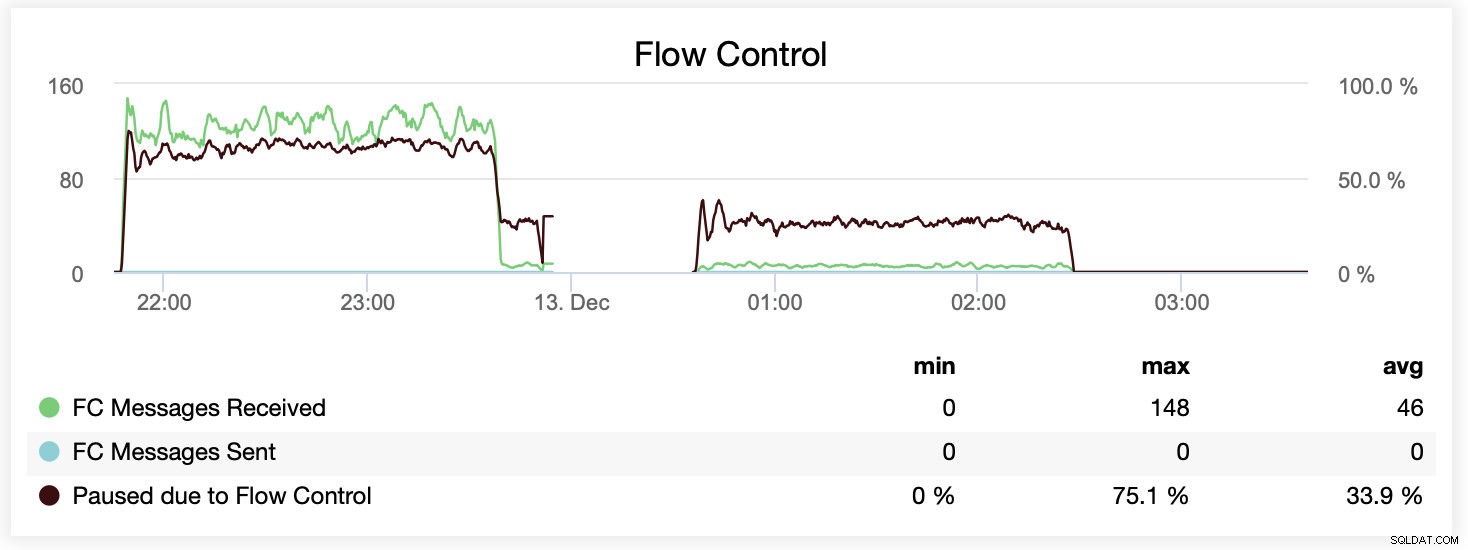
También puede comparar la diferencia en un solo gráfico. La caída al final de la primera parte es el primer intento de ejecutar con wsrep_slave_threads=16. Los servidores se quedaron sin espacio en disco para registros binarios y tuvimos que volver a ejecutar ese punto de referencia una vez más en otro momento.
¿Cómo se tradujo esto en términos de rendimiento? La diferencia es visible aunque definitivamente no tan espectacular.
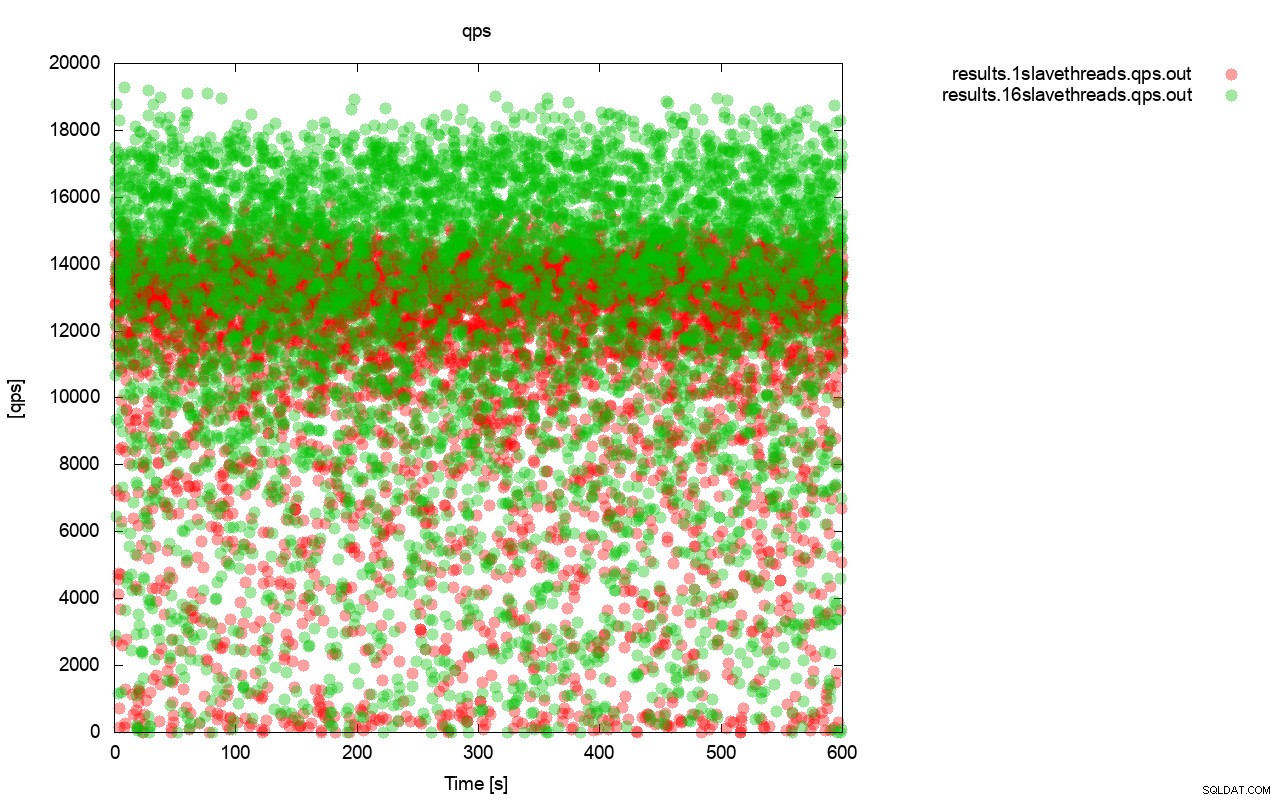
En primer lugar, el gráfico de consulta por segundo. En primer lugar, puede notar que en ambos casos los resultados están por todas partes. Esto se relaciona principalmente con el rendimiento inestable del almacenamiento de E/S y el control de flujo que se activa aleatoriamente. Todavía puede ver que el rendimiento del resultado "rojo" (wsrep_slave_threads=1) es bastante más bajo que el "verde" ( wsrep_slave_threads=16).
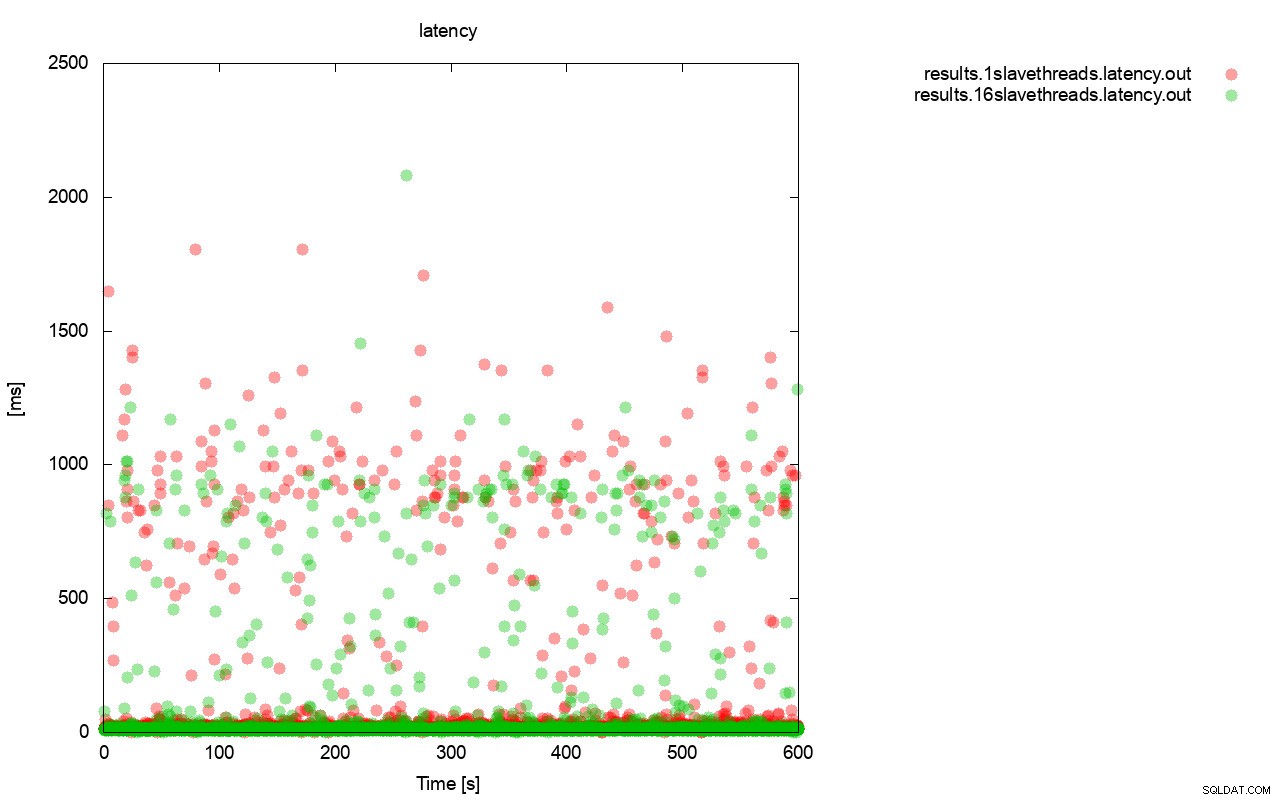
Una imagen bastante similar es cuando observamos la latencia. Puede ver más paradas (y generalmente más profundas) para la ejecución con wsrep_slave_thread=1.
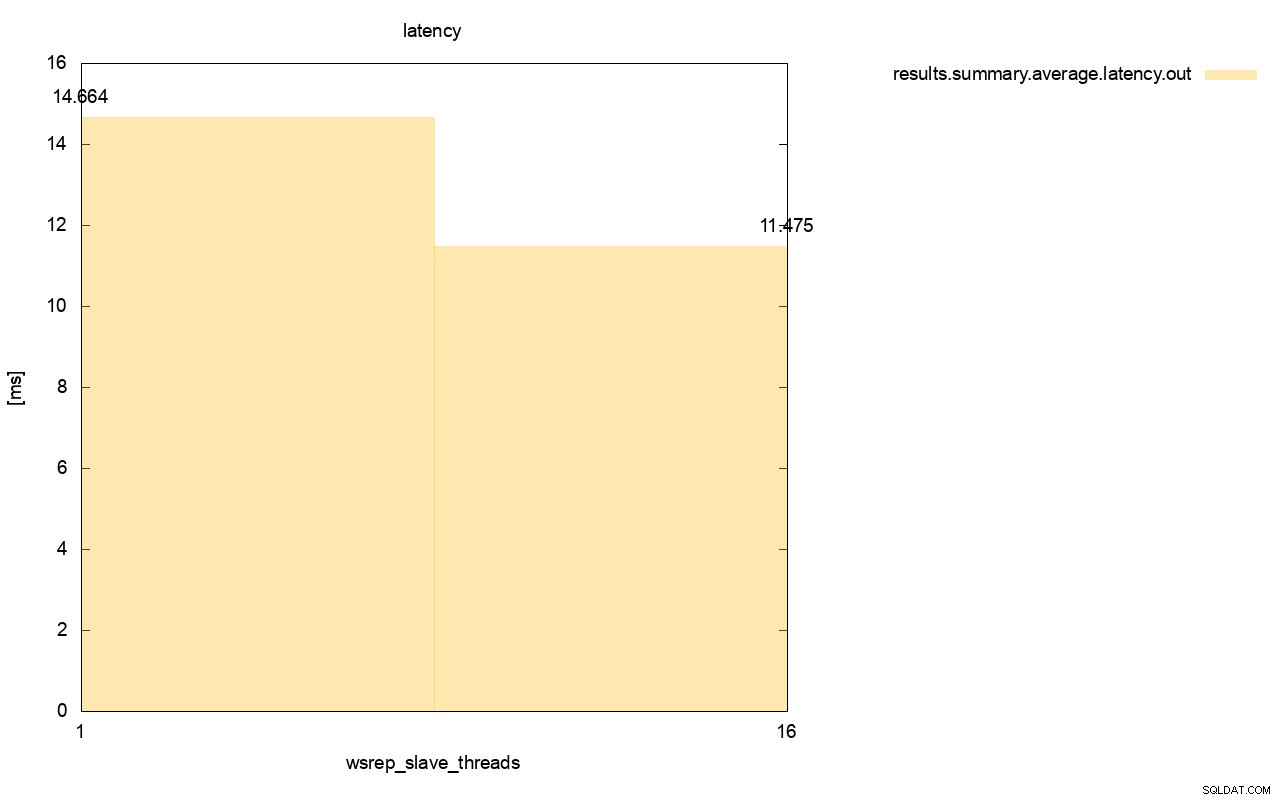
La diferencia es aún más visible cuando calculamos la latencia promedio en todas las ejecuciones y puede ver que la latencia de wsrep_slave_thread=1 es un 27 % más alta que la latencia con 16 subprocesos esclavos, lo que obviamente no es bueno, ya que queremos que la latencia sea más baja. , no más alto.
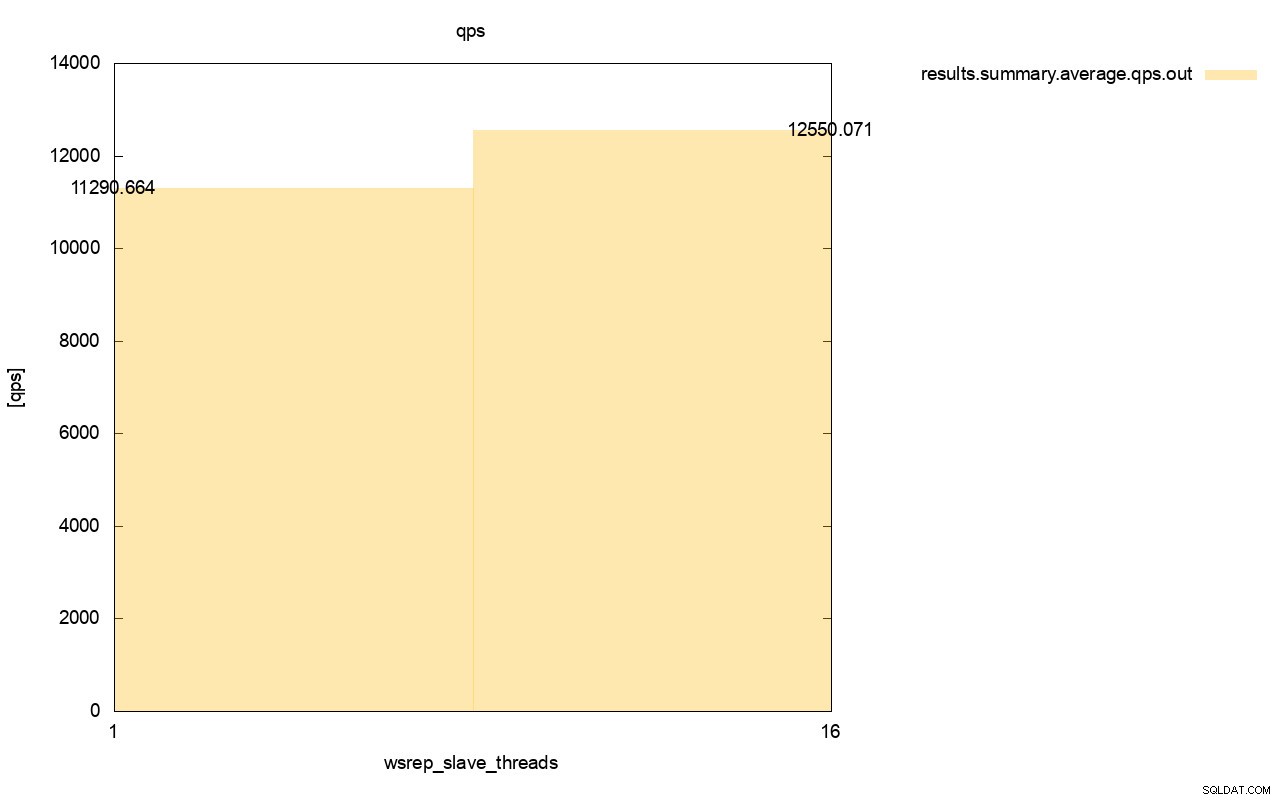
La diferencia en el rendimiento también es visible, alrededor del 11 % de la mejora cuando agregamos más wsrep_slave_threads.
Como puede ver, el impacto está ahí. De ninguna manera es 16x (incluso si así es como aumentamos el número de subprocesos esclavos en Galera), pero definitivamente es lo suficientemente prominente como para que no podamos clasificarlo como una anomalía estadística.
Tenga en cuenta que en nuestro caso usamos nodos bastante pequeños. La diferencia debería ser aún más significativa si hablamos de grandes instancias que se ejecutan en volúmenes de EBS con miles de IOPS aprovisionadas.
Entonces podríamos ejecutar sysbench de manera aún más agresiva, con una mayor cantidad de operaciones simultáneas. Esto debería mejorar la paralelización de los conjuntos de escritura, mejorando aún más la ganancia de los subprocesos múltiples. Además, un hardware más rápido significa que Galera podrá utilizar esos 16 subprocesos de manera más eficiente.
Al ejecutar pruebas como esta, debe tener en cuenta que debe llevar su configuración casi al límite. La replicación de subproceso único puede manejar una gran cantidad de carga y necesita ejecutar un tráfico pesado para que no tenga el rendimiento suficiente para manejar la tarea.
Esperamos que esta publicación de blog le brinde más información sobre las capacidades de Galera Cluster para aplicar conjuntos de escritura en paralelo y los factores limitantes que lo rodean.