El objetivo de tiempo de recuperación (RTO) es el período de tiempo dentro del cual se debe restaurar un servicio para evitar consecuencias inaceptables. Al calcular cuánto tiempo puede llevar recuperarse de una falla de la base de datos, podemos saber cuál es el nivel de preparación requerido. Si el RTO es de unos pocos minutos, se requiere una inversión significativa en conmutación por error. Un RTO de 36 horas requiere una inversión significativamente menor. Aquí es donde entra en juego la automatización de conmutación por error.
En nuestros blogs anteriores, hemos discutido la conmutación por error para MongoDB, MySQL/MariaDB/Percona, PostgreSQL o TimeScaleDB. En resumen, "Failover " es la capacidad de un sistema para continuar funcionando incluso si ocurre alguna falla. Sugiere que las funciones del sistema son asumidas por componentes secundarios si fallan los componentes primarios. La conmutación por error es una parte natural de cualquier sistema de alta disponibilidad y, en algunos casos, , incluso tiene que ser automatizado Las conmutaciones por error manuales toman demasiado tiempo, pero hay casos en los que la automatización no funcionará bien, por ejemplo, en el caso de un cerebro dividido donde la replicación de la base de datos se interrumpe y las dos "mitades" siguen recibiendo actualizaciones, efectivamente lo que lleva a conjuntos de datos divergentes e inconsistencias.
Anteriormente escribimos sobre los principios rectores detrás de los procedimientos automáticos de conmutación por error de ClusterControl. Siempre que sea posible, la conmutación por error automatizada brinda eficiencia, ya que permite una recuperación rápida de las fallas. En este blog, veremos cómo lograr una conmutación por error automática en una configuración de replicación maestro-esclavo (o principal-en espera) mediante ClusterControl.
Requisitos de la pila de tecnología
Se puede ensamblar una pila a partir de componentes de software de código abierto, y hay una serie de opciones disponibles, algunas más apropiadas que otras según las características de conmutación por error y también el nivel de experiencia disponible para administrar y mantener la solución. El hardware y las redes también son aspectos importantes.
Software
Hay muchas opciones disponibles en el ecosistema de código abierto que puede usar para implementar la conmutación por error. Para MySQL, puede aprovechar MHA, MMM, Maxscale/MRM, mysqlfailover u Orchestrator. Este blog anterior compara MaxScale con MHA con Maxscale/MRM. PostgreSQL tiene repmgr, Patroni, PostgreSQL Automatic Failover (PAF), pglookout, pgPool-II o stolon. Estas diferentes opciones de alta disponibilidad se cubrieron anteriormente. MongoDB tiene conjuntos de réplicas compatibles con conmutación por error automatizada.
ClusterControl proporciona una funcionalidad de conmutación por error automática para MySQL, MariaDB, PostgreSQL y MongoDB, que trataremos más adelante. Vale la pena señalar que también tiene funcionalidad para recuperar automáticamente nodos o clústeres rotos.
Hardware
La conmutación por error automática generalmente la realiza un servidor daemon separado que se configura en su propio hardware, separado de los nodos de la base de datos. Está monitoreando el estado de las bases de datos y utiliza la información para tomar decisiones sobre cómo reaccionar en caso de falla.
Los servidores básicos pueden funcionar bien, a menos que el servidor esté monitoreando una gran cantidad de instancias. Por lo general, las comprobaciones del sistema y el análisis de estado son ligeros en términos de procesamiento. Sin embargo, si tiene una gran cantidad de nodos para verificar, una gran CPU y memoria son imprescindibles, especialmente cuando las verificaciones deben ponerse en cola mientras intenta hacer ping y recopilar información de los servidores. Los nodos que se monitorean y supervisan pueden detenerse a veces debido a problemas de red, alta carga o, en el peor de los casos, pueden estar inactivos debido a una falla de hardware o algún daño en el host de VM. Por lo tanto, el servidor que ejecuta las comprobaciones del estado y del sistema podrá soportar tales bloqueos, ya que es probable que el procesamiento de las colas aumente, ya que las respuestas a cada uno de los nodos monitoreados pueden llevar tiempo hasta que se verifique que ya no está disponible o que se agotó el tiempo de espera. sido alcanzado.
Para entornos basados en la nube, existen servicios que ofrecen conmutación por error automática. Por ejemplo, Amazon RDS usa DRBD para replicar el almacenamiento en un nodo en espera. O si está almacenando sus volúmenes en EBS, estos se replican en varias zonas.
Red
El software de conmutación por error automatizado a menudo se basa en agentes que se configuran en los nodos de la base de datos. El agente recopila información localmente de la instancia de la base de datos y la envía al servidor, siempre que se solicite.
En términos de requisitos de red, asegúrese de tener un buen ancho de banda y una conexión de red estable. Las comprobaciones deben realizarse con frecuencia, y los latidos perdidos debido a una red inestable pueden hacer que el software de conmutación por error deduzca (erróneamente) que un nodo está inactivo.
ClusterControl no requiere la instalación de ningún agente en los nodos de la base de datos, ya que accederá mediante SSH a cada nodo de la base de datos a intervalos regulares y realizará una serie de comprobaciones.
Conmutación por error automatizada con ClusterControl
ClusterControl ofrece la capacidad de realizar failovers tanto manuales como automatizados. Veamos cómo se puede hacer esto.
La conmutación por error en ClusterControl se puede configurar para que sea automática o no. Si prefiere encargarse de la conmutación por error manualmente, puede deshabilitar la recuperación automática de clústeres. Al realizar una conmutación por error manual, puede ir a Clúster → Topología en Cluster Control. Vea la captura de pantalla a continuación:
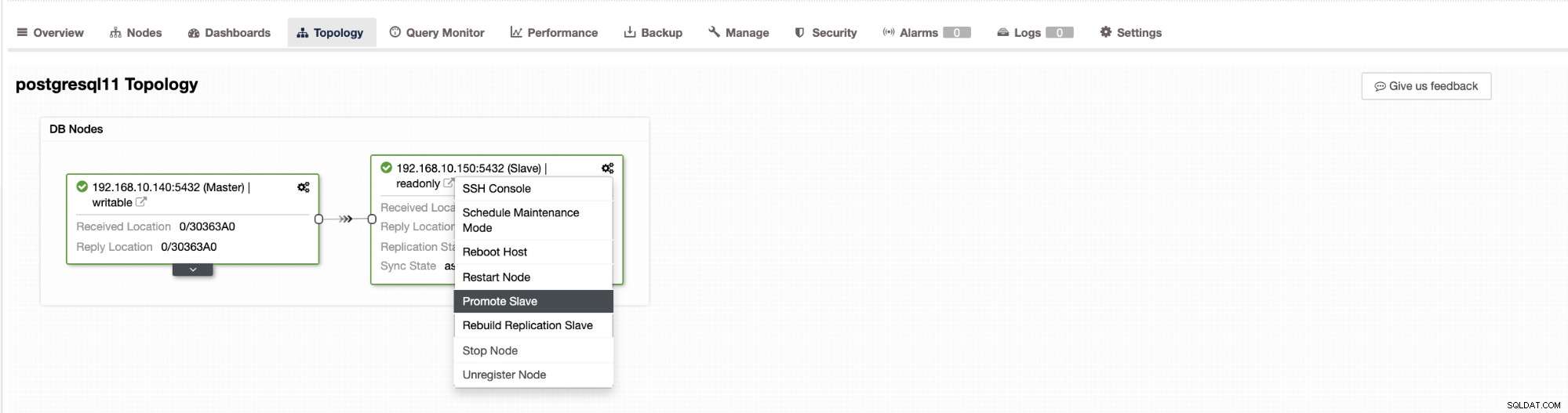
De manera predeterminada, la recuperación del clúster está habilitada y se usa la conmutación por error automatizada. Una vez que realiza cambios en la interfaz de usuario, la configuración del tiempo de ejecución cambia. Si desea que la configuración sobreviva a un reinicio del controlador, asegúrese de realizar también el cambio en la configuración de cmon, es decir, /etc/cmon.d/cmon_

En el servidor MySQL/MariaDB/Percona, ClusterControl inicia la conmutación por error automática cuando detecta que no hay ningún host con solo lectura bandera desactivada. Puede suceder porque maestro (que tiene solo lectura establecido en 0) no está disponible o puede ser activado por un usuario o algún software externo que cambió esta bandera en el maestro. Si realiza cambios manuales en los nodos de la base de datos o tiene un software que puede modificar la configuración de solo lectura, debe desactivar la conmutación por error automática. La conmutación por error automatizada de ClusterControl se intenta solo una vez, por lo tanto, una conmutación por error fallida no será seguida nuevamente por una conmutación por error posterior, no hasta que se reinicie cmon.
Para PostgreSQL, ClusterControl escogerá el esclavo más avanzado, utilizando para ello pg_current_xlog_location (PostgreSQL 9+) o pg_current_wal_lsn (PostgreSQL 10+) dependiendo de la versión de nuestra base de datos. ClusterControl también realiza varias comprobaciones sobre el proceso de conmutación por error para evitar algunos errores comunes. Un ejemplo es que si logramos recuperar nuestro antiguo maestro fallido, "no " ser reintroducido automáticamente al clúster, ni como maestro ni como esclavo. Necesitamos hacerlo manualmente. Esto evitará la posibilidad de pérdida de datos o inconsistencia en el caso de que nuestro esclavo (que promocionamos) se retrasara en ese momento de la falla. También es posible que queramos analizar el problema en detalle antes de volver a introducirlo en la configuración de la replicación, por lo que nos gustaría conservar la información de diagnóstico.
Además, si falla la conmutación por error, no se realizan más intentos (esto se aplica tanto a los clústeres basados en PostgreSQL como en MySQL), se requiere una intervención manual para analizar el problema y realizar las acciones correspondientes. Esto es para evitar la situación en la que ClusterControl, que maneja la conmutación por error automática, intenta promover el siguiente esclavo y el siguiente. Es posible que haya un problema y no queremos empeorar las cosas intentando varias conmutaciones por error.
ClusterControl ofrece listas blancas y negras de un conjunto de servidores que desea que participen en la conmutación por error o que desee excluir como candidatos.
Para clústeres de tipo MySQL, ClusterControl crea una lista de esclavos que pueden ascender a maestro. La mayoría de las veces, contendrá todos los esclavos en la topología, pero el usuario tiene algún control adicional sobre ellos. Hay dos variables que puede establecer en la configuración cmon:
replication_failover_whitelisty
replication_failover_blacklistPara la variable de configuración replication_failover_whitelist, contiene una lista de IP o nombres de host de esclavos que deben usarse como posibles candidatos maestros. Si se establece esta variable, solo se considerarán esos hosts. Para la variable replication_failover_blacklist, contiene una lista de hosts que nunca se considerarán candidatos maestros. Puede usarlo para enumerar esclavos que se usan para copias de seguridad o consultas analíticas. Si el hardware varía entre los esclavos, es posible que desee colocar aquí los esclavos que utilizan un hardware más lento.
replication_failover_whitelist tiene prioridad, lo que significa que replication_failover_blacklist se ignora si se establece replication_failover_whitelist.
Una vez que la lista de esclavos que pueden ascender a maestro está lista, ClusterControl comienza a comparar su estado, buscando el esclavo más actualizado. Aquí, el manejo de las configuraciones basadas en MariaDB y MySQL difiere. Para las configuraciones de MariaDB, ClusterControl elige un esclavo que tenga el retraso de replicación más bajo de todos los esclavos disponibles. Para las configuraciones de MySQL, ClusterControl también elige un esclavo de este tipo, pero luego busca transacciones faltantes adicionales que podrían haberse ejecutado en algunos de los esclavos restantes. Si se encuentra una transacción de este tipo, ClusterControl esclaviza al candidato maestro fuera de ese host para recuperar todas las transacciones faltantes. Puede omitir este proceso y simplemente usar el esclavo más avanzado configurando la variable replication_skip_apply_missing_txs en su configuración de CMON:
por ejemplo
replication_skip_apply_missing_txs=1Consulte nuestra documentación aquí para obtener más información con variables.
La advertencia es que solo debe configurar esto si sabe lo que está haciendo, ya que puede haber transacciones erróneas. Esto podría provocar que la replicación se interrumpa, así como la incoherencia de los datos en todo el clúster. Si la transacción errante ocurrió en el pasado, es posible que ya no esté disponible en los registros binarios. En ese caso, la replicación se interrumpirá porque los esclavos no podrán recuperar los datos que faltan. Por lo tanto, ClusterControl, de forma predeterminada, comprueba si hay transacciones erróneas antes de promover a un candidato maestro para que se convierta en maestro. Si se detecta dicho problema, el interruptor maestro se aborta y ClusterControl permite que el usuario solucione el problema manualmente.
Si quiere estar 100 % seguro de que ClusterControl promoverá un nuevo maestro incluso si se detectan algunos problemas, puede hacerlo usando la variable replication_stop_on_error. Ver a continuación:
por ejemplo
replication_stop_on_error=0Establezca esta variable en su archivo de configuración cmon. Como se mencionó anteriormente, puede generar problemas con la replicación, ya que los esclavos pueden comenzar a solicitar un evento de registro binario que ya no está disponible. Para manejar tales casos, agregamos soporte experimental para la reconstrucción de esclavos. Si establece la variable
replication_auto_rebuild_slave=1en la configuración de cmon y si su esclavo está marcado como inactivo con el siguiente error en MySQL:
Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'ClusterControl intentará reconstruir el esclavo usando datos del maestro. Tal configuración puede no ser siempre apropiada ya que el proceso de reconstrucción inducirá una mayor carga en el maestro. También puede ser que su conjunto de datos sea muy grande y una reconstrucción regular no sea una opción, por eso este comportamiento está deshabilitado de manera predeterminada.
Una vez que nos aseguramos de que no existe ninguna transacción errada y estamos listos para continuar, todavía hay un problema más que debemos manejar de alguna manera:puede suceder que todos los esclavos estén rezagados con respecto al maestro.
Como probablemente sepa, la replicación en MySQL funciona de una manera bastante simple. El maestro almacena escrituras en registros binarios. El subproceso de E/S del esclavo se conecta al maestro y extrae cualquier evento de registro binario que falte. Luego los almacena en forma de registros de retransmisión. El subproceso SQL los analiza y aplica eventos. El retraso del esclavo es una condición en la que el subproceso SQL (o subprocesos) no puede hacer frente a la cantidad de eventos y no puede aplicarlos tan pronto como el subproceso de E/S los extrae del maestro. Tal situación puede ocurrir sin importar qué tipo de replicación esté utilizando. Incluso si utiliza la replicación semisincrónica, solo puede garantizar que todos los eventos del maestro se almacenen en uno de los esclavos en el registro de retransmisión. No dice nada sobre la aplicación de esos eventos a un esclavo.
El problema aquí es que, si un esclavo se convierte en maestro, los registros de retransmisión se borrarán. Si un esclavo se está retrasando y no ha aplicado todas las transacciones, perderá datos:los eventos que aún no se hayan aplicado desde los registros de retransmisión se perderán para siempre.
No existe una forma única de resolver esta situación. ClusterControl brinda a los usuarios control sobre cómo debe hacerse, manteniendo valores predeterminados seguros. Se realiza en configuración cmon usando la siguiente configuración:
replication_failover_wait_to_apply_timeout=-1De manera predeterminada, toma un valor de '-1', lo que significa que la conmutación por error no ocurrirá de inmediato si un candidato maestro se está retrasando, por lo que está configurado para esperar para siempre a menos que el candidato se haya puesto al día. ClusterControl esperará indefinidamente a que aplique todas las transacciones faltantes de sus registros de retransmisión. Esto es seguro, pero, si por alguna razón, el esclavo más actualizado se está retrasando mucho, la conmutación por error puede tardar horas en completarse. En el otro lado del espectro está establecerlo en '0', lo que significa que la conmutación por error ocurre de inmediato, sin importar si el candidato principal se está retrasando o no. También puede ir por el camino medio y establecerlo en algún valor. Esto establecerá un tiempo en segundos, por ejemplo, 30 segundos, así que establezca la variable en,
replication_failover_wait_to_apply_timeout=30Cuando se establece en> 0, ClusterControl esperará a que un candidato maestro aplique las transacciones faltantes de sus registros de retransmisión hasta que se alcance el valor (que es 30 segundos en el ejemplo). La conmutación por error ocurre después del tiempo definido o cuando el candidato principal se pondrá al día con la replicación, lo que ocurra primero. Esta puede ser una buena opción si su aplicación tiene requisitos específicos con respecto al tiempo de inactividad y tiene que elegir un nuevo maestro dentro de un período de tiempo corto.
Para obtener más detalles sobre cómo funciona ClusterControl con la conmutación por error automática en PostgreSQL y MySQL, consulte nuestros blogs anteriores titulados "Conmutación por error para la replicación de PostgreSQL 101" y "Conmutación por error automática de la replicación de MySQL - Nuevo en ClusterControl 1.4".
Conclusión
La conmutación por error automatizada es una característica valiosa, especialmente para las empresas que requieren operaciones las 24 horas del día, los 7 días de la semana, con un tiempo de inactividad mínimo. La empresa debe definir cuánto control se otorga al proceso de automatización durante las interrupciones no planificadas. Una solución de alta disponibilidad como ClusterControl ofrece un nivel personalizable de interacción en el procesamiento de conmutación por error. Para algunas organizaciones, la conmutación por error automatizada puede no ser una opción, aunque la interacción del usuario durante la conmutación por error puede consumir tiempo y afectar el RTO. La suposición es que es demasiado arriesgado en caso de que la conmutación por error automatizada no funcione correctamente o, lo que es peor, da como resultado que los datos se estropeen y falten parcialmente (aunque se podría argumentar que un ser humano también puede cometer errores desastrosos que tengan consecuencias similares). Aquellos que prefieran mantener un control estricto sobre su base de datos pueden optar por omitir la conmutación por error automatizada y utilizar un proceso manual en su lugar. Este proceso lleva más tiempo, pero permite que un administrador experimentado evalúe el estado de un sistema y tome medidas correctivas en función de lo sucedido.