En un blog anterior, anunciamos una nueva característica de ClusterControl 1.7.4 llamada Replicación de clúster a clúster. Automatiza todo el proceso de configuración de un clúster DR fuera de su clúster principal, con replicación en el medio. Para obtener información más detallada, consulte la entrada de blog mencionada anteriormente.
Ahora, en este blog, veremos cómo configurar esta nueva función para un clúster existente. Para esta tarea, supondremos que tiene instalado ClusterControl y que Master Cluster se implementó usándolo.
Requisitos para el Master Cluster
Hay algunos requisitos para que Master Cluster funcione:
- Percona XtraDB Cluster versión 5.6.x y posteriores, o MariaDB Galera Cluster versión 10.x y posteriores.
- GTID habilitado.
- Binary Logging habilitado en al menos un nodo de base de datos.
- Las credenciales de respaldo deben ser las mismas en el clúster maestro y el clúster esclavo.
Preparación del grupo maestro
El Master Cluster debe estar preparado para usar esta nueva característica. Requiere configuración tanto del lado de ClusterControl como de la base de datos.
Configuración de control de clúster
En el nodo de la base de datos, verifique las credenciales de usuario de respaldo almacenadas en /etc/my.cnf.d/secrets-backup.cnf (para SO basado en RedHat) o en /etc/mysql/secrets-backup .cnf (para SO basado en Debian).
$ cat /etc/my.cnf.d/secrets-backup.cnf
# Security credentials for backup.
[mysqldump]
user=backupuser
password=cYj0GFBEdqdreZEl
[xtrabackup]
user=backupuser
password=cYj0GFBEdqdreZEl
[mysqld]
wsrep_sst_auth=backupuser:cYj0GFBEdqdreZElEn el nodo ClusterControl, edite el archivo de configuración /etc/cmon.d/cmon_ID.cnf (donde ID es el número de identificación del clúster) y asegúrese de que contiene las mismas credenciales almacenadas en secrets-backup. cnf.
$ cat /etc/cmon.d/cmon_8.cnf
backup_user=backupuser
backup_user_password=cYj0GFBEdqdreZEl
basedir=/usr
cdt_path=/
cluster_id=8
...Cualquier cambio en este archivo requiere un reinicio del servicio cmon:
$ service cmon restartCompruebe los parámetros de replicación de la base de datos para asegurarse de que tiene GTID y registro binario habilitados.
Configuración de la base de datos
En el nodo de la base de datos, verifique el archivo /etc/my.cnf (para SO basado en RedHat) o /etc/mysql/my.cnf (para SO basado en Debian) para ver la configuración relacionada con el proceso de replicación.
Percona XtraDB:
$ cat /etc/my.cnf
# REPLICATION SPECIFIC
server_id=4002
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
gtid_mode = ON
enforce_gtid_consistency = true
relay_log = relay-log
expire_logs_days = 7Clúster MariaDB Galera:
$ cat /etc/my.cnf
# REPLICATION SPECIFIC
server_id=9000
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
relay_log = relay-log
wsrep_gtid_domain_id=9000
wsrep_gtid_mode=ON
gtid_domain_id=9000
gtid_strict_mode=ON
gtid_ignore_duplicates=ON
expire_logs_days = 7En lugar de verificar los archivos de configuración, puede verificar si está habilitado en la interfaz de usuario de ClusterControl. Vaya a ClusterControl -> Seleccione Clúster -> Nodos. Ahí deberías tener algo como esto:

La función "Maestro" agregada en el primer nodo significa que el registro binario está habilitado.
Habilitación del registro binario
Si no tiene habilitado el registro binario, vaya a ClusterControl -> Seleccionar clúster -> Nodos -> Acciones de nodo -> Habilitar registro binario.
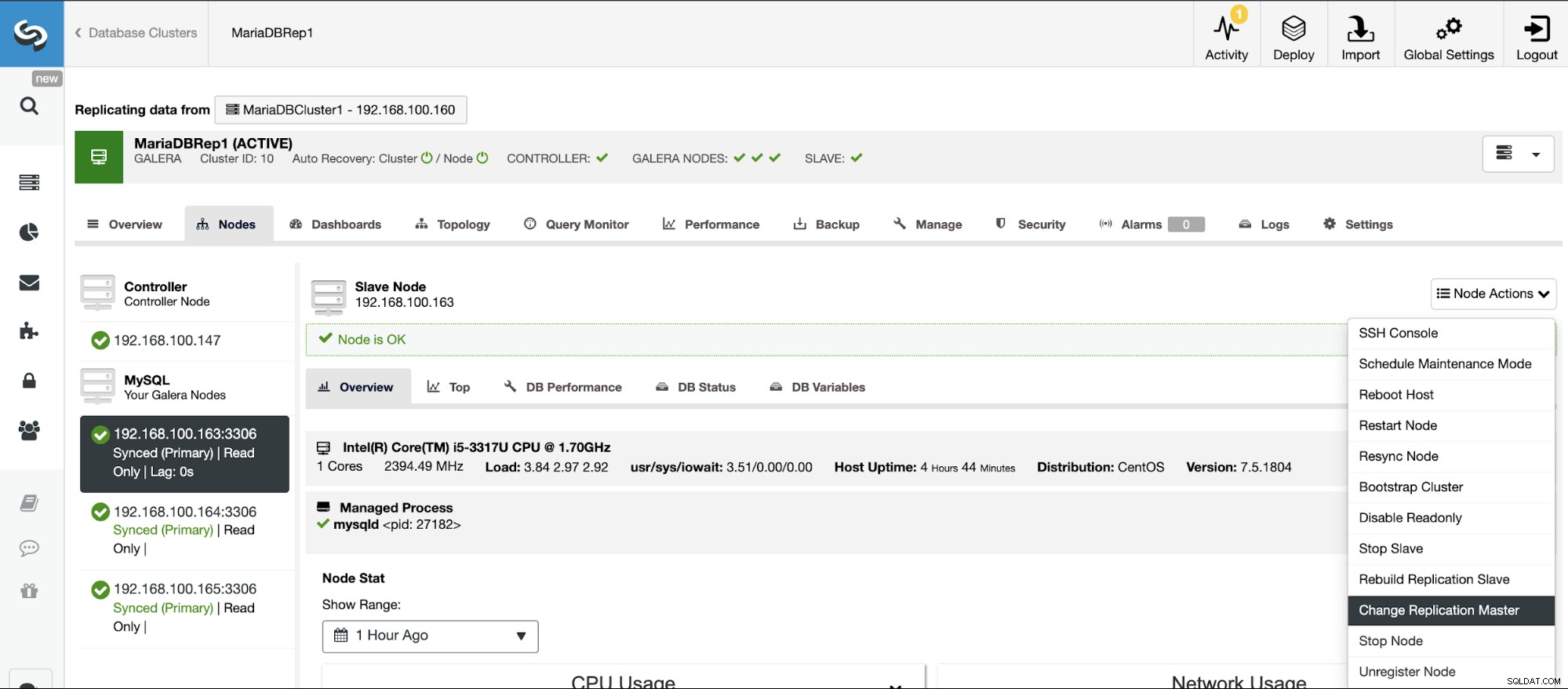
Luego, debe especificar la retención del registro binario y la ruta para almacenar eso. También debe especificar si desea que ClusterControl reinicie el nodo de la base de datos después de configurarlo o si prefiere reiniciarlo usted mismo.
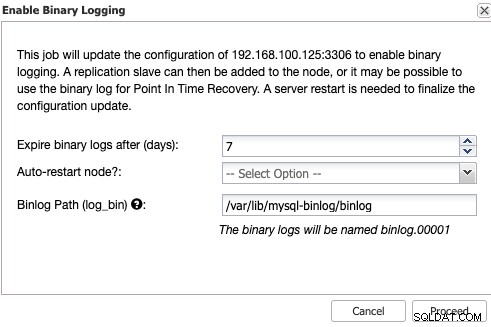
Recuerde que habilitar el registro binario siempre requiere reiniciar el servicio de la base de datos .
Creación del clúster esclavo desde la GUI de ClusterControl
Para crear un nuevo clúster esclavo, vaya a ClusterControl -> Seleccionar clúster -> Acciones del clúster -> Crear clúster esclavo.
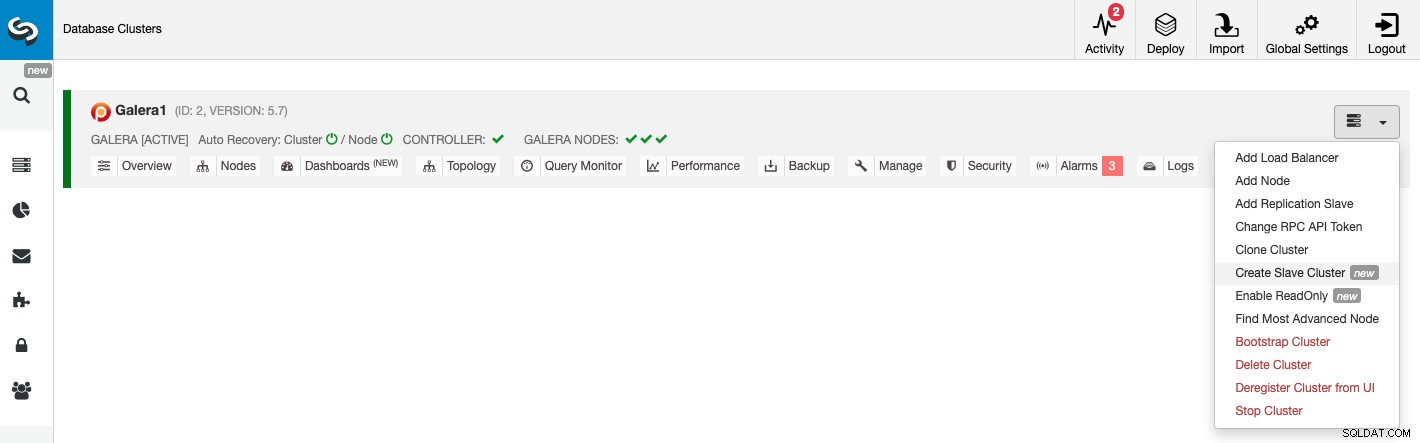
El clúster esclavo se puede crear transmitiendo datos desde el clúster maestro actual o mediante el uso de una copia de seguridad existente.
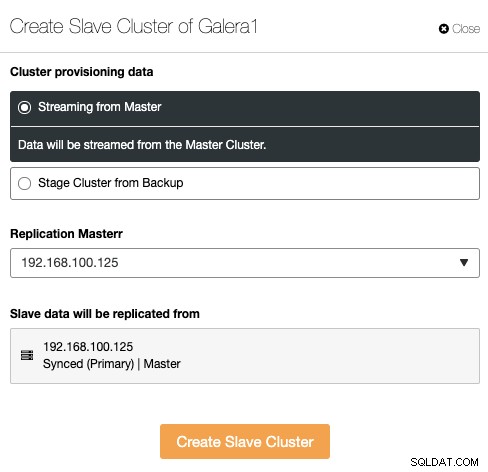
En esta sección, también debe elegir el nodo maestro del clúster actual a partir del cual se replicarán los datos.
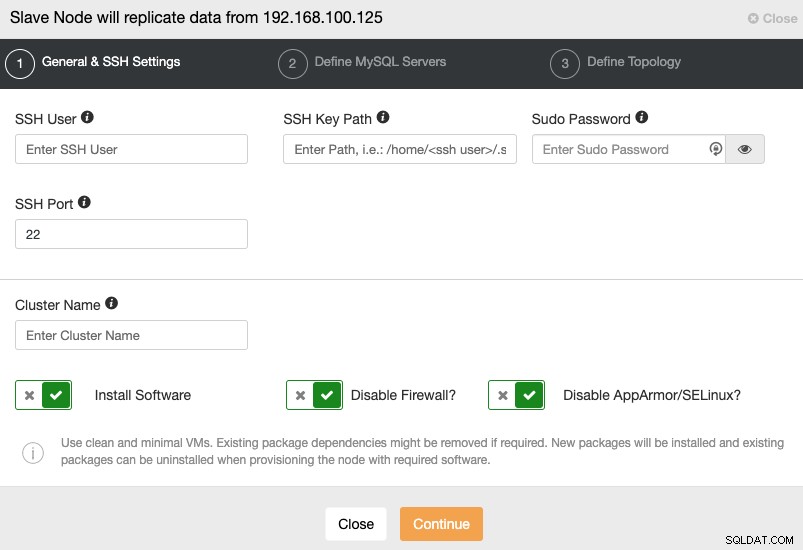
Cuando vaya al siguiente paso, debe especificar Usuario, Clave o Contraseña y puerto para conectarte por SSH a tus servidores. También necesita un nombre para su Slave Cluster y si desea que ClusterControl instale el software y las configuraciones correspondientes por usted.
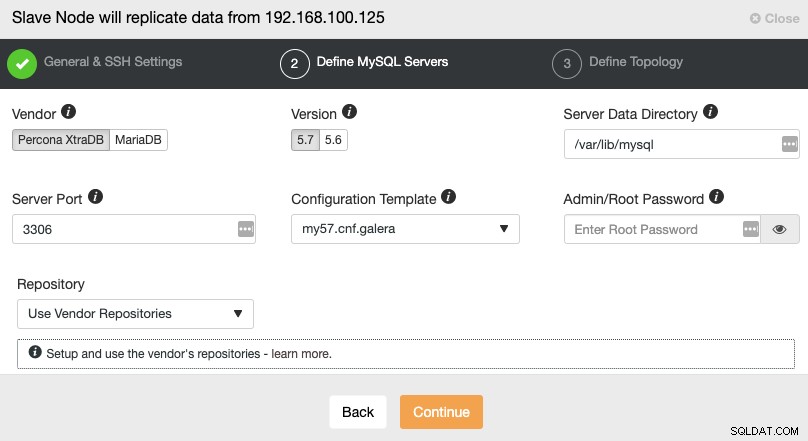
Después de configurar la información de acceso SSH, debe definir el proveedor de la base de datos y versión, datadir, puerto de la base de datos y la contraseña de administrador. Asegúrese de utilizar el mismo proveedor/versión y las mismas credenciales que utiliza el Master Cluster. También puede especificar qué repositorio usar.
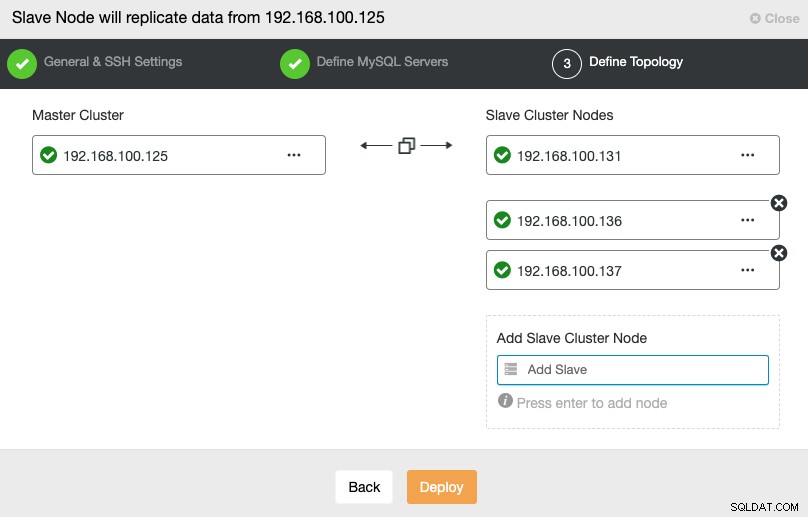
En este paso, debe agregar servidores al nuevo clúster esclavo. Para esta tarea, puede ingresar la dirección IP o el nombre de host de cada nodo de la base de datos.
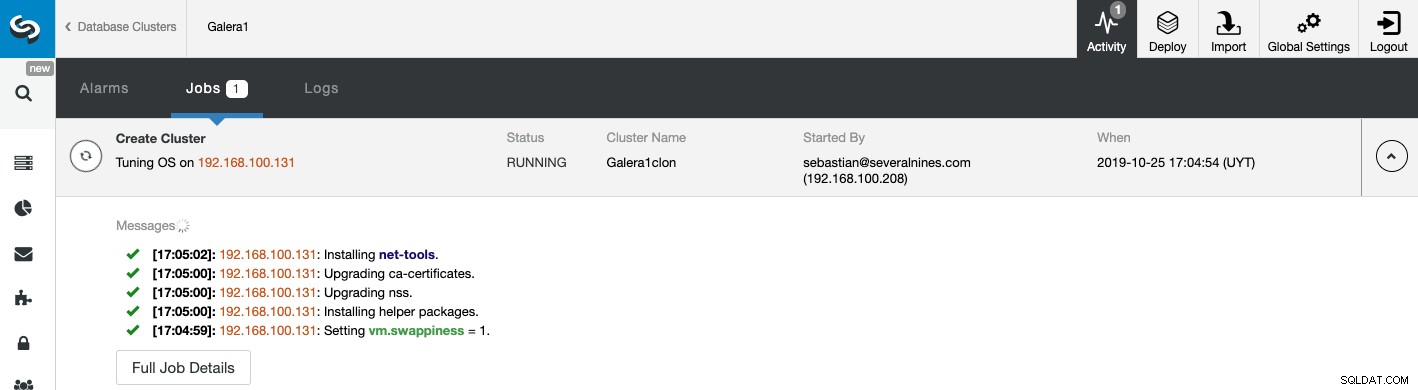
Puede monitorear el estado de la creación de su nuevo Slave Cluster desde el Monitor de actividad de ClusterControl. Una vez finalizada la tarea, puede ver el clúster en la pantalla principal de ClusterControl.
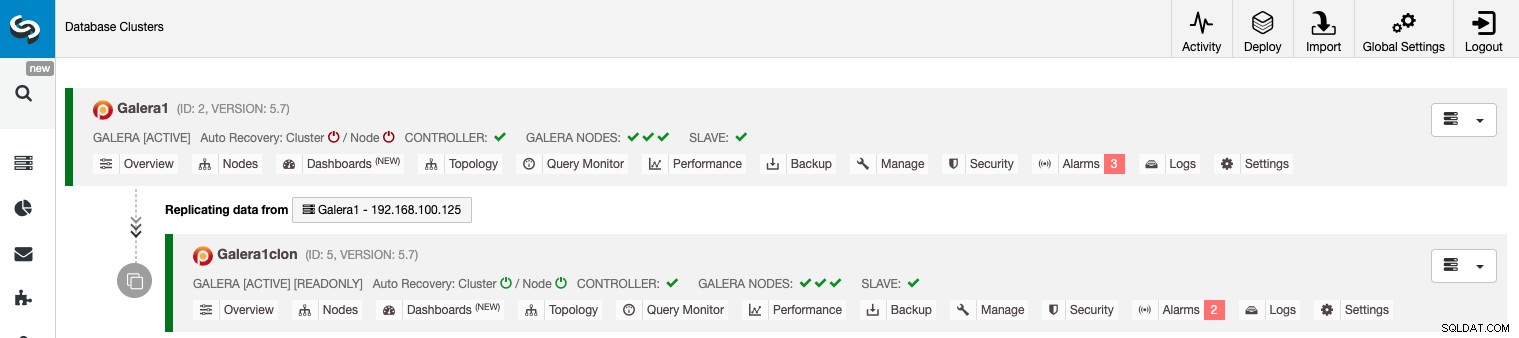
Gestión de la replicación de clúster a clúster mediante la GUI de ClusterControl
Ahora que tiene su replicación de clúster a clúster en funcionamiento, hay diferentes acciones para realizar en esta topología usando ClusterControl.
Configurar clústeres activo-activo
Como puede ver, de forma predeterminada, el clúster esclavo está configurado en modo de solo lectura. Es posible deshabilitar el indicador de solo lectura en los nodos uno por uno desde la interfaz de usuario de ClusterControl, pero tenga en cuenta que la agrupación en clústeres Activo-Activo solo se recomienda si las aplicaciones solo tocan conjuntos de datos separados en cualquiera de los clústeres, ya que MySQL/MariaDB no lo hace. ofrecer cualquier Detección o Resolución de Conflictos.
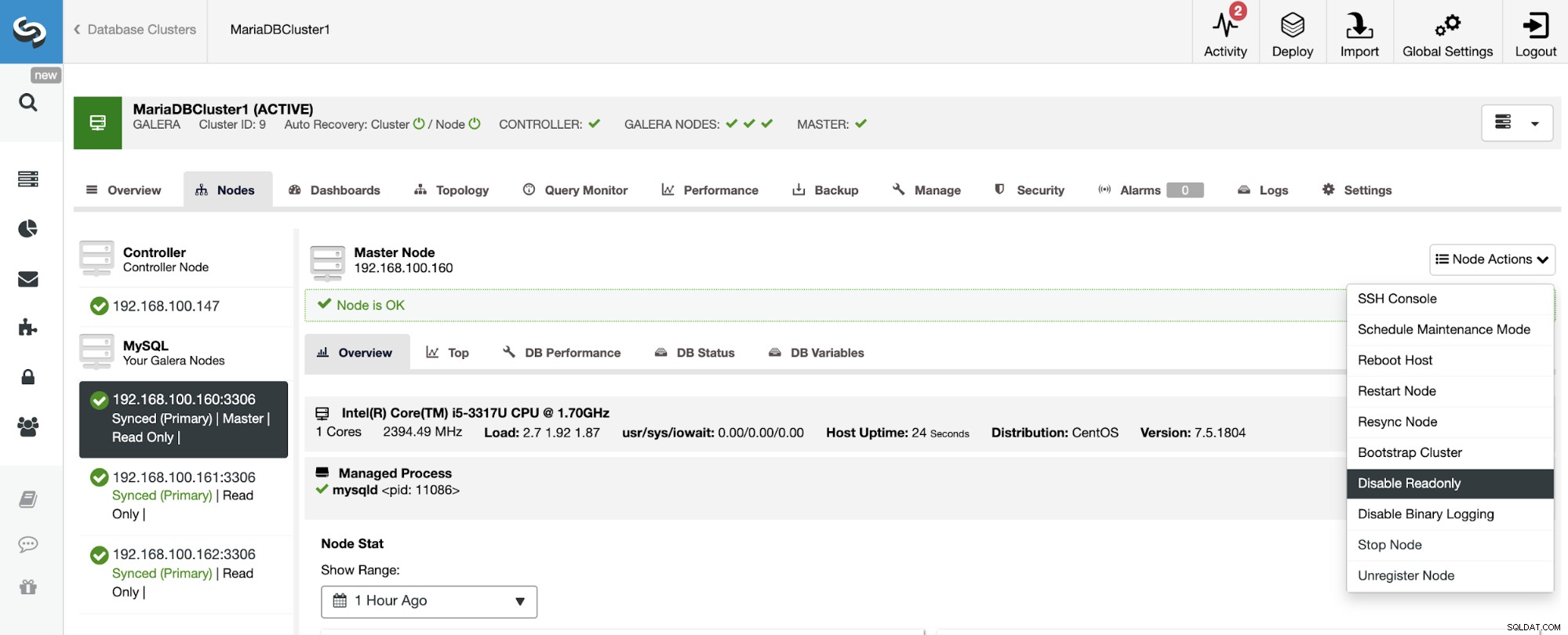
Para deshabilitar el modo de solo lectura, vaya a ClusterControl -> Seleccionar esclavo Clúster -> Nodos. En esta sección, seleccione cada nodo y use la opción Deshabilitar solo lectura.
Reconstrucción de un clúster esclavo
Para evitar inconsistencias, si desea reconstruir un clúster esclavo, debe ser un clúster de solo lectura, lo que significa que todos los nodos deben estar en modo de solo lectura.
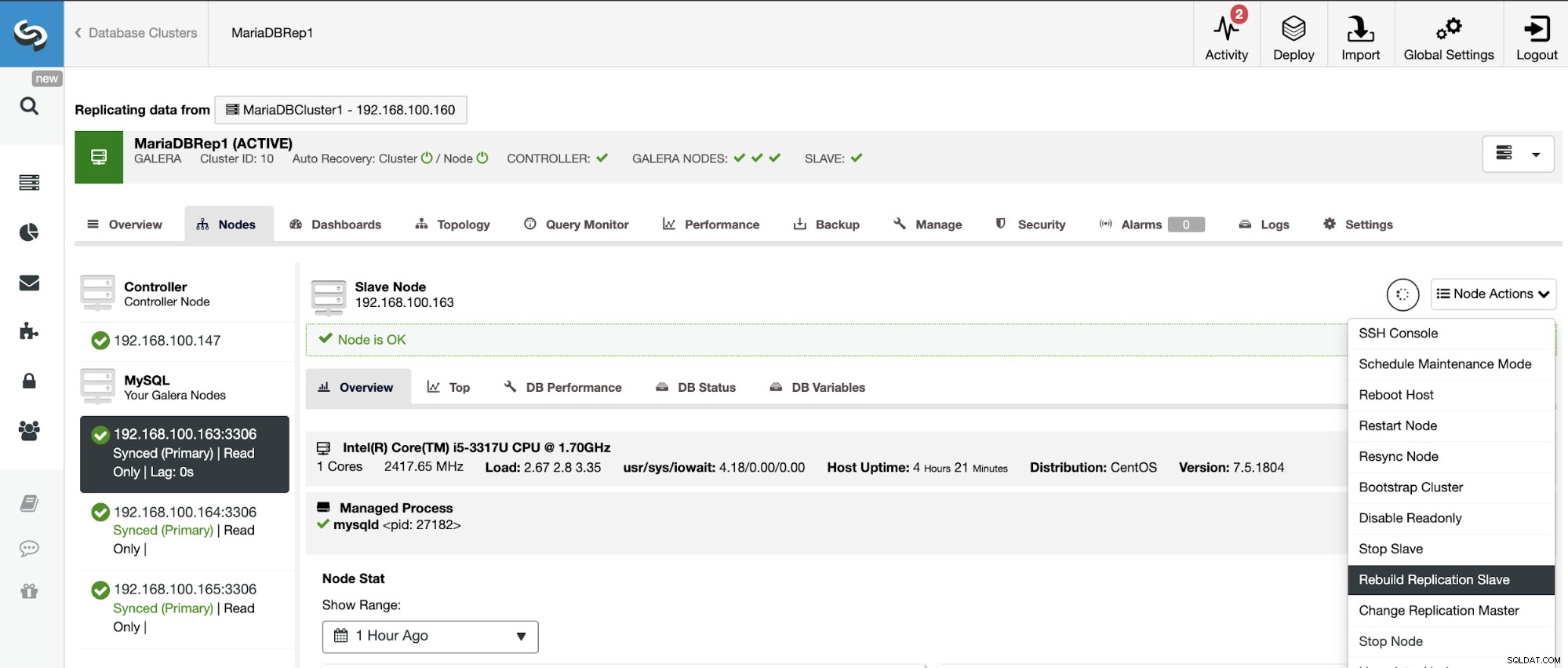
Vaya a ClusterControl -> Seleccione Clúster esclavo -> Nodos -> Elija el Nodo conectado al clúster maestro -> Acciones de nodo -> Reconstruir esclavo de replicación.
Cambios de topología
Si tiene la siguiente topología:
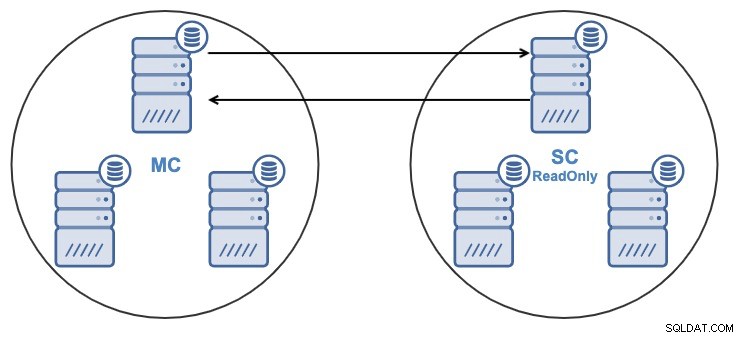
Y por alguna razón, desea cambiar el nodo de replicación en el Maestro Grupo. Es posible cambiar el nodo maestro utilizado por el Clúster Esclavo a otro nodo maestro en el Clúster Maestro.
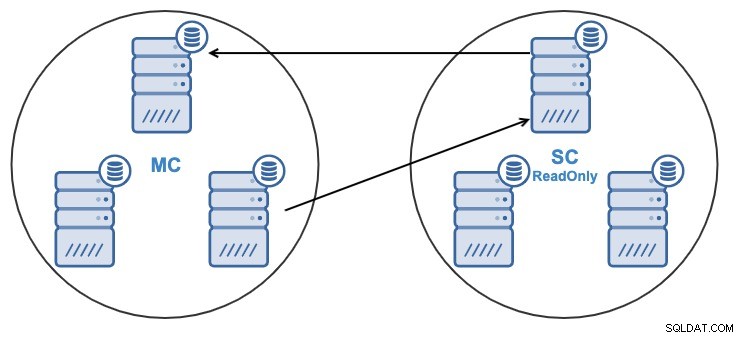
Para ser considerado como un nodo maestro, debe tener habilitado el registro binario .
Vaya a ClusterControl -> Seleccione Clúster esclavo -> Nodos -> Elija el Nodo conectado al clúster maestro -> Acciones de nodo -> Detener esclavo/Iniciar esclavo.
Detener/Iniciar esclavo de replicación
Puede detener e iniciar esclavos de replicación de una manera fácil usando ClusterControl.
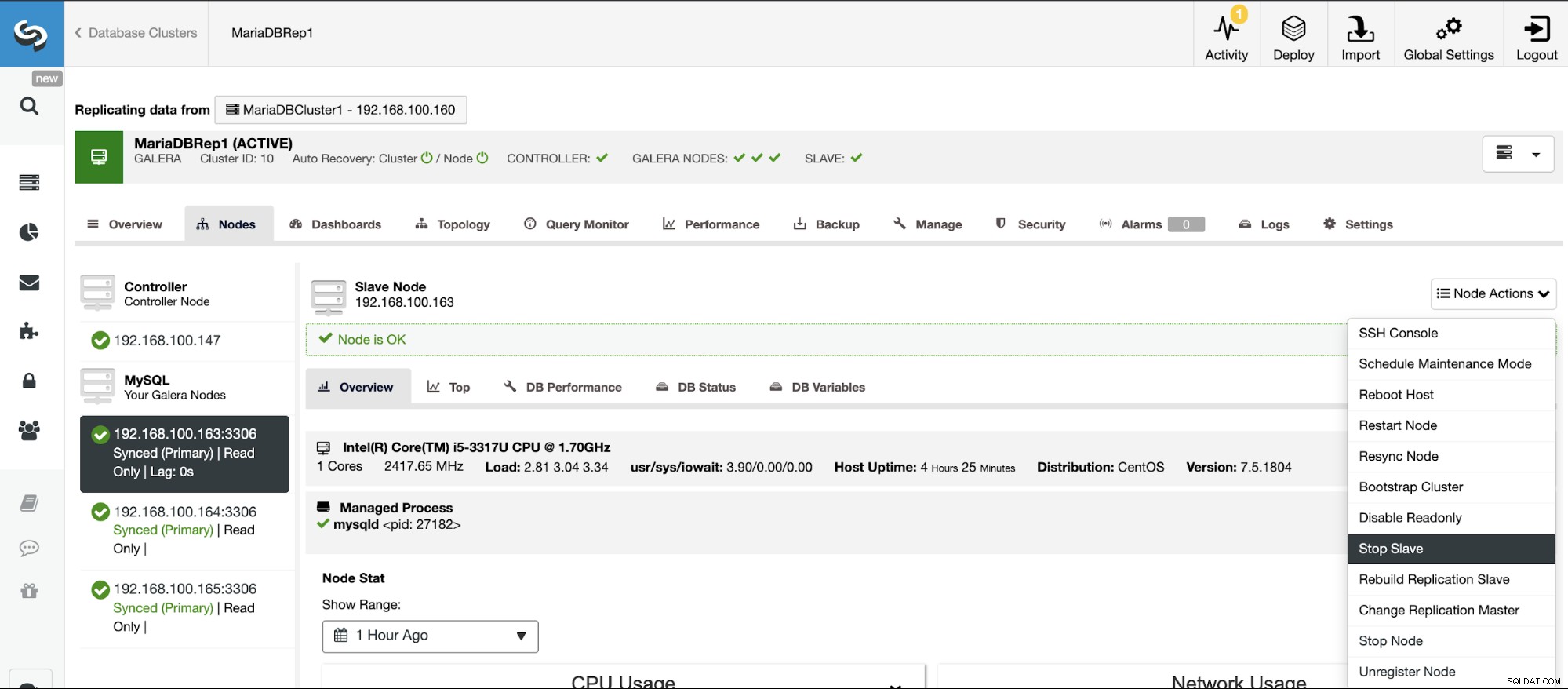
Vaya a ClusterControl -> Seleccione Clúster esclavo -> Nodos -> Elija el Nodo conectado al clúster maestro -> Acciones de nodo -> Detener esclavo/Iniciar esclavo.
Restablecer esclavo de replicación
Usando esta acción, puede reiniciar el proceso de replicación usando RESET SLAVE o RESET SLAVE ALL. La diferencia entre ellos es que RESET SLAVE no cambia ningún parámetro de replicación como el host maestro, el puerto y las credenciales. Para eliminar esta información, debe usar RESET SLAVE ALL que elimina toda la configuración de replicación, por lo que al usar este comando se destruirá el enlace de replicación de clúster a clúster.
Antes de usar esta función, debe detener el proceso de replicación (consulte la función anterior).
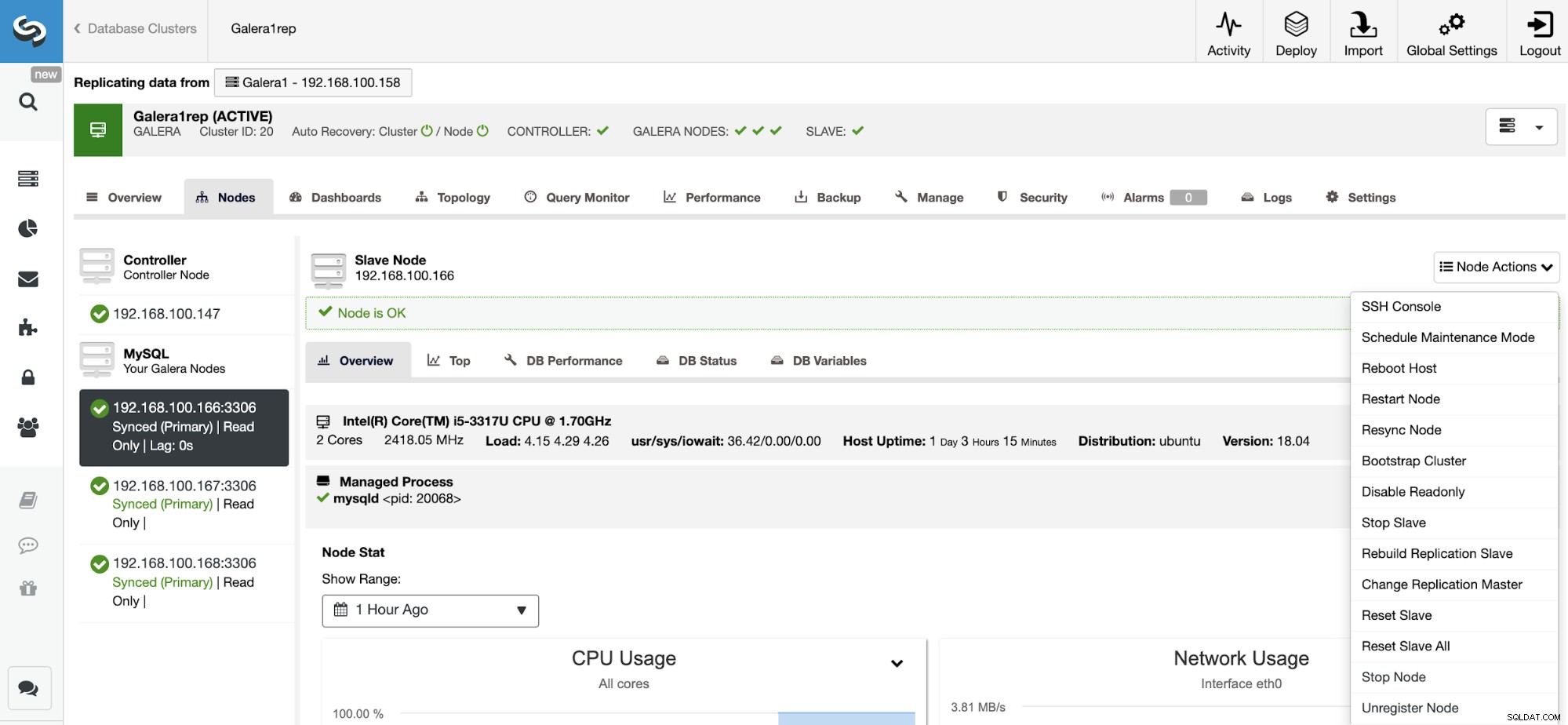
Vaya a ClusterControl -> Seleccione Clúster esclavo -> Nodos -> Elija el Nodo conectado al clúster maestro -> Acciones de nodo -> Restablecer esclavo/Restablecer esclavo todo.
Gestión de la replicación de clúster a clúster mediante la CLI de ClusterControl
En la sección anterior, pudo ver cómo administrar una replicación de clúster a clúster mediante la interfaz de usuario de ClusterControl. Ahora, veamos cómo hacerlo usando la línea de comando.
Nota:Como mencionamos al comienzo de este blog, asumiremos que tiene instalado ClusterControl y que Master Cluster se implementó usándolo.
Crear el clúster esclavo
Primero, veamos un comando de ejemplo para crear un clúster esclavo mediante la CLI de ClusterControl:
$ s9s cluster --create --cluster-name=Galera1rep --cluster-type=galera --provider-version=10.4 --nodes="192.168.100.166;192.168.100.167;192.168.100.168" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=root --db-admin-passwd=xxxxxxxx --vendor=mariadb --remote-cluster-id=11 --logAhora que tiene su proceso de creación de esclavos en ejecución, veamos cada parámetro utilizado:
- Cluster:para enumerar y manipular clústeres.
- Crear:crea e instala un nuevo clúster.
- Nombre del clúster:el nombre del nuevo clúster esclavo.
- Cluster-type:El tipo de clúster a instalar.
- Proveedor-version:La versión del software.
- Nodos:Lista de los nuevos nodos en el clúster esclavo.
- Os-user:El nombre de usuario para los comandos SSH.
- Os-key-file:el archivo de clave que se utilizará para la conexión SSH.
- Db-admin:El nombre de usuario del administrador de la base de datos.
- Db-admin-passwd:La contraseña para el administrador de la base de datos.
- Remote-cluster-id:ID de clúster maestro para la replicación de clúster a clúster.
- Registro:esperar y monitorear mensajes de trabajo.
Usando el indicador --log, podrá ver los registros en tiempo real:
Verifying job parameters.
Checking ssh/sudo on 3 hosts.
All 3 hosts are accessible by SSH.
192.168.100.166: Checking if host already exists in another cluster.
192.168.100.167: Checking if host already exists in another cluster.
192.168.100.168: Checking if host already exists in another cluster.
192.168.100.157:3306: Binary logging is enabled.
192.168.100.158:3306: Binary logging is enabled.
Creating the cluster with the following:
wsrep_cluster_address = 'gcomm://192.168.100.166,192.168.100.167,192.168.100.168'
Calling job: setupServer(192.168.100.166).
192.168.100.166: Checking OS information.
…
Caching config files.
Job finished, all the nodes have been added successfully.Configurar clústeres activo-activo
Como pudo ver anteriormente, puede deshabilitar el modo de solo lectura en el nuevo clúster al deshabilitarlo en cada nodo, así que veamos cómo hacerlo desde la línea de comandos.
$ s9s node --set-read-write --nodes="192.168.100.166" --cluster-id=16 --logVeamos cada parámetro:
- Nodo:Para manejar nodos.
- Establecer-lectura-escritura:establece el nodo en modo de lectura-escritura.
- Nodos:El nodo donde cambiarlo.
- Cluster-id:el ID del clúster en el que se encuentra el nodo.
Luego verás:
192.168.100.166:3306: Setting read_only=OFF.Reconstrucción de un clúster esclavo
Puede reconstruir un clúster esclavo con el siguiente comando:
$ s9s replication --stage --master="192.168.100.157:3306" --slave="192.168.100.166:3306" --cluster-id=19 --remote-cluster-id=11 --logLos parámetros son:
- Replicación:Para monitorear y controlar la replicación de datos.
- Etapa:etapa/reconstrucción de un esclavo de replicación.
- Maestro:el maestro de replicación en el clúster maestro.
- Esclavo:El esclavo de replicación en el clúster esclavo.
- Cluster-id:ID del clúster esclavo.
- Remote-cluster-id:El ID del clúster maestro.
- Registro:esperar y monitorear mensajes de trabajo.
El registro de trabajo debe ser similar a este:
Rebuild replication slave 192.168.100.166:3306 from master 192.168.100.157:3306.
Remote cluster id = 11
Shutting down Galera Cluster.
192.168.100.166:3306: Stopping node.
192.168.100.166:3306: Stopping mysqld (timeout=60, force stop after timeout=true).
192.168.100.166: Stopping MySQL service.
192.168.100.166: All processes stopped.
192.168.100.166:3306: Stopped node.
192.168.100.167:3306: Stopping node.
192.168.100.167:3306: Stopping mysqld (timeout=60, force stop after timeout=true).
192.168.100.167: Stopping MySQL service.
192.168.100.167: All processes stopped.
…
192.168.100.157:3306: Changing master to 192.168.100.166:3306.
192.168.100.157:3306: Changed master to 192.168.100.166:3306
192.168.100.157:3306: Starting slave.
192.168.100.157:3306: Collecting replication statistics.
192.168.100.157:3306: Started slave successfully.
192.168.100.166:3306: Starting node
Writing file '192.168.100.167:/etc/mysql/my.cnf'.
Writing file '192.168.100.167:/etc/mysql/secrets-backup.cnf'.
Writing file '192.168.100.168:/etc/mysql/my.cnf'.Cambios de topología
Puede cambiar su topología usando otro nodo en el Master Cluster desde el cual replicar los datos, por ejemplo, puede ejecutar:
$ s9s replication --failover --master="192.168.100.161:3306" --slave="192.168.100.163:3306" --cluster-id=10 --remote-cluster-id=9 --logVeamos los parámetros usados.
- Replicación:Para monitorear y controlar la replicación de datos.
- Failover:Asuma el rol de maestro de un maestro fallido/antiguo.
- Master:El nuevo maestro de replicación en el Master Cluster.
- Esclavo:El esclavo de replicación en el clúster esclavo.
- Cluster-id:El ID del clúster esclavo.
- Remote-Cluster-id:ID del clúster maestro.
- Registro:esperar y monitorear mensajes de trabajo.
Verá este registro:
192.168.100.161:3306 belongs to cluster id 9.
192.168.100.163:3306: Changing master to 192.168.100.161:3306
192.168.100.163:3306: My master is 192.168.100.160:3306.
192.168.100.161:3306: Sanity checking replication master '192.168.100.161:3306[cid:9]' to be used by '192.168.100.163[cid:139814070386698]'.
192.168.100.161:3306: Executing GRANT REPLICATION SLAVE ON *.* TO 'cmon_replication'@'192.168.100.163'.
Setting up link between 192.168.100.161:3306 and 192.168.100.163:3306
192.168.100.163:3306: Stopping slave.
192.168.100.163:3306: Successfully stopped slave.
192.168.100.163:3306: Setting up replication using MariaDB GTID: 192.168.100.161:3306->192.168.100.163:3306.
192.168.100.163:3306: Changing Master using master_use_gtid=slave_pos.
192.168.100.163:3306: Changing master to 192.168.100.161:3306.
192.168.100.163:3306: Changed master to 192.168.100.161:3306
192.168.100.163:3306: Starting slave.
192.168.100.163:3306: Collecting replication statistics.
192.168.100.163:3306: Started slave successfully.
192.168.100.160:3306: Flushing logs to update 'SHOW SLAVE HOSTS'Detener/Iniciar esclavo de replicación
Puede detenerse para replicar los datos del Master Cluster de esta manera:
$ s9s replication --stop --slave="192.168.100.166:3306" --cluster-id=19 --logVerás esto:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Stopping slave.
192.168.100.166:3306: Successfully stopped slave.Y ahora, puedes empezarlo de nuevo:
$ s9s replication --start --slave="192.168.100.166:3306" --cluster-id=19 --logEntonces, verás:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Starting slave.
192.168.100.166:3306: Collecting replication statistics.
192.168.100.166:3306: Started slave successfully.Ahora, revisemos los parámetros usados.
- Replicación:Para monitorear y controlar la replicación de datos.
- Detener/Iniciar:Para hacer que el esclavo detenga/comience a replicar.
- Esclavo:el nodo esclavo de replicación.
- Cluster-id:el ID del clúster en el que se encuentra el nodo esclavo.
- Registro:esperar y monitorear mensajes de trabajo.
Restablecer esclavo de replicación
Usando este comando, puede reiniciar el proceso de replicación usando RESET SLAVE o RESET SLAVE ALL. Para obtener más información sobre este comando, verifique su uso en la sección anterior de la interfaz de usuario de ClusterControl.
Antes de usar esta función, debe detener el proceso de replicación (consulte el comando anterior).
RESTABLECER ESCLAVO:
$ s9s replication --reset --slave="192.168.100.166:3306" --cluster-id=19 --logEl registro debe ser como:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Executing 'RESET SLAVE'.
192.168.100.166:3306: Command 'RESET SLAVE' succeeded.RESTABLECER ESCLAVO TODO:
$ s9s replication --reset --force --slave="192.168.100.166:3306" --cluster-id=19 --logY este registro debe ser:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
192.168.100.166:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.Veamos los parámetros utilizados tanto para RESET SLAVE como para RESET SLAVE ALL.
- Replicación:Para monitorear y controlar la replicación de datos.
- Restablecer:restablecer el nodo esclavo.
- Fuerza:Al utilizar este indicador, usará el comando RESET SLAVE ALL en el nodo esclavo.
- Esclavo:el nodo esclavo de replicación.
- Cluster-id:ID del clúster esclavo.
- Registro:esperar y monitorear mensajes de trabajo.
Conclusión
Esta nueva característica de ClusterControl le permitirá crear una replicación de clúster a clúster rápidamente y administrarla de una manera fácil y amigable. Este entorno mejorará la topología de su base de datos/clúster y sería útil para un plan de recuperación ante desastres, un entorno de prueba e incluso más opciones mencionadas en el blog de descripción general.