La alta disponibilidad es imprescindible en estos días, ya que la mayoría de las organizaciones no pueden permitirse perder sus datos. Sin embargo, la alta disponibilidad siempre viene con una etiqueta de precio (que puede variar mucho). Cualquier configuración que requiera una acción casi inmediata generalmente requerirá un entorno costoso que refleje con precisión la configuración de producción. Pero, hay otras opciones que pueden ser menos costosas. Es posible que no permitan un cambio inmediato a un clúster de recuperación ante desastres, pero aun así permitirán la continuidad del negocio (y no agotarán el presupuesto).
Un ejemplo de este tipo de configuración es un entorno DR de "espera en frío". Le permite reducir sus gastos sin dejar de poder poner en marcha un nuevo entorno en una ubicación externa en caso de que ocurra un desastre. En esta publicación de blog, demostraremos cómo crear una configuración de este tipo.
La configuración inicial
Supongamos que tenemos una configuración de replicación de MySQL maestro/esclavo bastante estándar en nuestro propio centro de datos. Es una configuración de alta disponibilidad con ProxySQL y Keepalived para el manejo de IP virtual. El principal riesgo es que el centro de datos no esté disponible. Es un DC pequeño, tal vez solo sea un ISP sin BGP implementado. Y en esta situación, supondremos que si llevaría horas recuperar la base de datos, está bien siempre que sea posible recuperarla.
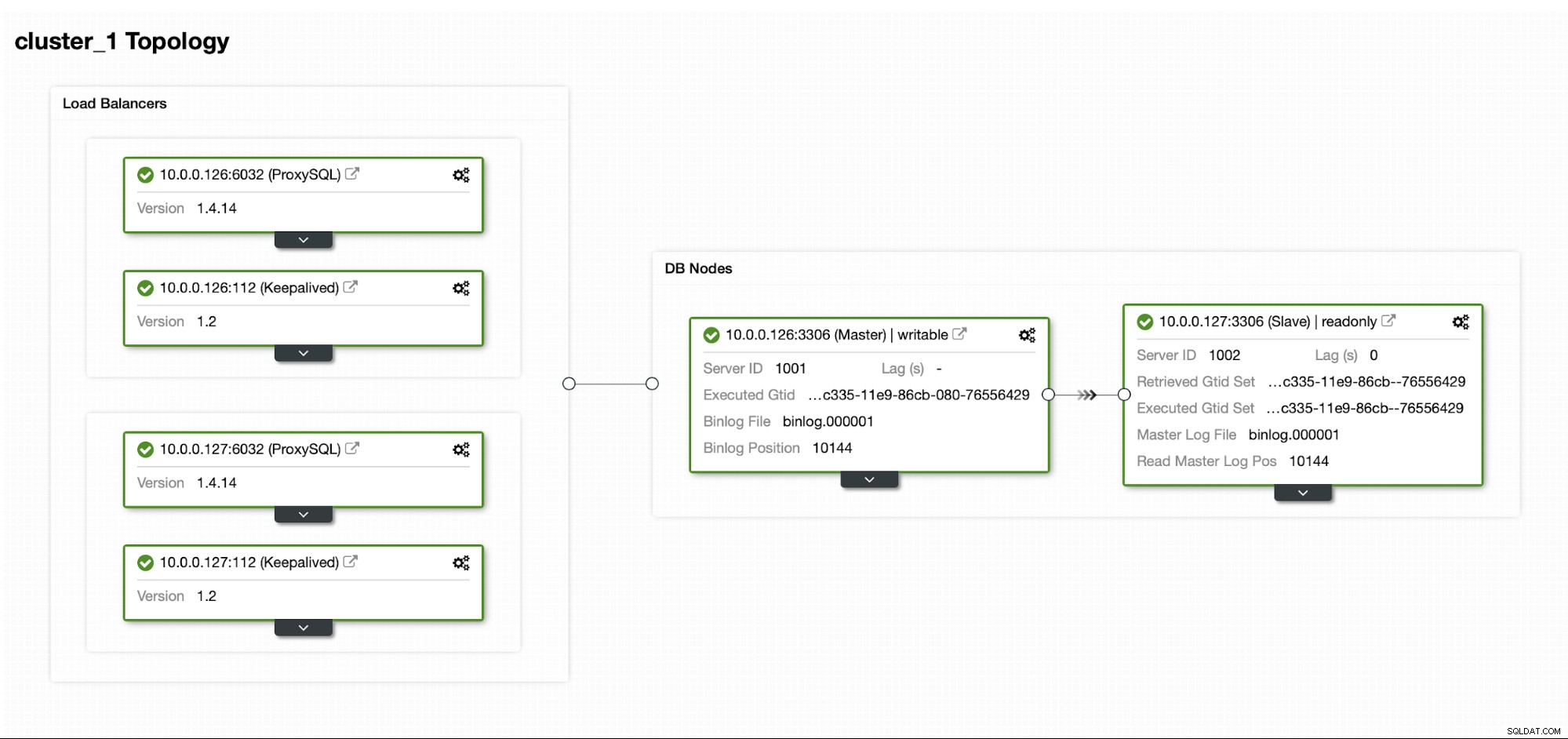
Para implementar este clúster, usamos ClusterControl, que puede descargar de forma gratuita. Para nuestro entorno DR, usaremos EC2 (pero también podría ser cualquier otro proveedor de nube).
El desafío
El problema principal con el que tenemos que lidiar es cómo debemos asegurarnos de tener datos nuevos para restaurar nuestra base de datos en el entorno de recuperación ante desastres. Por supuesto, lo ideal sería tener un esclavo de replicación funcionando en EC2... pero luego tenemos que pagarlo. Si estamos ajustados al presupuesto, podríamos intentar evitarlo con copias de seguridad. Esta no es la solución perfecta ya que, en el peor de los casos, nunca podremos recuperar todos los datos.
Por "el peor de los casos" nos referimos a una situación en la que no tendremos acceso a los servidores de la base de datos original. Si pudiéramos llegar a ellos, los datos no se habrían perdido.
La solución
Vamos a utilizar ClusterControl para configurar un programa de copia de seguridad para reducir la posibilidad de que se pierdan los datos. También usaremos la función ClusterControl para cargar copias de seguridad en la nube. Si el centro de datos no estará disponible, podemos esperar que el proveedor de la nube que hemos elegido esté accesible.
Configuración del programa de copia de seguridad en ClusterControl
Primero, tendremos que configurar ClusterControl con nuestras credenciales de nube.
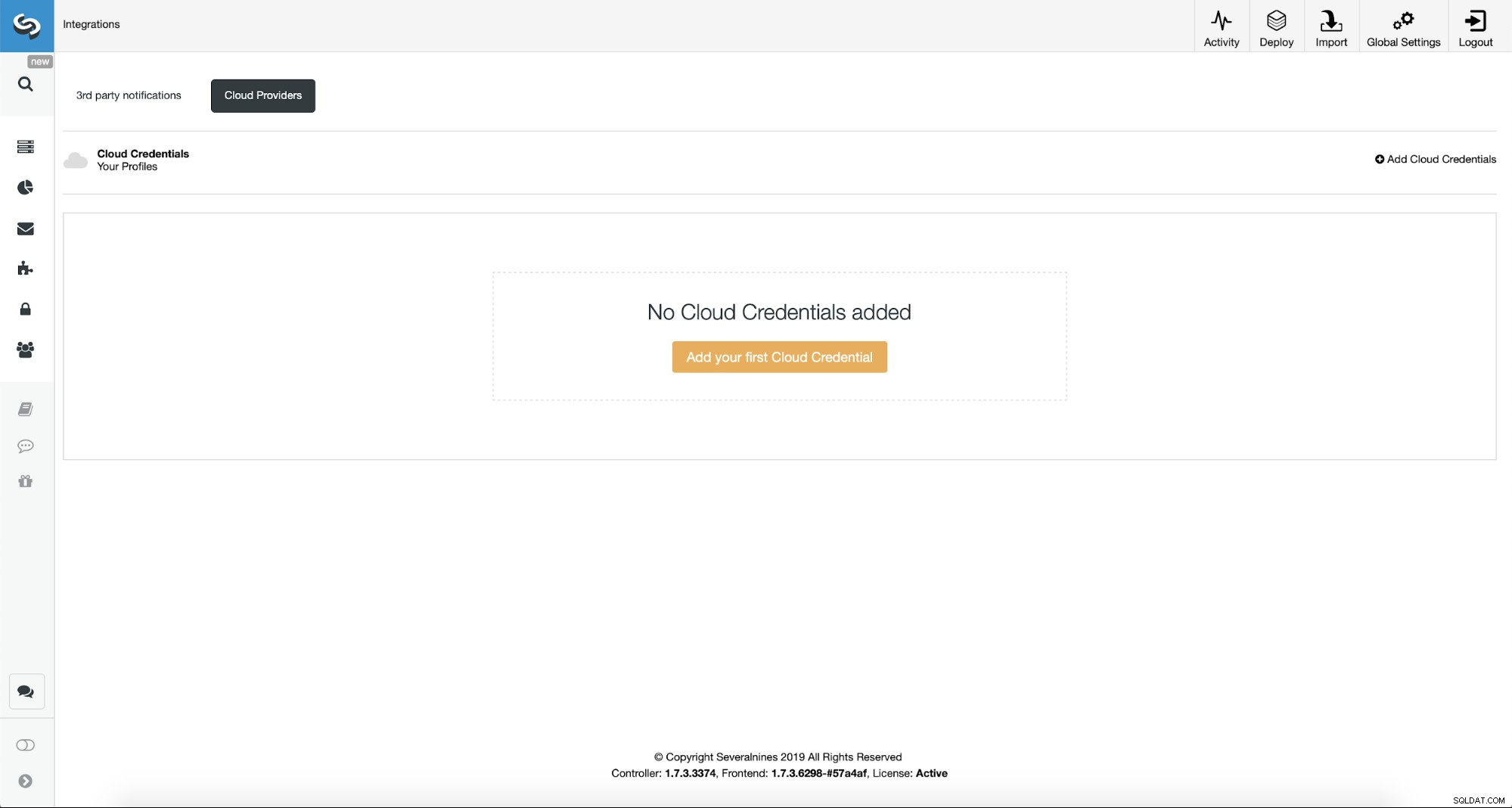
Podemos hacer esto usando "Integraciones" en el menú del lado izquierdo.
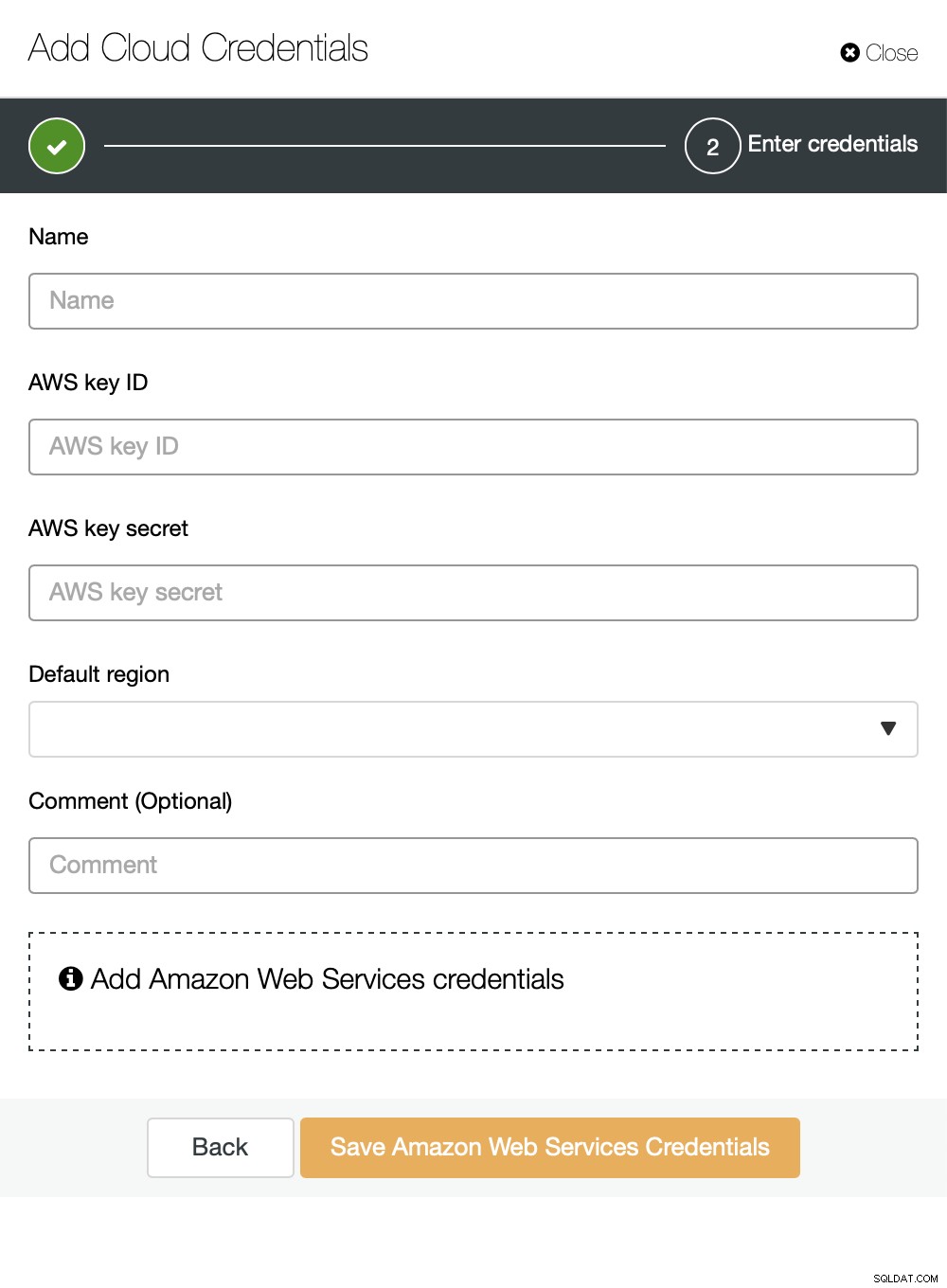
Puede elegir Amazon Web Services, Google Cloud o Microsoft Azure como la nube en el que desea que ClusterControl cargue las copias de seguridad. Continuaremos con AWS, donde ClusterControl usará S3 para almacenar copias de seguridad.
Luego necesitamos pasar el ID de clave y el secreto de clave, elegir la región predeterminada y elija un nombre para este conjunto de credenciales.
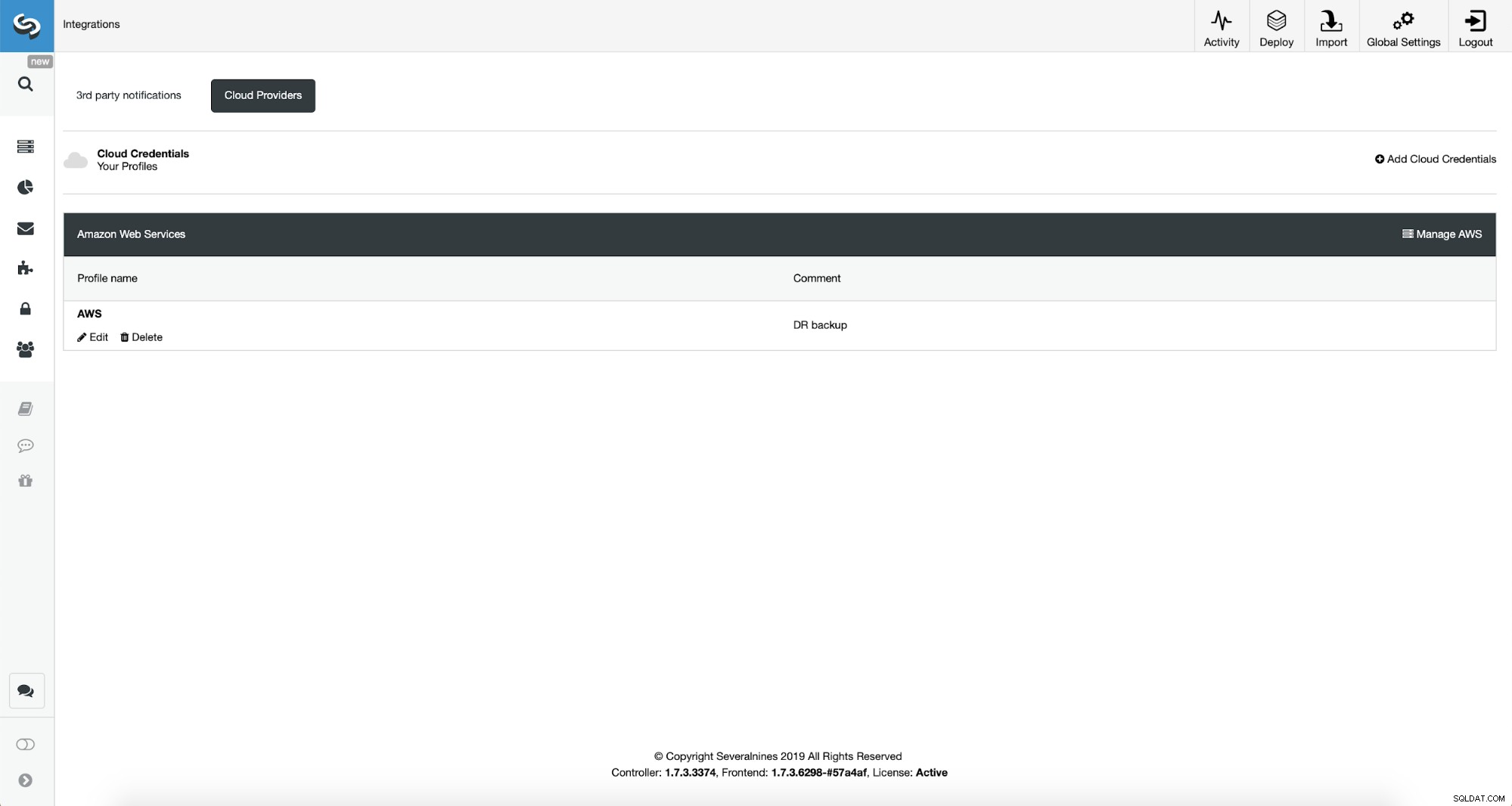
Una vez hecho esto, podemos ver las credenciales que acabamos de agregar enumeradas en Control de clúster.
Ahora, procederemos a configurar el programa de copia de seguridad.
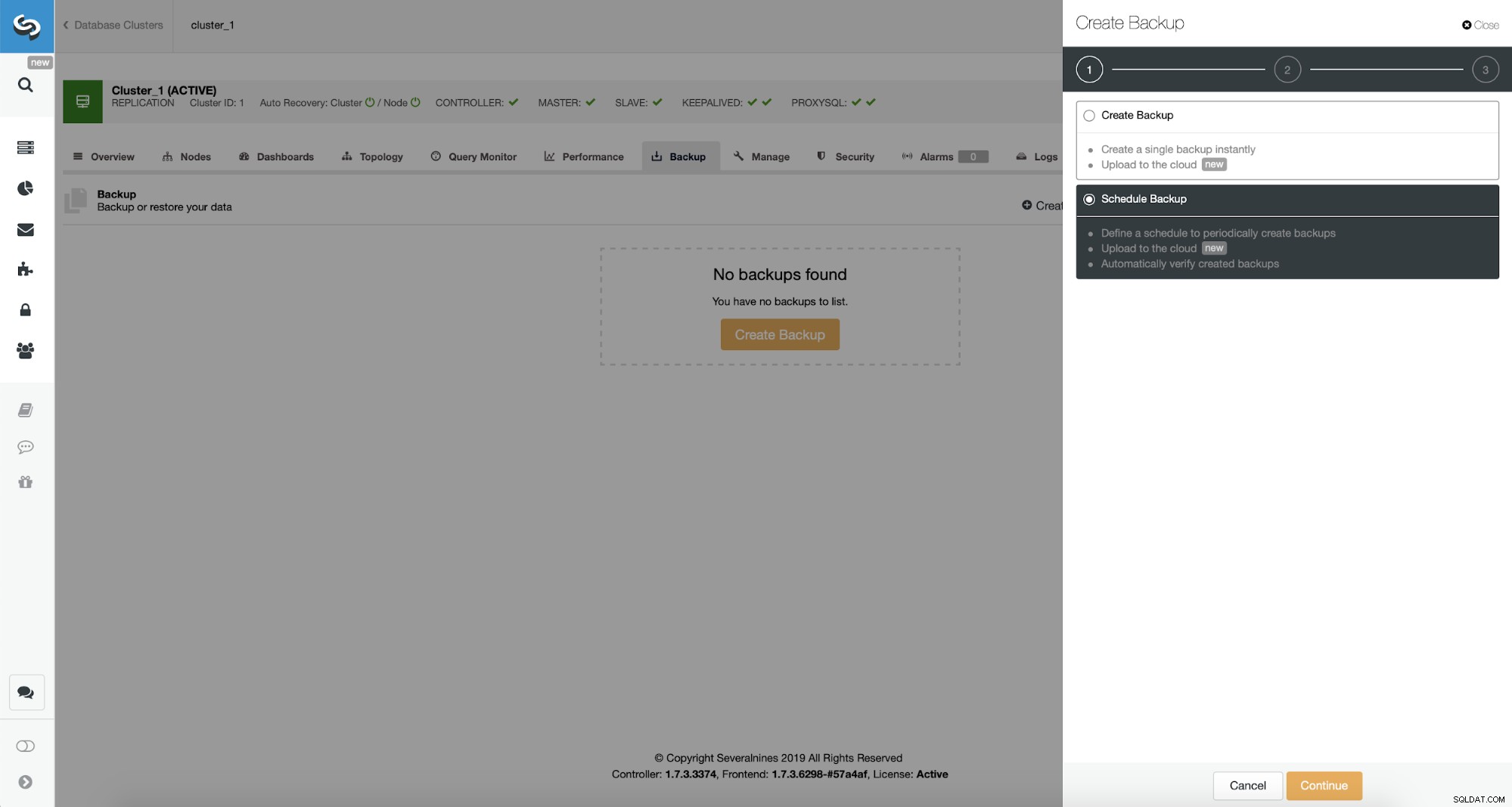
ClusterControl le permite crear una copia de seguridad inmediatamente o programarla. Iremos con la segunda opción. Lo que queremos es crear un horario siguiente:
- Copia de seguridad completa creada una vez al día
- Se crean copias de seguridad incrementales cada 10 minutos.
La idea aquí es la siguiente. En el peor de los casos, perderemos solo 10 minutos del tráfico. Si el centro de datos no está disponible desde el exterior pero funciona internamente, podemos intentar evitar cualquier pérdida de datos esperando 10 minutos, copiando la última copia de seguridad incremental en alguna computadora portátil y luego podemos enviarla manualmente a nuestra base de datos de recuperación ante desastres utilizando incluso conexión telefónica. y una conexión celular para sortear la falla del ISP. Si no podemos sacar los datos del antiguo centro de datos durante algún tiempo, esto tiene como objetivo minimizar la cantidad de transacciones que tendremos que fusionar manualmente en la base de datos DR.
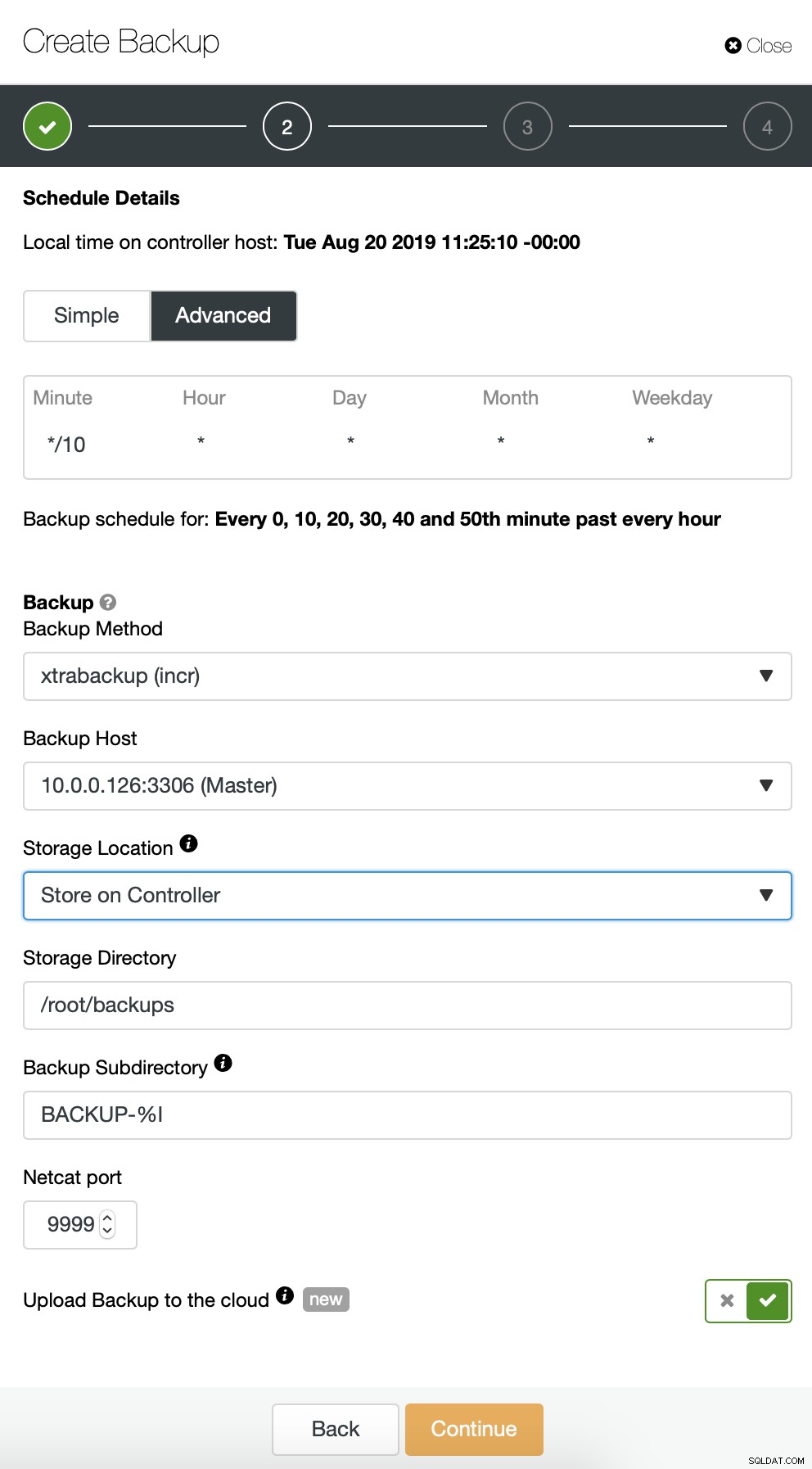
Comenzamos con una copia de seguridad completa que se realizará todos los días a las 2:00 am. Usaremos el maestro para tomar la copia de seguridad, la almacenaremos en el controlador en el directorio /root/backups/. También habilitaremos la opción "Subir copia de seguridad a la nube".
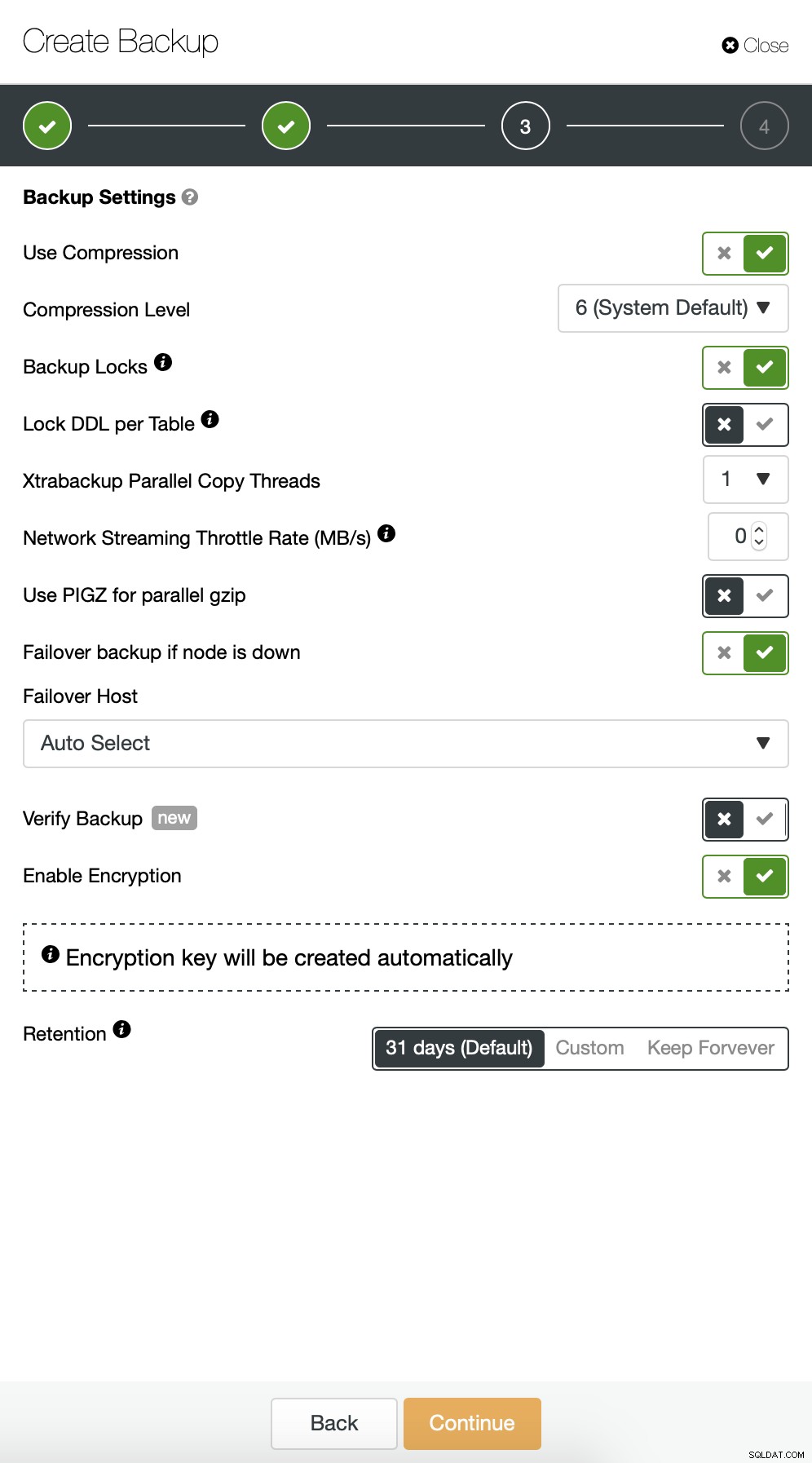
A continuación, queremos realizar algunos cambios en la configuración predeterminada. Decidimos ir con el host de conmutación por error seleccionado automáticamente (en caso de que nuestro maestro no esté disponible, ClusterControl usará cualquier otro nodo que esté disponible). También queríamos habilitar el cifrado, ya que enviaremos nuestras copias de seguridad a través de la red.
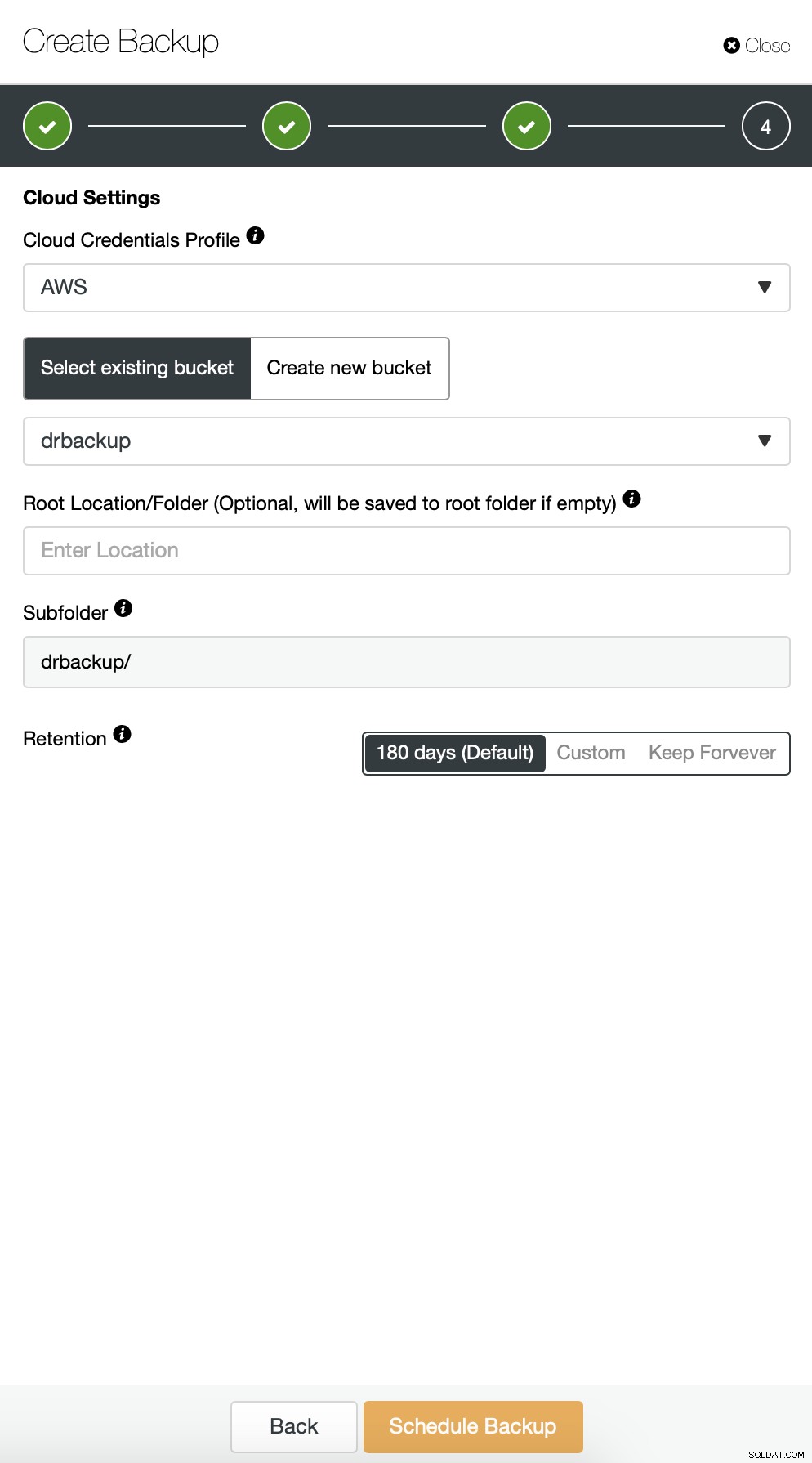
Luego tenemos que elegir las credenciales, seleccionar el depósito S3 existente o crear un uno nuevo si es necesario.
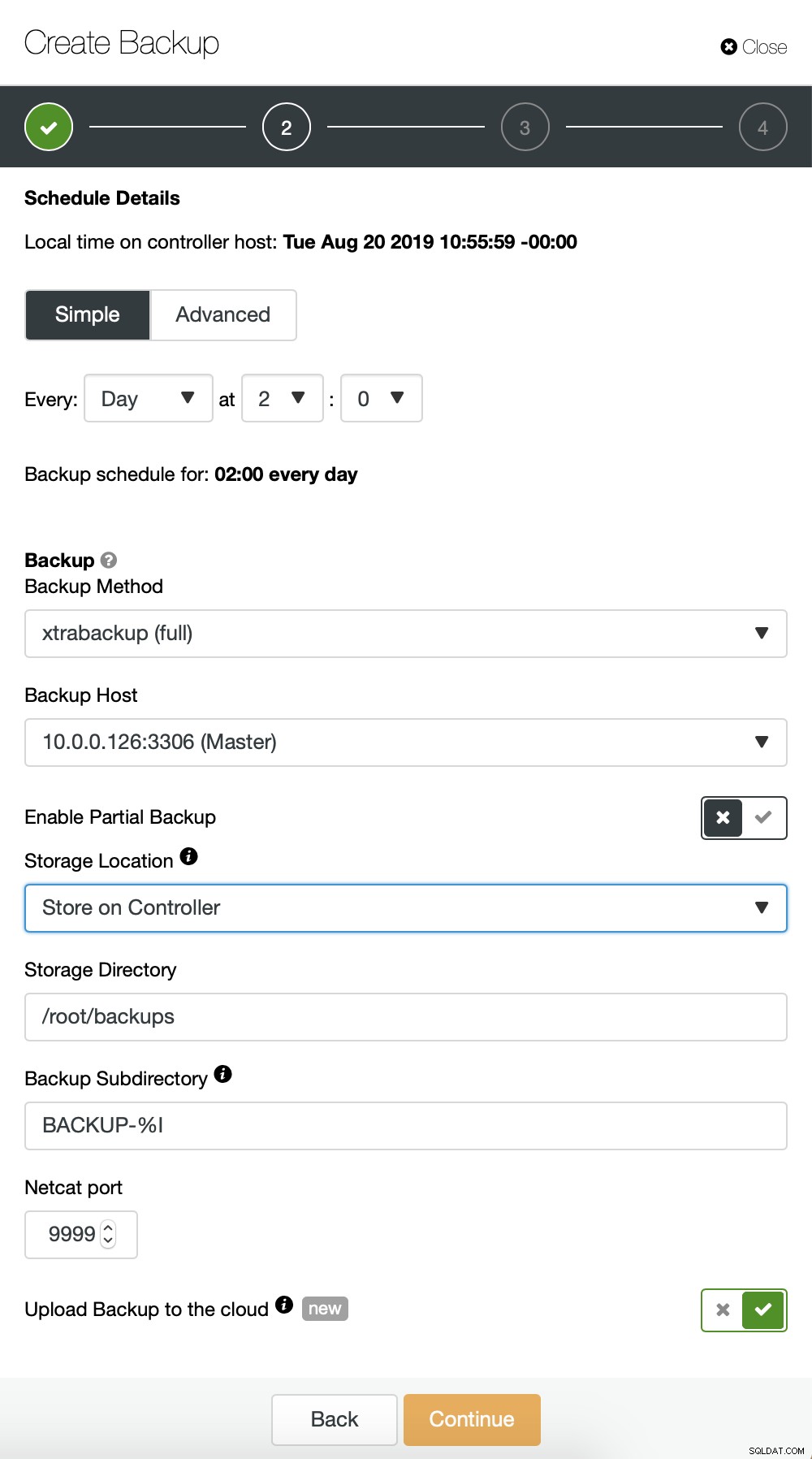
Básicamente estamos repitiendo el proceso para la copia de seguridad incremental, esta vez usamos el cuadro de diálogo "Avanzado" para ejecutar las copias de seguridad cada 10 minutos.
El resto de la configuración es similar, también podemos reutilizar el depósito S3.
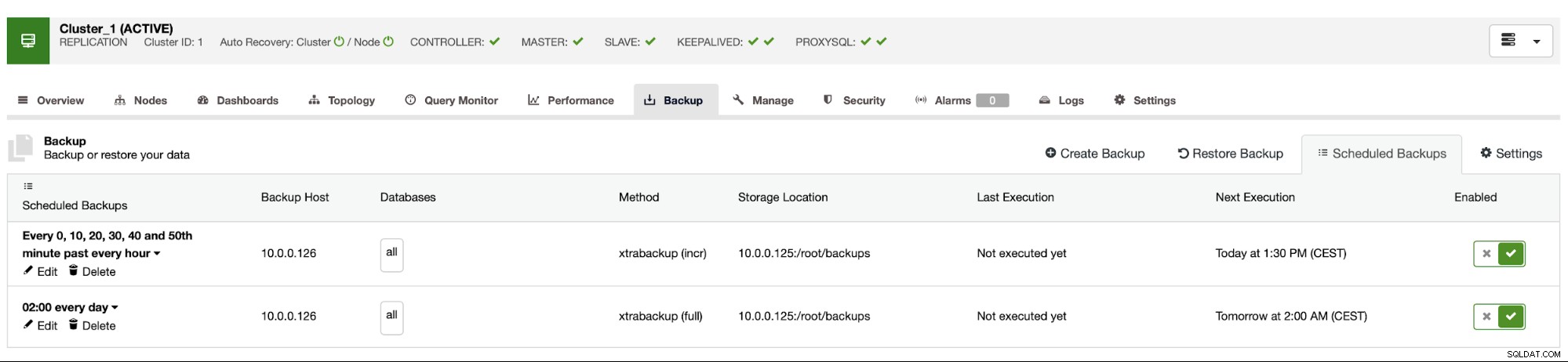
La programación de la copia de seguridad se ve como se muestra arriba. No tenemos que iniciar la copia de seguridad completa manualmente, ClusterControl ejecutará la copia de seguridad incremental según lo programado y si detecta que no hay una copia de seguridad completa disponible, ejecutará una copia de seguridad completa en lugar de la incremental.
Con tal configuración, podemos estar seguros de que podemos recuperar los datos en cualquier sistema externo con una granularidad de 10 minutos.
Restauración de copia de seguridad manual
Si sucede que necesitará restaurar la copia de seguridad en la instancia de recuperación ante desastres, hay un par de pasos que debe seguir. Recomendamos enfáticamente probar este proceso de vez en cuando, asegurándose de que funcione correctamente y que sea competente para ejecutarlo.
Primero, tenemos que instalar la herramienta de línea de comandos de AWS en nuestro servidor de destino:
example@sqldat.com:~# apt install python3-pip
example@sqldat.com:~# pip3 install awscli --upgrade --userLuego tenemos que configurarlo con las credenciales adecuadas:
example@sqldat.com:~# ~/.local/bin/aws configure
AWS Access Key ID [None]: yourkeyID
AWS Secret Access Key [None]: yourkeySecret
Default region name [None]: us-west-1
Default output format [None]: jsonAhora podemos probar si tenemos acceso a los datos en nuestro depósito S3:
example@sqldat.com:~# ~/.local/bin/aws s3 ls s3://drbackup/
PRE BACKUP-1/
PRE BACKUP-2/
PRE BACKUP-3/
PRE BACKUP-4/
PRE BACKUP-5/
PRE BACKUP-6/
PRE BACKUP-7/Ahora, tenemos que descargar los datos. Crearemos un directorio para las copias de seguridad; recuerde, tenemos que descargar todo el conjunto de copias de seguridad, desde una copia de seguridad completa hasta la última incremental que queremos aplicar.
example@sqldat.com:~# mkdir backups
example@sqldat.com:~# cd backups/Ahora hay dos opciones. Podemos descargar las copias de seguridad una por una:
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-1/ BACKUP-1 --recursive
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
Completed 30.4 MiB/36.2 MiB (4.9 MiB/s) with 1 file(s) remaining
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-2/ BACKUP-2 --recursive
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256También podemos, especialmente si tiene un cronograma de rotación ajustado, sincronizar todo el contenido del depósito con lo que tenemos localmente en el servidor:
example@sqldat.com:~/backups# ~/.local/bin/aws s3 sync s3://drbackup/ .
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-4/cmon_backup.metadata to BACKUP-4/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/cmon_backup.metadata to BACKUP-3/cmon_backup.metadata
download: s3://drbackup/BACKUP-6/cmon_backup.metadata to BACKUP-6/cmon_backup.metadata
download: s3://drbackup/BACKUP-5/cmon_backup.metadata to BACKUP-5/cmon_backup.metadata
download: s3://drbackup/BACKUP-7/cmon_backup.metadata to BACKUP-7/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 to BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256
download: s3://drbackup/BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256 to BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256 to BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256 to BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256 to BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256Como recordará, las copias de seguridad están encriptadas. Tenemos que tener una clave de cifrado que se almacena en ClusterControl. Asegúrese de tener su copia almacenada en un lugar seguro, fuera del centro de datos principal. Si no puede alcanzarlo, no podrá descifrar las copias de seguridad. La clave se puede encontrar en la configuración de ClusterControl:
example@sqldat.com:~# grep backup_encryption_key /etc/cmon.d/cmon_1.cnf
backup_encryption_key='aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM='Está codificado usando base64, por lo tanto, primero debemos decodificarlo y almacenarlo en el archivo antes de que podamos comenzar a descifrar la copia de seguridad:
echo "aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM=" | openssl enc -base64 -d> pasar
Ahora podemos reutilizar este archivo para descifrar las copias de seguridad. Por ahora, digamos que haremos una copia de seguridad completa y dos incrementales.
mkdir 1
mkdir 2
mkdir 3
cat BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/1/
cat BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/2/
cat BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/3/Tenemos los datos descifrados, ahora debemos continuar con la configuración de nuestro servidor MySQL. Idealmente, esta debería ser exactamente la misma versión que en los sistemas de producción. Usaremos Percona Server para MySQL:
cd ~
wget https://repo.percona.com/apt/percona-release_latest.generic_all.deb
sudo dpkg -i percona-release_latest.generic_all.deb
apt-get update
apt-get install percona-server-5.7Nada complejo, solo una instalación regular. Una vez que esté activo y listo, debemos detenerlo y eliminar el contenido de su directorio de datos.
service mysql stop
rm -rf /var/lib/mysql/*Para restaurar la copia de seguridad, necesitaremos Xtrabackup, una herramienta que CC usa para crearla (al menos para Perona y Oracle MySQL, MariaDB usa MariaBackup). Es importante que esta herramienta esté instalada en la misma versión que en los servidores de producción:
apt install percona-xtrabackup-24Eso es todo lo que tenemos que preparar. Ahora podemos comenzar a restaurar la copia de seguridad. Con las copias de seguridad incrementales, es importante tener en cuenta que debe prepararlas y aplicarlas sobre la copia de seguridad base. La copia de seguridad base también debe estar preparada. Es crucial ejecutar la preparación con la opción '--apply-log-only' para evitar que xtrabackup ejecute la fase de reversión. De lo contrario, no podrá aplicar la siguiente copia de seguridad incremental.
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/ --incremental-dir=/root/backups/2/
xtrabackup --prepare --target-dir=/root/backups/1/ --incremental-dir=/root/backups/3/En el último comando, permitimos que xtrabackup ejecutara la reversión de las transacciones no completadas; no aplicaremos más copias de seguridad incrementales después. Ahora es el momento de llenar el directorio de datos con la copia de seguridad, iniciar MySQL y ver si todo funciona como se esperaba:
example@sqldat.com:~/backups# mv /root/backups/1/* /var/lib/mysql/
example@sqldat.com:~/backups# chown -R mysql.mysql /var/lib/mysql
example@sqldat.com:~/backups# service mysql start
example@sqldat.com:~/backups# mysql -ppass
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 6
Server version: 5.7.26-29 Percona Server (GPL), Release '29', Revision '11ad961'
Copyright (c) 2009-2019 Percona LLC and/or its affiliates
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show schemas;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| proxydemo |
| sbtest |
| sys |
+--------------------+
6 rows in set (0.00 sec)
mysql> select count(*) from sbtest.sbtest1;
+----------+
| count(*) |
+----------+
| 10506 |
+----------+
1 row in set (0.01 sec)Como puede ver, todo está bien. MySQL se inició correctamente y pudimos acceder a él (¡y los datos están allí!). Logramos con éxito que nuestra base de datos volviera a funcionar en una ubicación separada. El tiempo total requerido depende estrictamente del tamaño de los datos:tuvimos que descargar los datos de S3, descifrarlos y descomprimirlos y, finalmente, preparar la copia de seguridad. Aún así, esta es una opción muy económica (solo tiene que pagar por los datos de S3) que le brinda una opción para la continuidad del negocio en caso de que ocurra un desastre.