La carga de trabajo de la base de datos MySQL está determinada por la cantidad de consultas que procesa. Hay varias situaciones en las que se puede originar la lentitud de MySQL. La primera posibilidad es si hay consultas que no utilizan la indexación adecuada. Cuando una consulta no puede hacer uso de un índice, el servidor MySQL tiene que usar más recursos y tiempo para procesar esa consulta. Al monitorear las consultas, tiene la capacidad de identificar el código SQL que es la causa raíz de una ralentización y solucionarlo antes de que el rendimiento general se degrade.
En esta publicación de blog, destacaremos la función Query Outlier disponible en ClusterControl y veremos cómo puede ayudarnos a mejorar el rendimiento de la base de datos. En general, ClusterControl realiza el muestreo de consultas de MySQL de dos formas:
- Obtener las consultas del esquema de rendimiento (recomendado ).
- Analice el contenido de MySQL Slow Query.
Si el esquema de rendimiento está deshabilitado, ClusterControl utilizará de forma predeterminada el registro de consulta lenta. Para obtener más información sobre cómo ClusterControl realiza esto, consulte esta publicación de blog, Cómo usar el Monitor de consulta de ClusterControl para MySQL, MariaDB y Percona Server.
¿Qué son los valores atípicos de consulta?
Un valor atípico es una consulta que lleva más tiempo que el tiempo de consulta normal de ese tipo. No tome esto literalmente como consultas "mal escritas". Debe tratarse como posibles consultas comunes subóptimas que podrían mejorarse. Después de varias muestras y cuando ClusterControl ha tenido suficientes estadísticas, puede determinar si la latencia es más alta de lo normal (2 sigmas + promedio_tiempo_de_consulta), entonces es un valor atípico y se agregará a Query Outlier.
Esta función depende de la función Consultas principales. Si el monitoreo de consultas está habilitado y las consultas principales se capturan y completan, los valores atípicos de consultas los resumirán y proporcionarán un filtro basado en la marca de tiempo. Para ver la lista de consultas que requieren atención, vaya a ClusterControl -> Query Monitor -> Query Outliers y debería ver algunas consultas en la lista (si las hay):
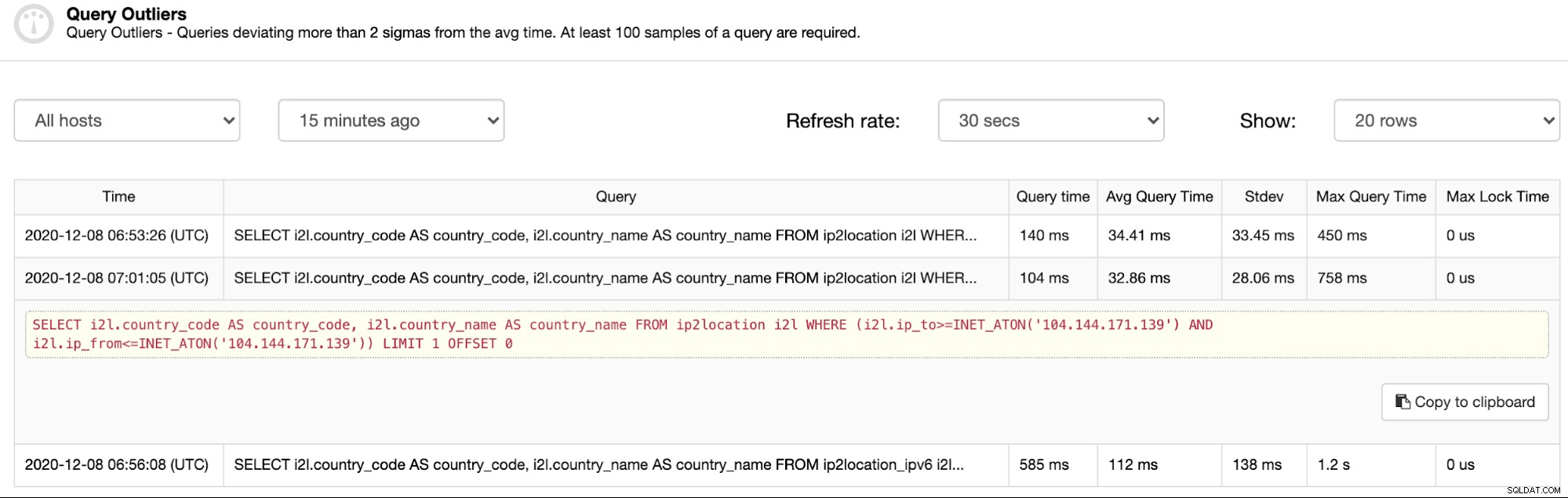
Como puede ver en la captura de pantalla anterior, los valores atípicos son básicamente consultas que tomó al menos 2 veces más que el tiempo promedio de consulta. Primero, la primera entrada, el tiempo promedio es de 34,41 ms, mientras que el tiempo de consulta del valor atípico es de 140 ms (más de 2 veces mayor que el tiempo promedio). De manera similar, para las próximas entradas, las columnas Tiempo de consulta y Tiempo promedio de consulta son dos cosas importantes para justificar los resultados destacados de una consulta atípica en particular.
Es relativamente fácil encontrar un patrón de un valor atípico de una consulta en particular observando un período de tiempo mayor, como hace una semana, como se destaca en la siguiente captura de pantalla:
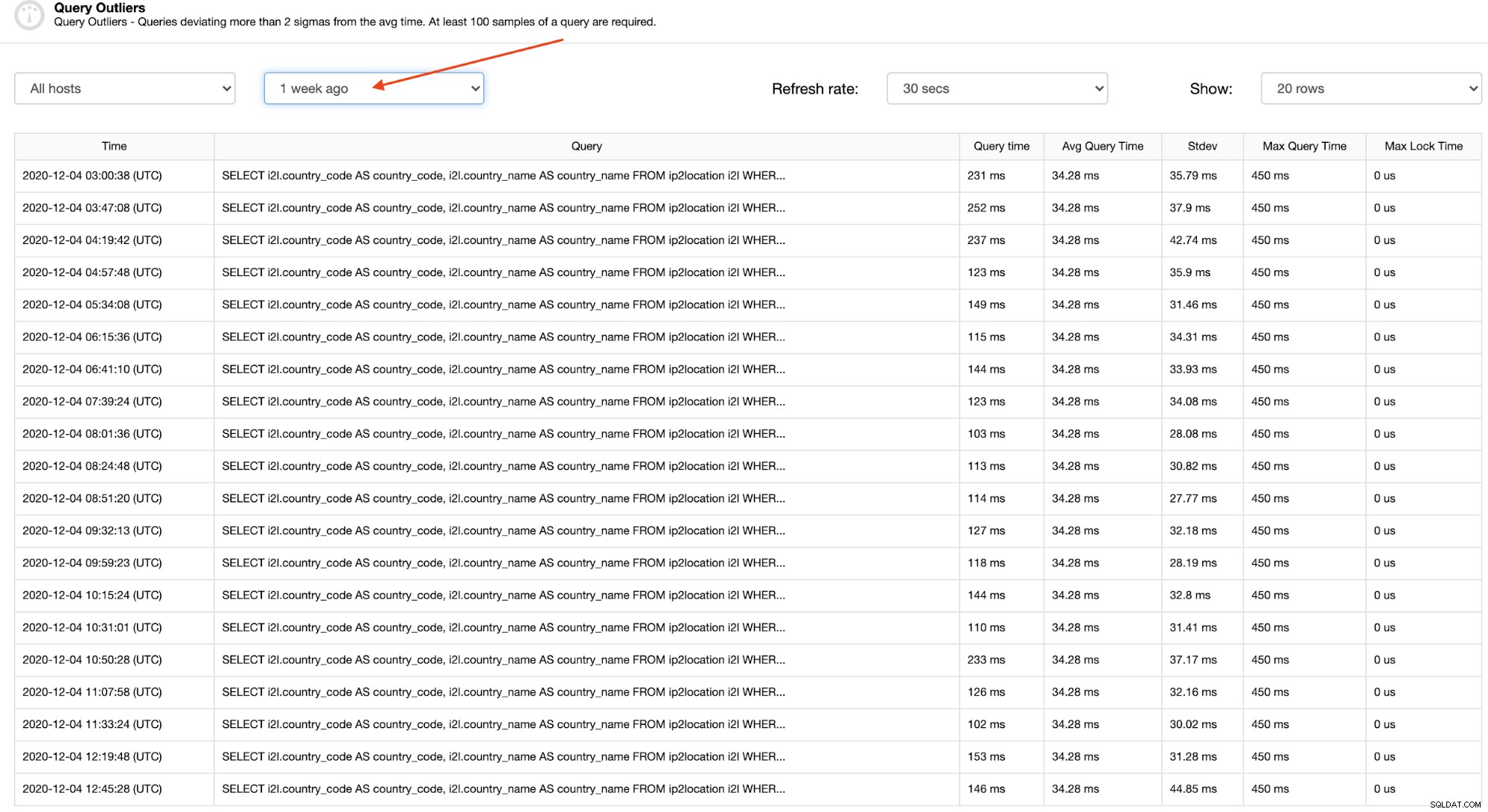
Al hacer clic en cada fila, puede ver la consulta completa que es realmente útil para identificar y comprender el problema, como se muestra en la siguiente sección.
Corregir los valores atípicos de la consulta
Para corregir los valores atípicos, debemos comprender la naturaleza de la consulta, el motor de almacenamiento de las tablas, la versión de la base de datos, el tipo de agrupación y el impacto de la consulta. En algunos casos, la consulta de valores atípicos no degrada realmente el rendimiento general de la base de datos. Como en este ejemplo, hemos visto que la consulta se ha destacado durante toda la semana y fue el único tipo de consulta que se capturó, por lo que probablemente sea una buena idea corregir o mejorar esta consulta si es posible.
Como en nuestro caso, la consulta atípica es:
SELECT i2l.country_code AS country_code, i2l.country_name AS country_name
FROM ip2location i2l
WHERE (i2l.ip_to >= INET_ATON('104.144.171.139')
AND i2l.ip_from <= INET_ATON('104.144.171.139'))
LIMIT 1
OFFSET 0;Y el resultado de la consulta es:
+--------------+---------------+
| country_code | country_name |
+--------------+---------------+
| US | United States |
+--------------+---------------+Usando EXPLAIN
La consulta es una consulta de selección de rango de solo lectura para determinar la información de ubicación geográfica del usuario (código de país y nombre de país) para una dirección IP en la tabla ip2location. El uso de la instrucción EXPLAIN puede ayudarnos a comprender el plan de ejecución de la consulta:
mysql> EXPLAIN SELECT i2l.country_code AS country_code, i2l.country_name AS country_name
FROM ip2location i2l
WHERE (i2l.ip_to>=INET_ATON('104.144.171.139')
AND i2l.ip_from<=INET_ATON('104.144.171.139'))
LIMIT 1 OFFSET 0;
+----+-------------+-------+------------+-------+--------------------------------------+-------------+---------+------+-------+----------+------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+--------------------------------------+-------------+---------+------+-------+----------+------------------------------------+
| 1 | SIMPLE | i2l | NULL | range | idx_ip_from,idx_ip_to,idx_ip_from_to | idx_ip_from | 5 | NULL | 66043 | 50.00 | Using index condition; Using where |
+----+-------------+-------+------------+-------+--------------------------------------+-------------+---------+------+-------+----------+------------------------------------+La consulta se ejecuta con un escaneo de rango en la tabla usando el índice idx_ip_from con 50% de filas potenciales (filtradas).
Motor de almacenamiento adecuado
Mirando la estructura de la tabla de ip2location:
mysql> SHOW CREATE TABLE ip2location\G
*************************** 1. row ***************************
Table: ip2location
Create Table: CREATE TABLE `ip2location` (
`ip_from` int(10) unsigned DEFAULT NULL,
`ip_to` int(10) unsigned DEFAULT NULL,
`country_code` char(2) COLLATE utf8_bin DEFAULT NULL,
`country_name` varchar(64) COLLATE utf8_bin DEFAULT NULL,
KEY `idx_ip_from` (`ip_from`),
KEY `idx_ip_to` (`ip_to`),
KEY `idx_ip_from_to` (`ip_from`,`ip_to`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_binEsta tabla se basa en la base de datos de ubicación de IP2 y rara vez se actualiza/escribe, por lo general, solo el primer día del mes calendario (recomendado por el proveedor). Entonces, una opción es convertir la tabla al motor de almacenamiento MyISAM (MySQL) o Aria (MariaDB) con formato de fila fijo para obtener un mejor rendimiento de solo lectura. Tenga en cuenta que esto solo es aplicable si está ejecutando MySQL o MariaDB de forma independiente o replicación. En Galera Cluster y Group Replication, utilice el motor de almacenamiento InnoDB (a menos que sepa lo que está haciendo).
De todos modos, para convertir la tabla de InnoDB a MyISAM con formato de fila fijo, simplemente ejecute el siguiente comando:
ALTER TABLE ip2location ENGINE=MyISAM ROW_FORMAT=FIXED;En nuestra medición, con 1000 pruebas de búsqueda de direcciones IP aleatorias, el rendimiento de las consultas mejoró alrededor de un 20 % con MyISAM y formato de fila fijo:
- Tiempo promedio (InnoDB):21.467823 ms
- Tiempo promedio (MyISAM fijo):17.175942 ms
- Mejora:19,992157565301 %
Puede esperar que este resultado sea inmediato después de modificar la tabla. No es necesaria ninguna modificación en el nivel superior (aplicación/balanceador de carga).
Ajuste de la consulta
Otra forma es inspeccionar el plan de consulta y utilizar un enfoque más eficiente para un mejor plan de ejecución de consulta. La misma consulta también se puede escribir usando una subconsulta como se muestra a continuación:
SELECT `country_code`, `country_name` FROM
(SELECT `country_code`, `country_name`, `ip_from`
FROM `ip2location`
WHERE ip_to >= INET_ATON('104.144.171.139')
LIMIT 1)
AS temptable
WHERE ip_from <= INET_ATON('104.144.171.139');La consulta ajustada tiene el siguiente plan de ejecución de consultas:
mysql> EXPLAIN SELECT `country_code`,`country_name` FROM
(SELECT `country_code`, `country_name`, `ip_from`
FROM `ip2location`
WHERE ip_to >= INET_ATON('104.144.171.139')
LIMIT 1)
AS temptable
WHERE ip_from <= INET_ATON('104.144.171.139');
+----+-------------+--------------+------------+--------+---------------+-----------+---------+------+-------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+--------+---------------+-----------+---------+------+-------+----------+-----------------------+
| 1 | PRIMARY | <derived2> | NULL | system | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
| 2 | DERIVED | ip2location | NULL | range | idx_ip_to | idx_ip_to | 5 | NULL | 66380 | 100.00 | Using index condition |
+----+-------------+--------------+------------+--------+---------------+-----------+---------+------+-------+----------+-----------------------+Usando la subconsulta, podemos optimizar la consulta usando una tabla derivada que se enfoca en un índice. La consulta debe devolver solo 1 registro en el que el valor de ip_to sea mayor o igual que el valor de la dirección IP. Esto permite que las filas potenciales (filtradas) lleguen al 100%, que es lo más eficiente. Luego, verifique que ip_from sea menor o igual que el valor de la dirección IP. Si es así, entonces deberíamos encontrar el registro. De lo contrario, la dirección IP no existe en la tabla ip2location.
En nuestra medición, el rendimiento de las consultas mejoró alrededor del 99 % con una subconsulta:
- Tiempo promedio (InnoDB + escaneo de rango):22.87112 ms
- Tiempo promedio (InnoDB + subconsulta):0.14744 ms
- Mejora:99,355344207017 %
Con la optimización anterior, podemos ver un tiempo de ejecución de consulta de menos de un milisegundo de este tipo de consulta, lo que es una gran mejora teniendo en cuenta que el tiempo promedio anterior es de 22 ms. Sin embargo, debemos realizar algunas modificaciones en el nivel superior (aplicación/balanceador de carga) para poder beneficiarnos de esta consulta optimizada.
Parches o reescritura de consultas
Parche sus aplicaciones para usar la consulta ajustada o reescriba la consulta atípica antes de que llegue al servidor de la base de datos. Podemos lograr esto usando un equilibrador de carga de MySQL como ProxySQL (reglas de consulta) o MariaDB MaxScale (filtro de reescritura de declaraciones), o usando el complemento MySQL Query Rewriter. En el siguiente ejemplo, usamos ProxySQL frente a nuestro clúster de base de datos y simplemente podemos crear una regla para reescribir la consulta más lenta en una más rápida, por ejemplo:
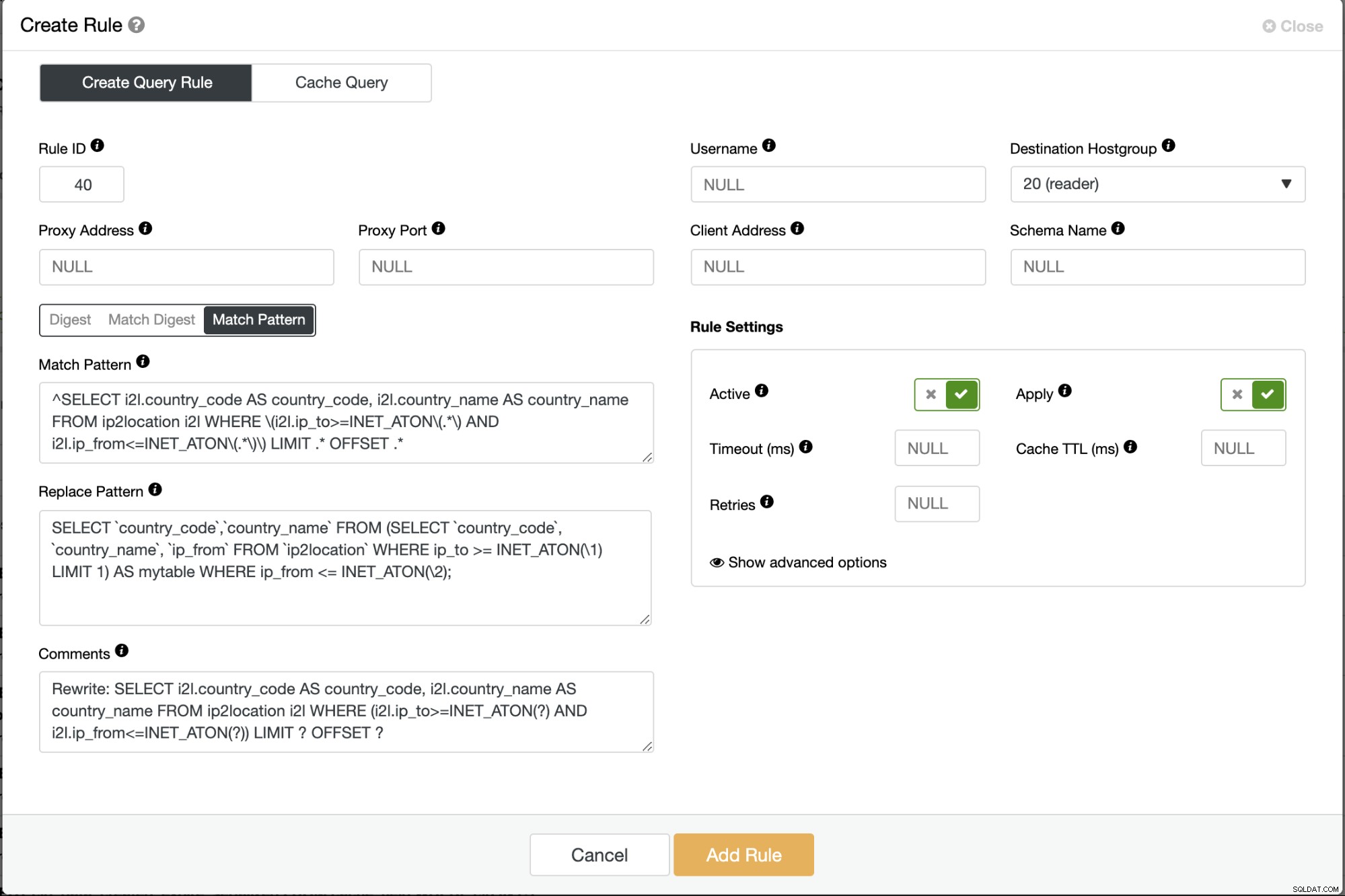
Guarde la regla de consulta y supervise la página Consulta de valores atípicos en ClusterControl. Esta corrección obviamente eliminará las consultas atípicas de la lista después de activar la regla de consulta.
Conclusión
Query outliers es una herramienta proactiva de supervisión de consultas que puede ayudarnos a comprender y solucionar el problema de rendimiento antes de que se salga de control. A medida que su aplicación crece y se vuelve más exigente, esta herramienta puede ayudarlo a mantener un rendimiento decente de la base de datos en el camino.