Antes de analizar el problema de rendimiento de los registros reenviados y resolverlo, debemos revisar la estructura de las tablas de SQL Server.
Descripción general de la estructura de la tabla
En SQL Server, la unidad fundamental de almacenamiento de datos son las Páginas de 8 KB . Cada página comienza con un encabezado de 96 bytes que almacena la información del sistema sobre esa página. Luego, las filas de la tabla se almacenarán en las páginas de datos en serie después del encabezado. Al final de la página, la tabla de compensación de filas, que contiene una entrada para cada fila, se almacenará frente a la secuencia de las filas en la página. Esta entrada de desplazamiento de fila muestra qué tan lejos se encuentra el primer byte de esa fila desde el inicio de la página.
SQL Server nos proporciona dos tipos de tablas, según la estructura de esa tabla. Los agrupados La tabla almacena y ordena los datos en las páginas de datos en función de los valores predefinidos de columna o columnas de clave de índice agrupado. Además, las páginas de datos dentro de la tabla agrupada se ordenan y vinculan en una lista vinculada basada en los valores clave del índice agrupado. El árbol B La estructura del índice agrupado proporciona un método de acceso rápido a los datos basado en los valores clave del índice agrupado. Si se inserta una nueva fila o se actualiza un valor de clave existente en la tabla agrupada, SQL Server almacenará el nuevo valor en la posición lógica correcta que se ajuste al tamaño de la fila insertada sin romper los criterios de ordenación. Si el valor insertado o actualizado es mayor que el espacio disponible en la página de datos, la página se dividirá en dos páginas para ajustarse al nuevo valor.
El segundo tipo de tablas es el Heap tabla, en la que los datos no se clasifican dentro de las páginas de datos en ningún orden y las páginas no están vinculadas entre sí, ya que no hay un índice agrupado definido en esa tabla, para aplicar ningún criterio de clasificación. El seguimiento de las páginas que no están ordenadas según ningún criterio de ordenación o enlazadas en la tabla heap no es una misión fácil. Para simplificar el proceso de seguimiento de la asignación de páginas dentro de la tabla de almacenamiento dinámico, SQL Server utiliza el mapa de asignación de índice (IAM), la única conexión lógica entre las páginas de datos de la tabla del montón, manteniendo una entrada para cada página de datos de la tabla o el índice de la tabla de IAM. Para recuperar cualquier dato de la tabla del montón, SQL Server Engine escanea el IAM para ubicar la extensión, que forma 8 páginas que almacenan los datos solicitados.
Problema de registros reenviados
Si se inserta una nueva fila en la tabla del montón, SQL Server Engine escaneará el espacio libre de la página (PFS) para rastrear el estado de la asignación y el uso del espacio en cada página de datos para encontrar la primera ubicación disponible en las páginas de datos que se ajuste al tamaño de la fila insertada. Luego, la fila se agregará a la página seleccionada. Si el valor insertado es mayor que el espacio disponible en las páginas de datos, se agregará una nueva página a esa tabla para poder insertar el nuevo valor.
Por otro lado, si se modifican los datos existentes en la tabla del montón, por ejemplo, actualizamos una cadena de longitud variable con un tamaño de datos más grande, y el espacio actual no se ajusta a los nuevos datos, los datos se moverán a un lugar físico diferente. ubicación y el registro reenviado se insertará en la tabla de montón en la ubicación de datos original, para apuntar a la nueva ubicación de esos datos y para simplificar la ubicación de los datos de seguimiento. La nueva ubicación de datos también contiene un puntero que apunta al puntero de reenvío para mantenerlo actualizado en el caso de mover los datos desde la nueva ubicación y para evitar la cadena larga del puntero de reenvío o eliminarlo. Esto también puede conducir a la eliminación del registro de reenvío.
Aunque el método de redirección de registros reenviados reduce la necesidad de operaciones de reconstrucción de tablas e índices no agrupados que consumen muchos recursos para actualizar las direcciones de datos cada vez que se cambia la ubicación de los datos, también duplica la cantidad de lecturas necesarias para recuperar los datos. SQL Server visitará primero la ubicación anterior, donde encontrará el registro reenviado que lo redirige a la nueva ubicación de datos. Luego, leerá los datos solicitados, realizando la operación de lectura dos veces. Además, el problema de los registros reenviados conduce a cambiar la lectura de datos secuenciales a lectura de datos aleatorios, lo que afecta negativamente el rendimiento de la operación de recuperación de datos a lo largo del tiempo.
Vamos a crear el siguiente montón de ForwardRecordDemo usando la declaración CREATE TABLE T-SQL a continuación:
CREATE TABLE ForwardRecordDemo ( ID INT IDENTITY (1,1), Emp_Name NVARCHAR (50), Emp_BirthDate DATETIME, Emp_Salary INT )
Luego, llene esa tabla con registros de 3K para propósitos de prueba, usando la instrucción INSERT INTO T-SQL a continuación:
INSERT INTO ForwardRecordDemo VALUES ('John','2000-05-05',500)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Zaid','1999-01-07',700)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Frank','1988-07-04',900)
GO 1000 Identificación del problema de registros reenviados
La información sobre el tipo de tabla y la cantidad de páginas consumidas mientras se almacenan los datos de la tabla, así como el porcentaje de fragmentación del índice y la cantidad de registros reenviados para una tabla específica se pueden ver consultando sys.dm_db_index_physical_stats función de gestión dinámica del sistema y pasando a la DETALLE modo para devolver el número de registros de reenvío. Para hacer esto, use el siguiente script T-SQL:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Como puede ver en el resultado de la consulta, la tabla anterior es la tabla del montón que no tiene un índice agrupado creado para ordenar los datos en las páginas y vincular las páginas entre sí. Las filas de 3K insertadas en la tabla se asignan a 15 páginas de datos, sin registros reenviados y porcentaje de fragmentación cero, como se muestra en el siguiente resultado:

Cuando define el tipo de datos de una columna como VARCHAR o NVARCHAR, el valor especificado en la definición del tipo de datos es el tamaño máximo permitido para esa cadena, sin reservar por completo esa cantidad al guardar los valores en las páginas de datos. Por ejemplo, el Juan El nombre del empleado insertado en esa tabla reservará solo 8 bytes del máximo de 100 bytes para esa columna, teniendo en cuenta que guardar la cadena NVARCHAR duplicará los bytes requeridos para la columna VARCHAR, como se muestra en DATALENGTH resultado de la función a continuación:
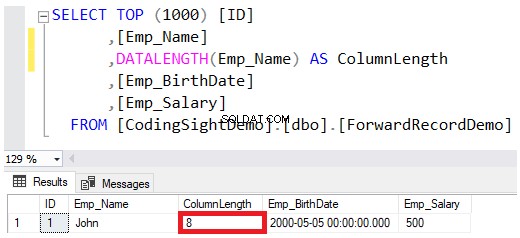
Si desea actualizar el valor de la columna Emp_Name para incluir el nombre completo del empleado de John, use la siguiente instrucción UPDATE:
UPDATE ForwardRecordDemo SET Emp_Name='John David Micheal' WHERE Emp_Name='John'
Verifique la longitud de la columna actualizada usando DATALENGTH función. Verá que la longitud de la columna Emp_Name en las filas actualizadas se ha ampliado en 28 bytes por cada columna, lo que equivale a unos 3,5 páginas de datos adicionales a esa tabla, como se muestra en el siguiente resultado:
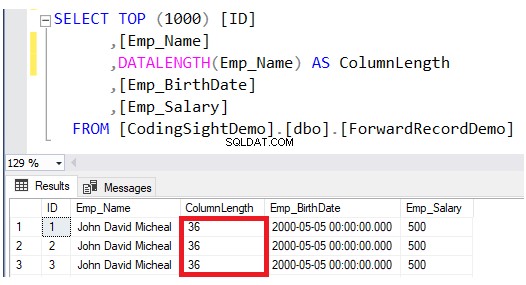
Luego, verifique la cantidad de registros reenviados después de la operación de actualización consultando la función de administración dinámica del sistema sys.dm_db_index_physical_stats. Para hacer esto, use el siguiente script T-SQL:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Como puede ver, actualizar la columna Emp_Name en registros de 1K con valores de cadena más grandes, sin agregar ningún registro nuevo, asignará los 5 adicionales páginas a esa tabla, en lugar de 3,5 páginas como se esperaba anteriormente. Esto sucederá debido a la generación de 484 registros reenviados para apuntar a las nuevas ubicaciones de los datos movidos. Esto puede causar que la tabla sea 33% fragmentado, como se muestra claramente a continuación:

Nuevamente, si logra actualizar el valor de la columna Emp_Name para incluir el nombre completo del empleado de Zaid, use la instrucción ACTUALIZAR a continuación:
UPDATE ForwardRecordDemo SET Emp_Name='Zaid Fuad Zreeq' WHERE Emp_Name='Zaid'
Verifique la longitud de la columna actualizada usando DATALENGTH función. Verá que la longitud de la columna Emp_Name en las filas actualizadas se expandió en 22 bytes por cada columna, lo que equivale a unos 2,7 páginas de datos adicionales agregadas a esa tabla, como se muestra en el siguiente resultado:
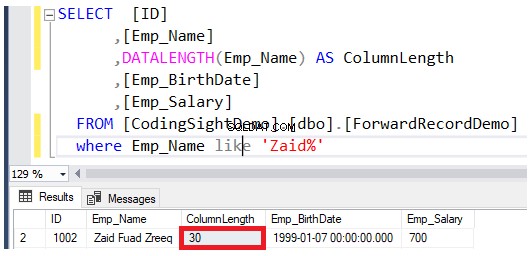
Compruebe el número de registros reenviados después de realizar la operación de actualización. Puede hacer esto consultando la función de administración dinámica del sistema sys.dm_db_index_physical_stats utilizando el mismo script T-SQL a continuación:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
El resultado le mostrará que actualizar la columna Emp_Name en los otros registros de 1K con valores de cadena más grandes sin insertar ninguna fila nueva asignará otro 4 páginas a esa tabla, en lugar de 2,7 páginas como se esperaba. Esto sucederá debido a la generación de 417 adicionales registros reenviados para apuntar a las nuevas ubicaciones de los datos movidos y manteniendo el mismo 33% porcentaje de fragmentación, como se muestra a continuación:

Solucionar el problema de los registros reenviados
La forma más sencilla de solucionar el problema de los registros reenviados es estimar la longitud máxima de la cadena que se almacenará en la columna y asignarla mediante la longitud fija. tipo de datos para esa columna en lugar de utilizar el tipo de datos de longitud variable. La forma óptima y permanente de solucionar el problema de los registros reenviados es agregar el índice agrupado a esa mesa. De esta forma, la tabla se convertirá por completo en una tabla agrupada, que se ordena en función de los valores clave del índice agrupado. Controlará el orden de los datos existentes, los datos recién insertados y actualizados que no se ajustan al espacio disponible actual en la página de datos, como se describe anteriormente en la introducción de este artículo.
Si agregar el índice agrupado a esa tabla no es una opción para requisitos específicos, como las tablas de etapas o las tablas ETL, puede superar el problema de los registros reenviados temporalmente al monitorear los registros reenviados y reconstruir la tabla de almacenamiento dinámico para eliminarlo, eso también actualice todos los índices no agrupados en esa tabla de montón. La funcionalidad de reconstruir la tabla de almacenamiento dinámico se introdujo en SQL Server 2008 mediante el uso de ALTER TABLE…REBUILD Comando T-SQL.
Para ver el impacto en el rendimiento de los registros reenviados en las consultas de recuperación de datos, ejecutemos la consulta SELECT que realiza la búsqueda en función de los valores de la columna Emp_Name. Sin embargo, antes de ejecutar la consulta, habilite las estadísticas TIME y IO:
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
Como resultado, verá que 925 se realizan operaciones de lectura lógica para recuperar los datos solicitados en 84 ms como se muestra a continuación:

Para reconstruir la tabla del montón a fin de eliminar todos los registros reenviados, utilice el comando ALTER TABLE…REBUILD:
ALTER TABLE ForwardRecordDemo REBUILD;
Ejecute la misma sentencia SELECT de nuevo:
SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
Las estadísticas TIME y IO le mostrarán que solo 21 operaciones de lectura lógica en comparación con el 925 se realizan operaciones de lectura lógica con los registros reenviados incluidos para recuperar los datos solicitados en 79 ms :

Para verificar la cantidad de registros reenviados después de reconstruir la tabla de montón, ejecute la función de administración dinámica del sistema sys.dm_db_index_physical_stats, use la misma secuencia de comandos T-SQL a continuación:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Verás que solo 21 páginas, con las 3 anteriores páginas consumidas para los Registros reenviados, se asignan a esa tabla para almacenar los datos, que es similar al resultado estimado que hemos obtenido durante las operaciones de inserción y actualización de datos (15+3.5+2.7). Después de reconstruir la tabla del montón, ahora se eliminan todos los registros reenviados. Como resultado, tenemos una tabla sin fragmentación:

El problema de registros reenviados es un problema de rendimiento importante que los administradores de bases de datos deben tener en cuenta al planificar la mantenimiento de la tabla de montón. Los resultados anteriores se recuperan de nuestra tabla de prueba que contiene solo registros de 3K. ¡Puede imaginar la cantidad de páginas que se desperdiciarán con los registros reenviados y la degradación del rendimiento de E/S debido a la lectura de una gran cantidad de registros reenviados cuando se lee desde tablas enormes!
Referencias:
- Guía de arquitectura de páginas y extensiones
- dm_db_index_physical_stats (Transact-SQL)
- ALTERAR TABLA (Transact-SQL)
- Conocer los "Registros reenviados" puede ayudar a diagnosticar problemas de rendimiento difíciles de encontrar