Hace unos días fue el lanzamiento de una nueva versión de ClusterControl, la 1.7.2, donde podemos ver varias novedades, una de las principales es el soporte para TimescaleDB.
TimescaleDB es una base de datos de series temporales de código abierto optimizada para una ingesta rápida y consultas complejas que admite SQL completo. Se basa en PostgreSQL y ofrece lo mejor de los mundos NoSQL y relacional para datos de series temporales. TimescaleDB admite la replicación de transmisión como método principal de replicación, que se puede usar en una configuración de alta disponibilidad. Sin embargo, PostgreSQL no viene con conmutación por error automática y esto es un problema en un entorno de producción de alta disponibilidad. La conmutación por error manual generalmente implica que un ser humano es buscado y tiene que encontrar una computadora, iniciar sesión en los sistemas, comprender lo que está sucediendo antes de iniciar los procedimientos de conmutación por error. Esto se traduce en un largo período de inactividad. Afortunadamente, existe una forma de automatizar las conmutaciones por error con ClusterControl, que ahora es compatible con TimescaleDB.
En este blog, veremos cómo implementar una configuración de TimescaleDB replicada con conmutación por error automática con solo unos pocos clics mediante ClusterControl. También veremos cómo agregar un punto final de base de datos único para aplicaciones a través de HAProxy. Como requisito previo, debe instalar la versión 1.7.2 de ClusterControl en un host o VM dedicado.
Implementar base de datos de escala de tiempo
Para realizar una nueva instalación de TimescaleDB desde ClusterControl, simplemente seleccione la opción “Deploy” y siga las instrucciones que aparecen. Tenga en cuenta que si ya tiene una instancia de TimescaleDB en ejecución, debe seleccionar 'Importar servidor/base de datos existente' en su lugar.
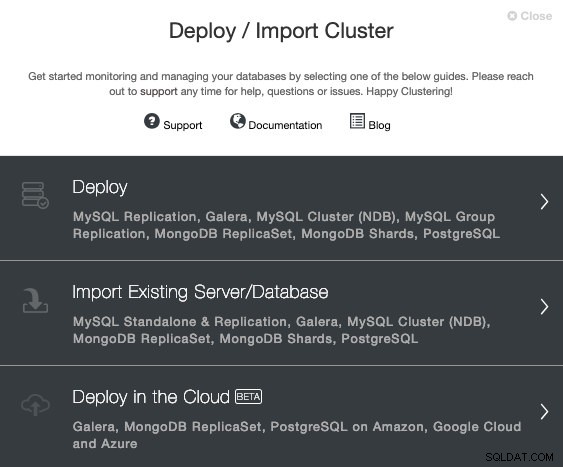
Al seleccionar TimescaleDB, debemos especificar Usuario, Clave o Contraseña y puerto para conectarnos por SSH a nuestros hosts TimescaleDB. También necesitamos un nombre para nuestro nuevo clúster y si queremos que ClusterControl instale el software y las configuraciones correspondientes por nosotros.
Compruebe aquí los requisitos de usuario de ClusterControl para esta tarea.
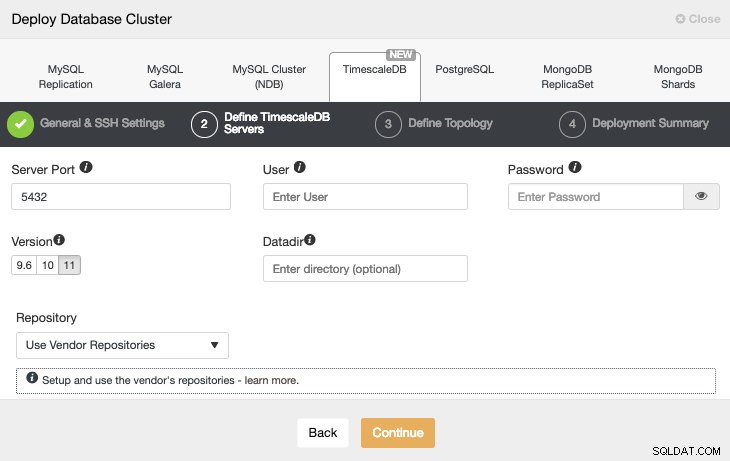
Después de configurar la información de acceso SSH, debemos definir el usuario de la base de datos, la versión y datadir (opcional). También podemos especificar qué repositorio usar.
En el siguiente paso, debemos agregar nuestros servidores al clúster que vamos a crear.
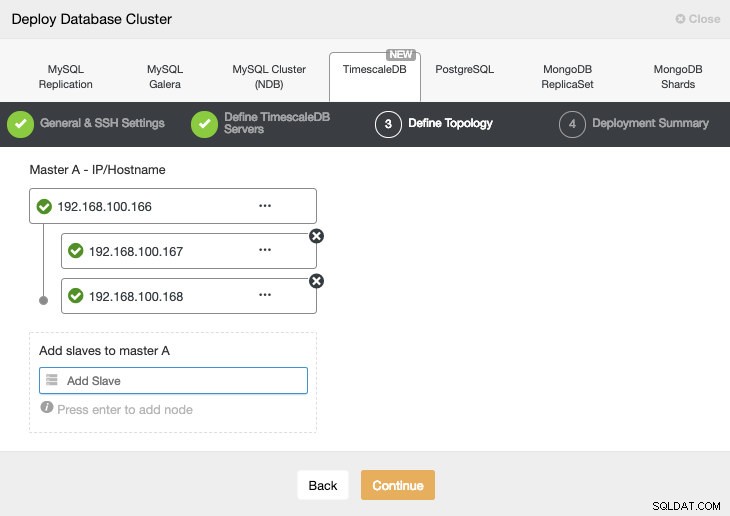
Al agregar nuestros servidores, podemos ingresar IP o nombre de host.
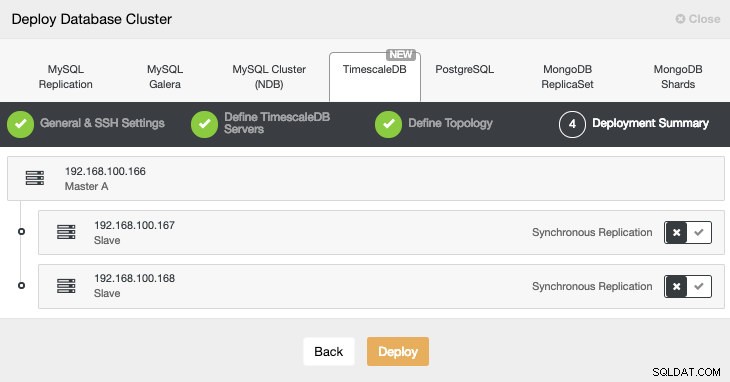
En el último paso, podemos elegir si nuestra replicación será Síncrona o Asíncrona.
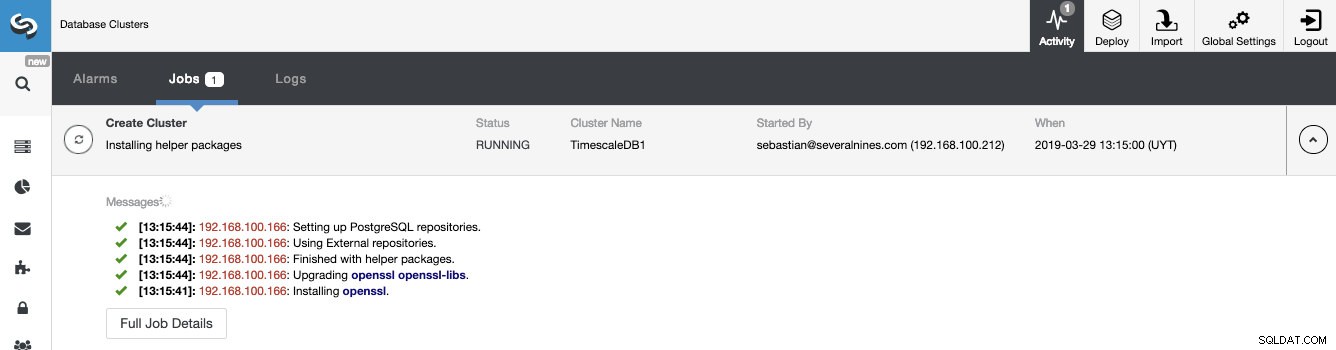
Podemos monitorear el estado de la creación de nuestro nuevo clúster desde el monitor de actividad de ClusterControl.
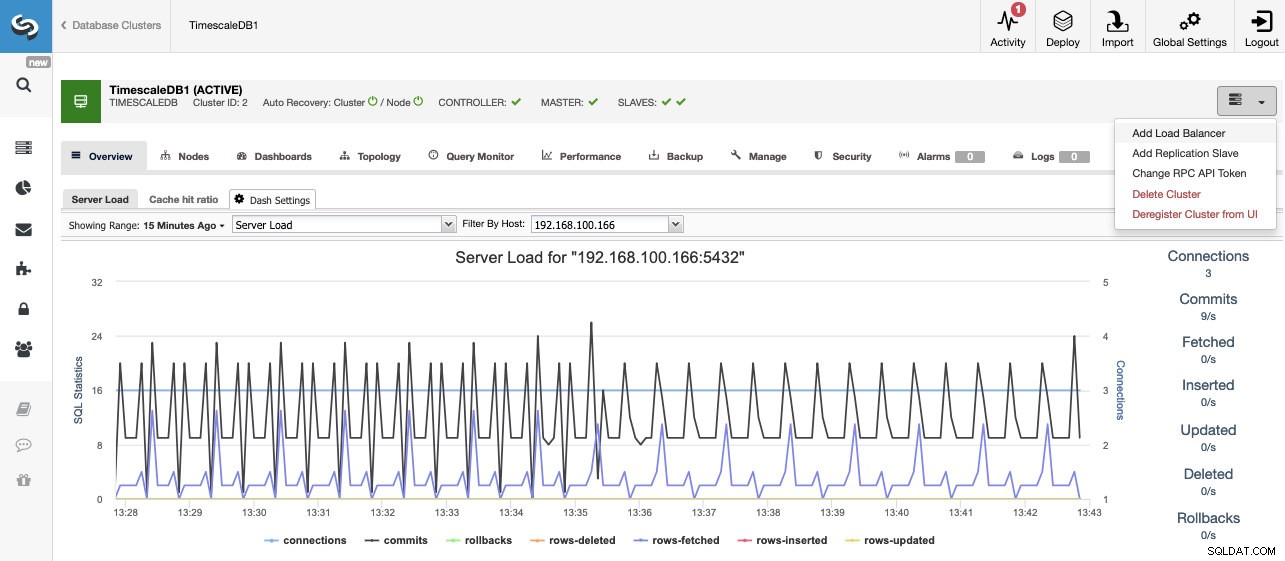
Una vez finalizada la tarea, podemos ver nuestro nuevo clúster de TimescaleDB en la pantalla principal de ClusterControl.

Una vez que tenemos nuestro clúster creado, podemos realizar varias tareas en él, como agregar un balanceador de carga (HAProxy) o una nueva réplica.
Escala de tiempo de escala DB
Si vamos a las acciones del clúster y seleccionamos "Agregar esclavo de replicación", podemos crear una nueva réplica desde cero o agregar una base de datos TimescaleDB existente como réplica.
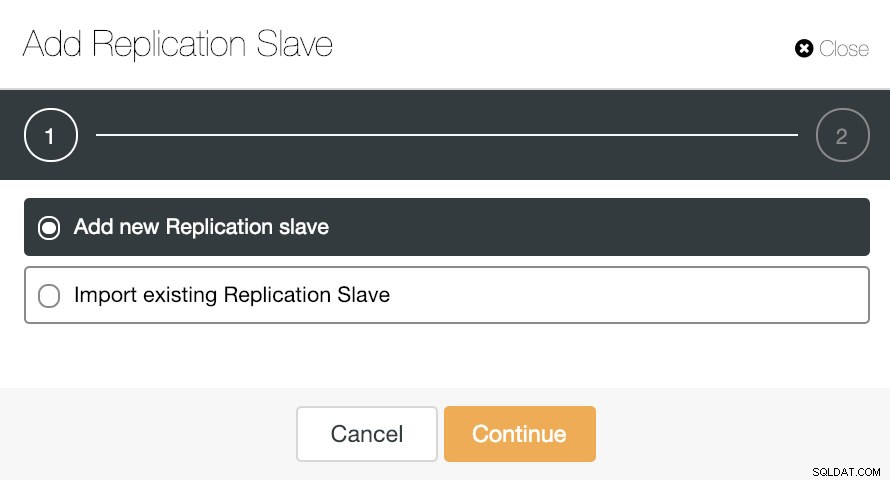
Veamos cómo agregar un nuevo esclavo de replicación puede ser una tarea realmente fácil.
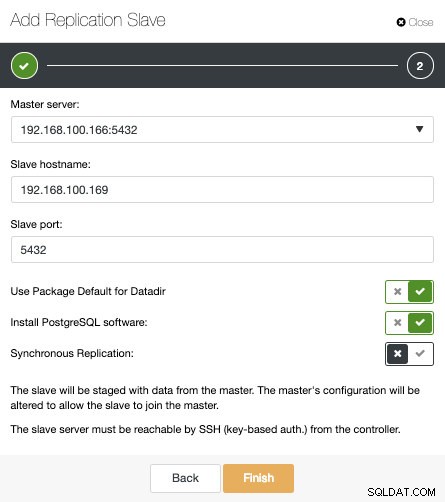
Como puede ver en la imagen, solo necesitamos elegir nuestro servidor Master, ingresar la dirección IP para nuestro nuevo servidor esclavo y el puerto de la base de datos. Luego, podemos elegir si queremos que ClusterControl instale el software por nosotros y si el esclavo de replicación debe ser síncrono o asíncrono.
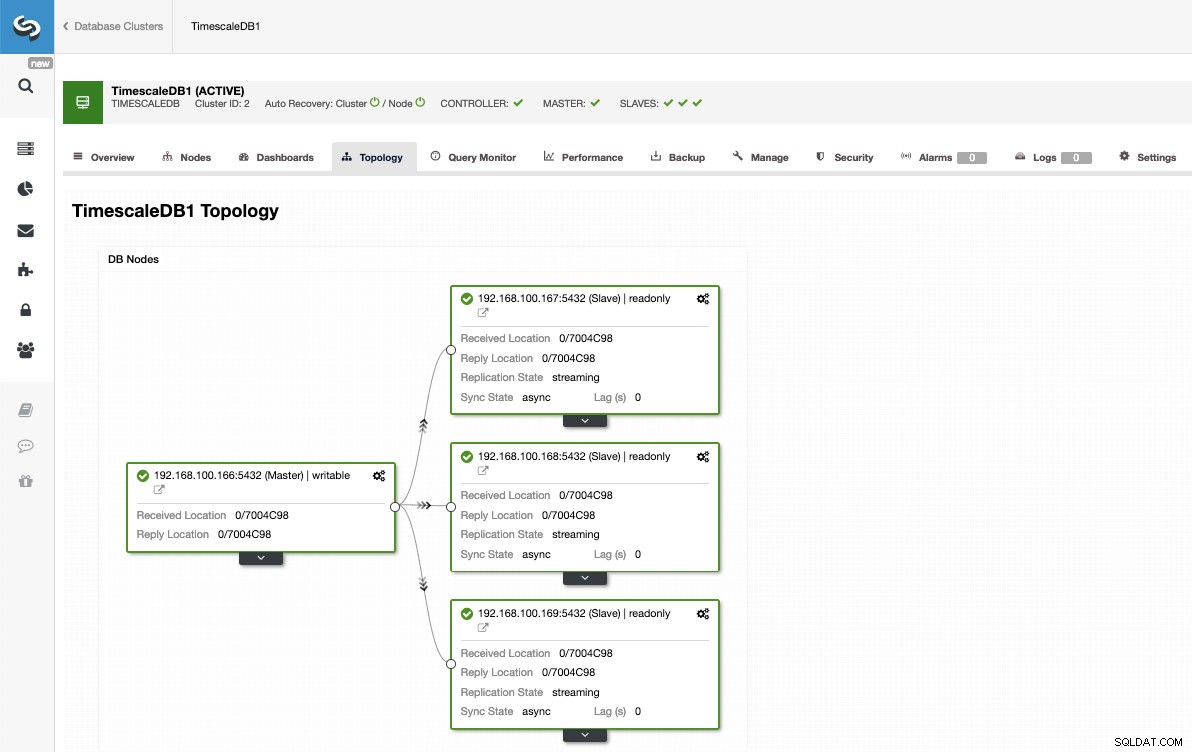
De esta forma, podemos añadir tantas réplicas como queramos y repartir el tráfico de lectura entre ellas mediante un balanceador de carga, que también podemos implementar con ClusterControl.
Desde ClusterControl, también puede realizar diferentes tareas de administración como Reiniciar host, Reconstruir esclavo de replicación o Promover esclavo, con un solo clic.
Conclusión
Como hemos visto anteriormente, ahora puede implementar TimescaleDB mediante ClusterControl. Una vez implementado, ClusterControl proporciona una amplia gama de funciones, desde monitoreo, alertas, conmutación por error automática, respaldo, recuperación de un momento dado, verificación de respaldo, hasta escalado de réplicas de lectura. Esto puede ayudarlo a administrar TimescaleDB de una manera amigable e intuitiva.