Las personas se preguntan si deberían hacer todo lo posible para evitar las excepciones o simplemente dejar que el sistema las maneje. He visto varias discusiones en las que la gente debate si deberían hacer todo lo posible para evitar una excepción, porque el manejo de errores es "caro". No hay duda de que el manejo de errores no es gratuito, pero predeciría que una violación de restricción es al menos tan eficiente como verificar primero una posible violación. Esto puede ser diferente para una infracción de clave que para una infracción de restricción estática, por ejemplo, pero en esta publicación me centraré en la primera.
Los enfoques principales que la gente usa para lidiar con las excepciones son:
- Deje que el motor lo maneje y envíe cualquier excepción a la persona que llama.
- Utilice
BEGIN TRANSACTIONyROLLBACKsi@@ERROR <> 0. - Use
TRY/CATCHconROLLBACKen elCATCHbloque (SQL Server 2005+).
Y muchos adoptan el enfoque de que primero deben verificar si van a incurrir en la infracción, ya que parece más limpio manejar el duplicado usted mismo que obligar al motor a hacerlo. Mi teoría es que debes confiar pero verificar; por ejemplo, considere este enfoque (principalmente pseudocódigo):
IF NOT EXISTS ([row that would incur a violation])
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
INSERT ()...
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
-- well, we incurred a violation anyway;
-- I guess a new row was inserted or
-- updated since we performed the check
ROLLBACK TRANSACTION;
END CATCH
END
Sabemos que el IF NOT EXISTS check no garantiza que otra persona no haya insertado la fila cuando lleguemos a INSERT (a menos que coloquemos bloqueos agresivos en la tabla y/o usemos SERIALIZABLE ), pero la verificación externa evita que intentemos cometer una falla y luego tengamos que retroceder. Nos mantenemos fuera de todo el TRY/CATCH estructura si ya sabemos que el INSERT fallará, y sería lógico suponer que, al menos en algunos casos, esto será más eficiente que ingresar el TRY/CATCH estructura incondicionalmente. Esto tiene poco sentido en un solo INSERT escenario, pero imagina un caso en el que hay más cosas en ese TRY bloquear (y más infracciones potenciales que podría verificar con anticipación, lo que significa aún más trabajo que de otro modo tendría que realizar y luego retroceder en caso de que ocurra una infracción posterior).
Ahora, sería interesante ver qué sucedería si usara un nivel de aislamiento no predeterminado (algo que trataré en una publicación futura), particularmente con la concurrencia. Sin embargo, para esta publicación, quería comenzar lentamente y probar estos aspectos con un solo usuario. Creé una tabla llamada dbo.[Objects] , una tabla muy simple:
CREATE TABLE dbo.[Objects] ( ObjectID INT IDENTITY(1,1), Name NVARCHAR(255) PRIMARY KEY ); GO
Quería llenar esta tabla con 100 000 filas de datos de muestra. Para hacer que los valores en la columna de nombre sean únicos (ya que PK es la restricción que quería violar), creé una función auxiliar que toma un número de filas y una cadena mínima. La cadena mínima se usaría para asegurarse de que (a) el conjunto comenzara más allá del valor máximo en la tabla Objetos, o (b) el conjunto comenzara en el valor mínimo en la tabla Objetos. (Los especificaré manualmente durante las pruebas, verificados simplemente inspeccionando los datos, aunque probablemente podría haber integrado esa verificación en la función).
CREATE FUNCTION dbo.GenerateRows(@n INT, @minString NVARCHAR(32)) RETURNS TABLE AS RETURN ( SELECT TOP (@n) name = name + '_' + RTRIM(rn) FROM ( SELECT a.name, rn = ROW_NUMBER() OVER (PARTITION BY a.name ORDER BY a.name) FROM sys.all_objects AS a CROSS JOIN sys.all_objects AS b WHERE a.name >= @minString AND b.name >= @minString ) AS x ); GO
Esto aplica un CROSS JOIN de sys.all_objects sobre sí mismo, agregando un número de fila único a cada nombre, por lo que los primeros 10 resultados se verían así:
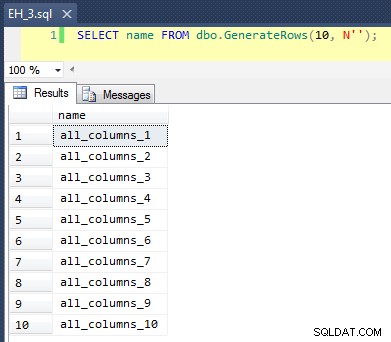
Completar la tabla con 100 000 filas fue simple:
INSERT dbo.[Objects](name) SELECT name FROM dbo.GenerateRows(100000, N'') ORDER BY name; GO
Ahora, dado que vamos a insertar nuevos valores únicos en la tabla, creé un procedimiento para realizar una limpieza al principio y al final de cada prueba; además de eliminar las filas nuevas que hayamos agregado, también limpiará la memoria caché y los búferes. No es algo que desee codificar en un procedimiento en su sistema de producción, por supuesto, pero está bien para las pruebas de rendimiento locales.
CREATE PROCEDURE dbo.EH_Cleanup -- P.S. "EH" stands for Error Handling, not "Eh?" AS BEGIN SET NOCOUNT ON; DELETE dbo.[Objects] WHERE ObjectID > 100000; DBCC FREEPROCCACHE; DBCC DROPCLEANBUFFERS; END GO
También creé una tabla de registro para realizar un seguimiento de las horas de inicio y finalización de cada prueba:
CREATE TABLE dbo.RunTimeLog ( LogID INT IDENTITY(1,1), Spid INT, InsertType VARCHAR(255), ErrorHandlingMethod VARCHAR(255), StartDate DATETIME2(7) NOT NULL DEFAULT SYSUTCDATETIME(), EndDate DATETIME2(7) ); GO
Finalmente, el procedimiento almacenado de prueba maneja una variedad de cosas. Tenemos tres métodos diferentes de manejo de errores, como se describe en las viñetas anteriores:"JustInsert", "Rollback" y "TryCatch"; también tenemos tres tipos de inserciones diferentes:(1) todas las inserciones son correctas (todas las filas son únicas), (2) todas las inserciones fallan (todas las filas son duplicadas) y (3) la mitad de las inserciones son correctas (la mitad de las filas son únicas y la otra mitad las filas son duplicados). Junto con esto, hay dos enfoques diferentes:verifique la violación antes de intentar la inserción, o simplemente continúe y deje que el motor determine si es válida. Pensé que esto daría una buena comparación de las diferentes técnicas de manejo de errores combinadas con diferentes probabilidades de colisiones para ver si un porcentaje alto o bajo de colisiones afectaría significativamente los resultados.
Para estas pruebas, elegí 40 000 filas como mi número total de intentos de inserción, y en el procedimiento realizo una unión de 20 000 filas únicas o no únicas con otras 20 000 filas únicas o no únicas. Puede ver que codifiqué las cadenas de corte en el procedimiento; tenga en cuenta que en su sistema estos cortes casi seguramente ocurrirán en un lugar diferente.
CREATE PROCEDURE dbo.EH_Insert @ErrorHandlingMethod VARCHAR(255), @InsertType VARCHAR(255), @RowSplit INT = 20000 AS BEGIN SET NOCOUNT ON; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; DECLARE @CutoffString1 NVARCHAR(255), @CutoffString2 NVARCHAR(255), @Name NVARCHAR(255), @Continue BIT = 1, @LogID INT; -- generate a new log entry INSERT dbo.RunTimeLog(Spid, InsertType, ErrorHandlingMethod) SELECT @@SPID, @InsertType, @ErrorHandlingMethod; SET @LogID = SCOPE_IDENTITY(); -- if we want everything to succeed, we need a set of data -- that has 40,000 rows that are all unique. So union two -- sets that are each >= 20,000 rows apart, and don't -- already exist in the base table: IF @InsertType = 'AllSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N'dm_clr_properties_1398'; -- if we want them all to fail, then it's easy, we can just -- union two sets that start at the same place as the initial -- population: IF @InsertType = 'AllFail' SELECT @CutoffString1 = N'', @CutoffString2 = N''; -- and if we want half to succeed, we need 20,000 unique -- values, and 20,000 duplicates: IF @InsertType = 'HalfSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N''; DECLARE c CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY FOR SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString1) UNION ALL SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString2); OPEN c; FETCH NEXT FROM c INTO @Name; WHILE @@FETCH_STATUS = 0 BEGIN SET @Continue = 1; -- let's only enter the primary code block if we -- have to check and the check comes back empty -- (in other words, don't try at all if we have -- a duplicate, but only check for a duplicate -- in certain cases: IF @ErrorHandlingMethod LIKE 'Check%' BEGIN IF EXISTS (SELECT 1 FROM dbo.[Objects] WHERE Name = @Name) SET @Continue = 0; END IF @Continue = 1 BEGIN -- just let the engine catch IF @ErrorHandlingMethod LIKE '%Insert' BEGIN INSERT dbo.[Objects](name) SELECT @name; END -- begin a transaction, but let the engine catch IF @ErrorHandlingMethod LIKE '%Rollback' BEGIN BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @name; IF @@ERROR <> 0 BEGIN ROLLBACK TRANSACTION; END ELSE BEGIN COMMIT TRANSACTION; END END -- use try / catch IF @ErrorHandlingMethod LIKE '%TryCatch' BEGIN BEGIN TRY BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @Name; COMMIT TRANSACTION; END TRY BEGIN CATCH ROLLBACK TRANSACTION; END CATCH END END FETCH NEXT FROM c INTO @Name; END CLOSE c; DEALLOCATE c; -- update the log entry UPDATE dbo.RunTimeLog SET EndDate = SYSUTCDATETIME() WHERE LogID = @LogID; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; END GO
Ahora podemos llamar a este procedimiento con varios argumentos para obtener el comportamiento diferente que buscamos, tratando de insertar 40,000 valores (y sabiendo, por supuesto, cuántos deberían tener éxito o fallar en cada caso). Para cada 'método de manejo de errores' (simplemente intente la inserción, use begin tran/rollback, o try/catch) y cada tipo de inserción (todos exitosos, la mitad exitosos y ninguno exitoso), combinados con si verificar o no la infracción primero, esto nos da 18 combinaciones:
EXEC dbo.EH_Insert 'JustInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllFail', 20000;
Después de ejecutar esto (toma alrededor de 8 minutos en mi sistema), tenemos algunos resultados en nuestro registro. Ejecuté el lote completo cinco veces para asegurarme de que obtuviéramos promedios decentes y para suavizar cualquier anomalía. Estos son los resultados:
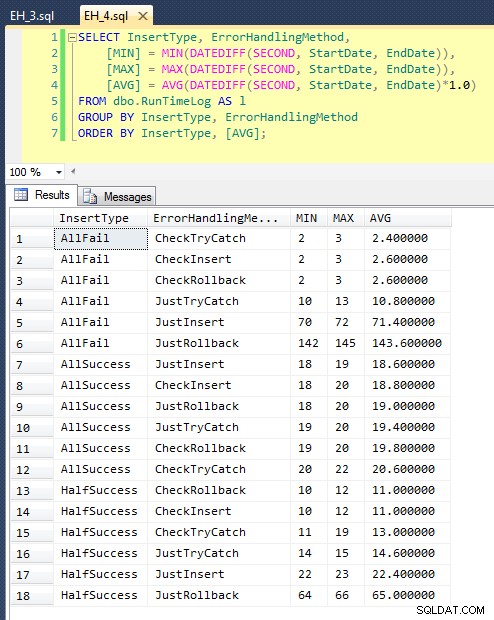
El gráfico que traza todas las duraciones a la vez muestra un par de valores atípicos graves:
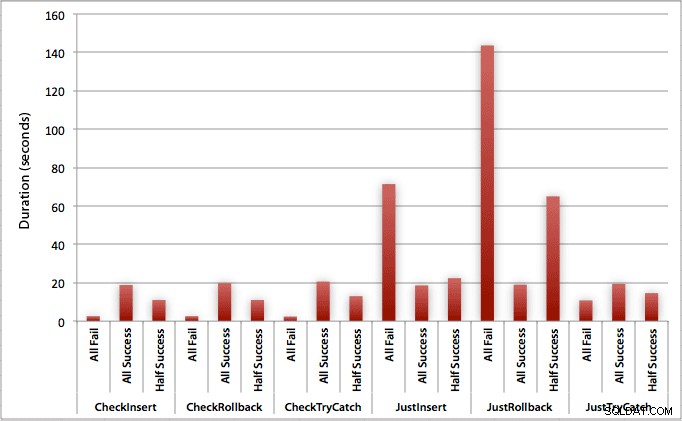
Puede ver que, en los casos en los que esperamos una alta tasa de fallas (en esta prueba, 100 %), comenzar una transacción y retroceder es, con mucho, el enfoque menos atractivo (3,59 milisegundos por intento), mientras que simplemente deja que el motor suba un error es aproximadamente la mitad de malo (1,785 milisegundos por intento). El siguiente peor desempeño fue el caso en el que comenzamos una transacción y luego la revertimos, en un escenario en el que esperamos que falle aproximadamente la mitad de los intentos (con un promedio de 1,625 milisegundos por intento). Los 9 casos en el lado izquierdo del gráfico, donde estamos comprobando primero la infracción, no se aventuraron por encima de los 0,515 milisegundos por intento.
Habiendo dicho eso, los gráficos individuales para cada escenario (alto % de éxito, alto % de falla y 50-50) realmente muestran el impacto de cada método.
Donde todas las inserciones tienen éxito
En este caso, vemos que la sobrecarga de verificar primero la infracción es insignificante, con una diferencia promedio de 0,7 segundos en el lote (o 125 microsegundos por intento de inserción):
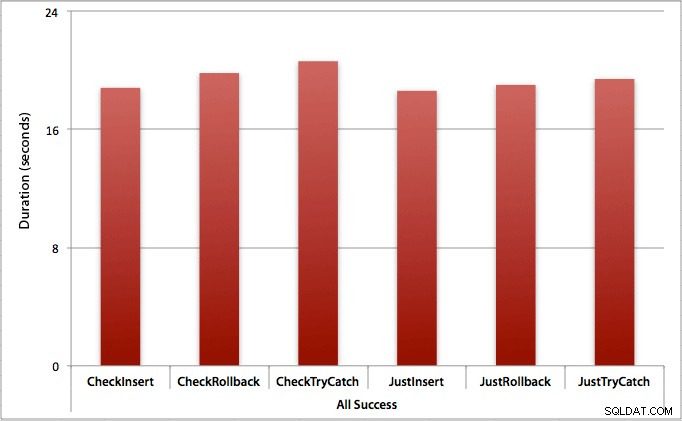
Donde solo la mitad de las inserciones tienen éxito
Cuando la mitad de las inserciones fallan, vemos un gran salto en la duración de los métodos de inserción/reversión. El escenario en el que comenzamos una transacción y la revertimos es aproximadamente 6 veces más lento en todo el lote en comparación con la verificación inicial (1,625 milisegundos por intento frente a 0,275 milisegundos por intento). Incluso el método TRY/CATCH es un 11 % más rápido cuando comprobamos primero:
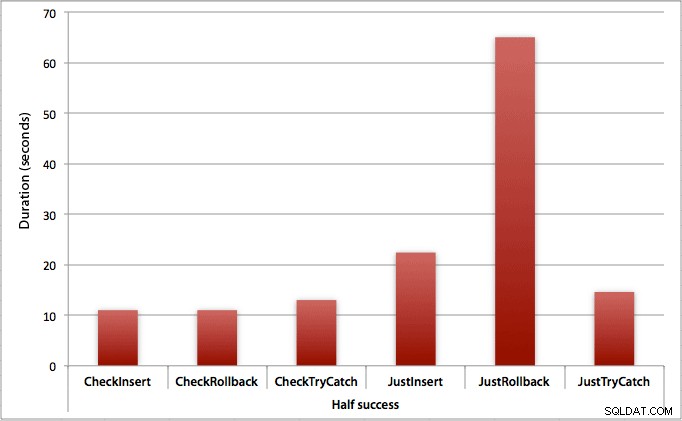
Donde todas las inserciones fallan
Como era de esperar, esto muestra el impacto más pronunciado del manejo de errores y los beneficios más obvios de verificar primero. El método de reversión es casi 70 veces más lento en este caso cuando no verificamos en comparación con cuando lo hacemos (3,59 milisegundos por intento frente a 0,065 milisegundos por intento):
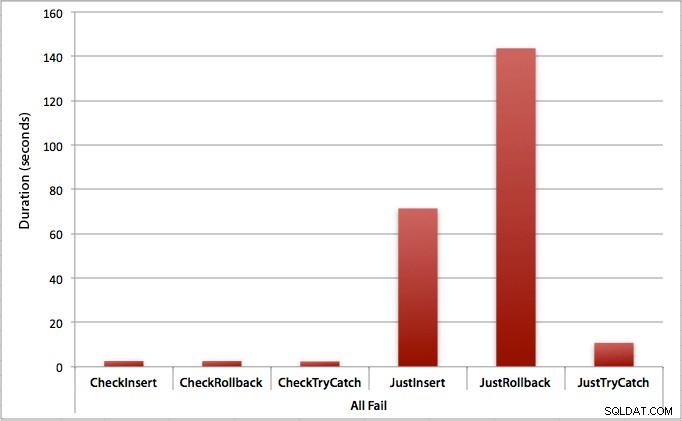
¿Qué nos dice esto? Si pensamos que vamos a tener una alta tasa de fallas, o no tenemos idea de cuál será nuestra tasa potencial de fallas, entonces verificar primero para evitar violaciones en el motor valdrá la pena. Incluso en el caso de que tengamos una inserción exitosa cada vez, el costo de verificar primero es marginal y se justifica fácilmente por el costo potencial de manejar errores más adelante (a menos que su tasa de falla anticipada sea exactamente 0%).
Entonces, por ahora, creo que me apegaré a mi teoría de que, en casos simples, tiene sentido verificar una posible violación antes de decirle a SQL Server que continúe e inserte de todos modos. En una publicación futura, analizaré el impacto en el rendimiento de varios niveles de aislamiento, simultaneidad y tal vez incluso algunas otras técnicas de manejo de errores.
[Aparte, escribí una versión resumida de esta publicación como sugerencia para mssqltips.com en febrero].