Con demasiada frecuencia veo gente quejándose de cómo su registro de transacciones se apoderó de su disco duro. Muchas veces resulta que estaban realizando una gran operación de eliminación, como purgar o archivar datos, en una transacción grande.
Quería realizar algunas pruebas para mostrar el impacto, tanto en la duración como en el registro de transacciones, de realizar la misma operación de datos en fragmentos frente a una sola transacción. Creé una base de datos y la llené con una tabla más grande SalesOrderDetailEnlarged ,
Después de completar la tabla, hice una copia de seguridad de la base de datos, hice una copia de seguridad del registro y ejecuté un DBCC SHRINKFILE (no me dispares) para que el impacto en el archivo de registro pueda establecerse a partir de una línea de base (sabiendo muy bien que estas operaciones *harán* que el registro de transacciones crezca).
Usé deliberadamente un disco mecánico en lugar de un SSD. Si bien podemos comenzar a ver una tendencia más popular de pasar a SSD, aún no ha sucedido en una escala lo suficientemente grande; en muchos casos, todavía es demasiado costoso hacerlo en dispositivos de almacenamiento de gran tamaño.
Las Pruebas
Entonces, a continuación, tenía que determinar qué quería probar para obtener el mayor impacto. Como ayer mismo participé en una discusión con un compañero de trabajo sobre la eliminación de datos en fragmentos, elegí eliminar. Y dado que el índice agrupado en esta tabla está en SalesOrderID , no quería usar eso; sería demasiado fácil (y muy rara vez coincidiría con la forma en que se manejan las eliminaciones en la vida real). Así que decidí buscar una serie de ProductID valores, lo que aseguraría que llegaría a una gran cantidad de páginas y requeriría mucho registro. Determiné qué productos eliminar mediante la siguiente consulta:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Esto arrojó los siguientes resultados:
ProductID ProductCount --------- ------------ 870 187520 712 135280 873 134160
Esto eliminaría 456 960 filas (alrededor del 10 % de la tabla), distribuidas en muchos pedidos. Esta no es una modificación realista en este contexto, ya que alterará los totales de pedidos precalculados, y realmente no puede eliminar un producto de un pedido que ya se envió. Pero usar una base de datos que todos conocemos y amamos, es similar a, por ejemplo, eliminar a un usuario de un sitio de foro y también eliminar todos sus mensajes, un escenario real que he visto en la naturaleza.
Entonces, una prueba sería realizar la siguiente eliminación de una sola vez:
DELETE dbo.SalesOrderDetailEnlarged WHERE ProductID IN (712, 870, 873);
Sé que esto requerirá un escaneo masivo y afectará enormemente el registro de transacciones. Ese es el punto. :-)
Mientras se ejecutaba, preparé un script diferente que realizará esta eliminación en partes:25 000, 50 000, 75 000 y 100 000 filas a la vez. Cada fragmento se confirmará en su propia transacción (de modo que si necesita detener el script, puede hacerlo y todos los fragmentos anteriores ya estarán confirmados, en lugar de tener que empezar de nuevo) y, según el modelo de recuperación, se seguirá por un CHECKPOINT o un BACKUP LOG para minimizar el impacto continuo en el registro de transacciones. (También probaré sin estas operaciones). Se verá así (no me voy a molestar con el manejo de errores y otras sutilezas para esta prueba, pero no debería ser tan arrogante):
SET NOCOUNT ON;
DECLARE @r INT;
SET @r = 1;
WHILE @r > 0
BEGIN
BEGIN TRANSACTION;
DELETE TOP (100000) -- this will change
dbo.SalesOrderDetailEnlarged
WHERE ProductID IN (712, 870, 873);
SET @r = @@ROWCOUNT;
COMMIT TRANSACTION;
-- CHECKPOINT; -- if simple
-- BACKUP LOG ... -- if full
END
Por supuesto, después de cada prueba, restauraría la copia de seguridad original de la base de datos WITH REPLACE, RECOVERY , establezca el modelo de recuperación en consecuencia y ejecute la siguiente prueba.
Los resultados
El resultado de la primera prueba no fue muy sorprendente en absoluto. Para realizar la eliminación en una sola declaración, tomó 42 segundos en total y 43 segundos en simple. En ambos casos, esto aumentó el registro a 579 MB.
La siguiente serie de pruebas me trajo un par de sorpresas. Una es que, si bien estos métodos de fragmentación redujeron significativamente el impacto en el archivo de registro, solo un par de combinaciones se acercaron en duración y ninguna fue realmente más rápida. Otra es que, en general, la fragmentación en la recuperación completa (sin realizar una copia de seguridad del registro entre pasos) funcionó mejor que las operaciones equivalentes en la recuperación simple. Estos son los resultados de la duración y el impacto del registro:
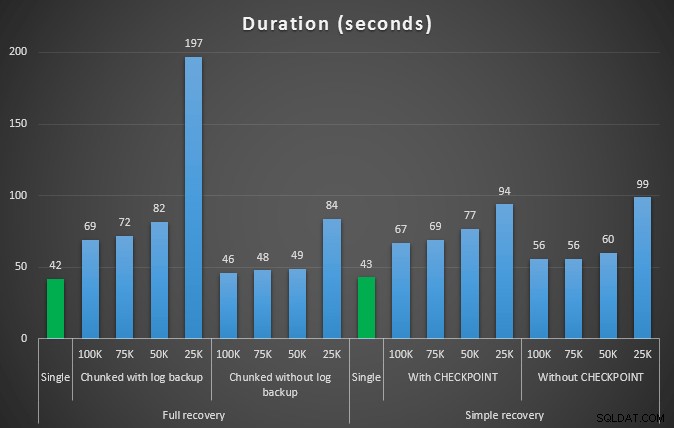
Duración, en segundos, de varias operaciones de eliminación que eliminan 457 000 filas
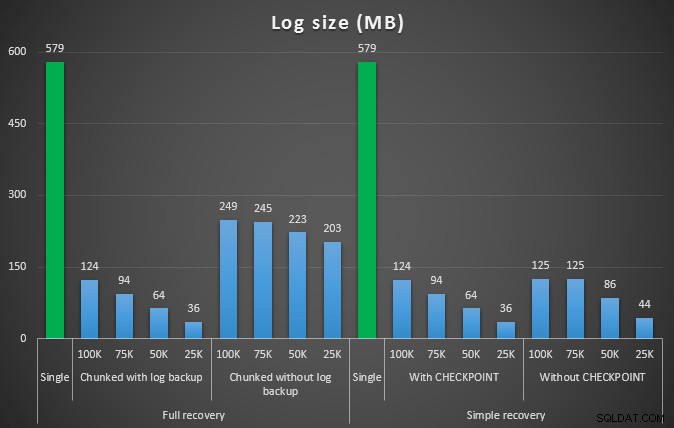
Tamaño de registro, en MB, después de varias operaciones de eliminación eliminando 457K filas
Nuevamente, en general, mientras que el tamaño del registro se reduce significativamente, la duración aumenta. Puede usar este tipo de escala para determinar si es más importante reducir el impacto en el espacio en disco o minimizar la cantidad de tiempo invertido. Por un pequeño impacto en la duración (y después de todo, la mayoría de estos procesos se ejecutan en segundo plano), puede tener un ahorro significativo (hasta un 94 %, en estas pruebas) en el uso del espacio de registro.
Tenga en cuenta que no probé ninguna de estas pruebas con la compresión habilitada (¡posiblemente una prueba futura!) este escenario horrible.
¿Pero qué pasa si tengo más datos?
Luego pensé que debería probar esto en una base de datos un poco más grande. Así que creé otra base de datos y creé una copia nueva y más grande de dbo.SalesOrderDetailEnlarged . Aproximadamente diez veces más grande, de hecho. Esta vez en lugar de una clave principal en SalesOrderID, SalesorderDetailID , simplemente lo convertí en un índice agrupado (para permitir duplicados) y lo rellené de esta manera:
SELECT c.*
INTO dbo.SalesOrderDetailReallyReallyEnlarged
FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged AS c
CROSS JOIN
(
SELECT TOP 10 Number FROM master..spt_values
) AS x;
CREATE CLUSTERED INDEX so ON dbo.SalesOrderDetailReallyReallyEnlarged
(SalesOrderID,SalesOrderDetailID);
-- I also made this index non-unique:
CREATE NONCLUSTERED INDEX rg ON dbo.SalesOrderDetailReallyReallyEnlarged(rowguid);
CREATE NONCLUSTERED INDEX p ON dbo.SalesOrderDetailReallyReallyEnlarged(ProductID); Debido a las limitaciones de espacio en disco, tuve que salir de la máquina virtual de mi computadora portátil para esta prueba (y elegí una caja de 40 núcleos, con 128 GB de RAM, que estaba casi inactiva :-)), y aún así no fue un proceso rápido de ninguna manera. El llenado de la tabla y la creación de los índices tomó ~24 minutos.
La tabla tiene 48,5 millones de filas y ocupa 7,9 GB en disco (4,9 GB en datos y 2,9 GB en índice).
Esta vez, mi consulta para determinar un buen conjunto de candidatos ProductID valores para eliminar:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailReallyReallyEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Dio los siguientes resultados:
ProductID ProductCount --------- ------------ 870 1828320 712 1318980 873 1308060
Entonces vamos a eliminar 4.455.360 filas, un poco menos del 10% de la tabla. Siguiendo un patrón similar a la prueba anterior, vamos a eliminar todo de una vez, luego en fragmentos de 500 000, 250 000 y 100 000 filas.
Resultados:
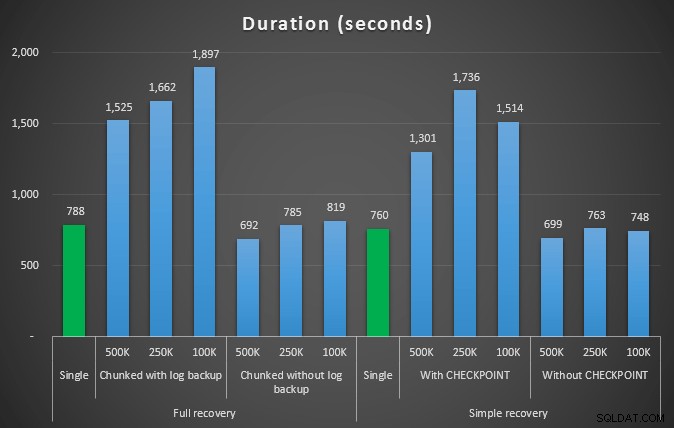 Duración, en segundos, de varias operaciones de eliminación que eliminan 4,5 MM de filas
Duración, en segundos, de varias operaciones de eliminación que eliminan 4,5 MM de filas
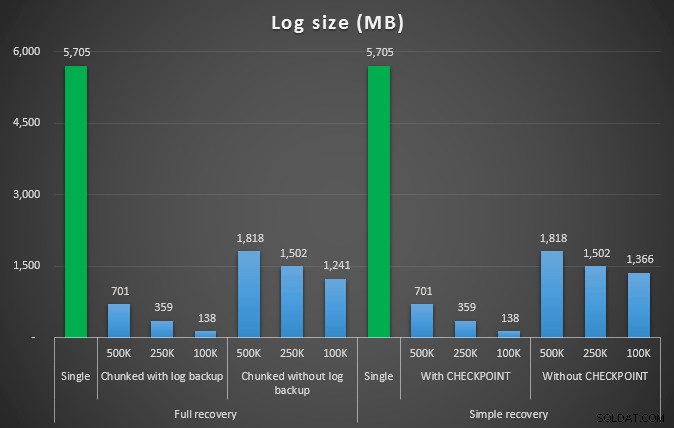 Tamaño de registro, en MB, después de varias operaciones de eliminación eliminando 4,5 MM de filas
Tamaño de registro, en MB, después de varias operaciones de eliminación eliminando 4,5 MM de filas
Entonces, nuevamente, vemos una reducción significativa en el tamaño del archivo de registro (más del 97% en los casos con el tamaño de fragmento más pequeño de 100K); sin embargo, a esta escala, vemos algunos casos en los que también logramos la eliminación en menos tiempo, incluso con todos los eventos de crecimiento automático que deben haber ocurrido. ¡Eso suena muy parecido a ganar-ganar para mí!
Esta vez con un tronco más grande
Ahora, tenía curiosidad de cómo estas diferentes eliminaciones se compararían con un archivo de registro de tamaño predeterminado para acomodar operaciones tan grandes. Siguiendo con nuestra base de datos más grande, expandí previamente el archivo de registro a 6 GB, hice una copia de seguridad y luego ejecuté las pruebas nuevamente:
ALTER DATABASE delete_test MODIFY FILE (NAME=delete_test_log, SIZE=6000MB);
Resultados, comparando la duración con un archivo de registro fijo con el caso en el que el archivo tuvo que crecer automáticamente de forma continua:
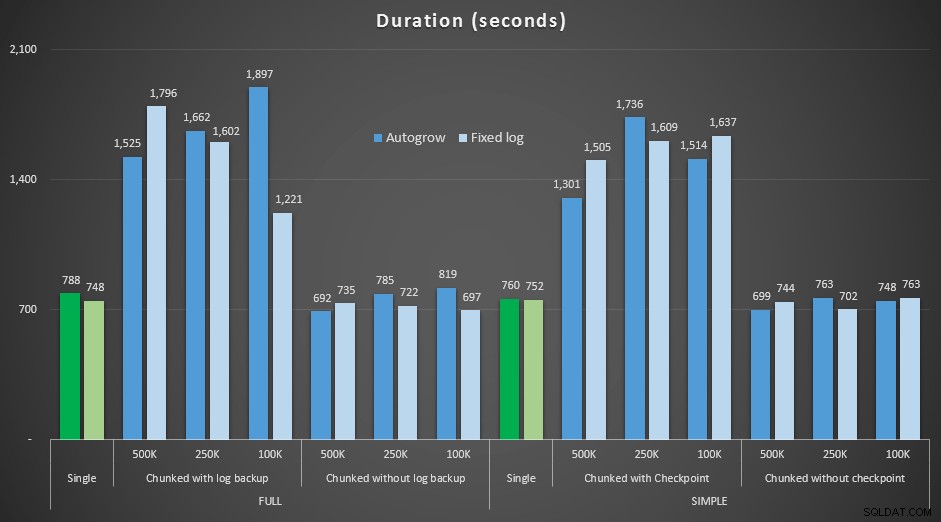
Duración, en segundos, de varias operaciones de eliminación que eliminan filas de 4,5 MM , comparando el tamaño de registro fijo y el crecimiento automático
Una vez más, vemos que los métodos que dividen las eliminaciones en lotes y *no* realizan una copia de seguridad del registro o un punto de control después de cada paso, compiten con la operación única equivalente en términos de duración. De hecho, vea que la mayoría se realiza en menos tiempo general, con la ventaja adicional de que otras transacciones podrán entrar y salir entre pasos. Lo cual es bueno, a menos que desee que esta operación de eliminación bloquee todas las transacciones no relacionadas.
Conclusión
Está claro que no hay una respuesta única y correcta a este problema:hay muchas variables inherentes de "depende". Puede ser necesario experimentar un poco para encontrar su número mágico, ya que habrá un equilibrio entre los gastos generales necesarios para hacer una copia de seguridad del registro y la cantidad de trabajo y tiempo que ahorra en diferentes tamaños de fragmentos. Pero si planea eliminar o archivar una gran cantidad de filas, es muy probable que, en general, le resulte mejor realizar los cambios en fragmentos, en lugar de en una sola transacción masiva, aunque los números de duración parecen hacer que una operación menos atractiva. No se trata solo de la duración:si no tiene un archivo de registro suficientemente preasignado y no tiene el espacio para acomodar una transacción tan masiva, probablemente sea mucho mejor minimizar el crecimiento del archivo de registro a costa de la duración. en cuyo caso querrá ignorar los gráficos de duración anteriores y prestar atención a los gráficos de tamaño de registro.
Si puede pagar el espacio, es posible que desee o no ajustar el tamaño de su registro de transacciones en consecuencia. Dependiendo del escenario, a veces usar la configuración predeterminada de crecimiento automático terminó un poco más rápido en mis pruebas que usar un archivo de registro fijo con mucho espacio. Además, puede ser difícil adivinar exactamente cuánto necesitará para acomodar una transacción grande que aún no ha realizado. Si no puede probar un escenario realista, haga todo lo posible para imaginar el peor de los casos; luego, por seguridad, duplíquelo. Kimberly Tripp (blog | @KimberlyLTripp) tiene algunos buenos consejos en esta publicación:8 pasos para mejorar el rendimiento del registro de transacciones; en este contexto, específicamente, mire el punto n.° 6. Independientemente de cómo decida calcular sus requisitos de espacio de registro, si va a terminar necesitando el espacio de todos modos, es mejor tomarlo de manera controlada con mucha anticipación, que detener sus procesos comerciales mientras esperan un crecimiento automático ( no importa múltiples!).
Otra faceta muy importante de esto que no midí explícitamente es el impacto en la concurrencia:un montón de transacciones más cortas, en teoría, tendrán menos impacto en las operaciones concurrentes. Si bien una sola eliminación tomó un poco menos de tiempo que las operaciones por lotes más largas, mantuvo todos sus bloqueos durante todo ese tiempo, mientras que las operaciones fragmentadas permitirían que otras transacciones en cola se colaran entre cada transacción. En una publicación futura, intentaré observar más de cerca este impacto (y también tengo planes para otros análisis más profundos).