Es muy fácil demostrar que las siguientes dos expresiones dan exactamente el mismo resultado:el primer día del mes actual.
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE())); Y tardan aproximadamente la misma cantidad de tiempo en calcular:
SELECT SYSDATETIME(); GO DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); GO 1000000 GO SELECT SYSDATETIME(); GO DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()); GO 1000000 SELECT SYSDATETIME();
En mi sistema, ambos lotes tardaron unos 175 segundos en completarse.
Entonces, ¿por qué preferiría un método sobre el otro? Cuando uno de ellos realmente se mete con las estimaciones de cardinalidad .
Como introducción rápida, comparemos estos dos valores:
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), -- today: 2013-09-01
DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0); -- today: 1786-05-01
--------------------------------------^^^^^^^^^^^^ notice how these are swapped
(Tenga en cuenta que los valores reales representados aquí cambiarán, dependiendo de cuándo lea esta publicación:"hoy" al que se hace referencia en el comentario es el 5 de septiembre de 2013, el día en que se escribió esta publicación. En octubre de 2013, por ejemplo, la salida será ser 2013-10-01 y 1786-04-01 .)
Con eso fuera del camino, déjame mostrarte lo que quiero decir...
Una reproducción
Vamos a crear una tabla muy simple, con solo un DATE agrupado columna y cargue 15 000 filas con el valor 1786-05-01 y 50 filas con el valor 2013-09-01 :
CREATE TABLE dbo.DateTest ( CreateDate DATE ); CREATE CLUSTERED INDEX x ON dbo.DateTest(CreateDate); INSERT dbo.DateTest(CreateDate) SELECT TOP (15000) DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 UNION ALL SELECT TOP (50) DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0) FROM sys.all_objects;
Y luego veamos los planes reales para estas dos consultas:
SELECT /* Query 1 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); SELECT /* Query 2 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
Los planos gráficos se ven bien:
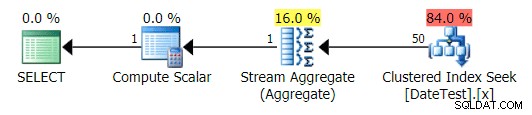
Plan gráfico para DATEDIFF(MES, 0, GETDATE()) consulta
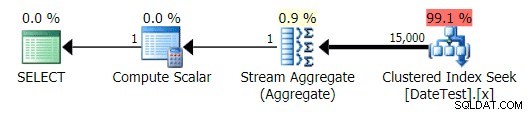
Plan gráfico para DATEDIFF(MES, GETDATE(), 0) consulta
Pero los costos estimados están fuera de control:tenga en cuenta cuánto más altos son los costos estimados para la primera consulta, que solo devuelve 50 filas, en comparación con la segunda consulta, ¡que devuelve 15 000 filas!

Cuadrícula de estado que muestra los costos estimados
Y la pestaña Operaciones principales muestra que la primera consulta (buscando 2013-09-01 ) estimó que encontraría 15.000 filas, cuando en realidad solo encontró 50; la segunda consulta muestra lo contrario:esperaba encontrar 50 filas que coincidieran con 1786-05-01 , pero encontró 15.000. Basado en estimaciones de cardinalidad incorrectas como esta, estoy seguro de que puede imaginar qué tipo de efecto drástico podría tener esto en consultas más complejas contra conjuntos de datos mucho más grandes.
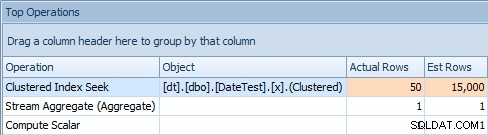
Pestaña Operaciones superior para la primera consulta [DATEDIFF(MES, 0, GETDATE())]
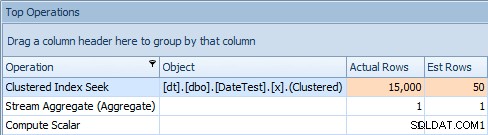
Pestaña Operaciones superior para la segunda consulta [DATEDIFF(MES, 0, GETDATE())]
Una variación ligeramente diferente de la consulta, que usa una expresión diferente para calcular el comienzo del mes (mencionada al comienzo de la publicación), no muestra este síntoma:
SELECT /* Query 3 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
El plan es muy similar a la consulta 1 anterior y, si no lo mirara más de cerca, pensaría que estos planes son equivalentes:
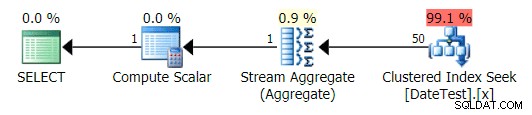
Plan gráfico para consulta sin DATEDIFF
Sin embargo, cuando observa la pestaña Operaciones principales aquí, ve que la estimación es perfecta:
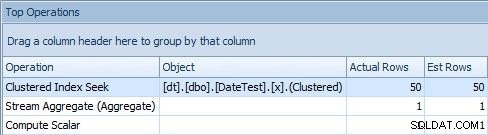
Pestaña Operaciones superior que muestra estimaciones precisas
En este tamaño de datos y consulta en particular, el impacto en el rendimiento neto (sobre todo la duración y las lecturas) es en gran medida irrelevante. Y es importante tener en cuenta que las consultas mismas aún devuelven datos correctos; es solo que las estimaciones son incorrectas (y podrían conducir a un plan peor que el que he demostrado aquí). Dicho esto, si está derivando constantes usando DATEDIFF dentro de sus consultas de esta manera, realmente debería probar este impacto en su entorno.
Entonces, ¿por qué sucede esto?
En pocas palabras, SQL Server tiene un DATEDIFF error donde intercambia el segundo y el tercer argumento al evaluar la expresión para la estimación de cardinalidad. Esto parece implicar un plegado constante, al menos en la periferia; hay muchos más detalles sobre el plegado constante en este artículo de Books Online pero, desafortunadamente, el artículo no revela ninguna información sobre este error en particular.
Hay una solución, ¿o sí?
Hay un artículo de la base de conocimientos (KB n.º 2481274) que pretende abordar el problema, pero tiene algunos problemas propios:
- El artículo de KB afirma que el problema se solucionó en varios paquetes de servicio o actualizaciones acumulativas para SQL Server 2005, 2008 y 2008 R2. Sin embargo, el síntoma todavía está presente en ramas que no se mencionan explícitamente allí, aunque han visto muchas CU adicionales desde que se publicó el artículo. Aún puedo reproducir este problema en SQL Server 2008 SP3 CU #8 (10.0.5828) y SQL Server 2012 SP1 CU #5 (11.0.3373).
- Omite mencionar que, para beneficiarse de la solución, debe activar el indicador de seguimiento 4199 (y "beneficiarse" de todas las otras formas en que el indicador de seguimiento específico puede afectar al optimizador). El hecho de que este indicador de seguimiento sea necesario para la corrección se menciona en un elemento relacionado de Connect, n.º 630583, pero esta información no ha regresado al artículo de KB. Ni el artículo de KB ni el elemento de conexión dan una idea de la causa (que los argumentos de
DATEDIFFhan sido intercambiados durante la evaluación). En el lado positivo, ejecutar las consultas anteriores con el indicador de rastreo activado (usandoOPTION (QUERYTRACEON 4199)) produce planes que no tienen el problema de estimación incorrecta.
- Sugiere que use SQL dinámico para solucionar el problema. En mis pruebas, usando una expresión diferente (como la anterior que no usa
DATEDIFF) superó el problema en las compilaciones modernas de SQL Server 2008 y SQL Server 2012. Recomendar SQL dinámico aquí es innecesariamente complejo y probablemente excesivo, dado que una expresión diferente podría resolver el problema. Pero si tuviera que usar SQL dinámico, lo haría de esta manera en lugar de la forma en que recomiendan en el artículo de KB, lo más importante para minimizar los riesgos de inyección de SQL:DECLARE @date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), @sql NVARCHAR(MAX) = N'SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @date;'; EXEC sp_executesql @sql, N'@date DATE', @date;(Y puede agregar
OPTION (RECOMPILE)allí, dependiendo de cómo desee que SQL Server maneje el análisis de parámetros).Esto lleva al mismo plan que la consulta anterior que no usa
DATEDIFF, con estimaciones adecuadas y el 99,1 % del costo en la búsqueda de índice agrupado.Otro enfoque que podría tentarlo (y por usted, me refiero a mí, cuando comencé a investigar) es usar una variable para calcular el valor de antemano:
DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
El problema con este enfoque es que, con una variable, terminará con un plan estable, pero la cardinalidad se basará en una conjetura (y el tipo de conjetura dependerá de la presencia o ausencia de estadísticas) . En este caso, aquí están los estimados frente a los reales:
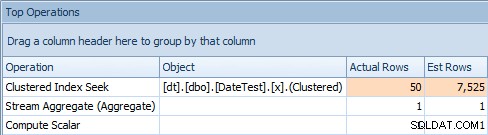
Pestaña Operaciones superior para consulta que usa una variableEsto claramente no está bien; parece que SQL Server ha adivinado que la variable coincidiría con el 50 % de las filas de la tabla.
Servidor SQL 2014
Encontré un problema ligeramente diferente en SQL Server 2014. Las dos primeras consultas están arregladas (mediante cambios en el estimador de cardinalidad u otras correcciones), lo que significa que DATEDIFF los argumentos ya no se cambian. ¡Hurra!
Sin embargo, parece que se ha introducido una regresión a la solución de usar una expresión diferente; ahora sufre de una estimación inexacta (basada en la misma conjetura del 50 % que usando una variable). Estas son las consultas que ejecuté:
SELECT /* 0, GETDATE() (2013) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0);
SELECT /* GETDATE(), 0 (1786) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
SELECT /* Non-DATEDIFF */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE());
SELECT /* Variable */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
DECLARE
@date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
@sql NVARCHAR(MAX) = N'SELECT /* Dynamic SQL */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = @date;';
EXEC sp_executesql @sql, N'@date DATE', @date; Aquí está la cuadrícula de declaraciones que compara los costos estimados y las métricas de tiempo de ejecución reales:
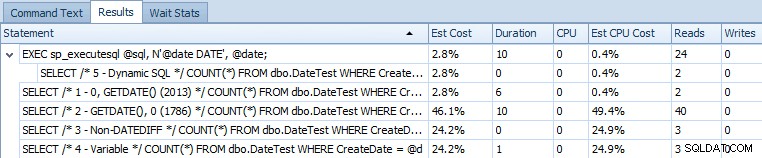
Costos estimados para las 5 consultas de muestra en SQL Server 2014
Y estos son sus recuentos de filas estimados y reales (ensamblados con Photoshop):

Recuento de filas estimado y real para las 5 consultas en SQL Server 2014
Está claro a partir de este resultado que la expresión que anteriormente resolvía el problema ahora ha introducido una diferente. No estoy seguro de si esto es un síntoma de ejecución en un CTP (por ejemplo, algo que se arreglará) o si esto realmente es una regresión.
En este caso, la marca de rastreo 4199 (por sí sola) no tiene efecto; el nuevo estimador de cardinalidad está haciendo conjeturas y simplemente no es correcto. Si conduce a un problema de rendimiento real depende mucho de muchos otros factores más allá del alcance de esta publicación.
Si se encuentra con este problema, puede, al menos en los CTP actuales, restaurar el comportamiento anterior usando OPTION (QUERYTRACEON 9481, QUERYTRACEON 4199) . Trace flag 9481 desactiva el nuevo estimador de cardinalidad, como se describe en estas notas de la versión (que seguramente desaparecerá o al menos se moverá en algún momento). Esto, a su vez, restaura las estimaciones correctas para los que no son DATEDIFF versión de la consulta, pero desafortunadamente aún no resuelve el problema en el que se adivina en función de una variable (y el uso de TF9481 solo, sin TF4199, obliga a las dos primeras consultas a regresar al antiguo comportamiento de intercambio de argumentos).
Conclusión
Admito que esto fue una gran sorpresa para mí. Felicitaciones a Martin Smith y t-clausen.dk por perseverar y convencerme de que este era un problema real y no imaginario. También muchas gracias a Paul White (@SQL_Kiwi) que me ayudó a mantener la cordura y me recordó las cosas que no debería decir. :-)
Al no estar al tanto de este error, insistí en que el mejor plan de consulta se generó simplemente cambiando el texto de la consulta, no debido al cambio específico. Resulta que, a veces, un cambio en una consulta que supondrías no hará ninguna diferencia, en realidad lo hará. Por lo tanto, recomiendo que si tiene patrones de consulta similares en su entorno, los pruebe y se asegure de que las estimaciones de cardinalidad sean correctas. Y tome nota para volver a probarlos cuando actualice.