En mi última publicación, demostré que en volúmenes pequeños, un TVP optimizado para memoria puede brindar beneficios de rendimiento sustanciales a los patrones de consulta típicos.
Para probar a una escala ligeramente mayor, hice una copia de SalesOrderDetailEnlarged table, que había ampliado a aproximadamente 5 000 000 de filas gracias a este script de Jonathan Kehayias (blog | @SQLPoolBoy)).
DROP TABLE dbo.SalesOrderDetailEnlarged; GO SELECT * INTO dbo.SalesOrderDetailEnlarged FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged; -- 4,973,997 rows CREATE CLUSTERED INDEX PK_SODE ON dbo.SalesOrderDetailEnlarged(SalesOrderID, SalesOrderDetailID);
También creé tres versiones en memoria de esta tabla, cada una con un recuento de cubetas diferente (buscando un "punto óptimo"):16 384, 131 072 y 1 048 576. (Puedes usar números más redondos, pero de todos modos se redondean a la siguiente potencia de 2). Ejemplo:
CREATE TABLE [dbo].[SalesOrderDetailEnlarged_InMem_16K] -- and _131K and _1MM ( [SalesOrderID] [int] NOT NULL, [SalesOrderDetailID] [int] NOT NULL, [CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [OrderQty] [smallint] NOT NULL, [ProductID] [int] NOT NULL, [SpecialOfferID] [int] NOT NULL, [UnitPrice] [money] NOT NULL, [UnitPriceDiscount] [money] NOT NULL, [LineTotal] [numeric](38, 6) NOT NULL, [rowguid] [uniqueidentifier] NOT NULL, [ModifiedDate] [datetime] NOT NULL PRIMARY KEY NONCLUSTERED HASH ( [SalesOrderID], [SalesOrderDetailID] ) WITH ( BUCKET_COUNT = 16384) -- and 131072 and 1048576 ) WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA ); GO INSERT dbo.SalesOrderDetailEnlarged_InMem_16K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_131K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_1MM SELECT * FROM dbo.SalesOrderDetailEnlarged; GO
Observe que cambié el tamaño del cubo del ejemplo anterior (256). Al crear la tabla, desea elegir el "punto óptimo" para el tamaño del depósito:desea optimizar el índice hash para las búsquedas de puntos, lo que significa que desea tantos depósitos como sea posible con la menor cantidad de filas posible en cada depósito. Por supuesto, si crea ~5 millones de cubos (ya que en este caso, quizás no sea un buen ejemplo, hay ~5 millones de combinaciones únicas de valores), tendrá que lidiar con algunas compensaciones de uso de memoria y recolección de basura. Sin embargo, si intenta meter ~5 millones de valores únicos en 256 cubos, también experimentará algunos problemas. En cualquier caso, esta discusión va mucho más allá del alcance de mis pruebas para esta publicación.
Para probar contra la tabla estándar, realicé procedimientos almacenados similares a los de las pruebas anteriores:
CREATE PROCEDURE dbo.SODE_InMemory
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @InMemory AS t
WHERE sode.SalesOrderID = t.Item);
END
GO
CREATE PROCEDURE dbo.SODE_Classic
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @Classic AS t
WHERE sode.SalesOrderID = t.Item);
END
GO Entonces, primero, mire los planes para, digamos, 1,000 filas que se insertan en las variables de la tabla y luego ejecuta los procedimientos:
DECLARE @InMemory dbo.InMemoryTVP; INSERT @InMemory SELECT TOP (1000) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); DECLARE @Classic dbo.ClassicTVP; INSERT @Classic SELECT Item FROM @InMemory; EXEC dbo.SODE_Classic @Classic = @Classic; EXEC dbo.SODE_InMemory @InMemory = @InMemory;
Esta vez, vemos que en ambos casos, el optimizador eligió una búsqueda de índice agrupado en la tabla base y una combinación de bucles anidados en el TVP. Algunas métricas de costos son diferentes, pero por lo demás los planes son bastante similares:
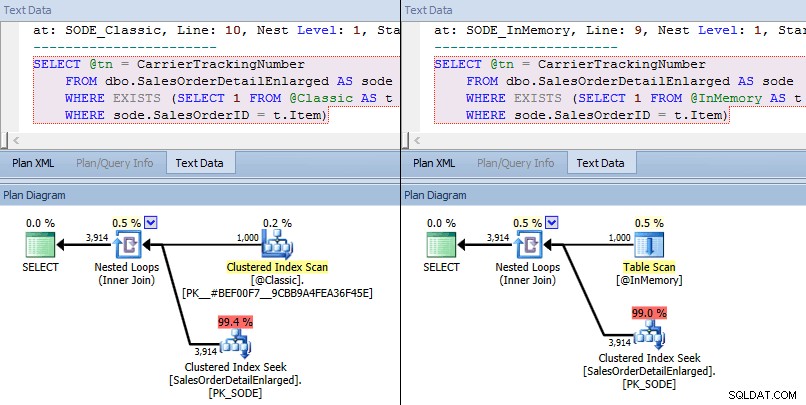 Planes similares para TVP en memoria frente a TVP clásico a mayor escala
Planes similares para TVP en memoria frente a TVP clásico a mayor escala
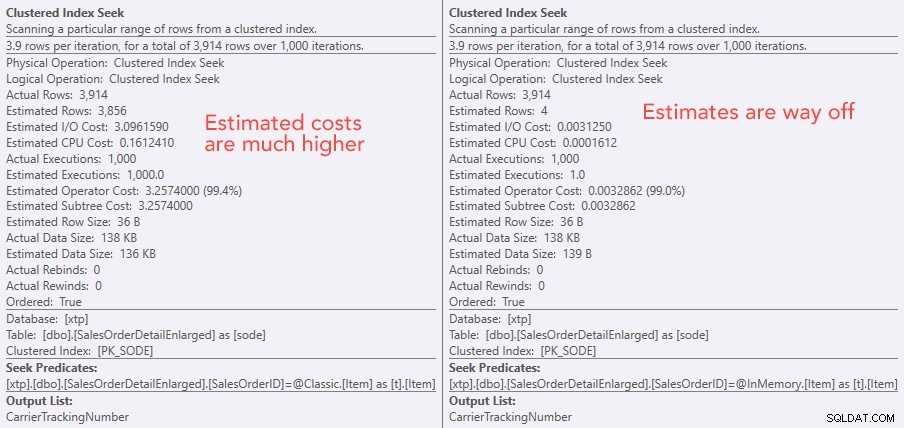 Comparación de los costos del operador de búsqueda:clásico a la izquierda, In-Memory a la derecha
Comparación de los costos del operador de búsqueda:clásico a la izquierda, In-Memory a la derecha
El valor absoluto de los costos hace que parezca que el TVP clásico sería mucho menos eficiente que el TVP In-Memory. Pero me preguntaba si esto sería cierto en la práctica (especialmente porque la cifra de Número estimado de ejecuciones a la derecha parecía sospechosa), así que, por supuesto, realicé algunas pruebas. Decidí comprobar los valores 100, 1000 y 2000 para enviarlos al procedimiento.
DECLARE @values INT = 100; -- 1000, 2000 DECLARE @Classic dbo.ClassicTVP; DECLARE @InMemory dbo.InMemoryTVP; INSERT @Classic(Item) SELECT TOP (@values) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); INSERT @InMemory(Item) SELECT Item FROM @Classic; DECLARE @i INT = 1; SELECT SYSDATETIME(); WHILE @i <= 10000 BEGIN EXEC dbo.SODE_Classic @Classic = @Classic; SET @i += 1; END SELECT SYSDATETIME(); SET @i = 1; WHILE @i <= 10000 BEGIN EXEC dbo.SODE_InMemory @InMemory = @InMemory; SET @i += 1; END SELECT SYSDATETIME();
Los resultados de rendimiento muestran que, en un mayor número de búsquedas de puntos, el uso de un TVP en memoria conduce a rendimientos ligeramente decrecientes, siendo un poco más lento cada vez:
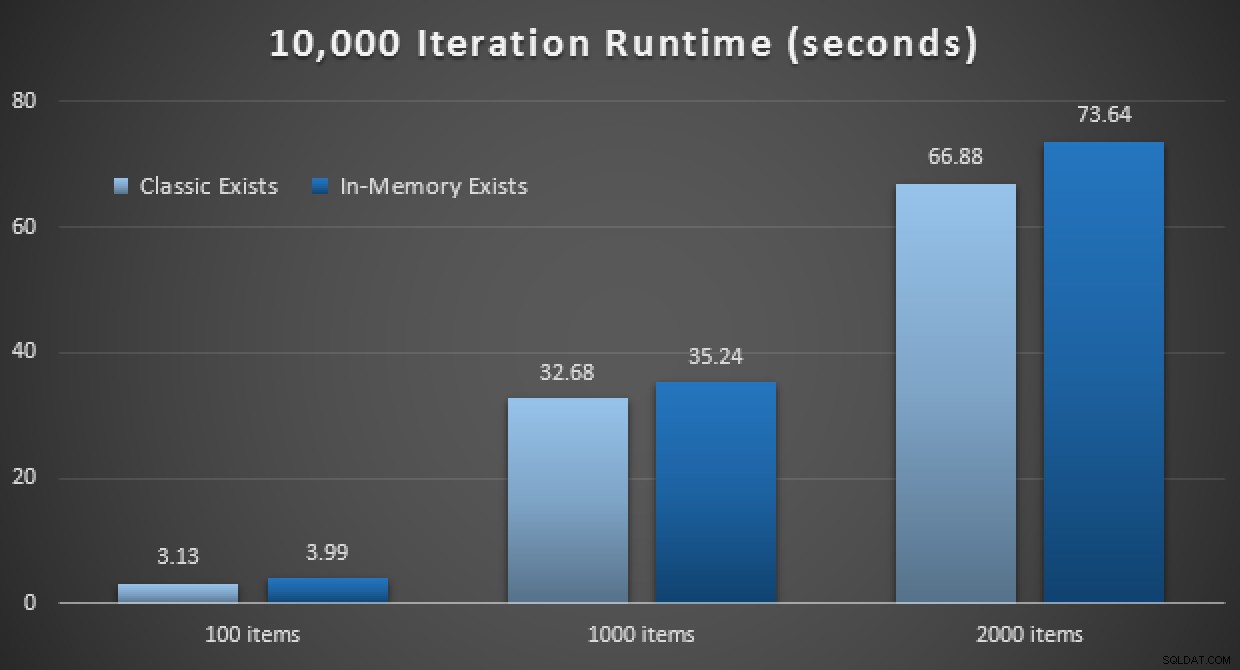
Resultados de 10 000 ejecuciones usando TVP clásicos y en memoria
Por lo tanto, contrariamente a la impresión que puede haber tenido de mi publicación anterior, el uso de un TVP en memoria no es necesariamente beneficioso en todos los casos.
Anteriormente, también analicé los procedimientos almacenados compilados de forma nativa y las tablas en memoria, en combinación con los TVP en memoria. ¿Podría esto hacer una diferencia aquí? Spoiler:absolutamente no. Creé tres procedimientos como este:
CREATE PROCEDURE [dbo].[SODE_Native_InMem_16K] -- and _131K and _1MM
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged_InMem_16K AS sode -- and _131K and _1MM
INNER JOIN @InMemory AS t -- no EXISTS allowed here
ON sode.SalesOrderID = t.Item;
END
GO Otro spoiler:no pude ejecutar estas 9 pruebas con un recuento de iteraciones de 10,000, tomó demasiado tiempo. En cambio, recorrí y ejecuté cada procedimiento 10 veces, ejecuté ese conjunto de pruebas 10 veces y saqué el promedio. Estos son los resultados:
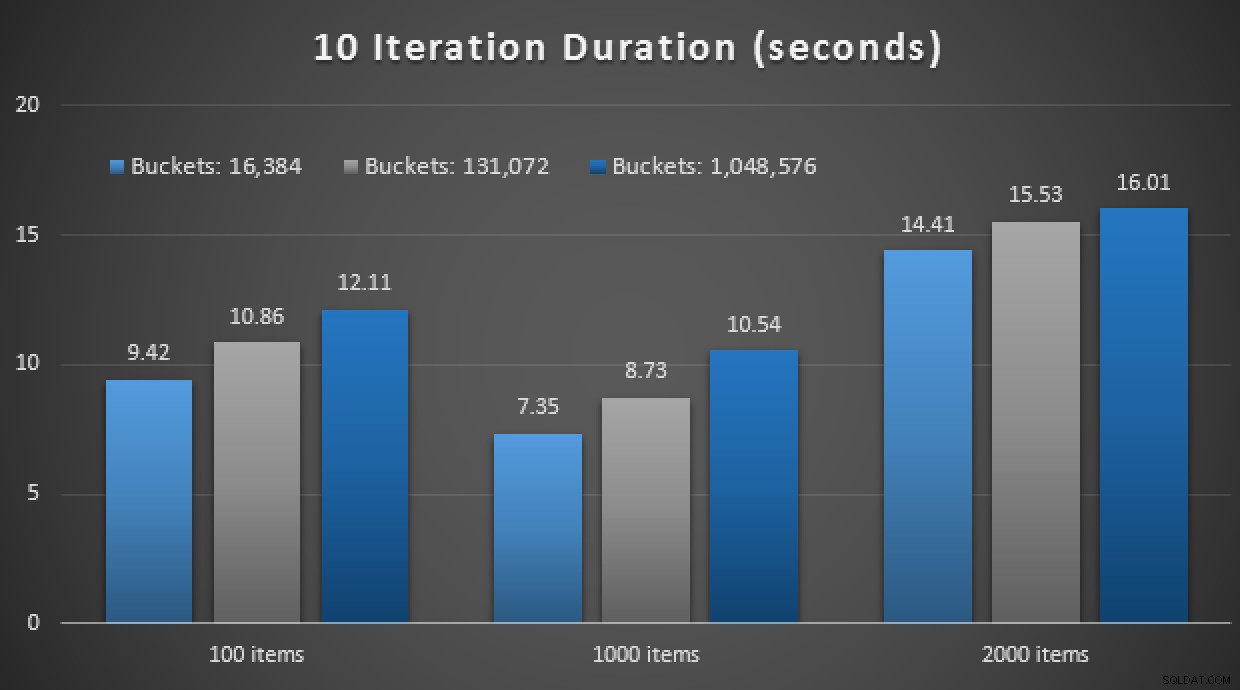
Resultados de 10 ejecuciones usando TVP en memoria y almacenamiento compilado de forma nativa procedimientos
En general, este experimento fue bastante decepcionante. Solo observando la magnitud de la diferencia, con una tabla en disco, la llamada de procedimiento almacenado promedio se completó en un promedio de 0,0036 segundos. Sin embargo, cuando todo usaba tecnologías en memoria, la llamada de procedimiento almacenado promedio fue de 1,1662 segundos. Ay . Es muy probable que haya elegido un caso de uso deficiente para la demostración general, pero en ese momento parecía ser un "primer intento" intuitivo.
Conclusión
Hay mucho más para probar en este escenario, y tengo más publicaciones de blog para seguir. Todavía no he identificado el caso de uso óptimo para TVP en memoria a mayor escala, pero espero que esta publicación sirva como un recordatorio de que, aunque una solución parece óptima en un caso, nunca es seguro asumir que es igualmente aplicable. a diferentes escenarios. Así es exactamente como se debe abordar In-Memory OLTP:como una solución con un conjunto limitado de casos de uso que deben validarse absolutamente antes de implementarse en producción.