Cualquier programador le dirá que escribir código multiproceso seguro puede ser difícil. Requiere gran cuidado y una buena comprensión de los aspectos técnicos involucrados. Como experto en bases de datos, podría pensar que este tipo de dificultades y complicaciones no se aplican al escribir T-SQL. Por lo tanto, puede sorprender un poco darse cuenta de que el código T-SQL también es vulnerable al tipo de condiciones de carrera y otros riesgos de integridad de datos más comúnmente asociados con la programación de subprocesos múltiples. Esto es cierto ya sea que estemos hablando de una sola instrucción T-SQL o de un grupo de instrucciones incluidas en una transacción explícita.
En el centro del problema está el hecho de que los sistemas de bases de datos permiten que se ejecuten múltiples transacciones al mismo tiempo. Este es un estado de cosas bien conocido (y muy deseable), sin embargo, una gran parte del código T-SQL de producción aún asume silenciosamente que los datos subyacentes no cambian durante la ejecución de una transacción o una declaración DML única como SELECT , INSERT , UPDATE , DELETE , o MERGE .
Incluso cuando el autor del código es consciente de los posibles efectos de los cambios de datos simultáneos, con demasiada frecuencia se supone que el uso de transacciones explícitas proporciona más protección de la que realmente se justifica. Estas suposiciones y conceptos erróneos pueden ser sutiles y ciertamente pueden engañar incluso a los profesionales de bases de datos experimentados.
Ahora, hay casos en los que estos temas no importarán mucho en un sentido práctico. Por ejemplo, la base de datos puede ser de solo lectura o puede haber alguna otra garantía genuina que nadie más cambiará los datos subyacentes mientras trabajamos con ellos. Igualmente, la operación en cuestión puede no requerir resultados que son exactamente correcto; nuestros consumidores de datos podrían estar perfectamente satisfechos con un resultado aproximado (incluso uno que no represente el estado comprometido de la base de datos en cualquier punto en el tiempo).
Problemas de concurrencia
La cuestión de la interferencia entre tareas que se ejecutan simultáneamente es un problema familiar para los desarrolladores de aplicaciones que trabajan en lenguajes de programación como C# o Java. Las soluciones son muchas y variadas, pero generalmente implican el uso de operaciones atómicas u obtener un recurso mutuamente excluyente (como un bloqueo ) mientras se está realizando una operación confidencial. Cuando no se toman las precauciones adecuadas, los resultados probables son datos dañados, un error o incluso un bloqueo total.
Muchos de los mismos conceptos (p. ej., operaciones atómicas y bloqueos) existen en el mundo de las bases de datos, pero lamentablemente a menudo tienen diferencias cruciales de significado. . La mayoría de las personas que trabajan con bases de datos conocen las propiedades ACID de las transacciones de bases de datos, donde la A significa atomic . SQL Server también usa bloqueos (y otros dispositivos de exclusión mutua internamente). Ninguno de estos términos significa exactamente lo que un programador experimentado de C# o Java esperaría razonablemente, y muchos profesionales de bases de datos también tienen una comprensión confusa de estos temas (como lo demostrará una búsqueda rápida utilizando su motor de búsqueda favorito).
Para reiterar, a veces estos problemas no serán una preocupación práctica. Si escribe una consulta para contar el número de pedidos activos en un sistema de base de datos, ¿qué importancia tiene si el recuento está un poco fuera de lugar? ¿O si refleja el estado de la base de datos en algún otro momento?
Es común que los sistemas reales hagan un compromiso entre concurrencia y consistencia (incluso si el diseñador no era consciente de ello en ese momento, informado). las compensaciones son quizás un animal más raro). Los sistemas reales a menudo funcionan bastante bien , con anomalías de corta duración o consideradas sin importancia. Un usuario que ve un estado inconsistente en una página web a menudo resolverá el problema al actualizar la página. Si se informa el problema, lo más probable es que se cierre como No reproducible. No digo que este sea un estado de cosas deseable, solo reconozco que sucede.
Sin embargo, es tremendamente útil para comprender los problemas de concurrencia a un nivel fundamental. Estar conscientes de ellos nos permite escribir correctamente (o informados) lo suficientemente correcto) T-SQL según lo requieran las circunstancias. Más importante aún, nos permite evitar escribir T-SQL que podría comprometer la integridad lógica de nuestros datos.
¡Pero SQL Server ofrece garantías ACID!
Sí, lo hace, pero no siempre son lo que cabría esperar y no protegen todo. La mayoría de las veces, los humanos leen mucho más en ACID de lo justificado.
Los componentes del acrónimo ACID que se malinterpretan con más frecuencia son las palabras Atómico, Consistente y Aislado; llegaremos a ellos en un momento. El otro, Duradero , es lo suficientemente intuitivo siempre que recuerde que se aplica solo a persistente (recuperable) usuario datos.
Dicho todo esto, SQL Server 2014 comienza a desdibujar un poco los límites de la propiedad Durable con la introducción de la durabilidad diferida general y la durabilidad solo del esquema OLTP en memoria. Los menciono solo para completar, no discutiremos más estas nuevas características. Pasemos a las propiedades ACID más problemáticas:
La propiedad atómica
Muchos lenguajes de programación proporcionan operaciones atómicas que se puede usar para proteger contra condiciones de carrera y otros efectos de concurrencia indeseables, donde múltiples subprocesos de ejecución pueden acceder o modificar estructuras de datos compartidas. Para el desarrollador de aplicaciones, una operación atómica viene con una garantía explícita de aislamiento total de los efectos de otro procesamiento concurrente en un programa de subprocesos múltiples.
Surge una situación análoga en el mundo de las bases de datos, donde múltiples consultas T-SQL acceden y modifican simultáneamente datos compartidos (es decir, la base de datos) desde diferentes subprocesos. Tenga en cuenta que aquí no estamos hablando de consultas paralelas; las consultas ordinarias de un solo subproceso se programan de forma rutinaria para ejecutarse simultáneamente dentro de SQL Server en subprocesos de trabajo separados.
Desafortunadamente, la propiedad atómica de transacciones SQL solo garantiza que las modificaciones de datos realizadas dentro de una transacción tengan éxito o fallen como una unidad . Nada más que eso. Ciertamente no hay garantía de aislamiento completo de los efectos de otro procesamiento concurrente. Observe también de pasada que la propiedad de transacción atómica no dice nada sobre ninguna garantía sobre lectura datos.
Declaraciones individuales
Tampoco hay nada especial en una sola declaración en el servidor SQL. Donde una transacción contenedora explícita (BEGIN TRAN...COMMIT TRAN ) no existe, aún se ejecuta una sola instrucción DML dentro de una transacción de confirmación automática. Las mismas garantías de ACID se aplican a una sola declaración y también las mismas limitaciones. En particular, una sola declaración viene sin garantías especiales de que los datos no cambiarán mientras está en progreso.
Considere la siguiente consulta de Toy AdventureWorks:
SELECT
TH.TransactionID,
TH.ProductID,
TH.ReferenceOrderID,
TH.ReferenceOrderLineID,
TH.TransactionDate,
TH.TransactionType,
TH.Quantity,
TH.ActualCost
FROM Production.TransactionHistory AS TH
WHERE TH.ReferenceOrderID =
(
SELECT TOP (1)
TH2.ReferenceOrderID
FROM Production.TransactionHistory AS TH2
WHERE TH2.TransactionType = N'P'
ORDER BY
TH2.Quantity DESC,
TH2.ReferenceOrderID ASC
); La consulta está destinada a mostrar información sobre el pedido que ocupa el primer lugar por cantidad. El plan de ejecución es el siguiente:
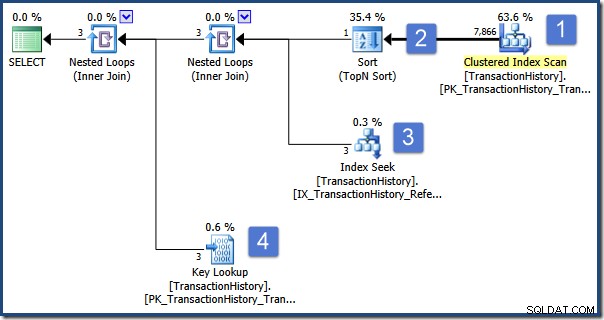
Las principales operaciones de este plan son:
- Explore la tabla para encontrar filas con el tipo de transacción requerida
- Encuentre el ID de pedido que se clasifique más alto según la especificación en la subconsulta
- Encuentre las filas (en la misma tabla) con el ID de pedido seleccionado utilizando un índice no agrupado
- Busque los datos de la columna restante utilizando el índice agrupado
Ahora imagine que un usuario simultáneo modifica la Orden 495, cambiando su Tipo de transacción de P a W, y confirma ese cambio en la base de datos. Por suerte, esta modificación se lleva a cabo mientras nuestra consulta realiza la operación de clasificación (paso 2).
Cuando se completa la ordenación, la búsqueda de índice en el paso 3 encuentra las filas con el ID de pedido seleccionado (que resulta ser 495) y la Búsqueda de clave en el paso 4 obtiene las columnas restantes de la tabla base (donde el Tipo de transacción ahora es W) .
Esta secuencia de eventos significa que nuestra consulta produce un resultado aparentemente imposible:

En lugar de encontrar pedidos con el tipo de transacción P como especificó la consulta, los resultados muestran el tipo de transacción W.
La causa principal es clara:nuestra consulta asumió implícitamente que los datos no podían cambiar mientras nuestra consulta de declaración única estaba en curso. La ventana de oportunidad en este caso era relativamente grande debido al tipo de bloqueo, pero el mismo tipo de condición de carrera puede ocurrir en cualquier etapa de la ejecución de la consulta, en términos generales. Naturalmente, los riesgos suelen ser mayores con mayores niveles de modificaciones simultáneas, tablas más grandes y donde aparecen operadores de bloqueo en el plan de consulta.
Otro mito persistente en la misma área general es que MERGE es preferible a INSERT separado , UPDATE y DELETE sentencias porque la sola sentencia MERGE es atómico. Eso es una tontería, por supuesto. Volveremos a este tipo de razonamiento más adelante en la serie.
El mensaje general en este punto es que, a menos que se tomen medidas explícitas para garantizar lo contrario, las filas de datos y las entradas de índice pueden cambiar, moverse de posición o desaparecer por completo en cualquier momento durante el proceso de ejecución. Es bueno tener en cuenta una imagen mental de cambios constantes y aleatorios en la base de datos al escribir consultas T-SQL.
La Propiedad de Consistencia
La segunda palabra del acrónimo ACID también tiene una gama de posibles interpretaciones. En una base de datos de SQL Server, Coherencia significa solo que una transacción deja la base de datos en un estado que no viola ninguna restricción activa. Es importante apreciar completamente cuán limitada es esa afirmación:las únicas garantías ACID de integridad de datos y consistencia lógica son aquellas proporcionadas por restricciones activas.
SQL Server proporciona una gama limitada de restricciones para hacer cumplir la integridad lógica, incluida PRIMARY KEY , FOREIGN KEY , CHECK , UNIQUE y NOT NULL . Se garantiza que todos estos se satisfarán en el momento en que se confirme una transacción. Además, SQL Server garantiza la física integridad de la base de datos en todo momento, por supuesto.
Las restricciones integradas no siempre son suficientes para hacer cumplir todas las reglas comerciales y de integridad de datos que nos gustaría. Ciertamente, es posible ser creativo con las instalaciones estándar, pero rápidamente se vuelven complejas y pueden resultar en el almacenamiento de datos duplicados.
Como consecuencia, la mayoría de las bases de datos reales contienen al menos algunas rutinas T-SQL escritas para aplicar reglas adicionales, por ejemplo, en procedimientos almacenados y disparadores. La responsabilidad de garantizar que este código funcione correctamente recae completamente en el autor; la propiedad de consistencia no proporciona protecciones específicas.
Para enfatizar el punto, las pseudo-restricciones escritas en T-SQL deben funcionar correctamente sin importar las modificaciones concurrentes que puedan estar ocurriendo. Un desarrollador de aplicaciones podría proteger una operación confidencial como esa con una declaración de bloqueo. Lo más parecido que tienen los programadores de T-SQL a esa facilidad para el procedimiento almacenado en riesgo y el código de activación es el sp_getapplock comparativamente poco utilizado. procedimiento almacenado del sistema. Eso no quiere decir que sea la única opción, o incluso la preferida, solo que existe y puede ser la elección correcta en algunas circunstancias.
La propiedad de aislamiento
Esta es fácilmente la más malinterpretada de las propiedades de transacción de ACID.
En principio, un completamente aislado La transacción se ejecuta como la única tarea que se ejecuta contra la base de datos durante su vida útil. Otras transacciones solo pueden comenzar una vez que la transacción actual haya finalizado por completo (es decir, confirmada o revertida). Ejecutada de esta manera, una transacción sería verdaderamente una operación atómica , en el sentido estricto que una persona ajena a la base de datos le atribuiría a la frase.
En la práctica, las transacciones de bases de datos funcionan con un grado de aislamiento. especificado por el nivel de aislamiento de transacciones vigente actualmente (que se aplica igualmente a declaraciones independientes, recuerde). Este compromiso (el grado de aislamiento) es la consecuencia práctica de las compensaciones entre concurrencia y corrección mencionadas anteriormente. Un sistema que literalmente procesara las transacciones una por una, sin superposición en el tiempo, proporcionaría un aislamiento completo, pero el rendimiento general del sistema probablemente sería deficiente.
La próxima vez
La próxima parte de esta serie continuará el examen de los problemas de simultaneidad, las propiedades ACID y el aislamiento de transacciones con una mirada detallada al nivel de aislamiento serializable, otro ejemplo de algo que puede no significar lo que cree que significa.
[ Ver el índice de toda la serie ]


