En 2012, escribí una publicación de blog aquí destacando los enfoques para calcular una mediana. En esa publicación, traté un caso muy simple:queríamos encontrar la mediana de una columna en toda una tabla. Me han mencionado varias veces desde entonces que un requisito más práctico es calcular una mediana dividida . Al igual que con el caso básico, hay varias formas de resolver esto en varias versiones de SQL Server; no es sorprendente que algunos funcionen mucho mejor que otros.
En el ejemplo anterior, solo teníamos las columnas genéricas id y val. Hagamos esto más realista y digamos que tenemos vendedores y la cantidad de ventas que han realizado en algún período. Para probar nuestras consultas, primero creemos un montón simple con 17 filas y verifiquemos que todas produzcan los resultados que esperamos (el vendedor 1 tiene una mediana de 7,5 y el vendedor 2 tiene una mediana de 6,0):
CREATE TABLE dbo.Sales(SalesPerson INT, Amount INT); GO INSERT dbo.Sales WITH (TABLOCKX) (SalesPerson, Amount) VALUES (1, 6 ),(1, 11),(1, 4 ),(1, 4 ), (1, 15),(1, 14),(1, 4 ),(1, 9 ), (2, 6 ),(2, 11),(2, 4 ),(2, 4 ), (2, 15),(2, 14),(2, 4 );
Aquí están las consultas, que vamos a probar (¡con muchos más datos!) contra el montón anterior, así como con los índices de soporte. Descarté un par de consultas de la prueba anterior, que no se escalaron en absoluto o no se asignaron muy bien a las medianas particionadas (a saber, 2000_B, que usaba una tabla #temp, y 2005_A, que usaba una fila opuesta números). Sin embargo, he agregado algunas ideas interesantes de un artículo reciente de Dwain Camps (@DwainCSQL), que se basó en mi publicación anterior.
Servidor SQL 2000+
El único método del enfoque anterior que funcionó lo suficientemente bien en SQL Server 2000 como para incluirlo en esta prueba fue el enfoque "mínimo de la mitad, máximo del otro":
SELECT DISTINCT s.SalesPerson, Median = (
(SELECT MAX(Amount) FROM
(SELECT TOP 50 PERCENT Amount FROM dbo.Sales
WHERE SalesPerson = s.SalesPerson ORDER BY Amount) AS t)
+ (SELECT MIN(Amount) FROM
(SELECT TOP 50 PERCENT Amount FROM dbo.Sales
WHERE SalesPerson = s.SalesPerson ORDER BY Amount DESC) AS b)
) / 2.0
FROM dbo.Sales AS s; Honestamente, traté de imitar la versión de la tabla #temp que usé en el ejemplo más simple, pero no escaló bien en absoluto. Con 20 o 200 filas funcionó bien; en 2000 tardó casi un minuto; a 1.000.000 me di por vencido después de una hora. Lo he incluido aquí para la posteridad (haga clic para revelar).
CREATE TABLE #x
(
i INT IDENTITY(1,1),
SalesPerson INT,
Amount INT,
i2 INT
);
CREATE CLUSTERED INDEX v ON #x(SalesPerson, Amount);
INSERT #x(SalesPerson, Amount)
SELECT SalesPerson, Amount
FROM dbo.Sales
ORDER BY SalesPerson,Amount OPTION (MAXDOP 1);
UPDATE x SET i2 = i-
(
SELECT COUNT(*) FROM #x WHERE i <= x.i
AND SalesPerson < x.SalesPerson
)
FROM #x AS x;
SELECT SalesPerson, Median = AVG(0. + Amount)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE SalesPerson = x.SalesPerson
AND x.i2 - (SELECT MAX(i2) / 2.0 FROM #x WHERE SalesPerson = x.SalesPerson)
IN (0, 0.5, 1)
)
GROUP BY SalesPerson;
GO
DROP TABLE #x; Servidor SQL 2005+ 1
Esto utiliza dos funciones de ventana diferentes para derivar una secuencia y un recuento total de cantidades por vendedor.
SELECT SalesPerson, Median = AVG(1.0*Amount)
FROM
(
SELECT SalesPerson, Amount, rn = ROW_NUMBER() OVER
(PARTITION BY SalesPerson ORDER BY Amount),
c = COUNT(*) OVER (PARTITION BY SalesPerson)
FROM dbo.Sales
)
AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2)
GROUP BY SalesPerson; Servidor SQL 2005+ 2
Esto vino del artículo de Dwain Camps, que hace lo mismo que el anterior, de una manera un poco más elaborada. Básicamente, esto desvía las filas interesantes de cada grupo.
;WITH Counts AS
(
SELECT SalesPerson, c
FROM
(
SELECT SalesPerson, c1 = (c+1)/2,
c2 = CASE c%2 WHEN 0 THEN 1+c/2 ELSE 0 END
FROM
(
SELECT SalesPerson, c=COUNT(*)
FROM dbo.Sales
GROUP BY SalesPerson
) a
) a
CROSS APPLY (VALUES(c1),(c2)) b(c)
)
SELECT a.SalesPerson, Median=AVG(0.+b.Amount)
FROM
(
SELECT SalesPerson, Amount, rn = ROW_NUMBER() OVER
(PARTITION BY SalesPerson ORDER BY Amount)
FROM dbo.Sales a
) a
CROSS APPLY
(
SELECT Amount FROM Counts b
WHERE a.SalesPerson = b.SalesPerson AND a.rn = b.c
) b
GROUP BY a.SalesPerson; Servidor SQL 2005+ 3
Esto se basó en una sugerencia de Adam Machanic en los comentarios de mi publicación anterior, y también fue mejorada por Dwain en su artículo anterior.
;WITH Counts AS
(
SELECT SalesPerson, c = COUNT(*)
FROM dbo.Sales
GROUP BY SalesPerson
)
SELECT a.SalesPerson, Median = AVG(0.+Amount)
FROM Counts a
CROSS APPLY
(
SELECT TOP (((a.c - 1) / 2) + (1 + (1 - a.c % 2)))
b.Amount, r = ROW_NUMBER() OVER (ORDER BY b.Amount)
FROM dbo.Sales b
WHERE a.SalesPerson = b.SalesPerson
ORDER BY b.Amount
) p
WHERE r BETWEEN ((a.c - 1) / 2) + 1 AND (((a.c - 1) / 2) + (1 + (1 - a.c % 2)))
GROUP BY a.SalesPerson; Servidor SQL 2005+ 4
Esto es similar a "2005+ 1" anterior, pero en lugar de usar COUNT(*) OVER() para derivar los recuentos, realiza una autocombinación con un agregado aislado en una tabla derivada.
SELECT SalesPerson, Median = AVG(1.0 * Amount)
FROM
(
SELECT s.SalesPerson, s.Amount, rn = ROW_NUMBER() OVER
(PARTITION BY s.SalesPerson ORDER BY s.Amount), c.c
FROM dbo.Sales AS s
INNER JOIN
(
SELECT SalesPerson, c = COUNT(*)
FROM dbo.Sales GROUP BY SalesPerson
) AS c
ON s.SalesPerson = c.SalesPerson
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2)
GROUP BY SalesPerson; Servidor SQL 2012+ 1
Esta fue una contribución muy interesante del compañero MVP de SQL Server Peter "Peso" Larsson (@SwePeso) en los comentarios sobre el artículo de Dwain; usa CROSS APPLY y el nuevo OFFSET / FETCH funcionalidad de una manera aún más interesante y sorprendente que la solución de Itzik para el cálculo de la mediana más simple.
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median); Servidor SQL 2012+ 2
Finalmente, tenemos el nuevo PERCENTILE_CONT() función introducida en SQL Server 2012.
SELECT SalesPerson, Median = MAX(Median)
FROM
(
SELECT SalesPerson,Median = PERCENTILE_CONT(0.5) WITHIN GROUP
(ORDER BY Amount) OVER (PARTITION BY SalesPerson)
FROM dbo.Sales
)
AS x
GROUP BY SalesPerson; Las pruebas reales
Para probar el rendimiento de las consultas anteriores, vamos a crear una tabla mucho más sustancial. Vamos a tener 100 vendedores únicos, con 10 000 cifras de montos de ventas cada uno, para un total de 1 000 000 de filas. También vamos a ejecutar cada consulta en el montón tal como está, con un índice no agrupado agregado en (SalesPerson, Amount) y con un índice agrupado en las mismas columnas. Aquí está la configuración:
CREATE TABLE dbo.Sales(SalesPerson INT, Amount INT); GO --CREATE CLUSTERED INDEX x ON dbo.Sales(SalesPerson, Amount); --CREATE NONCLUSTERED INDEX x ON dbo.Sales(SalesPerson, Amount); --DROP INDEX x ON dbo.sales; ;WITH x AS ( SELECT TOP (100) number FROM master.dbo.spt_values GROUP BY number ) INSERT dbo.Sales WITH (TABLOCKX) (SalesPerson, Amount) SELECT x.number, ABS(CHECKSUM(NEWID())) % 99 FROM x CROSS JOIN x AS x2 CROSS JOIN x AS x3;
Y aquí están los resultados de las consultas anteriores, contra el montón, el índice no agrupado y el índice agrupado:
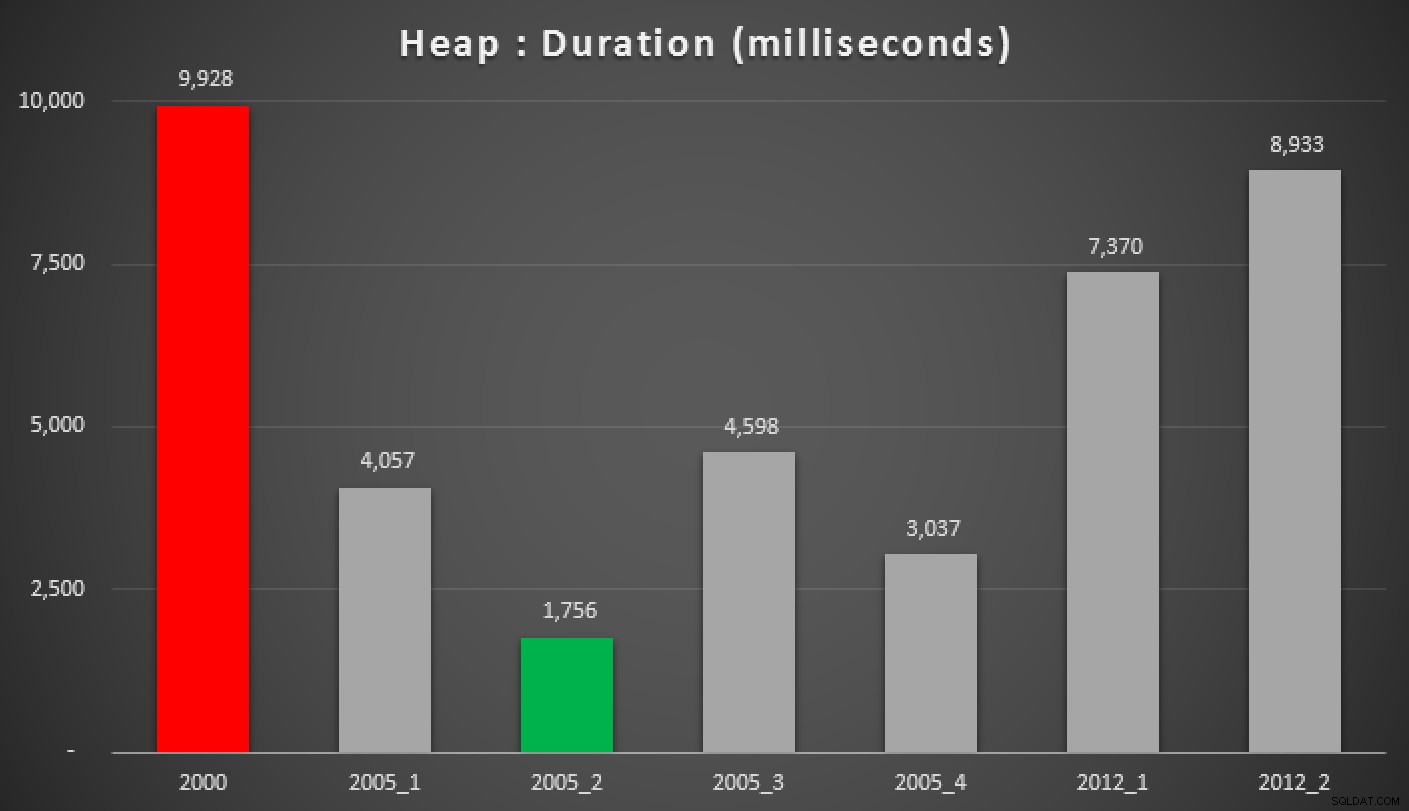
Duración, en milisegundos, de varios enfoques medianos agrupados (contra un montón)
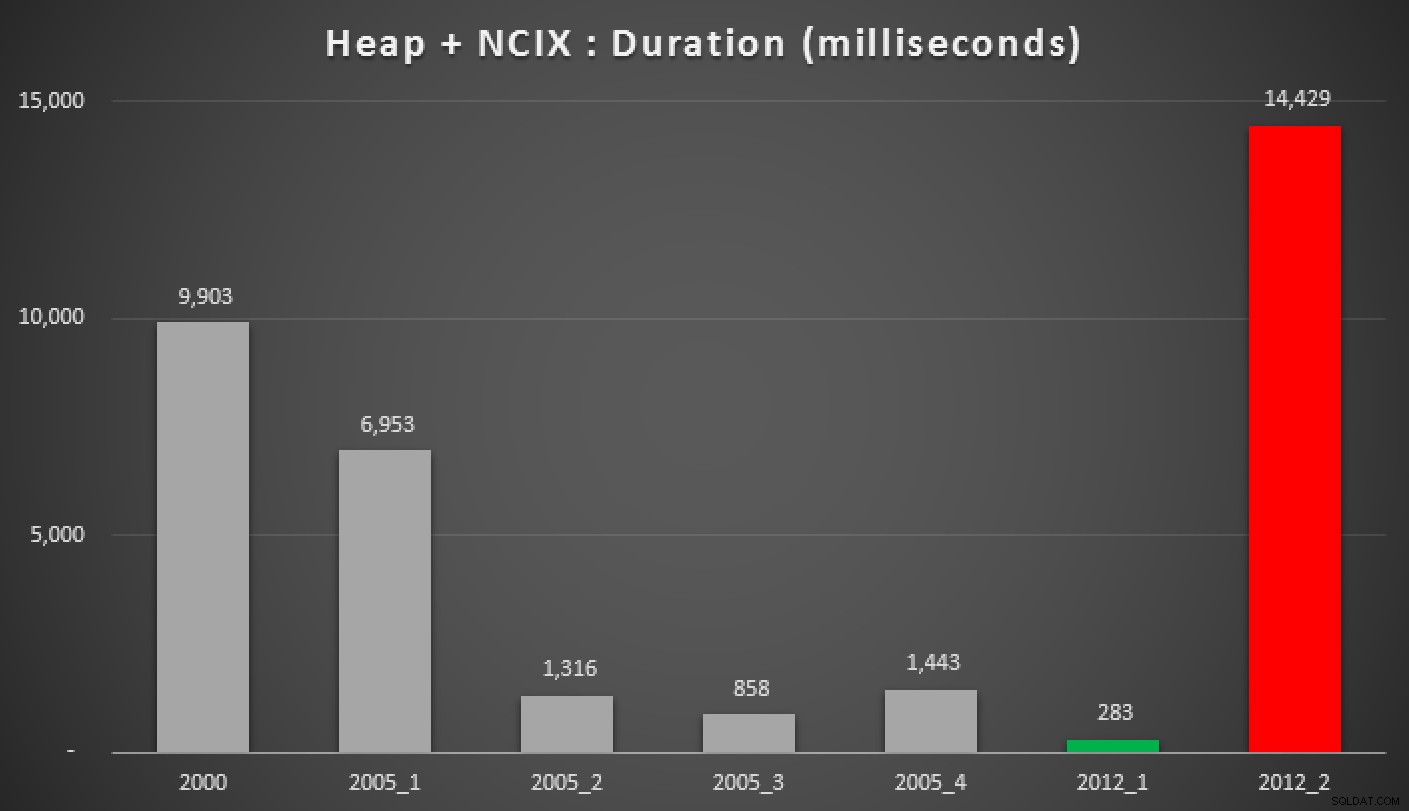
Duración, en milisegundos, de varios enfoques medianos agrupados (contra un montón con un índice no agrupado)
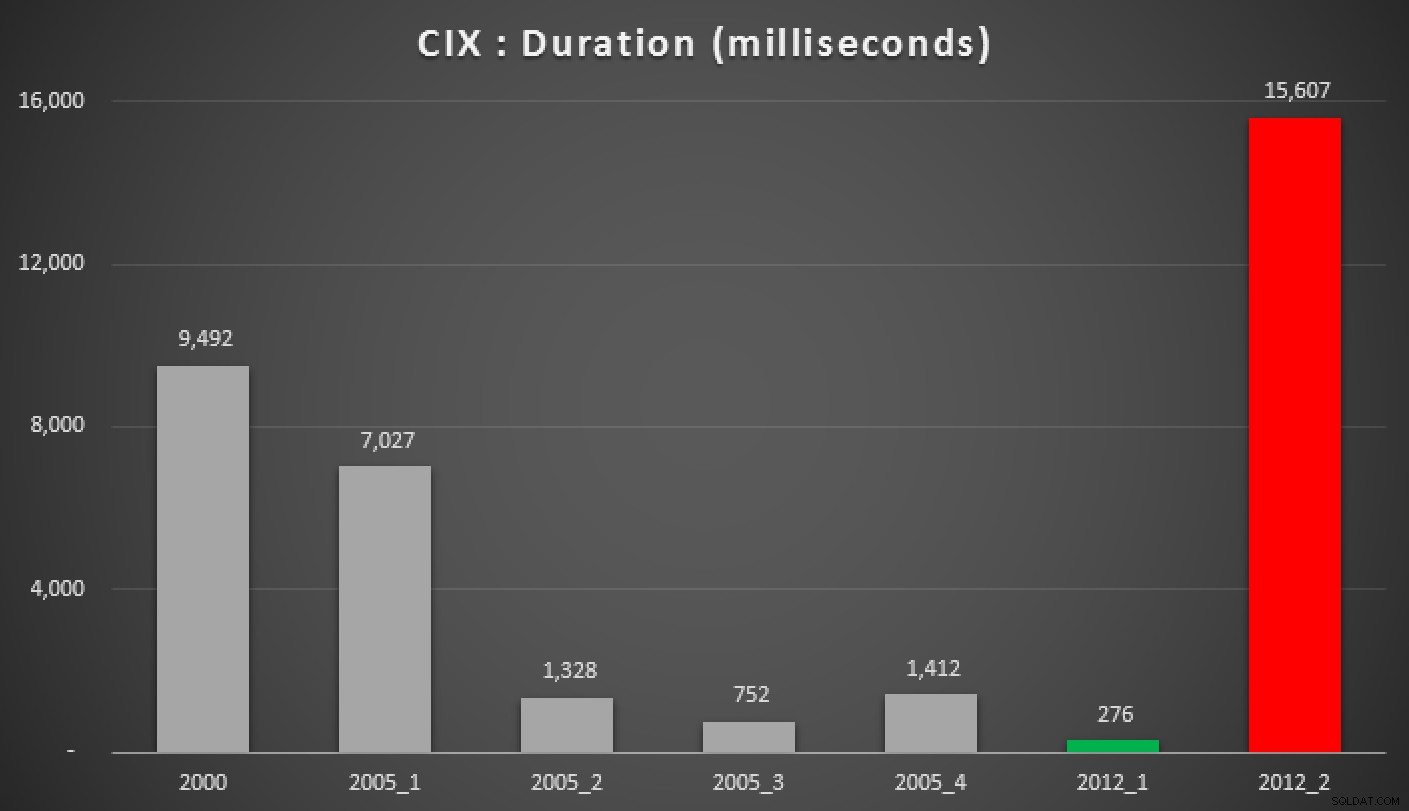
Duración, en milisegundos, de varios enfoques medianos agrupados (contra un índice agrupado)
¿Qué pasa con Hekatón?
Naturalmente, tenía curiosidad por saber si esta nueva función en SQL Server 2014 podría ayudar con alguna de estas consultas. Así que creé una base de datos In-Memory, dos versiones In-Memory de la tabla Sales (una con un índice hash en (SalesPerson, Amount) , y el otro solo en (SalesPerson) ), y volvió a ejecutar las mismas pruebas:
CREATE DATABASE Hekaton; GO ALTER DATABASE Hekaton ADD FILEGROUP xtp CONTAINS MEMORY_OPTIMIZED_DATA; GO ALTER DATABASE Hekaton ADD FILE (name = 'xtp', filename = 'c:\temp\hek.mod') TO FILEGROUP xtp; GO ALTER DATABASE Hekaton SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT ON; GO USE Hekaton; GO CREATE TABLE dbo.Sales1 ( ID INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED, SalesPerson INT NOT NULL, Amount INT NOT NULL, INDEX x NONCLUSTERED HASH (SalesPerson, Amount) WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); GO CREATE TABLE dbo.Sales2 ( ID INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED, SalesPerson INT NOT NULL, Amount INT NOT NULL, INDEX x NONCLUSTERED HASH (SalesPerson) WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); GO ;WITH x AS ( SELECT TOP (100) number FROM master.dbo.spt_values GROUP BY number ) INSERT dbo.Sales1 (SalesPerson, Amount) -- TABLOCK/TABLOCKX not allowed here SELECT x.number, ABS(CHECKSUM(NEWID())) % 99 FROM x CROSS JOIN x AS x2 CROSS JOIN x AS x3; INSERT dbo.Sales2 (SalesPerson, Amount) SELECT SalesPerson, Amount FROM dbo.Sales1;
Los resultados:
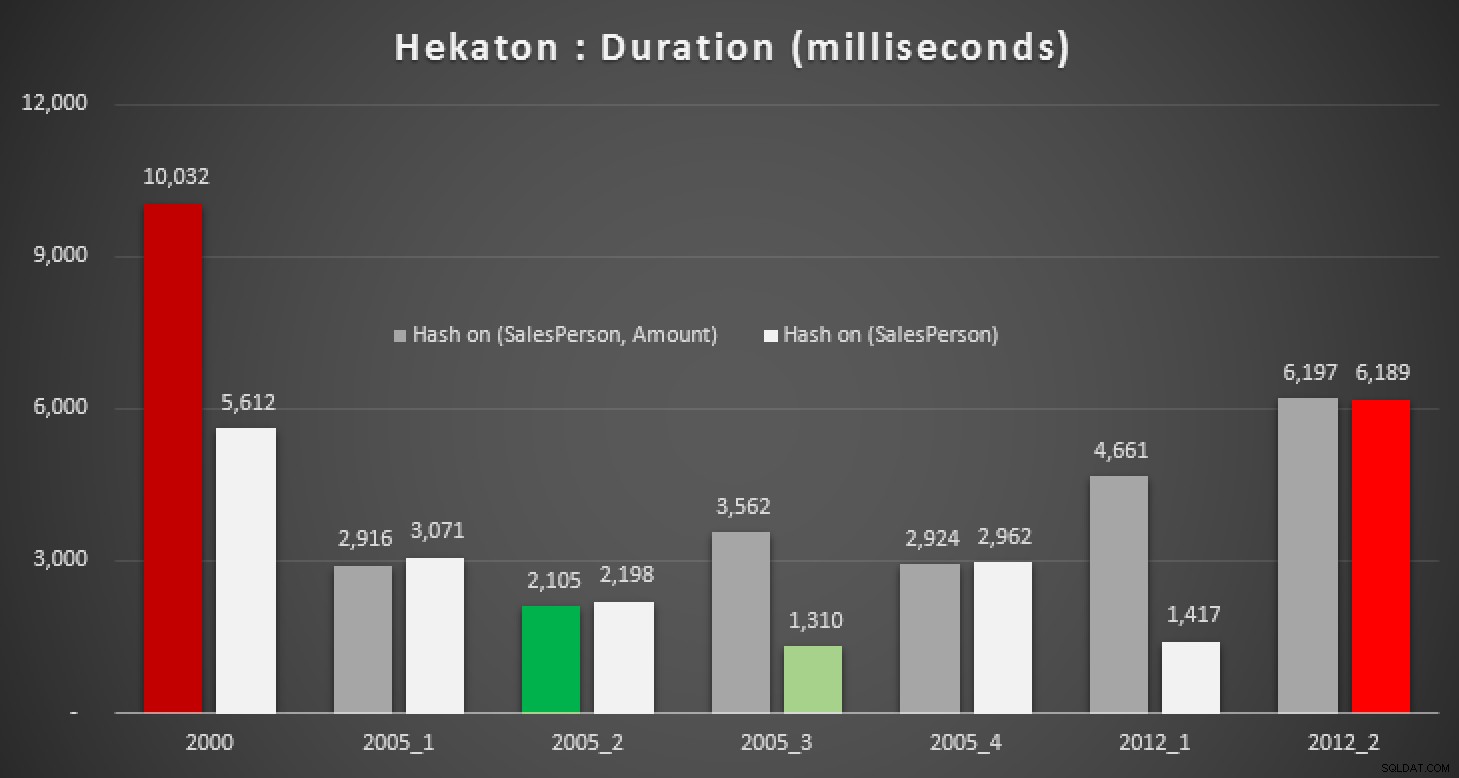
Duración, en milisegundos, para varios cálculos medianos contra In-Memory mesas
Incluso con el índice hash correcto, realmente no vemos mejoras significativas con respecto a una tabla tradicional. Además de eso, tratar de resolver el problema de la mediana utilizando un procedimiento almacenado compilado de forma nativa no será una tarea fácil, ya que muchas de las construcciones de lenguaje utilizadas anteriormente no son válidas (también me sorprendieron algunas). Intentar compilar todas las variaciones de consulta anteriores produjo este desfile de errores; algunos ocurrieron varias veces dentro de cada procedimiento, e incluso después de eliminar los duplicados, esto sigue siendo algo cómico:
Msg 10794, Nivel 16, Estado 47, Procedimiento GroupedMedian_2000La opción 'DISTINCT' no es compatible con procedimientos almacenados compilados de forma nativa.
Msg 12311, Nivel 16, Estado 37, Procedimiento GroupedMedian_2000
Subconsultas ( consultas anidadas dentro de otra consulta) no se admiten con procedimientos almacenados compilados de forma nativa.
Msj 10794, nivel 16, estado 48, procedimiento GroupedMedian_2000
La opción 'PERCENT' no se admite con procedimientos almacenados compilados de forma nativa.
Msg 12311, Nivel 16, Estado 37, Procedimiento GroupedMedian_2005_1
Las subconsultas (consultas anidadas dentro de otra consulta) no se admiten con procedimientos almacenados compilados de forma nativa.
Msg 10794, Nivel 16, Estado 91 , Procedimiento GroupedMedian_2005_1
La función agregada 'ROW_NUMBER' no es compatible con procedimientos almacenados compilados de forma nativa.
Msg 10794, Nivel 16, Estado 56, Procedimiento GroupedMedian_2005_1
El operador 'IN' no es compatible con procedimientos almacenados compilados de forma nativa.
Msg 12310, Nivel 16, Estado 36, Procedimiento GroupedMedian_2005_2
Expresiones de tabla común (CTE) no son compatibles con procedimientos almacenados compilados de forma nativa.
Msj 12309, Nivel 16, Estado 35, Procedimiento GroupedMedian_2005_2
Declaraciones del formulario INSERT…VALUES… que insertan filas múltiples no son compatibles con los procedimientos almacenados compilados de forma nativa.
Mensaje 10794, nivel 16, estado 53, procedimiento GroupedMedian_2005_2
El operador 'APPLY' no es compatible con los procedimientos almacenados compilados de forma nativa.
Msg 12311, nivel 16, estado 37, procedimiento GroupedMedian_2005_2
Las subconsultas (consultas anidadas dentro de otra consulta) no se admiten con procedimientos almacenados compilados de forma nativa.
Msg 10794, nivel 16, estado 91, procedimiento GroupedMedian_2005_2
La función agregada 'ROW_NUMBER' no es compatible con procedimientos almacenados compilados de forma nativa.
Msg 12310, nivel 16, estado 36, procedimiento GroupedMedian_2005_3
Las expresiones de tabla comunes (CTE) son no compatible con almacenamiento compilado de forma nativa procedimientos.
Msg 12311, nivel 16, estado 37, procedimiento GroupedMedian_2005_3
Las subconsultas (consultas anidadas dentro de otra consulta) no se admiten con procedimientos almacenados compilados de forma nativa.
Msg 10794, nivel 16, estado 91 , Procedimiento GroupedMedian_2005_3
La función agregada 'ROW_NUMBER' no es compatible con procedimientos almacenados compilados de forma nativa.
Msg 10794, Nivel 16, Estado 53, Procedimiento GroupedMedian_2005_3
El operador 'APPLY' no es compatible con procedimientos almacenados compilados de forma nativa.
Msg 12311, nivel 16, estado 37, procedimiento GroupedMedian_2005_4
Las subconsultas (consultas anidadas dentro de otra consulta) no se admiten con procedimientos almacenados compilados de forma nativa.
Msg El operador 'IN' no es compatible con almacenamiento compilado de forma nativa ed.
Mensaje 12311, nivel 16, estado 37, procedimiento GroupedMedian_2012_1
Las subconsultas (consultas anidadas dentro de otra consulta) no se admiten con procedimientos almacenados compilados de forma nativa.
Mensaje 10794, Nivel 16, Estado 38, Procedimiento GroupedMedian_2012_1
El operador 'OFFSET' no es compatible con procedimientos almacenados compilados de forma nativa.
Msg 10794, Nivel 16, Estado 53, Procedimiento GroupedMedian_2012_1
El operador 'APPLY' no se admite con procedimientos almacenados compilados de forma nativa.
Msj 12311, nivel 16, estado 37, procedimiento GroupedMedian_2012_2
Las subconsultas (consultas anidadas dentro de otra consulta) no se admiten con procedimientos almacenados compilados de forma nativa.
Mensaje 10794, Nivel 16, Estado 90, Procedimiento GroupedMedian_2012_2
La función agregada 'PERCENTILE_CONT' no es compatible con los procedimientos almacenados compilados de forma nativa.
Tal como está escrito actualmente, ninguna de estas consultas podría trasladarse a un procedimiento almacenado compilado de forma nativa. Tal vez algo para buscar en otra publicación de seguimiento.
Conclusión
Descartando los resultados de Hekaton, y cuando hay un índice de apoyo presente, la consulta de Peter Larsson ("2012+ 1") usando OFFSET / FETCH salió como el ganador de lejos en estas pruebas. Si bien es un poco más complejo que la consulta equivalente en las pruebas sin particiones, coincide con los resultados que observé la última vez.
En esos mismos casos, el 2000 MIN/MAX enfoque y PERCENTILE_CONT() de 2012 salieron como perros de verdad; de nuevo, al igual que mis pruebas anteriores contra el caso más simple.
Si aún no está en SQL Server 2012, entonces su siguiente mejor opción es "2005+ 3" (si tiene un índice de soporte) o "2005+ 2" si está tratando con un montón. Lo siento, tuve que idear un nuevo esquema de nombres para estos, principalmente para evitar confusiones con los métodos de mi publicación anterior.
Por supuesto, estos son mis resultados en comparación con un esquema y un conjunto de datos muy específicos. Al igual que con todas las recomendaciones, debe probar estos enfoques con su esquema y datos, ya que otros factores pueden influir en diferentes resultados.
Otra nota
Además de tener un desempeño deficiente y no ser compatible con los procedimientos almacenados compilados de forma nativa, otro punto débil de PERCENTILE_CONT() es que no se puede usar en modos de compatibilidad más antiguos. Si lo intentas, obtienes este error:
La función PERCENTILE_CONT no está permitida en el modo de compatibilidad actual. Solo está permitido en modo 110 o superior.