En mi publicación anterior de esta serie, demostré que no todos los escenarios de consulta pueden beneficiarse de las tecnologías In-Memory OLTP. De hecho, el uso de Hekaton en ciertos casos de uso puede tener un efecto perjudicial en el rendimiento (haga clic para ampliar):

Perfil del monitor de rendimiento durante la ejecución del procedimiento almacenado
Sin embargo, podría haber apilado el mazo contra Hekaton en ese escenario, de dos maneras:
- El tipo de tabla optimizada para memoria que creé tenía un recuento de cubos de 256, pero estaba pasando hasta 2000 valores para comparar. En una publicación de blog más reciente del equipo de SQL Server, explicaron que sobredimensionar el número de cubos es mejor que subdimensionarlo, algo que sabía en general, pero no me di cuenta que también tenía efectos significativos en las variables de la tabla:Mantener tenga en cuenta que para un índice hash, el bucket_count debe ser aproximadamente 1-2X el número de claves de índice únicas esperadas. El tamaño excesivo suele ser mejor que el tamaño insuficiente:si a veces inserta solo 2 valores en las variables, pero a veces inserta hasta 1000 valores, generalmente es mejor especificar
BUCKET_COUNT=1000.No discuten explícitamente la razón real de esto, y estoy seguro de que hay muchos detalles técnicos en los que podríamos profundizar, pero la guía prescriptiva parece ser demasiado grande.
- La clave principal era un índice hash en dos columnas, mientras que el parámetro con valores de tabla solo intentaba hacer coincidir los valores en una de esas columnas. Sencillamente, esto significaba que no se podía usar el índice hash. Tony Rogerson explica esto con un poco más de detalle en una publicación de blog reciente:El hash se genera en todas las columnas contenidas en el índice, también debe especificar todas las columnas en el índice hash en su expresión de verificación de igualdad; de lo contrario, no se puede usar el índice. .
No lo mostré antes, pero tenga en cuenta que el plan contra la tabla optimizada para memoria con el índice hash de dos columnas en realidad hace un escaneo de la tabla en lugar de la búsqueda de índice que podría esperar contra el índice hash no agrupado (ya que el índice principal la columna era
SalesOrderID):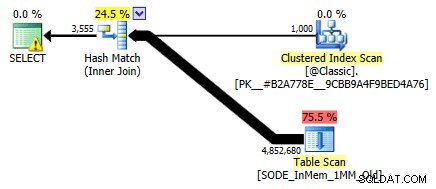
Plan de consulta que involucra una tabla en memoria con dos columnas índice hashPara ser más específicos, en un índice hash, la columna inicial no significa una montaña de frijoles por sí sola; el hash aún coincide en todas las columnas, por lo que no funciona en absoluto como un índice de árbol B tradicional (con un índice tradicional, un predicado que involucre solo la columna inicial podría ser muy útil para eliminar filas).
¿Qué hacer?
Bueno, primero, creé un índice hash secundario solo en el SalesOrderID columna. Un ejemplo de una de esas tablas, con un millón de cubos:
CREATE TABLE [dbo].[SODE_InMem_1MM]
(
[SalesOrderID] [int] NOT NULL,
[SalesOrderDetailID] [int] NOT NULL,
[CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[OrderQty] [smallint] NOT NULL,
[ProductID] [int] NOT NULL,
[SpecialOfferID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[UnitPriceDiscount] [money] NOT NULL,
[LineTotal] [numeric](38, 6) NOT NULL,
[rowguid] [uniqueidentifier] NOT NULL,
[ModifiedDate] [datetime] NOT NULL
PRIMARY KEY NONCLUSTERED HASH
(
[SalesOrderID],
[SalesOrderDetailID]
) WITH (BUCKET_COUNT = 1048576),
/* I added this secondary non-clustered hash index: */
INDEX x NONCLUSTERED HASH
(
[SalesOrderID]
) WITH (BUCKET_COUNT = 1048576)
/* I used the same bucket count to minimize testing permutations */
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); Recuerda que nuestros tipos de tablas se configuran de esta manera:
CREATE TYPE dbo.ClassicTVP AS TABLE ( Item INT PRIMARY KEY ); CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON);
Una vez que llené las nuevas tablas con datos y creé un nuevo procedimiento almacenado para hacer referencia a las nuevas tablas, el plan que obtuvimos muestra correctamente una búsqueda de índice contra el índice hash de una sola columna:

Plan mejorado usando el índice hash de una sola columna
Pero, ¿qué significaría eso realmente para el rendimiento? Volví a ejecutar el mismo conjunto de pruebas:consultas en esta tabla con recuentos de depósitos de 16 000, 131 000 y 1 MM; utilizando TVP clásicos y en memoria con valores 100, 1000 y 2000; y en el caso de TVP en memoria, utilizando un procedimiento almacenado tradicional y un procedimiento almacenado compilado de forma nativa. Así es como fue el rendimiento durante 10 000 iteraciones por combinación:

Perfil de rendimiento para 10 000 iteraciones contra un índice hash de una sola columna, usando un TVP de 256 cubos
Puede pensar, oye, ese perfil de rendimiento no se ve tan bien; al contrario, es mucho mejor que mi anterior prueba del mes pasado. Simplemente demuestra que el recuento de cubos para la tabla puede tener un gran impacto en la capacidad de SQL Server para usar el índice hash de manera efectiva. En este caso, usar un conteo de cubos de 16K claramente no es óptimo para ninguno de estos casos, y empeora exponencialmente a medida que aumenta la cantidad de valores en el TVP.
Ahora, recuerde, el conteo de cubos del TVP fue 256. Entonces, ¿qué pasaría si aumentara eso, según las instrucciones de Microsoft? Creé un segundo tipo de tabla con un tamaño de cubo más apropiado. Como estaba probando los valores 100, 1000 y 2000, usé la siguiente potencia de 2 para el conteo de cubetas (2048):
CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 2048) ) WITH (MEMORY_OPTIMIZED = ON);
Creé procedimientos de apoyo para esto y volví a ejecutar la misma batería de pruebas. Estos son los perfiles de rendimiento uno al lado del otro:

Comparación del perfil de rendimiento con TVP de 256 y 2048 cubos
El cambio en el recuento de cubos para el tipo de tabla no tuvo el impacto que esperaba, dada la declaración de Microsoft sobre el tamaño. Realmente no tuvo mucho efecto positivo en absoluto; de hecho, para algunos escenarios fue un poco peor. Pero, en general, los perfiles de rendimiento son, para todos los efectos, los mismos.
Sin embargo, lo que tuvo un gran efecto fue crear el índice hash *correcto* para admitir el patrón de consulta. Estaba agradecido de haber podido demostrar que, a pesar de mis pruebas anteriores que indicaban lo contrario, una tabla en memoria y un TVP en memoria podían vencer a la vieja escuela para lograr lo mismo. Tomemos el caso más extremo de mi ejemplo anterior, cuando la tabla solo tenía un índice hash de dos columnas:

Perfil de rendimiento para 10 iteraciones contra un índice hash de dos columnas
La barra más a la derecha muestra la duración de solo 10 iteraciones del procedimiento almacenado nativo que se compara con un índice hash inapropiado:tiempos de consulta que van desde 735 a 1601 milisegundos. Ahora, sin embargo, con el índice hash correcto, las mismas consultas se ejecutan en un rango mucho más pequeño:de 0,076 milisegundos a 51,55 milisegundos. Si omitimos el peor de los casos (recuentos de cubos de 16K), la discrepancia es aún más pronunciada. En todos los casos, esto es al menos el doble de eficiente (al menos en términos de duración) que cualquier método, sin un procedimiento almacenado compilado de forma ingenua, contra la misma tabla optimizada para memoria; y cientos de veces mejor que cualquiera de los enfoques contra nuestra antigua tabla optimizada para memoria con el único índice hash de dos columnas.
Conclusión
Espero haber demostrado que se debe tener mucho cuidado al implementar tablas optimizadas para memoria de cualquier tipo y que, en muchos casos, usar un TVP optimizado para memoria por sí solo puede no generar la mayor ganancia de rendimiento. Deberá considerar el uso de procedimientos almacenados compilados de forma nativa para obtener el máximo rendimiento de su inversión, y para escalar mejor, realmente querrá prestar atención al recuento de cubos para los índices hash en sus tablas optimizadas para memoria (pero quizás no mucha atención a sus tipos de tablas optimizadas para memoria).
Para leer más sobre la tecnología In-Memory OLTP en general, puede consultar estos recursos:
- Blog del equipo de SQL Server (Etiqueta:Hekaton y Etiqueta:OLTP en memoria:¿no son divertidos los nombres en clave?)
- Blog de Bob Beauchemin
- Blog de Klaus Aschenbrenner