Todas mis publicaciones este año han sido sobre reacciones instintivas a las estadísticas de espera, pero en esta publicación me estoy desviando de ese tema para hablar sobre un error mío en particular:el contador de rendimiento de la expectativa de vida de la página (que llamaré PLE ).
¿Qué significa PLE?
Hay todo tipo de afirmaciones incorrectas sobre la esperanza de vida de una página en Internet, y las más notorias son aquellas que especifican que el valor 300 es el umbral por el que deberías preocuparte.
Para comprender por qué esta declaración es tan engañosa, debe comprender qué es realmente PLE.
La definición de PLE es el tiempo esperado, en segundos, que una página de archivo de datos leída en el grupo de búfer (el caché en memoria de las páginas de archivos de datos) permanecerá en la memoria antes de ser expulsada de la memoria para dejar espacio para una información diferente. página de archivo. Otra forma de pensar en PLE es una medida instantánea de la presión sobre el grupo de búfer para liberar espacio para las páginas que se leen del disco. Para ambas definiciones, un número más alto es mejor.
¿Qué es un buen umbral de PLE?
Un PLE de 300 significa que todo el grupo de búfer se está vaciando y releyendo de manera efectiva cada cinco minutos. Cuando Microsoft proporcionó por primera vez la guía de umbral para PLE de 300, alrededor de 2005/2006, ese número puede haber tenido más sentido ya que la cantidad promedio de memoria en un servidor era mucho menor.
Hoy en día, donde los servidores tienen rutinariamente 64 GB, 128 GB y mayores cantidades de memoria, tener aproximadamente esa cantidad de datos que se leen del disco cada cinco minutos probablemente sea la causa de un problema de rendimiento paralizante
Entonces, en realidad, para cuando el PLE se mantenga en 300 o menos, su servidor ya se encuentra en una situación desesperada. Comenzarías a preocuparte mucho antes de que el PLE sea tan bajo.
Entonces, ¿cuál es el umbral a utilizar cuando debería estar preocupado?
Bueno, ese es solo el punto. No puedo darle un umbral, ya que ese número variará para todos. Si realmente desea usar un número, mi colega Jonathan Kehayias ideó una fórmula:
(Memoria de grupo de búfer en GB/4) x 300Incluso ese número es algo arbitrario y su millaje variará.
No me gusta recomendar ningún número. Mi consejo es que mida su PLE cuando el rendimiento esté en el nivel deseado:eso es el umbral que usas.
Entonces, ¿comienza a preocuparse tan pronto como el PLE cae por debajo de ese umbral? No. Comienza a preocuparse cuando el PLE cae por debajo de ese umbral y se mantiene por debajo de ese umbral, o si cae precipitadamente y no sabe por qué.
Esto se debe a que hay algunas operaciones que provocarán una caída de PLE (por ejemplo, ejecutar DBCC CHECKDB o las reconstrucciones de índices pueden hacerlo a veces) y no son motivo de preocupación. Pero si ve una gran caída del PLE y no sabe qué lo está causando, es cuando debería preocuparse.
Quizás se pregunte cómo DBCC CHECKDB puede causar una caída de PLE cuando se desfavorece y se esfuerza por evitar vaciar el grupo de búfer con los datos que usa (consulte esta publicación de blog para obtener una explicación). Es porque la concesión de memoria de ejecución de consultas para DBCC CHECKDB El Optimizador de consultas calcula mal y puede causar una gran reducción en el tamaño del grupo de búfer (la memoria para la concesión se roba del grupo de búfer) y una caída consiguiente en PLE.
¿Cómo se supervisa el PLE?
Esta es la parte complicada. La mayoría de la gente irá directamente al Buffer Manager objeto de rendimiento en PerfMon y supervisar la Page life expectancy mostrador. ¿Es este el enfoque correcto? Lo más probable es que no.
Diría que la gran mayoría de los servidores que existen hoy en día utilizan la arquitectura NUMA, y esto tiene un efecto profundo en la forma en que supervisa PLE.
Cuando NUMA está involucrado, el grupo de búfer se divide en nodos de búfer, con un nodo de búfer por nodo NUMA que SQL Server puede "ver". Cada nodo de búfer rastrea PLE por separado y el Buffer Manager:Page life expectancy contador es el promedio de los PLE del nodo de búfer. Si solo está monitoreando el grupo de búfer general PLE, entonces la presión en uno de los nodos de búfer puede estar enmascarada por el promedio (hablo de esto en una publicación de blog aquí).
Entonces, si su servidor usa NUMA, debe monitorear el Buffer Node:Page life expectancy individual. contadores (habrá un objeto de rendimiento de nodo de búfer para cada nodo NUMA), de lo contrario, es bueno monitorear el Buffer Manager:Page life expectancy contador.
Aún mejor es usar una herramienta de monitoreo como SQL Sentry Performance Advisor, que mostrará este contador como parte del tablero, teniendo en cuenta los nodos NUMA en el servidor, y le permitirá configurar alertas fácilmente.
Ejemplos del uso de Performance Advisor
A continuación se muestra una parte de ejemplo de una captura de pantalla de Performance Advisor para un sistema con un solo nodo NUMA:
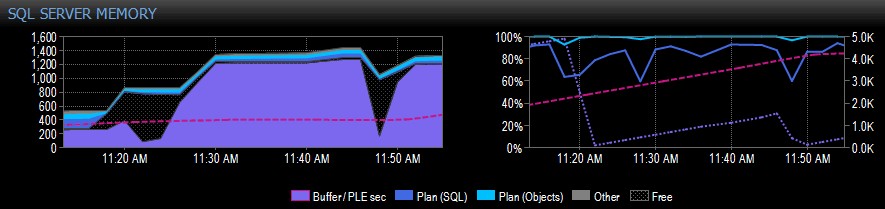
En el lado derecho de la captura, la línea punteada de color rosa es el PLE entre las 10:30 a. m. y las 11:20 a. m.; está aumentando de manera constante hasta aproximadamente 5000, un número realmente saludable. Justo antes de las 11:20 a. m. hay una gran caída y luego comienza a subir de nuevo hasta las 11:45 a. m., donde vuelve a caer.
Esto es típicamente lo que vería si el grupo de búfer está lleno, con todas las páginas en uso, y luego se ejecuta una consulta que hace que se lea una gran cantidad de datos diferentes del disco, desplazando gran parte de lo que ya está en la memoria y causando un Caída estrepitosa del PLE. Si no supiera qué causó algo como esto, querría investigar, como lo describo más adelante.
Como segundo ejemplo, la siguiente captura de pantalla es de uno de nuestros clientes DBA remotos donde el servidor tiene dos nodos NUMA (puede ver que hay dos líneas PLE moradas) y donde usamos Performance Advisor ampliamente:

En el servidor de este cliente, todas las mañanas alrededor de las 5 a. m., se inicia un trabajo de verificación de consistencia y mantenimiento del índice que hace que el PLE caiga en ambos nodos de búfer. Este es el comportamiento esperado, por lo que no es necesario investigar siempre que el PLE vuelva a aparecer durante el día.
¿Qué puede hacer con respecto a la caída de PLE?
Si no se conoce la causa de la caída del PLE, puede hacer varias cosas:
- Si el problema está ocurriendo ahora, investigue qué consultas están causando lecturas usando
sys.dm_os_waiting_tasksDMV para ver qué subprocesos están esperando que se lean las páginas del disco (es decir, aquellos que esperanPAGEIOLATCH_SH), y luego solucione esas consultas. - Si el problema ocurrió en el pasado, busque en el DMV sys.dm_exec_query_stats consultas con un alto número de lecturas físicas, o use una herramienta de monitoreo que pueda brindarle esa información (por ejemplo, la vista Top SQL en Performance Advisor) y luego solucione esas consultas.
- Correlacione la caída de PLE con los trabajos de agente programados que realizan el mantenimiento de la base de datos.
- Busque consultas con asignaciones de memoria de memoria de ejecución de consultas muy grandes mediante
sys.dm_exec_query_memory_grantsDMV y luego corregir esas consultas.
Mi publicación anterior aquí explica más sobre el n. ° 1 y el n. ° 2, y aquí hay un script para investigar las esperas que ocurren en un servidor y un enlace a sus planes de consulta.
El "arreglar esas consultas" está más allá del alcance de esta publicación, así que lo dejaré para otro momento o como un ejercicio para el lector ☺
Resumen
No caiga en la trampa de creer cualquier umbral PLE recomendado que pueda leer en línea. La mejor manera de reaccionar a los cambios del PLE es cuando el PLE cae por debajo de cualquier su el nivel de comodidad es y permanece ahí:eso es la indicación de un problema de rendimiento que debe investigar.
En el próximo artículo de la serie, analizaré otra causa común de ajuste de rendimiento instintivo. Hasta entonces, ¡feliz resolución de problemas!