En mi publicación anterior, discutí las esperas de CXPACKET y las formas de prevenir o limitar el paralelismo. También expliqué cómo el subproceso de control en una operación paralela siempre registra una espera de CXPACKET y que, a veces, los subprocesos que no son de control también pueden registrar esperas de CXPACKET. Esto puede suceder si uno de los subprocesos está bloqueado esperando un recurso (por lo que todos los demás subprocesos terminan antes que él y también registran las esperas de CXPACKET), o si las estimaciones de cardinalidad son incorrectas. En este post me gustaría explorar esto último.
Cuando las estimaciones de cardinalidad son incorrectas, los subprocesos paralelos que realizan el trabajo de consulta reciben cantidades desiguales de trabajo. El caso típico es donde un subproceso recibe todo el trabajo, o mucho más trabajo que los otros subprocesos. Esto significa que aquellos subprocesos que terminan de procesar sus filas (si es que les dieron alguna) antes que el subproceso más lento registran un CXPACKET desde el momento en que terminan hasta que finaliza el subproceso más lento. Este problema puede llevar a una aparente explosión en las esperas de CXPACKET y se denomina comúnmente paralelismo sesgado , porque la distribución del trabajo entre los hilos paralelos está sesgada, ni siquiera.
Tenga en cuenta que en SQL Server 2016 SP2 y SQL Server 2017 RTM CU3, los subprocesos de consumo ya no registran esperas de CXPACKET. Registran esperas de CXCONSUMER, que son benignas y se pueden ignorar. Esto es para reducir la cantidad de esperas de CXPACKET que se generan, y es más probable que las restantes sean accionables.
Ejemplo de paralelismo sesgado
Veré un ejemplo artificial para mostrar cómo identificar tales casos.
En primer lugar, crearé un escenario en el que una tabla tenga estadísticas muy imprecisas, configurando manualmente el número de filas y páginas en un ACTUALIZAR ESTADÍSTICAS declaración (¡no hagas esto en producción!):
USE [master];
GO
IF DB_ID (N'ExecutionMemory') IS NOT NULL
BEGIN
ALTER DATABASE [ExecutionMemory] SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE [ExecutionMemory];
END
GO
CREATE DATABASE [ExecutionMemory];
GO
USE [ExecutionMemory];
GO
CREATE TABLE dbo.[Test] (
[RowID] INT IDENTITY,
[ParentID] INT,
[CurrentValue] NVARCHAR (100),
CONSTRAINT [PK_Test] PRIMARY KEY CLUSTERED ([RowID]));
GO
INSERT INTO dbo.[Test] ([ParentID], [CurrentValue])
SELECT
CASE WHEN ([t1].[number] % 3 = 0)
THEN [t1].[number] – [t1].[number] % 6
ELSE [t1].[number] END,
'Test' + CAST ([t1].[number] % 2 AS VARCHAR(11))
FROM [master].[dbo].[spt_values] AS [t1]
WHERE [t1].[type] = 'P';
GO
UPDATE STATISTICS dbo.[Test] ([PK_Test]) WITH ROWCOUNT = 10000000, PAGECOUNT = 1000000;
GO Entonces, mi tabla solo tiene unas pocas miles de filas, pero he fingido que tiene 10 millones de filas.
Ahora crearé una consulta artificial para seleccionar las 500 filas principales, que irá en paralelo porque cree que hay millones de filas para escanear.
USE [ExecutionMemory];
GO
SET NOCOUNT ON;
GO
DECLARE @CurrentValue NVARCHAR (100);
WHILE (1=1)
SELECT TOP (500)
@CurrentValue = [CurrentValue]
FROM dbo.[Test]
ORDER BY NEWID() DESC;
GO Y ponlo en marcha.
Ver las esperas de CXPACKET
Ahora puedo ver las esperas de CXPACKET que se están produciendo usando un script simple para ver sys.dm_os_waiting_tasks DMV:
SELECT
[owt].[session_id],
[owt].[exec_context_id],
[owt].[wait_duration_ms],
[owt].[wait_type],
[owt].[blocking_session_id],
[owt].[resource_description],
[er].[database_id],
[eqp].[query_plan]
FROM sys.dm_os_waiting_tasks [owt]
INNER JOIN sys.dm_exec_sessions [es] ON
[owt].[session_id] = [es].[session_id]
INNER JOIN sys.dm_exec_requests [er] ON
[es].[session_id] = [er].[session_id]
OUTER APPLY sys.dm_exec_sql_text ([er].[sql_handle]) [est]
OUTER APPLY sys.dm_exec_query_plan ([er].[plan_handle]) [eqp]
WHERE
[es].[is_user_process] = 1
ORDER BY
[owt].[session_id],
[owt].[exec_context_id]; Si ejecuto esto varias veces, finalmente veo algunos resultados que muestran un paralelismo sesgado (eliminé el enlace del controlador del plan de consulta y reduje la descripción del recurso, para mayor claridad, y observe que introduje el código para obtener el texto SQL si lo desea). también):
| session_id | exec_context_id | esperar_duración_ms | tipo_espera | blocking_session_id | resource_description | id_base_de_datos |
|---|---|---|---|---|---|---|
56 | 0 | 1 | CXPACKET | NULL | exchangeEvent | 13 |
56 | 1 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
56 | 3 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
56 | 4 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
56 | 5 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
56 | 6 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
56 | 7 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
Resultados que muestran un paralelismo sesgado en acción
El hilo de control es el que tiene exec_context_id establecido en 0. Los otros subprocesos paralelos son aquellos con exec_context_id superior a 0, y todos muestran esperas de CXPACKET menos uno (tenga en cuenta que exec_context_id = 2 falta en la lista). Notarás que todos enumeran su propio session_id como el que los está bloqueando, y eso es correcto porque todos los subprocesos están esperando otro subproceso de su propio session_id completar. El id_base_de_datos es la base de datos en cuyo contexto se ejecuta la consulta, no necesariamente la base de datos donde se encuentra el problema, pero generalmente lo es, a menos que la consulta utilice nombres de tres partes para ejecutarse en una base de datos diferente.
Visualización del problema de estimación de cardinalidad
Con el query_plan columna en el resultado de la consulta (que eliminé para mayor claridad), puede hacer clic en él para que aparezca el plan gráfico y luego hacer clic con el botón derecho y seleccionar Ver con SQL Sentry Plan Explorer. Esto se muestra a continuación:
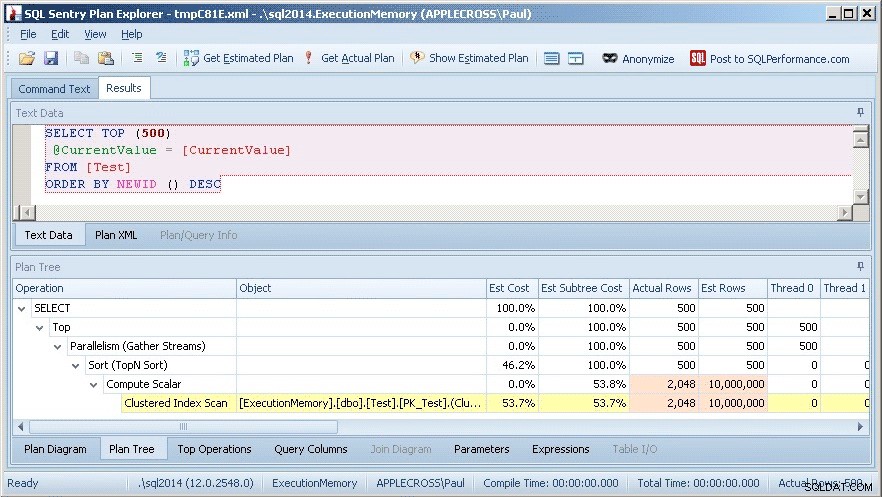
Inmediatamente puedo ver que hay un problema de estimación de cardinalidad, ya que las filas reales para el análisis de índice agrupado son solo 2048, en comparación con 10 000 000 filas estimadas (estimadas).
Si me desplazo, puedo ver la distribución de filas en los subprocesos paralelos que se usaron:
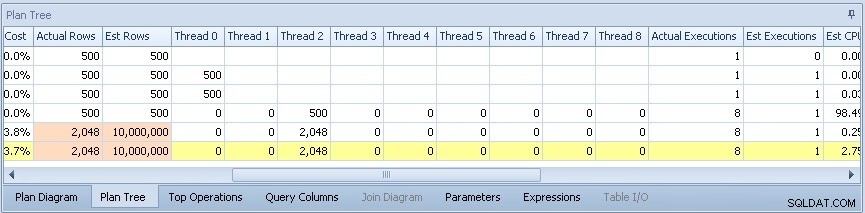
He aquí que solo un subproceso estaba haciendo algún trabajo durante la parte paralela del plan:el que no apareció en sys.dm_os_waiting_tasks salida arriba.
En este caso, la solución es actualizar las estadísticas de la tabla.
En mi ejemplo artificial, eso no funcionará, ya que no ha habido ninguna modificación en la tabla, así que volveré a ejecutar el script de configuración, omitiendo ACTUALIZAR ESTADÍSTICAS declaración.
El plan de consulta se convierte entonces en:
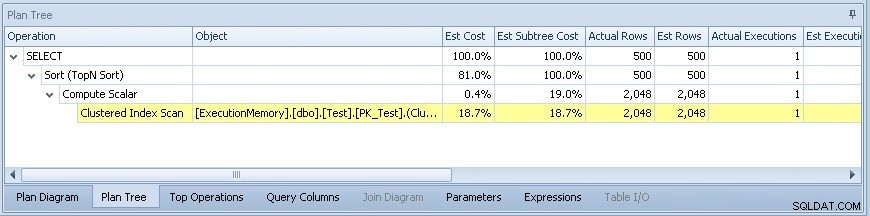
Donde no hay problema de cardinalidad ni tampoco de paralelismo, ¡problema resuelto!
Resumen
Si ve que se producen esperas de CXPACKET, es fácil comprobar si hay un paralelismo sesgado mediante el método descrito anteriormente. Todos los casos que he visto se deben a problemas de estimación de cardinalidad de un tipo u otro y, a menudo, es simplemente un caso de actualización de estadísticas.
En lo que respecta a las estadísticas generales de espera, puede encontrar más información sobre cómo usarlas para solucionar problemas de rendimiento en:
- La serie de publicaciones de mi blog SQLskills, que comienza con las estadísticas de espera o, por favor, dígame dónde le duele.
- Mi biblioteca de tipos de espera y clases de bloqueo aquí
- Curso de capacitación en línea My Pluralsight SQL Server:solución de problemas de rendimiento mediante estadísticas de espera
- Guardián SQL
Hasta la próxima, ¡feliz resolución de problemas!



