 Al crecer, me encantaban los juegos que ponían a prueba la memoria y las habilidades de combinación de patrones. Varios de mis amigos tenían a Simon, mientras que yo tenía una imitación llamada Einstein. Otros tenían un Atari Touch Me, que incluso en ese entonces sabía que era una decisión de nombre cuestionable. En estos días, la coincidencia de patrones significa algo muy diferente para mí y puede ser una parte costosa de las consultas diarias a la base de datos.
Al crecer, me encantaban los juegos que ponían a prueba la memoria y las habilidades de combinación de patrones. Varios de mis amigos tenían a Simon, mientras que yo tenía una imitación llamada Einstein. Otros tenían un Atari Touch Me, que incluso en ese entonces sabía que era una decisión de nombre cuestionable. En estos días, la coincidencia de patrones significa algo muy diferente para mí y puede ser una parte costosa de las consultas diarias a la base de datos.
Recientemente me encontré con un par de comentarios en Stack Overflow donde un usuario afirmaba, como si fuera un hecho, que CHARINDEX funciona mejor que LEFT o LIKE . En un caso, la persona citó un artículo de David Lozinski, "SQL:LIKE vs SUBSTRING vs LEFT/RIGHT vs CHARINDEX". Sí, el artículo muestra que, en el ejemplo artificial, CHARINDEX se desempeñó mejor. Sin embargo, dado que siempre soy escéptico acerca de declaraciones generales como esa, y no podía pensar en una razón lógica por la que una función de cadena siempre desempeñarse mejor que otro, con todo lo demás igual , Corrí sus pruebas. Efectivamente, obtuve resultados repetidamente diferentes en mi máquina (haga clic para ampliar):
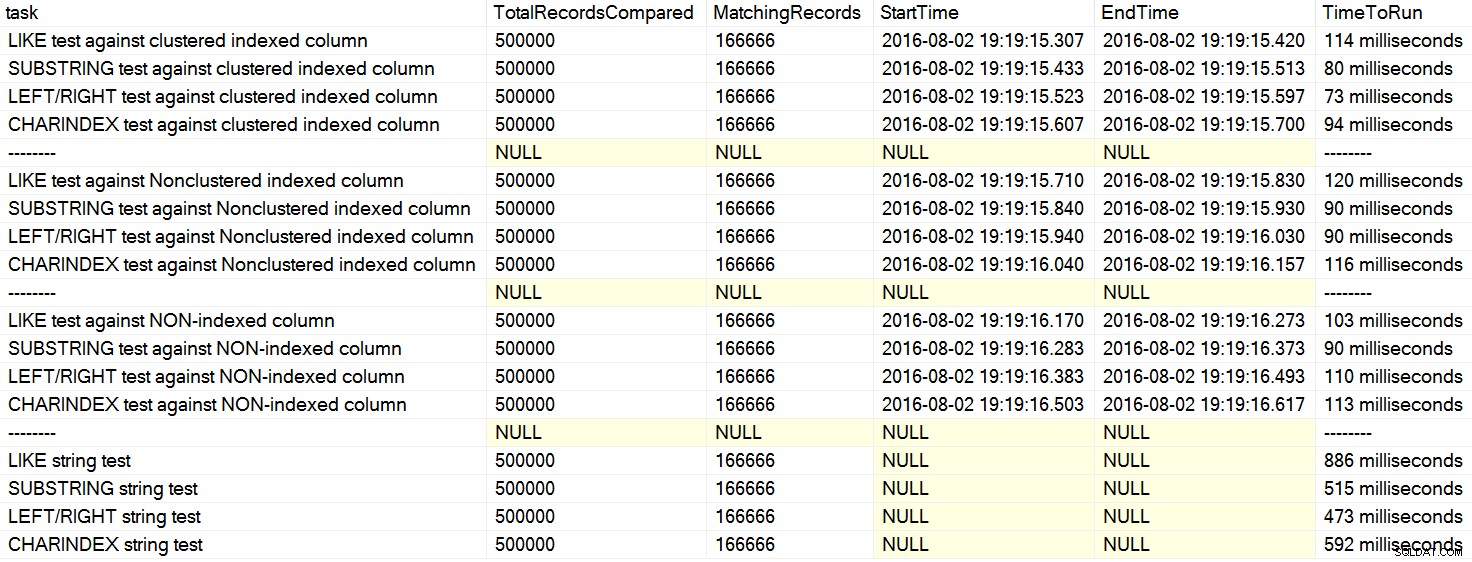 En mi máquina, CHARINDEX era más lento que IZQUIERDA/DERECHA/SUBCADENA.
En mi máquina, CHARINDEX era más lento que IZQUIERDA/DERECHA/SUBCADENA.
Las pruebas de David básicamente comparaban estas estructuras de consulta, buscando un patrón de cadena al principio o al final de un valor de columna, en términos de duración sin procesar:
WHERE Column LIKE @pattern + '%' OR Column LIKE '%' + @pattern; WHERE SUBSTRING(Column, 1, LEN(@pattern)) = @pattern OR SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)) = @pattern; WHERE LEFT(Column, LEN(@pattern)) = @pattern OR RIGHT(Column, LEN(@pattern)) = @pattern; WHERE CHARINDEX(@pattern, SUBSTRING(Column, 1, LEN(@pattern)), 0) > 0 OR CHARINDEX(@pattern, SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)), 0) > 0;
Con solo mirar estas cláusulas, puede ver por qué CHARINDEX podría ser menos eficiente:realiza múltiples llamadas funcionales adicionales que los otros enfoques no tienen que realizar. No estoy seguro de por qué este enfoque funcionó mejor en la máquina de David; tal vez ejecutó el código exactamente como se publicó, y realmente no eliminó los búferes entre las pruebas, de modo que las últimas pruebas se beneficiaron de los datos almacenados en caché.
En teoría, CHARINDEX podría haberse expresado de forma más sencilla, por ejemplo:
WHERE CHARINDEX(@pattern, Column) = 1 OR CHARINDEX(@pattern, Column) = LEN(Column) - LEN(@pattern) + 1;
(Pero esto en realidad funcionó aún peor en mis pruebas casuales).
¿Y por qué estos son incluso OR? condiciones, no estoy seguro. Siendo realistas, la mayor parte del tiempo estás haciendo uno de dos tipos de búsquedas de patrones:comienza con o contiene (es mucho menos común buscar termina con ). Y en la mayoría de esos casos, el usuario tiende a decir de antemano si quiere que empiece con o contiene , al menos en todas las aplicaciones en las que he estado involucrado en mi carrera.
Tiene sentido separarlos como tipos separados de consultas, en lugar de usar un O condicional, ya que empieza por puede hacer uso de un índice (si existe uno que sea lo suficientemente adecuado para una búsqueda, o que sea más delgado que el índice agrupado), mientras que termina con no puede (y O las condiciones tienden a arrojar llaves al optimizador en general). Si puedo confiar en ME GUSTA para usar un índice cuando puede, y para funcionar tan bien o mejor que las otras soluciones anteriores en la mayoría o en todos los casos, entonces puedo hacer que esta lógica sea muy fácil. Un procedimiento almacenado puede tomar dos parámetros:el patrón que se busca y el tipo de búsqueda a realizar (generalmente hay cuatro tipos de coincidencia de cadenas:comienza con, termina con, contiene o coincidencia exacta).
CREATE PROCEDURE dbo.Search
@pattern nvarchar(100),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
-- latter two are supported but won't be tested here
AS
BEGIN
SET NOCOUNT ON;
SELECT ...
WHERE Column LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
Esto maneja cada caso potencial sin usar SQL dinámico; la OPTION (RECOMPILE) está allí porque no le gustaría que un plan optimizado para "termina con" (que casi con certeza necesitará escanear) se reutilice para una consulta "comienza con", o viceversa; también garantizará que las estimaciones sean correctas ("comienza con S" probablemente tenga una cardinalidad muy diferente de "comienza con QX"). Incluso si tiene un escenario en el que los usuarios eligen un tipo de búsqueda el 99% del tiempo, podría usar SQL dinámico aquí en lugar de recompilar, pero en ese caso aún sería vulnerable a la detección de parámetros. En muchas consultas de lógica condicional, la recompilación y/o el SQL dinámico completo suelen ser el enfoque más sensato (consulte mi publicación sobre "el fregadero de la cocina").
Las Pruebas
Como recientemente comencé a buscar en la nueva base de datos de muestra de WideWorldImporters, decidí ejecutar mis propias pruebas allí. Fue difícil encontrar una tabla de tamaño decente sin un índice de ColumnStore o una tabla de historial temporal, pero Sales.Invoices , que tiene 70 510 filas, tiene un nvarchar(20) simple columna llamada CustomerPurchaseOrderNumber que decidí usar para las pruebas. (Por qué es nvarchar(20) cuando cada valor individual es un número de 5 dígitos, no tengo idea, pero a la coincidencia de patrones realmente no le importa si los bytes debajo representan números o cadenas).
| Ventas.Facturas Número de pedido de compra del cliente | ||
|---|---|---|
| Patrón | # de filas | % de la tabla |
| Comienza con "1" | 70.505 | 99,993 % |
| Empieza por "2" | 5 | 0,007 % |
| Termina en "5" | 6897 | 9,782 % |
| Termina en "30" | 749 | 1,062 % |
Examiné los valores en la tabla para encontrar múltiples criterios de búsqueda que producirían números de filas muy diferentes, con la esperanza de revelar cualquier comportamiento de punto de inflexión con un enfoque determinado. A la derecha están las consultas de búsqueda a las que llegué.
Quería probarme a mí mismo que el procedimiento anterior era innegablemente mejor en general para todas las búsquedas posibles que cualquiera de las consultas que usan OR condicionales, independientemente de si usan LIKE , LEFT/RIGHT , SUBSTRING , o CHARINDEX . Tomé las estructuras de consulta básicas de David y las puse en procedimientos almacenados (con la advertencia de que realmente no puedo probar "contiene" sin su entrada, y que tenía que hacer su OR lógica un poco más flexible para obtener el mismo número de filas), junto con una versión de mi lógica. También planeé probar los procedimientos con y sin un índice que crearía en la columna de búsqueda, y tanto en caché cálido como frío.
Los procedimientos:
CREATE PROCEDURE dbo.David_LIKE
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CustomerPurchaseOrderNumber LIKE @pattern + N'%')
OR (@option = 'EndsWith'
AND CustomerPurchaseOrderNumber LIKE N'%' + @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0)
OR (@option = 'EndsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Aaron_Conditional
@pattern nvarchar(10),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
También hice versiones de los procedimientos de David fieles a su intención original, asumiendo que el requisito realmente es encontrar cualquier fila donde el patrón de búsqueda esté al principio *o* al final de la cadena. Hice esto simplemente para poder comparar el rendimiento de los diferentes enfoques, exactamente como los escribió, para ver si en este conjunto de datos mis resultados coincidirían con mis pruebas de su script original en mi sistema. En este caso no había ninguna razón para presentar una versión propia, ya que simplemente coincidiría con su LIKE % + @pattern OR LIKE @pattern + % variación.
CREATE PROCEDURE dbo.David_LIKE_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE @pattern + N'%'
OR CustomerPurchaseOrderNumber LIKE N'%' + @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern
OR SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OR RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0
OR CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0
OPTION (RECOMPILE);
END
GO Con los procedimientos implementados, pude generar el código de prueba, que a menudo es tan divertido como el problema original. Primero, una tabla de registro:
DROP TABLE IF EXISTS dbo.LoggingTable; GO SET NOCOUNT ON; CREATE TABLE dbo.LoggingTable ( LogID int IDENTITY(1,1), prc sysname, opt varchar(10), pattern nvarchar(10), frame varchar(11), duration int, LogTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME() );
Luego, el código que realizaría operaciones de selección utilizando los diversos procedimientos y argumentos:
SET NOCOUNT ON;
;WITH prc(name) AS
(
SELECT name FROM sys.procedures
WHERE LEFT(name,5) IN (N'David', N'Aaron')
),
args(opt,pattern) AS
(
SELECT 'StartsWith', N'1'
UNION ALL SELECT 'StartsWith', N'2'
UNION ALL SELECT 'EndsWith', N'5'
UNION ALL SELECT 'EndsWith', N'30'
),
frame(w) AS
(
SELECT 'BeforeIndex'
UNION ALL SELECT 'AfterIndex'
),
y AS
(
-- comment out lines 2-4 here if we want warm cache
SELECT cmd = 'GO
DBCC FREEPROCCACHE() WITH NO_INFOMSGS;
DBCC DROPCLEANBUFFERS() WITH NO_INFOMSGS;
GO
DECLARE @d datetime2, @delta int;
SET @d = SYSUTCDATETIME();
EXEC dbo.' + prc.name + ' @pattern = N'''
+ args.pattern + '''' + CASE
WHEN prc.name LIKE N'%_Original' THEN ''
ELSE ',@option = ''' + args.opt + '''' END + ';
SET @delta = DATEDIFF(MICROSECOND, @d, SYSUTCDATETIME());
INSERT dbo.LoggingTable(prc,opt,pattern,frame,duration)
SELECT N''' + prc.name + ''',''' + args.opt + ''',N'''
+ args.pattern + ''',''' + frame.w + ''',@delta;
',
*, rn = ROW_NUMBER() OVER
(PARTITION BY frame.w ORDER BY frame.w DESC,
LEN(prc.name), args.opt DESC, args.pattern)
FROM prc CROSS JOIN args CROSS JOIN frame
)
SELECT cmd = cmd + CASE WHEN rn = 36 THEN
CASE WHEN w = 'BeforeIndex'
THEN 'CREATE INDEX testing ON '+
'Sales.Invoices(CustomerPurchaseOrderNumber);
' ELSE 'DROP INDEX Sales.Invoices.testing;' END
ELSE '' END--, name, opt, pattern, w, rn
FROM y
ORDER BY w DESC, rn; Resultados
Realicé estas pruebas en una máquina virtual con Windows 10 (1511/10586.545), SQL Server 2016 (13.0.2149), con 4 CPU y 32 GB de RAM. Ejecuté cada conjunto de pruebas 11 veces; para las pruebas de caché en caliente, descarté el primer conjunto de resultados porque algunos de ellos eran realmente pruebas de caché en frío.
Luché con la forma de graficar los resultados para mostrar patrones, principalmente porque simplemente no había patrones. Casi todos los métodos fueron los mejores en un escenario y los peores en otro. En las siguientes tablas, destaqué el procedimiento de mejor y peor desempeño para cada columna, y puede ver que los resultados están lejos de ser concluyentes:
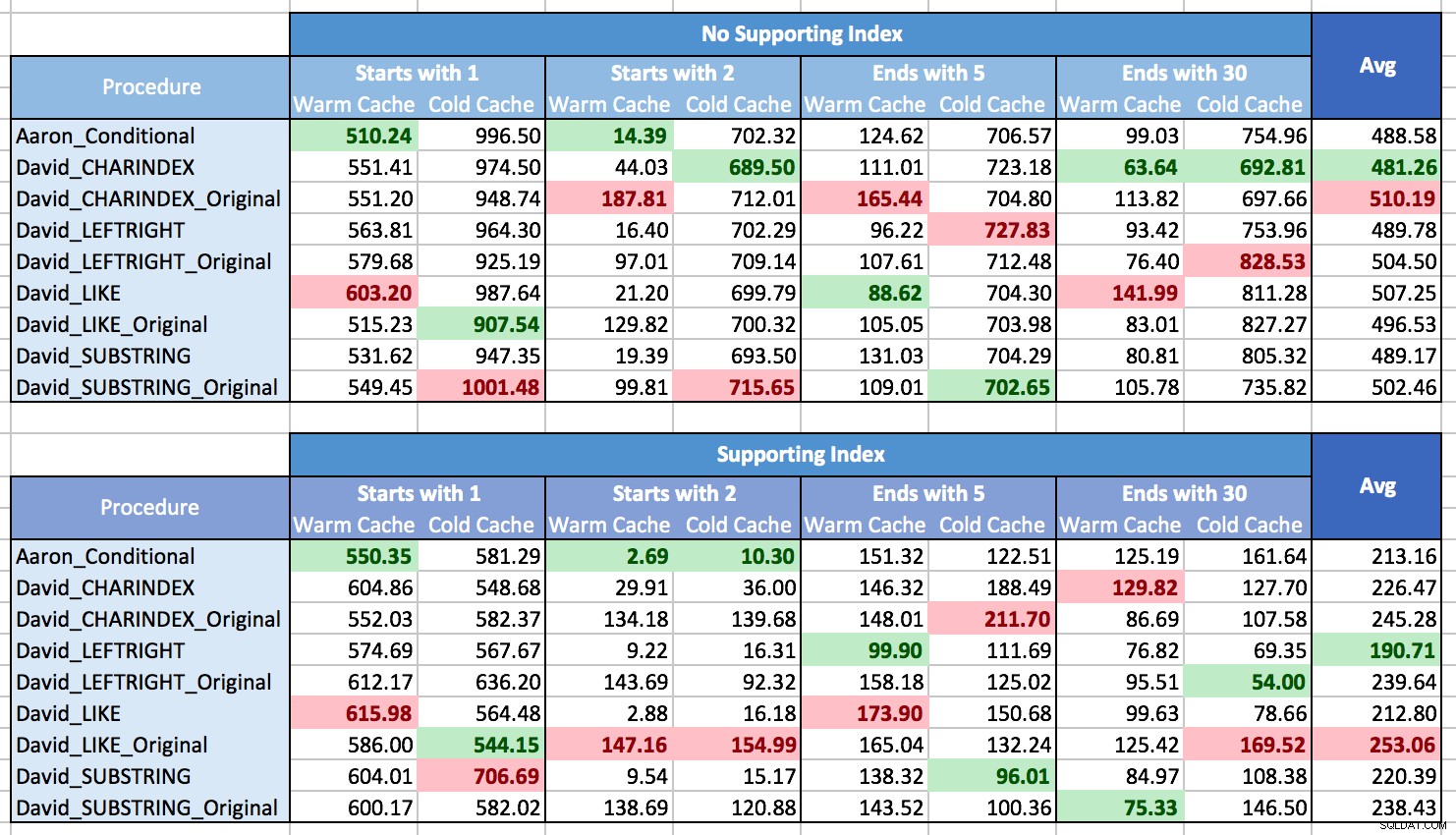 En estas pruebas, a veces CHARINDEX ganó y otras no.
En estas pruebas, a veces CHARINDEX ganó y otras no.
Lo que aprendí es que, en general, si va a enfrentar muchas situaciones diferentes (diferentes tipos de coincidencia de patrones, con un índice de soporte o no, los datos no siempre pueden estar en la memoria), realmente no hay claro ganador, y el rango de rendimiento en promedio es bastante pequeño (de hecho, dado que un caché tibio no siempre ayudó, sospecho que los resultados se vieron más afectados por el costo de generar los resultados que por recuperarlos). Para escenarios individuales, no confíe en mis pruebas; ejecute algunos puntos de referencia usted mismo dado su hardware, configuración, datos y patrones de uso.
Advertencias
Algunas cosas que no consideré para estas pruebas:
- Agrupados frente a no agrupados . Dado que es poco probable que su índice agrupado esté en una columna en la que realiza búsquedas de coincidencia de patrones contra el principio o el final de la cadena, y dado que una búsqueda será prácticamente la misma en ambos casos (y las diferencias entre escaneos serán en gran medida sea una función del ancho del índice frente al ancho de la tabla), solo probé el rendimiento usando un índice no agrupado. Si tiene escenarios específicos en los que esta diferencia por sí sola hace una gran diferencia en la coincidencia de patrones, hágamelo saber.
- Tipos MAX . Si está buscando cadenas dentro de
varchar(max)/nvarchar(max), no se pueden indexar, por lo que, a menos que use columnas calculadas para representar partes del valor, se requerirá un escaneo, ya sea que esté buscando comienza con, termina con o contiene. No probé si la sobrecarga de rendimiento se correlaciona con el tamaño de la cadena o si se introduce una sobrecarga adicional simplemente debido al tipo.
- Búsqueda de texto completo . He jugado con esta función aquí y allá, y puedo deletrearlo, pero si mi comprensión es correcta, esto solo podría ser útil si está buscando palabras completas sin parar y no le preocupa dónde estaban en la cadena. encontrado. No sería útil si estuviera almacenando párrafos de texto y quisiera encontrar todos los que comienzan con "Y", contienen la palabra "el" o terminan con un signo de interrogación.
Resumen
La única declaración general que puedo hacer al alejarme de esta prueba es que no hay declaraciones generales sobre cuál es la forma más eficiente de realizar la coincidencia de patrones de cadenas. Si bien estoy sesgado hacia mi enfoque condicional para la flexibilidad y la mantenibilidad, no fue el ganador del rendimiento en todos los escenarios. Para mí, a menos que me encuentre con un cuello de botella en el rendimiento y esté buscando todas las vías, continuaré usando mi enfoque por coherencia. Como sugerí anteriormente, si tiene un escenario muy limitado y es muy sensible a las pequeñas diferencias en la duración, querrá ejecutar sus propias pruebas para determinar qué método es el mejor para usted.



