Prácticamente todos los problemas de rendimiento relacionados con la columna calculada que he encontrado a lo largo de los años han tenido una (o más) de las siguientes causas principales:
- Limitaciones de implementación
- Falta de compatibilidad con el modelo de costes en el optimizador de consultas
- Expansión de definición de columna calculada antes de que comience la optimización
Un ejemplo de una limitación de implementación no es capaz de crear un índice filtrado en una columna calculada (incluso cuando persiste). No hay mucho que podamos hacer con respecto a esta categoría de problemas; tenemos que usar soluciones alternativas mientras esperamos que lleguen las mejoras del producto.
La falta de compatibilidad con el modelo de costes del optimizador significa que SQL Server asigna un pequeño costo fijo a los cálculos escalares, independientemente de la complejidad o la implementación. Como consecuencia, el servidor a menudo decide volver a calcular un valor de columna calculado almacenado en lugar de leer directamente el valor persistente o indexado. Esto es particularmente doloroso cuando la expresión calculada es costosa, por ejemplo, cuando implica llamar a una función escalar definida por el usuario.
Los problemas en torno a la expansión de definiciones son un poco más complicados y tienen efectos de gran alcance.
Los problemas de la expansión de columnas calculadas
SQL Server normalmente expande las columnas calculadas en sus definiciones subyacentes durante la fase de vinculación de la normalización de consultas. Esta es una fase muy temprana en el proceso de compilación de consultas, mucho antes de que se tomen decisiones de selección de planes (incluido el plan trivial).
En teoría, realizar una expansión temprana podría permitir optimizaciones que de otro modo se perderían. Por ejemplo, el optimizador podría aplicar simplificaciones dada otra información en la consulta y los metadatos (por ejemplo, restricciones). Este es el mismo tipo de razonamiento que lleva a que se expandan las definiciones de vista (a menos que se presente un NOEXPAND se usa una pista).
Más adelante en el proceso de compilación (pero incluso antes de que se haya considerado un plan trivial), el optimizador busca hacer coincidir las expresiones con las columnas calculadas indexadas o persistentes. El problema es que, mientras tanto, las actividades del optimizador pueden haber cambiado las expresiones expandidas de tal manera que ya no es posible volver a coincidir.
Cuando esto ocurre, el plan de ejecución final parece como si el optimizador hubiera perdido una oportunidad "obvia" de usar una columna calculada persistente o indexada. Hay pocos detalles en los planes de ejecución que pueden ayudar a determinar la causa, lo que hace que este sea un problema potencialmente frustrante para depurar y solucionar.
Hacer coincidir expresiones con columnas calculadas
Vale la pena dejar especialmente claro que hay dos procesos separados aquí:
- Expansión temprana de columnas calculadas; y
- Intentos posteriores de hacer coincidir expresiones con columnas calculadas.
En particular, tenga en cuenta que cualquier expresión de consulta puede coincidir con una columna calculada adecuada más adelante, no solo con expresiones que surgieron de la expansión de columnas calculadas.
La coincidencia de expresión de columna calculada puede permitir mejoras en el plan incluso cuando el texto de la consulta original no se puede modificar. Por ejemplo, crear una columna calculada para que coincida con una expresión de consulta conocida permite que el optimizador use estadísticas e índices asociados con la columna calculada. Esta característica es conceptualmente similar a la coincidencia de vista indexada en Enterprise Edition. La coincidencia de columnas calculadas es funcional en todas las ediciones.
Desde un punto de vista práctico, mi propia experiencia ha sido que hacer coincidir las expresiones de consulta generales con las columnas calculadas puede beneficiar el rendimiento, la eficiencia y la estabilidad del plan de ejecución. Por otro lado, rara vez (si es que alguna vez) he encontrado que valga la pena la expansión de columna calculada. Simplemente nunca parece producir optimizaciones útiles.
Usos de columnas calculadas
Columnas calculadas que son ninguna persistentes ni indexados tienen usos válidos. Por ejemplo, pueden admitir estadísticas automáticas si la columna es determinista y precisa (sin elementos de coma flotante). También se pueden usar para ahorrar espacio de almacenamiento (a expensas de un poco de uso adicional del procesador en tiempo de ejecución). Como ejemplo final, pueden proporcionar una forma ordenada de garantizar que un cálculo simple siempre se realice correctamente, en lugar de escribirse explícitamente en las consultas cada vez.
Persistente las columnas calculadas se agregaron al producto específicamente para permitir que los índices se construyan en columnas deterministas pero "imprecisas" (coma flotante). En mi experiencia, este uso previsto es relativamente raro. Tal vez esto se deba simplemente a que no encuentro mucho los datos de punto flotante.
Aparte de los índices de punto flotante, las columnas persistentes son bastante comunes. Hasta cierto punto, esto puede deberse a que los usuarios inexpertos asumen que una columna calculada siempre debe conservarse antes de que se pueda indexar. Los usuarios más experimentados pueden emplear columnas persistentes simplemente porque han descubierto que el rendimiento tiende a ser mejor de esa manera.
Indexado las columnas calculadas (persistentes o no) se pueden usar para proporcionar un orden y un método de acceso eficiente. Puede resultar útil almacenar un valor calculado en un índice sin conservarlo también en la tabla base. Del mismo modo, las columnas calculadas adecuadas también pueden incluirse en los índices en lugar de ser columnas clave.
Bajo rendimiento
Una de las principales causas de un bajo rendimiento es una simple falla al usar un valor de columna calculado indexado o persistente como se esperaba. He perdido la cuenta de la cantidad de preguntas que he tenido a lo largo de los años preguntando por qué el optimizador elegiría un plan de ejecución terrible cuando existe un plan obviamente mejor que utiliza una columna calculada indexada o persistente.
La causa precisa en cada caso varía, pero casi siempre es una decisión defectuosa basada en costos (porque a los escalares se les asigna un costo fijo bajo); o una falla al hacer coincidir una expresión expandida con una columna o índice calculado persistente.
Las fallas de emparejamiento son especialmente interesantes para mí, porque a menudo involucran interacciones complejas con características ortogonales del motor. Con la misma frecuencia, la falla en la "coincidencia" deja una expresión (en lugar de una columna) en una posición en el árbol de consulta interno que impide que coincida una regla de optimización importante. En cualquier caso, el resultado es el mismo:un plan de ejecución subóptimo.
Ahora, creo que es justo decir que las personas generalmente indexan o conservan una columna calculada con la fuerte expectativa de que el valor almacenado realmente se utilizará. Puede ser bastante impactante ver que SQL Server vuelve a calcular la expresión subyacente cada vez, mientras ignora el valor almacenado proporcionado deliberadamente. Las personas no siempre están muy interesadas en las interacciones internas y las deficiencias del modelo de costos que llevaron al resultado no deseado. Incluso cuando existen soluciones alternativas, estas requieren tiempo, habilidad y esfuerzo para descubrirlas y probarlas.
En resumen:muchas personas simplemente preferirían que SQL Server use el valor persistente o indexado. Siempre.
Una nueva opción
Históricamente, no ha habido forma de obligar a SQL Server a usar siempre el valor almacenado (no hay equivalente a NOEXPAND sugerencia para las vistas). Hay algunas circunstancias en las que una guía de plan funcionará, pero no siempre es posible generar la forma de plan requerida en primer lugar, y no se pueden forzar todos los elementos y posiciones del plan (filtros y calcular escalares, por ejemplo).
Todavía no existe una solución clara y completamente documentada, pero una actualización reciente de SQL Server 2016 ha proporcionado un nuevo enfoque interesante. Se aplica a instancias de SQL Server 2016 parcheadas con al menos la Actualización acumulativa 2 para SQL Server 2016 SP1 o la Actualización acumulativa 4 para SQL Server 2016 RTM.
La actualización relevante está documentada en:FIX:No se puede reconstruir la partición en línea para una tabla que contiene una columna de partición calculada en SQL Server 2016
Como suele ocurrir con la documentación de soporte, esto no dice exactamente qué se ha cambiado en el motor para solucionar el problema. Ciertamente no parece terriblemente relevante para nuestras preocupaciones actuales, a juzgar por el título y la descripción. Sin embargo, esta solución introduce una nueva marca de rastreo admitida 176 , que se verifica en un método de código llamado FDontExpandPersistedCC . Como sugiere el nombre del método, esto evita que se expanda una columna calculada persistente.
Hay tres advertencias importantes para esto:
- La columna calculada debe ser persistente . Incluso si está indexada, la columna también debe conservarse.
- La coincidencia de expresiones de consulta generales con columnas calculadas persistentes está inhabilitada .
- La documentación no describe la función de la marca de rastreo y no la prescribe para ningún otro uso. Si elige usar el indicador de seguimiento 176 para evitar la expansión de columnas calculadas persistentes, será bajo su propio riesgo.
Esta marca de rastreo es efectiva como una puesta en marcha –T opción, tanto en el ámbito global como en el de la sesión mediante DBCC TRACEON , y por consulta con OPTION (QUERYTRACEON) .
Ejemplo
Esta es una versión simplificada de una pregunta (basada en un problema del mundo real) que respondí en Database Administrators Stack Exchange hace unos años. La definición de la tabla incluye una columna calculada persistente:
CREATE TABLE dbo.T
(
ID integer IDENTITY NOT NULL,
A varchar(20) NOT NULL,
B varchar(20) NOT NULL,
C varchar(20) NOT NULL,
D date NULL,
Computed AS A + '-' + B + '-' + C PERSISTED,
CONSTRAINT PK_T_ID
PRIMARY KEY CLUSTERED (ID),
);
GO
INSERT dbo.T WITH (TABLOCKX)
(A, B, C, D)
SELECT
A = STR(SV.number % 10, 2),
B = STR(SV.number % 20, 2),
C = STR(SV.number % 30, 2),
D = DATEADD(DAY, 0 - SV.number, SYSUTCDATETIME())
FROM master.dbo.spt_values AS SV
WHERE SV.[type] = N'P'; La siguiente consulta devuelve todas las filas de la tabla en un orden particular, al mismo tiempo que devuelve el siguiente valor de la columna D en el mismo orden:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
(
SELECT TOP (1)
t2.D
FROM dbo.T AS T2
WHERE
T2.Computed = T1.Computed
AND T2.D > T1.D
ORDER BY
T2.D ASC
)
FROM dbo.T AS T1
ORDER BY
T1.Computed, T1.D; Un índice de cobertura obvio para respaldar el ordenamiento final y las búsquedas en la subconsulta es:
CREATE UNIQUE NONCLUSTERED INDEX IX_T_Computed_D_ID ON dbo.T (Computed, D, ID);
El plan de ejecución entregado por el optimizador es sorprendente y decepcionante:
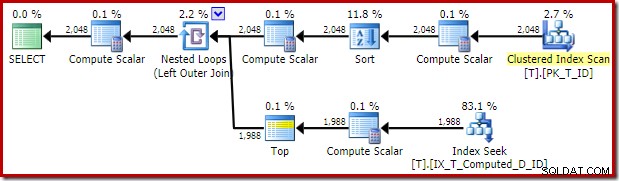
La búsqueda de índice en el lado interno de Nested Loops Join parece estar bien. Sin embargo, la exploración y clasificación del índice agrupado en la entrada externa es inesperada. Hubiéramos esperado ver un escaneo ordenado de nuestro índice no agrupado de cobertura en su lugar.
Podemos obligar al optimizador a usar el índice no agrupado con una sugerencia de tabla:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
(
SELECT TOP (1)
t2.D
FROM dbo.T AS T2
WHERE
T2.Computed = T1.Computed
AND T2.D > T1.D
ORDER BY
T2.D ASC
)
FROM dbo.T AS T1
WITH (INDEX(IX_T_Computed_D_ID)) -- New!
ORDER BY
T1.Computed, T1.D; El plan de ejecución resultante es:
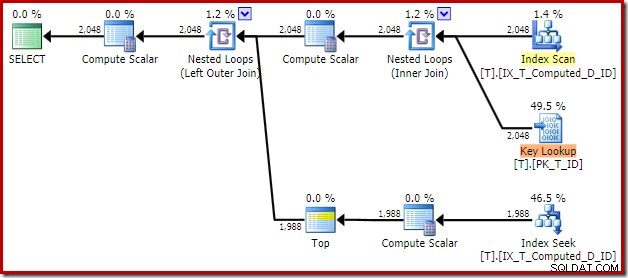
Escanear el índice no agrupado elimina la ordenación, ¡pero agrega una búsqueda de claves! Las búsquedas en este nuevo plan son sorprendentes, dado que nuestro índice definitivamente cubre todas las columnas que necesita la consulta.
Mirando las propiedades del operador Key Lookup:
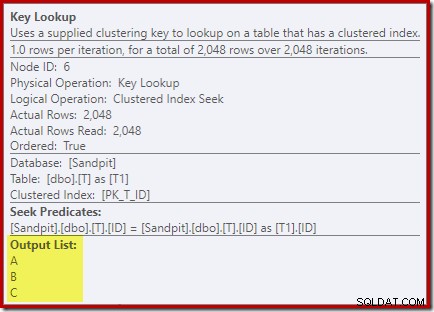
Por alguna razón, el optimizador ha decidido que tres columnas que no se mencionan en la consulta deben obtenerse de la tabla base (ya que no están presentes en nuestro índice no agrupado por diseño).
Mirando alrededor del plan de ejecución, descubrimos que las columnas buscadas son necesarias para el lado interno Index Seek:

La primera parte de este predicado de búsqueda corresponde a la correlación T2.Computed = T1.Computed en la consulta original. El optimizador ha ampliado las definiciones de ambas columnas calculadas, pero solo logró hacer coincidir con la columna calculada persistente e indexada para el alias del lado interno T1 . Dejando el T2 la referencia expandida ha dado como resultado que el lado exterior de la unión necesite proporcionar las columnas de la tabla base (A , B y C ) necesarios para calcular esa expresión para cada fila.
Como suele ser el caso, es posible volver a escribir esta consulta para que el problema desaparezca (se muestra una opción en mi respuesta anterior a la pregunta de Stack Exchange). Con SQL Server 2016, también podemos probar el indicador de seguimiento 176 para evitar que se expandan las columnas calculadas:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
(
SELECT TOP (1)
t2.D
FROM dbo.T AS T2
WHERE
T2.Computed = T1.Computed
AND T2.D > T1.D
ORDER BY
T2.D ASC
)
FROM dbo.T AS T1
ORDER BY
T1.Computed, T1.D
OPTION (QUERYTRACEON 176); -- New! El plan de ejecución ahora ha mejorado mucho:
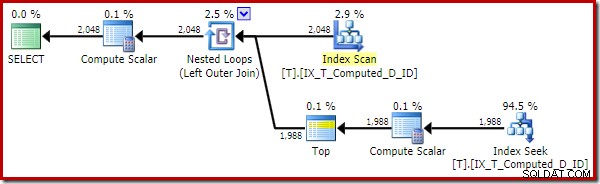
Este plan de ejecución contiene solo referencias a las columnas calculadas. Los Compute Scalars no hacen nada útil y se limpiarían si el optimizador estuviera un poco más ordenado en la casa.
El punto importante es que el índice óptimo ahora se usa correctamente, y se han eliminado la búsqueda de orden y clave. Todo al evitar que SQL Server haga algo que nunca hubiéramos esperado que hiciera en primer lugar (expandir una columna calculada indexada y persistente).
Uso de PLOMO
La pregunta original de Stack Exchange estaba dirigida a SQL Server 2008, donde LEAD no está disponible. Intentemos expresar el requisito en SQL Server 2016 usando la sintaxis más nueva:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
LEAD(T1.D) OVER (
PARTITION BY T1.Computed
ORDER BY T1.D)
FROM dbo.T AS T1
ORDER BY
T1.Computed; El plan de ejecución de SQL Server 2016 es:
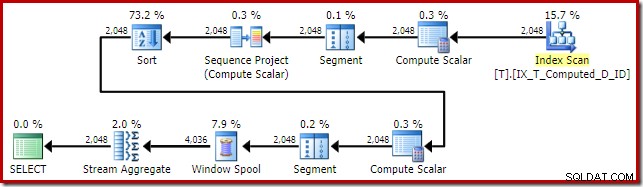
Esta forma de plano es bastante típica para una función de ventana de modo de fila simple. El único elemento inesperado es el operador Ordenar en el medio. Si el conjunto de datos fuera grande, esta clasificación podría tener un gran impacto en el rendimiento y el uso de la memoria.
El problema, una vez más, es la expansión de la columna calculada. En este caso, una de las expresiones expandidas se encuentra en una posición que impide que la lógica normal del optimizador simplifique la clasificación.
Intentando exactamente la misma consulta con el indicador de seguimiento 176:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
LEAD(T1.D) OVER (
PARTITION BY T1.Computed
ORDER BY T1.D)
FROM dbo.T AS T1
ORDER BY
T1.Computed
OPTION (QUERYTRACEON 176); Produce el plan:
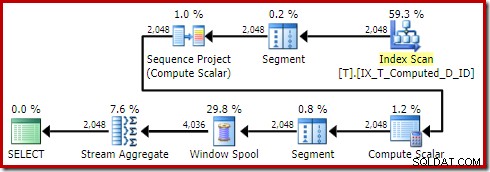
El Sort ha desaparecido como debería. Tenga en cuenta también de paso que esta consulta calificó para un plan trivial, evitando por completo la optimización basada en costos.
Coincidencia de expresiones generales deshabilitada
Una de las advertencias mencionadas anteriormente fue que el indicador de seguimiento 176 también deshabilita la coincidencia de expresiones en la consulta de origen con columnas calculadas persistentes.
Para ilustrar, considere la siguiente versión de la consulta de ejemplo. El LEAD se ha eliminado el cálculo y las referencias a la columna calculada en SELECT y ORDER BY Las cláusulas han sido reemplazadas con las expresiones subyacentes. Ejecútelo primero sin el indicador de rastreo 176:
SELECT
T1.ID,
Computed = T1.A + '-' + T1.B + '-' + T1.C,
T1.D
FROM dbo.T AS T1
ORDER BY
T1.A + '-' + T1.B + '-' + T1.C; Las expresiones se comparan con la columna calculada persistente y el plan de ejecución es un escaneo ordenado simple del índice no agrupado:
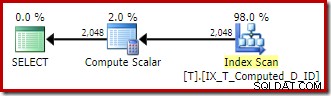
Una vez más, Compute Scalar no es más que basura arquitectónica sobrante.
Ahora intente la misma consulta con el indicador de rastreo 176 habilitado:
SELECT
T1.ID,
Computed = T1.A + '-' + T1.B + '-' + T1.C,
T1.D
FROM dbo.T AS T1
ORDER BY
T1.A + '-' + T1.B + '-' + T1.C
OPTION (QUERYTRACEON 176); -- New! El nuevo plan de ejecución es:
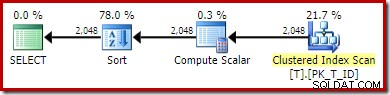
La exploración de índice no agrupado se ha reemplazado por una exploración de índice agrupado. Compute Scalar evalúa la expresión y Sort ordena por el resultado. Privado de la capacidad de hacer coincidir expresiones con columnas calculadas persistentes, el optimizador no puede utilizar el valor persistente o el índice no agrupado.
Tenga en cuenta que la limitación de coincidencia de expresiones solo se aplica a persistente columnas calculadas cuando el indicador de seguimiento 176 está activo. Si hacemos que la columna calculada sea indexada pero no persistente, la coincidencia de expresiones funciona correctamente.
Para eliminar el atributo persistente, primero debemos eliminar el índice no agrupado. Una vez que se realiza el cambio, podemos volver a colocar el índice (porque la expresión es determinista y precisa):
DROP INDEX IX_T_Computed_D_ID ON dbo.T; GO ALTER TABLE dbo.T ALTER COLUMN Computed DROP PERSISTED; GO CREATE UNIQUE NONCLUSTERED INDEX IX_T_Computed_D_ID ON dbo.T (Computed, D, ID);
El optimizador ahora no tiene problemas para hacer coincidir la expresión de consulta con la columna calculada cuando el indicador de seguimiento 176 está activo:
-- Computed column no longer persisted
-- but still indexed. TF 176 active.
SELECT
T1.ID,
Computed = T1.A + '-' + T1.B + '-' + T1.C,
T1.D
FROM dbo.T AS T1
ORDER BY
T1.A + '-' + T1.B + '-' + T1.C
OPTION (QUERYTRACEON 176); El plan de ejecución vuelve al escaneo de índice no agrupado óptimo sin ordenar:
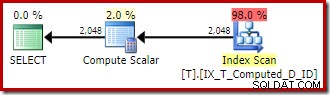
Para resumir:el indicador de seguimiento 176 evita la expansión persistente de la columna calculada. Como efecto secundario, también evita que la expresión de consulta coincida solo con columnas calculadas persistentes.
Los metadatos del esquema solo se cargan una vez, durante la fase de vinculación. El indicador de seguimiento 176 evita la expansión, por lo que la definición de la columna calculada no se carga en ese momento. La coincidencia posterior de expresión con columna no puede funcionar sin la definición de columna calculada con la que comparar.
La carga inicial de metadatos trae todas las columnas, no solo aquellas a las que se hace referencia en la consulta (esa optimización se realiza más adelante). Esto hace que todas las columnas calculadas estén disponibles para la coincidencia, lo que generalmente es algo bueno. Desafortunadamente, si una de las columnas calculadas cargadas contiene una función escalar definida por el usuario, su presencia deshabilita el paralelismo para toda la consulta, incluso cuando no se usa la columna problemática. El indicador de seguimiento 176 también puede ayudar con esto, si la columna en cuestión se conserva. Al no cargar la definición, una función escalar definida por el usuario nunca está presente, por lo que el paralelismo no está deshabilitado.
Reflexiones finales
Me parece que el mundo de SQL Server sería un lugar mejor si el optimizador tratara las columnas calculadas persistentes o indexadas más como columnas regulares. En casi todos los casos, esto coincidiría mejor con las expectativas de los desarrolladores que con el arreglo actual. Expandir las columnas calculadas en sus expresiones subyacentes y luego intentar hacerlas coincidir no es tan exitoso en la práctica como podría sugerir la teoría.
Hasta que SQL Server proporcione soporte específico para evitar la expansión de columnas calculadas indexadas o persistentes, la nueva marca de seguimiento 176 es una opción tentadora para los usuarios de SQL Server 2016, aunque sea imperfecta. Es un poco desafortunado que deshabilite la coincidencia de expresiones generales como efecto secundario. También es una pena que la columna calculada tenga que persistir cuando se indexa. Entonces existe el riesgo de usar una marca de rastreo para otro propósito que no sea el documentado a considerar.
Es justo decir que la mayoría de los problemas con las consultas de columnas calculadas se pueden resolver en última instancia de otras maneras, con suficiente tiempo, esfuerzo y experiencia. Por otro lado, el indicador de rastreo 176 a menudo parece funcionar como magia. La elección, como dicen, es tuya.
Para terminar, aquí hay algunos problemas interesantes de columnas calculadas que se benefician del indicador de seguimiento 176:
- Índice de columna calculado no utilizado
- La columna calculada PERSISTIDA no se usa en el particionamiento de la función de ventanas
- Columna calculada persistente que provoca el análisis
- Índice de columna calculado no utilizado con tipos de datos MAX
- Problema grave de rendimiento con columnas y uniones calculadas persistentes
- ¿Por qué SQL Server "Calcula escalar" cuando SELECCIONO una columna calculada persistente?
- Columnas base utilizadas en lugar de columnas calculadas persistentes por motor
- Columna calculada con UDF deshabilita el paralelismo para consultas en *otras* columnas