Uno de los términos más comunes que surgen en las discusiones sobre el ajuste del rendimiento de SQL Server es estadísticas de espera. . Esto se remonta a mucho tiempo atrás, incluso antes de este documento de Microsoft de 2006, "Esperas y colas de SQL Server 2005".
Las esperas no lo son todo en absoluto, y esta metodología no es la única forma de ajustar una instancia, sin importar una consulta individual. De hecho, las esperas suelen ser inútiles cuando todo lo que se tiene es la consulta que las sufrió, y no el contexto que las rodea, especialmente mucho después del hecho. Esto se debe a que, muy a menudo, lo que está esperando una consulta no es culpa de esa consulta . Como todo, hay excepciones, pero si está eligiendo una herramienta o secuencia de comandos solo porque ofrece esta funcionalidad muy específica, creo que se está perjudicando a sí mismo. Tiendo a seguir un consejo que Paul Randal me dio hace algún tiempo:
…generalmente recomiendo comenzar con esperas de instancias completas. Yo nunca empezar solución de problemas observando las esperas de consultas individuales.
De vez en cuando, sí, es posible que desee profundizar en una consulta individual y ver qué está esperando; de hecho, Microsoft agregó recientemente estadísticas de espera de nivel de consulta al plan de presentación para ayudar con este análisis. Pero estos números generalmente no lo ayudarán a ajustar el rendimiento de su instancia en su conjunto, a menos que ayuden a señalar algo que también afecta toda su carga de trabajo. Si ve una consulta de ayer que se ejecutó durante 5 minutos y observa que su tipo de espera era LCK_M_S , ¿qué vas a hacer al respecto ahora? ¿Cómo va a rastrear lo que realmente bloqueó la consulta y provocó ese tipo de espera? Puede haber sido causado por una transacción que no se comprometió por algún otro motivo, pero no puede ver eso si no puede ver el estado de todo el sistema y se enfoca solo en consultas individuales y las esperas que experimentaron.
Jason Hall (@SQLSaurus) mencionó algo de pasada que también me resultó interesante. Dijo que si las estadísticas de espera a nivel de consulta fueran una parte tan importante de los esfuerzos de ajuste, esta metodología se habría integrado en Query Store desde el principio. Se ha agregado recientemente (en SQL Server 2017). Pero aún no obtiene estadísticas de espera por ejecución; obtiene promedios a lo largo del tiempo, como las estadísticas de consultas y las estadísticas de procedimientos que ve en los DMV. Por lo tanto, las anomalías repentinas pueden ser evidentes en función de otras métricas que se capturan por ejecución de consulta, pero no en función de los promedios de los tiempos de espera que se calculan sobre todos. ejecuciones Puede personalizar el rango en el que se agregan las esperas, pero en sistemas ocupados, es posible que esto no sea lo suficientemente granular para hacer lo que cree que hará por usted.
El objetivo de esta publicación es discutir algunos de los tipos de espera más comunes que vemos en nuestra base de clientes y qué tipo de acciones puede (y no debe) tomar cuando ocurren. Tenemos una base de datos de estadísticas de espera anónimas que hemos recopilado de nuestros clientes de Cloud Sync durante bastante tiempo y, desde mayo de 2017, les hemos estado mostrando a todos cómo se ven en la biblioteca de esperas de SQLskills.
Paul habla sobre la razón detrás de la biblioteca y también sobre nuestra integración con este servicio gratuito. Básicamente, busca un tipo de espera que está experimentando o que le causa curiosidad, y él explica lo que significa y lo que puede hacer al respecto. Complementamos esta información cualitativa con un gráfico que muestra qué tan frecuente es la espera actual entre nuestra base de usuarios, comparándola con todos los otros tipos de espera que vemos, para que pueda saber rápidamente si está tratando con un tipo de espera común o algo un poco más. exótico. (Tenga en cuenta que SQL Sentry no incluye las esperas benignas, de fondo y de cola que generan ruido y que la mayoría de las secuencias de comandos se filtran, como WAITFOR o LAZYWRITER_SLEEP; estas simplemente no son fuentes de problemas de rendimiento).
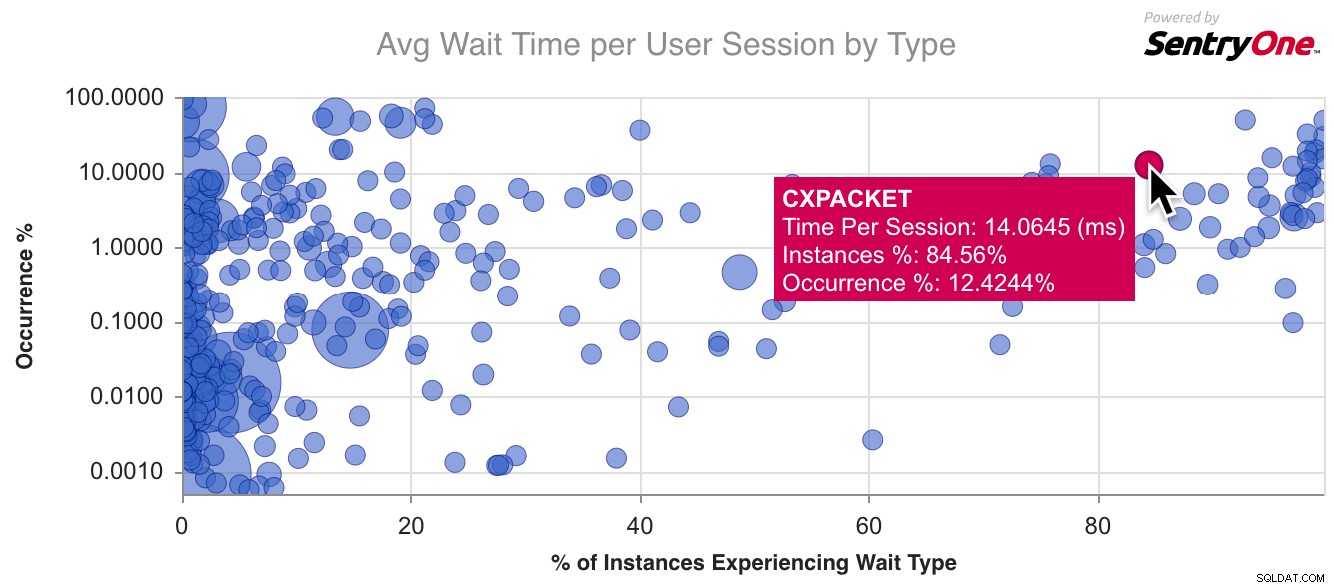
Aquí hay un gráfico de ejemplo para CXPACKET , el tipo de espera más común que existe:
Empecé a ir un poco más allá, mapeando algunos de los tipos de espera más comunes y anotando algunas de las propiedades que compartían. Traducido a preguntas que un sintonizador podría tener sobre un tipo de espera que está experimentando:
- ¿Se puede resolver el tipo de espera en el nivel de consulta?
- ¿Es probable que el síntoma principal de la espera afecte a otras consultas?
- ¿Es probable que necesite más información fuera del contexto de una sola consulta y los tipos de espera que experimentó para "resolver" el problema?
Cuando me dispuse a escribir esta publicación, mi objetivo era solo agrupar los tipos de espera más comunes y luego comenzar a tomar notas sobre ellos en relación con las preguntas anteriores. Jason sacó los más comunes de la biblioteca, y luego dibujé un rasguño de pollo en una pizarra, que luego arreglé un poco. Esta investigación inicial condujo a una charla que Jason dio en el crucero TechOutbound SQL más reciente en Alaska. Estoy un poco avergonzado de que haya organizado una charla meses antes de que pudiera terminar esta publicación, así que sigamos adelante. Estas son las principales esperas que vemos (que coinciden en gran medida con la encuesta de Paul de 2014), mis respuestas a las preguntas anteriores y algunos comentarios sobre cada una:
Para interactuar con los enlaces de la siguiente tabla, visite esta página en una pantalla más amplia.
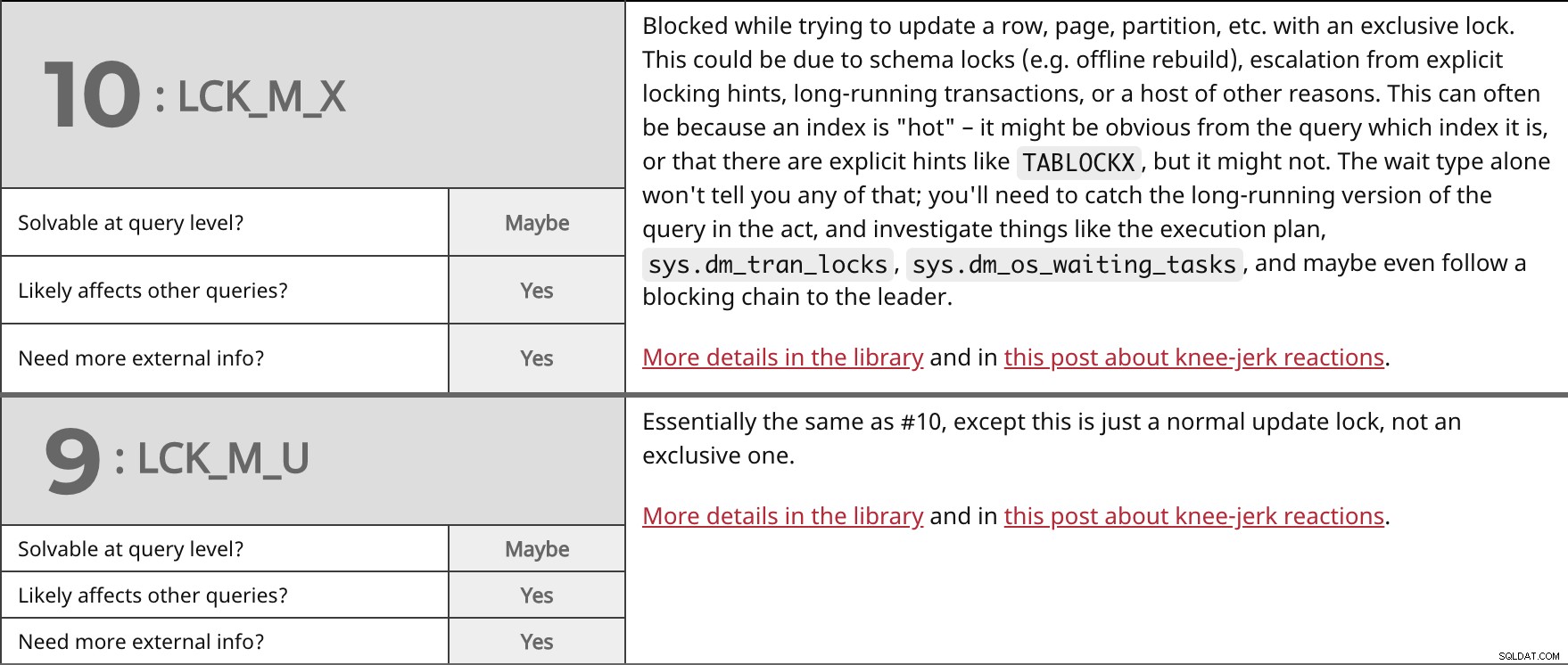
Bloqueado al intentar actualizar una fila, página, partición, etc. con un bloqueo exclusivo. Esto podría deberse a bloqueos de esquema (por ejemplo, reconstrucción fuera de línea), escalamiento de sugerencias de bloqueo explícito, transacciones de ejecución prolongada o una serie de otras razones. A menudo, esto puede deberse a que un índice está "caliente":puede ser obvio a partir de la consulta qué índice es, o que hay sugerencias explícitas como TABLOCKX , pero puede que no. El tipo de espera por sí solo no le dirá nada de eso; deberá capturar la versión de ejecución prolongada de la consulta en el acto e investigar cosas como el plan de ejecución, sys.dm_tran_locks , sys.dm_os_waiting_tasks , y tal vez incluso seguir una cadena de bloqueo hasta el líder. Más detalles en la biblioteca y en esta publicación sobre reacciones instintivas. | ||
| ¿Resoluble a nivel de consulta? | Tal vez | |
| Sí | ||
| ¿Necesita más información externa? | Sí | |
|
Esencialmente lo mismo que el n.° 10, excepto que se trata de un bloqueo de actualización normal, no exclusivo. Más detalles en la biblioteca y en esta publicación sobre reacciones instintivas. | ||
| ¿Resoluble a nivel de consulta? | Tal vez | |
| Sí | ||
| ¿Necesita más información externa? | Sí | |
|
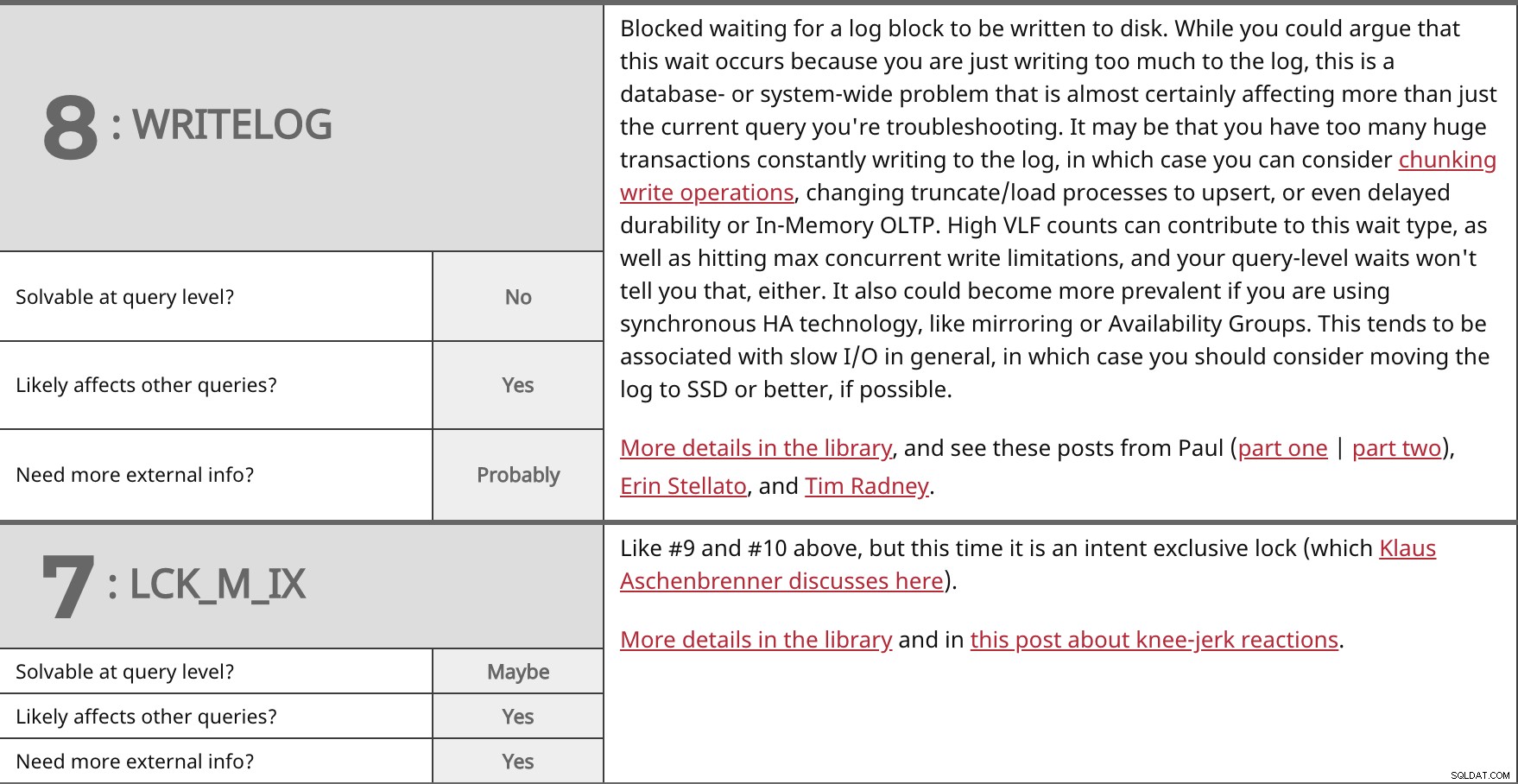
Bloqueado esperando que se escriba un bloque de registro en el disco. Si bien podría argumentar que esta espera ocurre porque simplemente está escribiendo demasiado en el registro, este es un problema de toda la base de datos o del sistema que casi seguramente afecta más que solo la consulta actual que está resolviendo. Es posible que tenga demasiadas transacciones enormes escribiendo constantemente en el registro, en cuyo caso puede considerar fragmentar las operaciones de escritura, cambiar los procesos de truncado/carga a upsert, o incluso retrasar la durabilidad o OLTP en memoria. Los conteos altos de VLF pueden contribuir a este tipo de espera, además de alcanzar las limitaciones máximas de escritura simultánea, y las esperas de nivel de consulta tampoco le dirán eso. También podría volverse más frecuente si usa tecnología HA síncrona, como duplicación o grupos de disponibilidad. Esto tiende a estar asociado con E/S lenta en general, en cuyo caso debería considerar mover el registro a SSD o mejor, si es posible. Más detalles en la biblioteca y vea estas publicaciones de Paul (primera parte | segunda parte), Erin Stellato y Tim Radney. | ||
| ¿Resoluble a nivel de consulta? | No | |
| Sí | ||
| ¿Necesita más información externa? | Probablemente | |
|
Como el n.° 9 y el n.° 10 anteriores, pero esta vez es un bloqueo exclusivo de intención (que Klaus Aschenbrenner analiza aquí). Más detalles en la biblioteca y en esta publicación sobre reacciones instintivas. | ||
| ¿Resoluble a nivel de consulta? | Tal vez | |
| Sí | ||
| ¿Necesita más información externa? | Sí | |
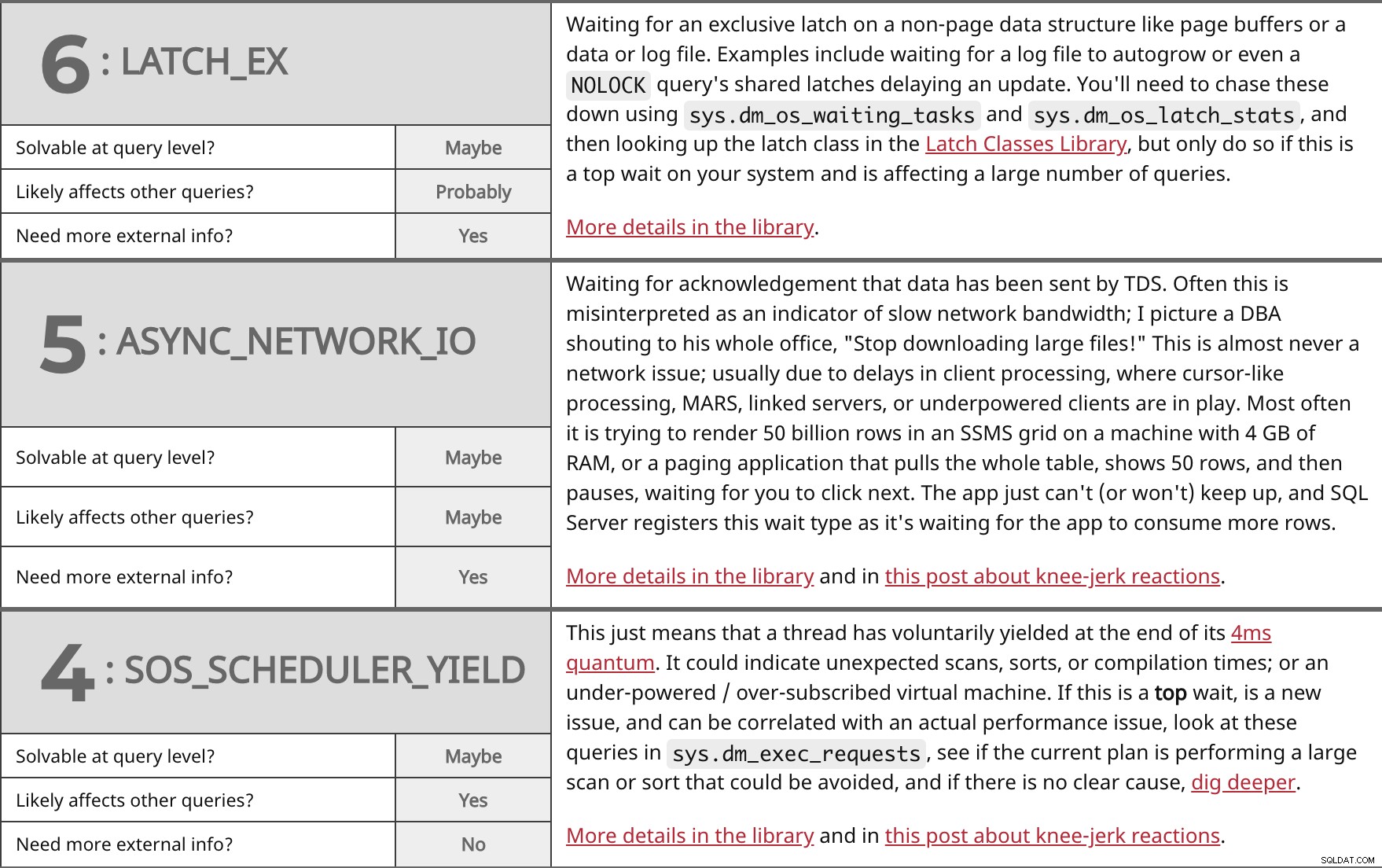
Esperando un pestillo exclusivo en una estructura de datos que no son de página, como búferes de página o un archivo de datos o de registro. Los ejemplos incluyen esperar a que un archivo de registro crezca automáticamente o incluso un NOLOCK pestillos compartidos de la consulta que retrasan una actualización. Deberá perseguirlos usando sys.dm_os_waiting_tasks y sys.dm_os_latch_stats y luego busque la clase de pestillo en la biblioteca de clases de pestillo, pero hágalo solo si se trata de una espera principal en su sistema y está afectando a una gran cantidad de consultas. Más detalles en la biblioteca. | ||
| ¿Resoluble a nivel de consulta? | Tal vez | |
| Probablemente | ||
| ¿Necesita más información externa? | Sí | |
|
Esperando la confirmación de que TDS ha enviado los datos. A menudo, esto se malinterpreta como un indicador de ancho de banda de red lento; Me imagino a un DBA gritando a toda su oficina:"¡Dejen de descargar archivos grandes!" Esto casi nunca es un problema de red; generalmente debido a retrasos en el procesamiento del cliente, donde están en juego el procesamiento tipo cursor, MARS, servidores vinculados o clientes con poca potencia. La mayoría de las veces, intenta representar 50 mil millones de filas en una cuadrícula SSMS en una máquina con 4 GB de RAM o una aplicación de paginación que extrae toda la tabla, muestra 50 filas y luego se detiene, esperando que haga clic en Siguiente. La aplicación simplemente no puede (o no quiere) mantener el ritmo, y SQL Server registra este tipo de espera mientras espera que la aplicación consuma más filas. Más detalles en la biblioteca y en esta publicación sobre reacciones instintivas. | ||
| ¿Resoluble a nivel de consulta? | Tal vez | |
| Tal vez | ||
| ¿Necesita más información externa? | Sí | |
Esto solo significa que un subproceso ha cedido voluntariamente al final de su cuanto de 4ms. Podría indicar exploraciones, clasificaciones o tiempos de compilación inesperados; o una máquina virtual con poca potencia o sobresuscrita. Si esto es un top espere, es un problema nuevo y se puede correlacionar con un problema de rendimiento real, mire estas consultas en sys.dm_exec_requests , vea si el plan actual está realizando una búsqueda u ordenación grande que podría evitarse y, si no hay una causa clara, profundice más. Más detalles en la biblioteca y en esta publicación sobre reacciones instintivas. | ||
| ¿Resoluble a nivel de consulta? | Tal vez | |
| Sí | ||
| ¿Necesita más información externa? | No | |
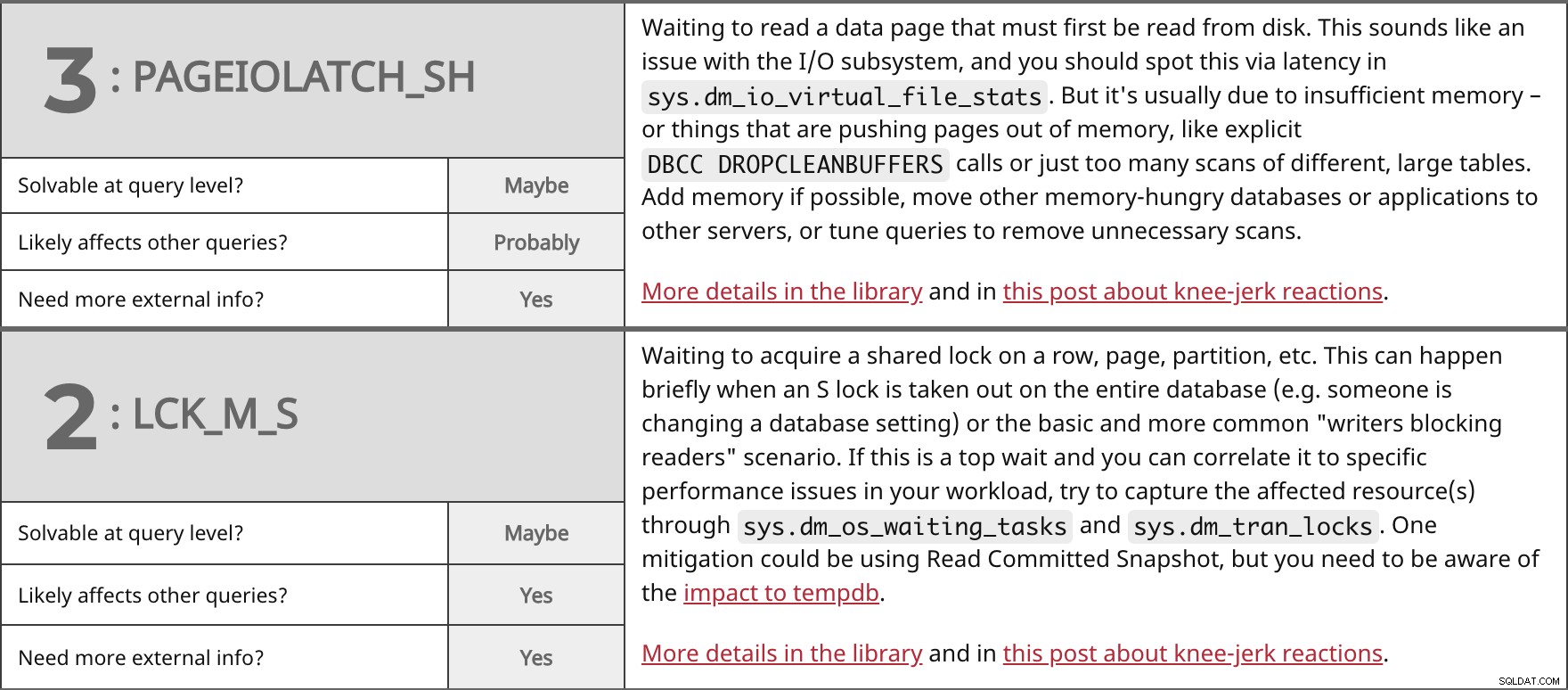
Esperando leer una página de datos que primero debe leerse desde el disco. Esto suena como un problema con el subsistema de E/S, y debería detectarlo a través de la latencia en sys.dm_io_virtual_file_stats . Pero generalmente se debe a una memoria insuficiente, o cosas que están sacando páginas de la memoria, como DBCC DROPCLEANBUFFERS explícitos. llamadas o simplemente demasiados escaneos de diferentes tablas grandes. Agregue memoria si es posible, mueva otras bases de datos o aplicaciones que consumen mucha memoria a otros servidores, o ajuste las consultas para eliminar análisis innecesarios. Más detalles en la biblioteca y en esta publicación sobre reacciones instintivas. | ||
| ¿Resoluble a nivel de consulta? | Tal vez | |
| Probablemente | ||
| ¿Necesita más información externa? | Sí | |
Esperando adquirir un bloqueo compartido en una fila, página, partición, etc. Esto puede suceder brevemente cuando se elimina un bloqueo S en toda la base de datos (por ejemplo, alguien está cambiando una configuración de base de datos) o el escenario básico y más común de "escritores que bloquean a los lectores". Si esta es una espera principal y puede correlacionarla con problemas de rendimiento específicos en su carga de trabajo, intente capturar los recursos afectados a través de sys.dm_os_waiting_tasks y sys.dm_tran_locks . Una mitigación podría ser usar la instantánea de lectura confirmada, pero debe tener en cuenta el impacto en tempdb. Más detalles en la biblioteca y en esta publicación sobre reacciones instintivas. | ||
| ¿Resoluble a nivel de consulta? | Tal vez | |
| Sí | ||
| ¿Necesita más información externa? | Sí | |
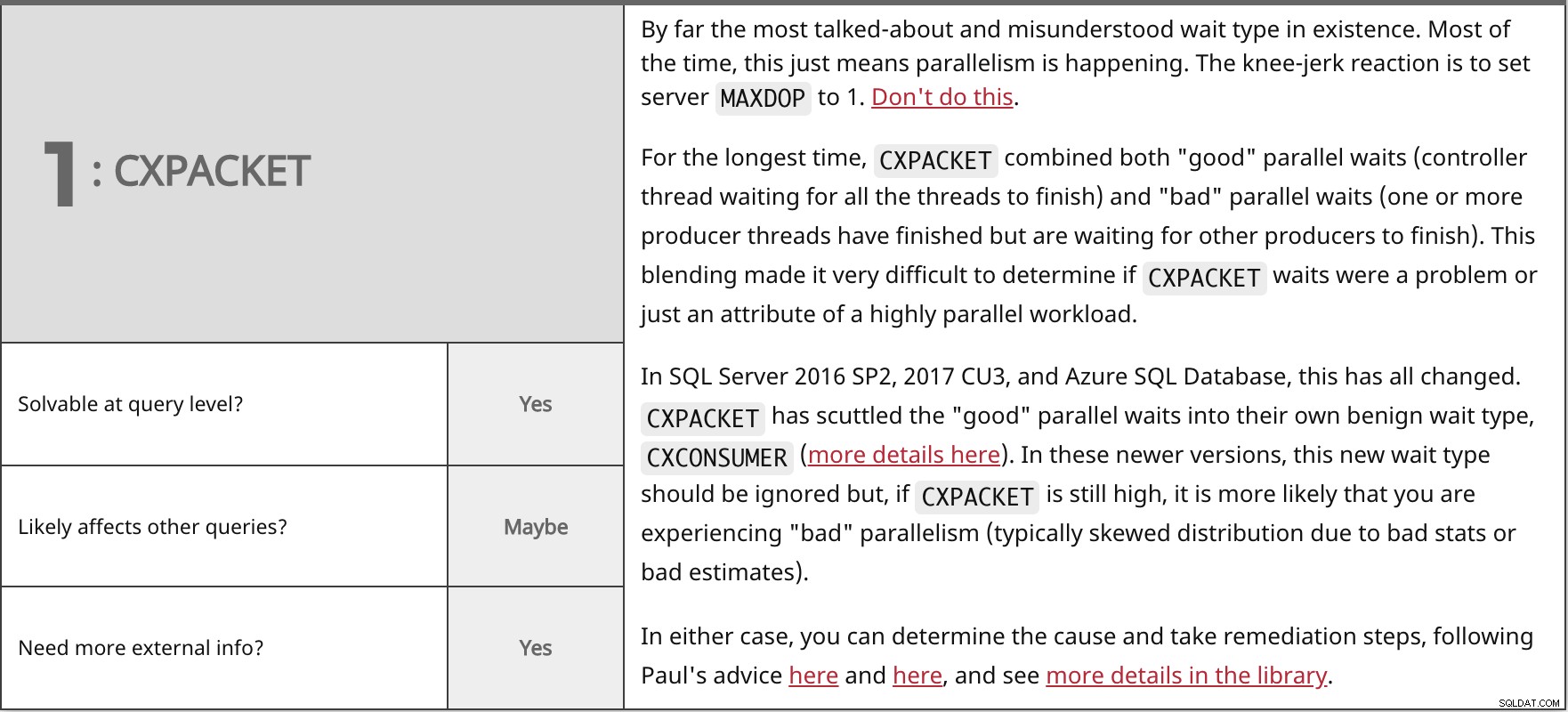
Con mucho, el tipo de espera más comentado e incomprendido que existe. La mayoría de las veces, esto solo significa que se está produciendo un paralelismo. La reacción instintiva es configurar el servidor MAXDOP a 1. No hagas esto.
Durante mucho tiempo,
En SQL Server 2016 SP2, 2017 CU3 y Azure SQL Database, todo esto ha cambiado. En cualquier caso, puede determinar la causa y tomar medidas correctivas, siguiendo los consejos de Paul aquí y aquí, y ver más detalles en la biblioteca. | ||
| ¿Resoluble a nivel de consulta? | Sí | |
| Tal vez | ||
| ¿Necesita más información externa? | Sí | |
Resumen
En la mayoría de estos casos, es mejor observar las esperas a nivel de instancia y solo concentrarse en las esperas a nivel de consulta cuando está solucionando consultas específicas que muestran problemas de rendimiento independientemente del tipo de espera. Estas son cosas que surgen por otras razones, como larga duración, CPU alta o E/S alta, y no se pueden explicar con cosas más simples (como un escaneo de índice agrupado cuando esperaba una búsqueda).
Incluso a nivel de instancia, no persiga cada espera que se convierta en la espera principal en su sistema; SIEMPRE ten una espera superior, y nunca podrás dejar de perseguirla. Asegúrese de ignorar las esperas benignas (Paul mantiene una lista) y solo preocúpese por las esperas que pueda asociar con un problema de rendimiento real que esté experimentando. Si CXPACKET Las esperas son altas, ¿y qué? ¿Hay algún otro síntoma además de que ese número sea "alto" o esté en la parte superior de la lista?
Todo se reduce a por qué está solucionando problemas en primer lugar. ¿Un solo usuario se queja de una sola instancia de una consulta no autorizada? ¿Está su servidor de rodillas? ¿Algo en el medio? En el primer caso, claro, saber por qué una consulta es lenta puede ser útil, pero es bastante costoso rastrear (no importa mantener indefinidamente) todas las esperas asociadas con cada consulta, todo el día, todos los días, en la extraña posibilidad de que quiero volver y revisarlos más tarde. Si se trata de un problema generalizado aislado de esa consulta, debería poder determinar qué está ralentizando esa consulta ejecutándola nuevamente y recopilando el plan de ejecución, el tiempo de compilación y otras métricas de tiempo de ejecución. Si fue algo único que sucedió el martes pasado, ya sea que tenga las esperas para esa única instancia de la consulta o no, es posible que no pueda resolver el problema sin más contexto. Tal vez hubo un bloqueo, pero no sabrá por qué, o tal vez hubo un pico de E/S, pero tendrá que buscar ese problema por separado. El tipo de espera por sí solo no suele proporcionar suficiente información excepto, en el mejor de los casos, un puntero a otra cosa.
Por supuesto, también necesito ganarme el sustento aquí. Nuestro producto estrella, SQL Sentry, adopta un enfoque holístico para el monitoreo. Recopilamos estadísticas de espera de toda la instancia, las clasificamos por usted y las graficamos en nuestro tablero:
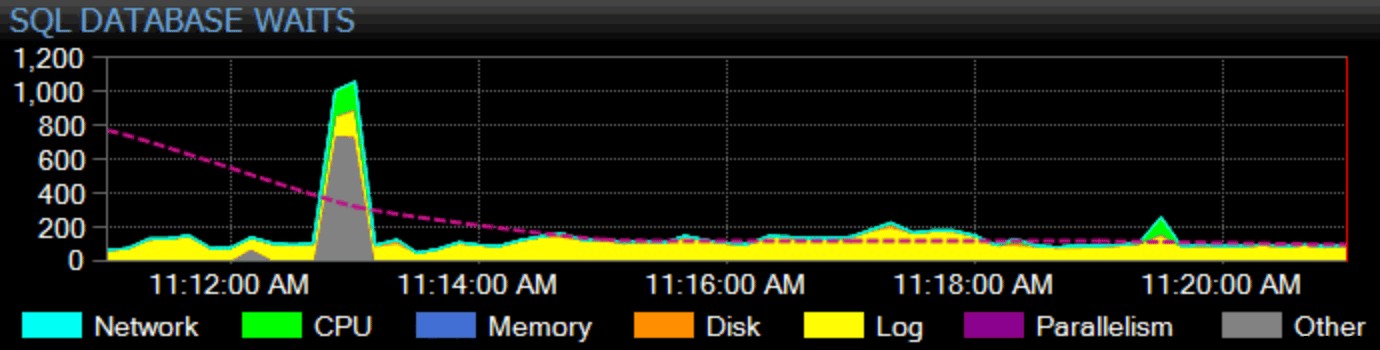
Puede personalizar cómo se categoriza cualquier espera individual y si esa categoría aparece o no en el tablero. Puede comparar las estadísticas de espera actuales con líneas de base integradas o personalizadas, e incluso configurar alertas o acciones cuando exceden alguna desviación definida de la línea de base. Y, quizás lo más importante, puede mirar un punto de datos del pasado y sincronizar todo el tablero con ese punto en el tiempo, para que pueda capturar todo el contexto circundante y cualquier otra situación que pueda haber influido en el problema. Cuando encuentre elementos más granulares en los que concentrarse, como bloqueos, latencia de disco alta o consultas con E/S alta o de larga duración, puede profundizar en esas métricas y llegar a la raíz del problema con bastante rapidez.
Para obtener más información sobre los enfoques generales de las estadísticas de espera y nuestra solución en particular, puede consultar el documento técnico de Kevin Kline, Solución de problemas de las estadísticas de espera de SQL Server, y puede descargar un seminario web de dos partes presentado por Paul Randal, Andy Yun (@SQLBek), y Andy Mallon (@AMtwo):
- Parte 1:solución de problemas de rendimiento mediante estadísticas de espera
- Parte 2:Análisis rápido de las estadísticas de espera con SentryOne
Y si desea probar la plataforma SentryOne, puede comenzar aquí con una oferta por tiempo limitado:
Descargue una prueba gratuita de 15 días