Este artículo es el segundo de una serie sobre errores, trampas y mejores prácticas de T-SQL. Esta vez me enfoco en errores clásicos que involucran subconsultas. Particularmente, cubro errores de sustitución y problemas lógicos de tres valores. Varios de los temas que cubro en la serie fueron sugeridos por compañeros MVP en una discusión que tuvimos sobre el tema. ¡Gracias a Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man y Paul White por sus sugerencias!
Error de sustitución
Para demostrar el clásico error de sustitución, usaré un escenario simple de pedidos de clientes. Ejecute el siguiente código para crear una función auxiliar denominada GetNums y para crear y completar las tablas Clientes y Pedidos:
SET NOCOUNT ON;
USE tempdb;
GO
DROP TABLE IF EXISTS dbo.Orders;
DROP TABLE IF EXISTS dbo.Customers;
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
CREATE TABLE dbo.Customers
(
custid INT NOT NULL
CONSTRAINT PK_Customers PRIMARY KEY,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100);
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
customerid INT NOT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (customerid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_customerid ON dbo.Orders(customerid); Actualmente, la tabla Clientes tiene 100 clientes con ID de clientes consecutivos en el rango de 1 a 100. 98 de esos clientes tienen pedidos correspondientes en la tabla Pedidos. Los clientes con ID 17 y 59 aún no realizaron ningún pedido y, por lo tanto, no tienen presencia en la tabla Pedidos.
Solo busca clientes que realizaron pedidos, e intenta lograrlo utilizando la siguiente consulta (llámela Consulta 1):
SET NOCOUNT OFF; SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT custid FROM dbo.Orders);
Se supone que debe recuperar 98 clientes, pero en su lugar obtiene los 100 clientes, incluidos aquellos con ID 17 y 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 17 Cust 17 18 Cust 18 ... 58 Cust 58 59 Cust 59 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (100 rows affected)
¿Puedes averiguar qué está mal?
Para aumentar la confusión, examine el plan para la Consulta 1 como se muestra en la Figura 1.
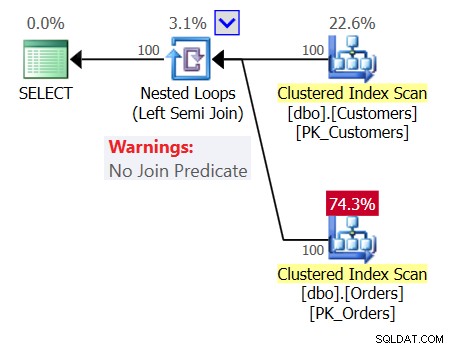 Figura 1:Plan para Consulta 1
Figura 1:Plan para Consulta 1
El plan muestra un operador de bucles anidados (semiunión izquierda) sin predicado de unión, lo que significa que la única condición para devolver un cliente es tener una tabla de pedidos no vacía, como si la consulta que escribiera fuera la siguiente:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
Probablemente esperaba un plan similar al que se muestra en la Figura 2.
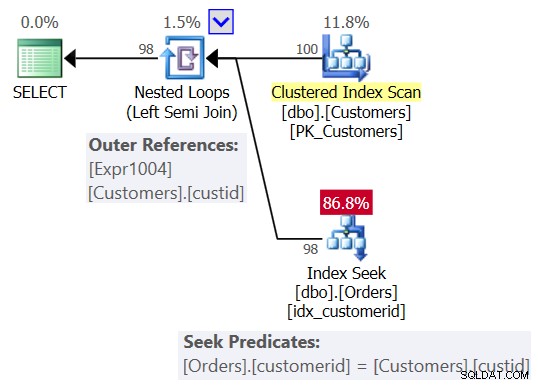 Figura 2:Plan esperado para la consulta 1
Figura 2:Plan esperado para la consulta 1
En este plan, verá un operador de bucles anidados (semiunión izquierda), con un escaneo del índice agrupado en Clientes como entrada externa y una búsqueda en el índice de la columna de identificación de cliente en Pedidos como entrada interna. También verá una referencia externa (parámetro correlacionado) basada en la columna custid en Customers y el predicado de búsqueda Orders.customerid =Customers.custid.
Entonces, ¿por qué obtiene el plan de la Figura 1 y no el de la Figura 2? Si aún no lo ha descubierto, observe detenidamente las definiciones de ambas tablas, específicamente los nombres de las columnas, y los nombres de las columnas que se usan en la consulta. Notará que la tabla Customers contiene los ID de los clientes en una columna llamada custid y que la tabla Orders contiene los ID de los clientes en una columna llamada customerid. Sin embargo, el código usa custid tanto en las consultas internas como externas. Dado que la referencia a custid en la consulta interna no está calificada, SQL Server tiene que resolver de qué tabla proviene la columna. De acuerdo con el estándar SQL, se supone que SQL Server debe buscar primero la columna en la tabla que se consulta en el mismo ámbito, pero dado que no hay una columna llamada custid en Pedidos, se supone que debe buscarla en la tabla en el exterior alcance, y esta vez hay una coincidencia. Entonces, sin querer, la referencia a custid se convierte implícitamente en una referencia correlacionada, como si escribiera la siguiente consulta:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT Customers.custid FROM dbo.Orders);
Siempre que Pedidos no esté vacío y que el valor externo de la identificación no sea NULO (no puede ser en nuestro caso ya que la columna se define como NO NULO), siempre obtendrá una coincidencia porque compara el valor consigo mismo . Entonces la consulta 1 se convierte en el equivalente de:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
Si la tabla externa admitiera valores NULL en la columna custid, la consulta 1 habría sido equivalente a:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders) AND custid IS NOT NULL;
Ahora comprende por qué la Consulta 1 se optimizó con el plan de la Figura 1 y por qué recuperó los 100 clientes.
Hace algún tiempo visité a un cliente que tenía un error similar, pero desafortunadamente con una instrucción DELETE. Piensa por un momento lo que esto significa. ¡Todas las filas de la tabla se borraron y no solo las que originalmente tenían la intención de eliminar!
En cuanto a las mejores prácticas que pueden ayudarlo a evitar tales errores, hay dos principales. En primer lugar, tanto como pueda controlarlo, asegúrese de utilizar nombres de columna coherentes en las tablas para los atributos que representan lo mismo. En segundo lugar, asegúrese de calificar en la tabla las referencias de las columnas en las subconsultas, incluidas las independientes donde esta no es una práctica común. Por supuesto, puede usar el alias de la tabla si prefiere no usar los nombres completos de la tabla. Aplicando esta práctica a nuestra consulta, suponga que su intento inicial usó el siguiente código:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.custid FROM dbo.Orders AS O);
Aquí no está permitiendo la resolución implícita de nombres de columnas y, por lo tanto, SQL Server genera el siguiente error:
Msg 207, Level 16, State 1, Line 108 Invalid column name 'custid'.
Vaya y verifique los metadatos de la tabla Pedidos, se dé cuenta de que usó el nombre de columna incorrecto y corrija la consulta (llámela Consulta 2), así:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.customerid FROM dbo.Orders AS O);
Esta vez obtiene el resultado correcto con 98 clientes, excluyendo los clientes con ID 17 y 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 18 Cust 18 .. 58 Cust 58 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (98 rows affected)
También obtiene el plan esperado que se muestra anteriormente en la Figura 2.
Aparte, está claro por qué Customers.custid es una referencia externa (parámetro correlacionado) en el operador Nested Loops (Left Semi Join) en la Figura 2. Lo que es menos obvio es por qué Expr1004 también aparece en el plan como una referencia externa. El compañero MVP de SQL Server, Paul White, teoriza que podría estar relacionado con el uso de información de la hoja de entrada externa para insinuar el motor de almacenamiento para evitar la duplicación de esfuerzos por parte de los mecanismos de lectura anticipada. Puede encontrar los detalles aquí.
Problema de lógica de tres valores
Un error común relacionado con las subconsultas tiene que ver con los casos en los que la consulta externa usa el predicado NOT IN y la subconsulta puede potencialmente devolver valores NULL entre sus valores. Por ejemplo, suponga que necesita poder almacenar pedidos en nuestra tabla Pedidos con NULL como ID de cliente. Tal caso representaría un pedido que no está asociado con ningún cliente; por ejemplo, un pedido que compensa las inconsistencias entre los conteos reales de productos y los conteos registrados en la base de datos.
Utilice el siguiente código para recrear la tabla Pedidos con la columna de identificación que permite NULL y, por ahora, complétela con los mismos datos de muestra que antes (con pedidos por ID de cliente del 1 al 100, sin incluir el 17 y el 59):
DROP TABLE IF EXISTS dbo.Orders;
GO
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
custid INT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (custid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_custid ON dbo.Orders(custid); Tenga en cuenta que mientras estamos en eso, seguí la mejor práctica discutida en la sección anterior para usar nombres de columna consistentes en todas las tablas para los mismos atributos, y nombré la columna en la tabla Pedidos como custid como en la tabla Clientes.
Suponga que necesita escribir una consulta que devuelva clientes que no realizaron pedidos. Se le ocurre la siguiente solución simplista utilizando el predicado NOT IN (llámelo Consulta 3, primera ejecución):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
Esta consulta devuelve el resultado esperado con los clientes 17 y 59:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Se realiza un inventario en el almacén de la empresa y se encuentra una inconsistencia entre la cantidad real de algún producto y la cantidad registrada en la base de datos. Entonces, agrega una orden de compensación ficticia para dar cuenta de la inconsistencia. Dado que no hay un cliente real asociado con el pedido, utiliza un NULL como ID de cliente. Ejecute el siguiente código para agregar un encabezado de pedido de este tipo:
INSERT INTO dbo.Orders(custid) VALUES(NULL);
Ejecute Consulta 3 por segunda vez:
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
Esta vez, obtienes un resultado vacío:
custid companyname ------- ------------ (0 rows affected)
Claramente, algo anda mal. Sabe que los clientes 17 y 59 no realizaron ningún pedido y, de hecho, aparecen en la tabla Clientes pero no en la tabla Pedidos. Sin embargo, el resultado de la consulta afirma que no hay ningún cliente que no haya realizado ningún pedido. ¿Puedes averiguar dónde está el error y cómo solucionarlo?
El error tiene que ver con el NULL en la tabla de Pedidos, por supuesto. Para SQL, un NULL es un marcador de un valor faltante que podría representar un cliente aplicable. SQL no sabe que para nosotros NULL representa un cliente faltante e inaplicable (irrelevante). Para todos los clientes en la tabla Clientes que están presentes en la tabla Pedidos, el predicado IN encuentra una coincidencia que arroja VERDADERO y la parte NOT IN lo convierte en FALSO, por lo tanto, la fila del cliente se descarta. Hasta aquí todo bien. Pero para los clientes 17 y 59, el predicado IN arroja DESCONOCIDO ya que todas las comparaciones con valores distintos de NULL arrojan FALSO, y la comparación con NULL arroja DESCONOCIDO. Recuerde, SQL asume que NULL podría representar a cualquier cliente aplicable, por lo que el valor lógico DESCONOCIDO indica que se desconoce si el ID de cliente externo es igual al ID de cliente NULL interno. FALSO O FALSO… O DESCONOCIDO es DESCONOCIDO. Luego, la parte NOT IN aplicada a UNKNOWN todavía produce UNKNOWN.
En términos más simples en inglés, solicitó devolver a los clientes que no realizaron pedidos. Entonces, naturalmente, la consulta descarta todos los clientes de la tabla Clientes que están presentes en la tabla Pedidos porque se sabe con certeza que realizaron pedidos. En cuanto al resto (17 y 59 en nuestro caso), la consulta los descarta desde SQL, al igual que se desconoce si realizaron pedidos, se desconoce si no realizaron pedidos y el filtro necesita certeza (VERDADERO) en para devolver una fila. ¡Qué pepinillo!
Entonces, tan pronto como el primer NULL ingrese a la tabla de Pedidos, desde ese momento siempre obtendrá un resultado vacío de la consulta NOT IN. ¿Qué pasa con los casos en los que en realidad no tiene NULL en los datos, pero la columna permite NULL? Como vio en la primera ejecución de la Consulta 3, en tal caso obtiene el resultado correcto. Tal vez esté pensando que la aplicación nunca introducirá valores NULL en los datos, por lo que no debe preocuparse por nada. Esa es una mala práctica por un par de razones. Por un lado, si una columna se define para permitir NULL, es casi seguro que los NULL eventualmente llegarán allí, incluso si no se supone que lo hagan; Es solo cuestión de tiempo. Podría ser el resultado de importar datos incorrectos, un error en la aplicación y otras razones. Por otro lado, incluso si los datos no contienen NULL, si la columna los permite, el optimizador debe tener en cuenta la posibilidad de que NULL estén presentes cuando crea el plan de consulta, y en nuestra consulta NOT IN esto incurre en una penalización de rendimiento. . Para demostrar esto, considere el plan para la primera ejecución de la Consulta 3 antes de agregar la fila con NULL, como se muestra en la Figura 3.
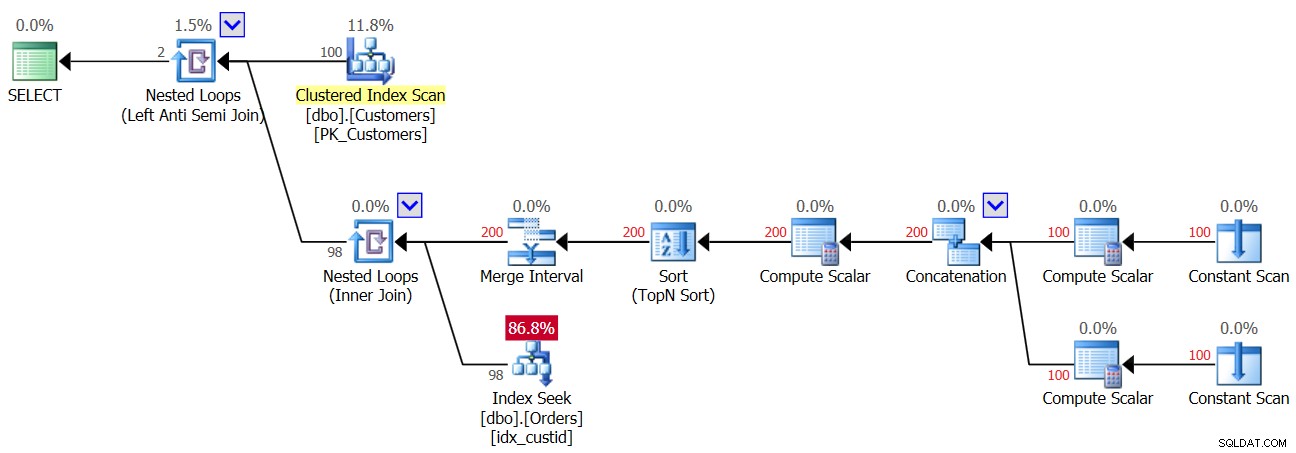 Figura 3:Plan para la primera ejecución de Consulta 3
Figura 3:Plan para la primera ejecución de Consulta 3
El operador superior de bucles anidados maneja la lógica de combinación izquierda antisemi. Básicamente, se trata de identificar las coincidencias y cortocircuitar la actividad interna tan pronto como se encuentra una coincidencia. La parte exterior del bucle extrae los 100 clientes de la tabla Clientes, por lo que la parte interior del bucle se ejecuta 100 veces.
La parte interior del bucle superior ejecuta un operador de bucles anidados (unión interior). La parte exterior del bucle inferior crea dos filas por cliente, una para un caso NULL y otra para el ID de cliente actual, en este orden. No deje que el operador Merge Interval lo confunda. Normalmente se usa para fusionar intervalos superpuestos, por ejemplo, un predicado como col1 ENTRE 20 Y 30 O col1 ENTRE 25 Y 35 se convierte en col1 ENTRE 20 Y 35. Esta idea se puede generalizar para eliminar duplicados en un predicado IN. En nuestro caso, realmente no puede haber ningún duplicado. En términos simplificados, como se mencionó, piense en la parte exterior del bucle como si creara dos filas por cliente:la primera para un caso NULL y la segunda para el ID de cliente actual. Luego, la parte interna del ciclo primero realiza una búsqueda en el índice idx_custid en Orders para buscar un NULL. Si se encuentra un NULL, no activa la segunda búsqueda de la ID de cliente actual (recuerde el cortocircuito manejado por el bucle Anti Semi Join superior). En tal caso, el cliente externo se descarta. Pero si no se encuentra un NULL, el bucle inferior activa una segunda búsqueda para buscar el ID de cliente actual en Pedidos. Si se encuentra, el cliente externo se descarta. Si no se encuentra, se devuelve el cliente externo. Lo que esto significa es que cuando los valores NULL no están presentes en los pedidos, ¡este plan realiza dos búsquedas por cliente! Esto se puede observar en el plan como el número de filas 200 en la entrada exterior del bucle inferior. En consecuencia, aquí están las estadísticas de E/S que se informan para la primera ejecución:
Table 'Orders'. Scan count 200, logical reads 603
El plan para la segunda ejecución de la Consulta 3, después de agregar una fila con NULL a la tabla Pedidos, se muestra en la Figura 4.
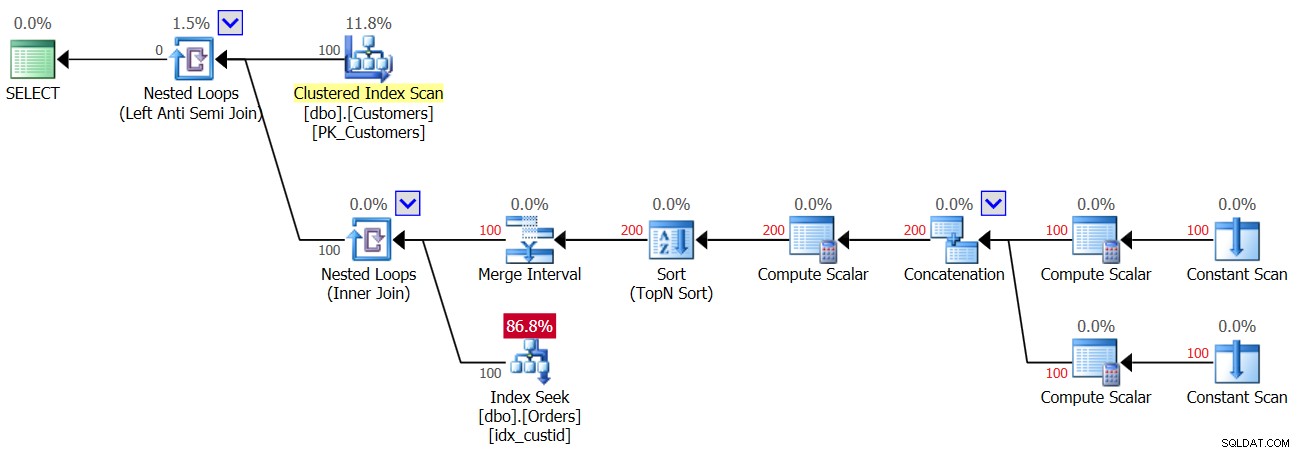 Figura 4:Plan para la segunda ejecución de Consulta 3
Figura 4:Plan para la segunda ejecución de Consulta 3
Dado que NULL está presente en la tabla, para todos los clientes, la primera ejecución del operador Index Seek encuentra una coincidencia y, por lo tanto, todos los clientes se descartan. Entonces sí, solo hacemos una búsqueda por cliente y no dos, así que esta vez obtienes 100 búsquedas y no 200; sin embargo, al mismo tiempo, esto significa que obtendrá un resultado vacío.
Estas son las estadísticas de E/S que se informan para la segunda ejecución:
Table 'Orders'. Scan count 100, logical reads 300
Una solución a esta tarea cuando los NULL son posibles entre los valores devueltos en la subconsulta es simplemente filtrarlos, así (llámelo Solución 1/Consulta 4):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O WHERE O.custid IS NOT NULL);
Este código genera el resultado esperado:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
La desventaja de esta solución es que debe recordar agregar el filtro. Prefiero una solución que use el predicado NOT EXISTS, donde la subconsulta tiene una correlación explícita comparando el ID de cliente del pedido con el ID de cliente del cliente, así (llámelo Solución 2/Consulta 5):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE NOT EXISTS (SELECT * FROM dbo.Orders AS O WHERE O.custid = C.custid);
Recuerde que una comparación basada en la igualdad entre NULL y cualquier cosa produce UNKNOWN, y UNKNOWN es descartado por un filtro WHERE. Por lo tanto, si existen valores NULL en los pedidos, el filtro de la consulta interna los eliminará sin necesidad de agregar un tratamiento NULL explícito y, por lo tanto, no tendrá que preocuparse de si los valores NULL existen o no en los datos.
Esta consulta genera el resultado esperado:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Los planes para ambas soluciones se muestran en la Figura 5.
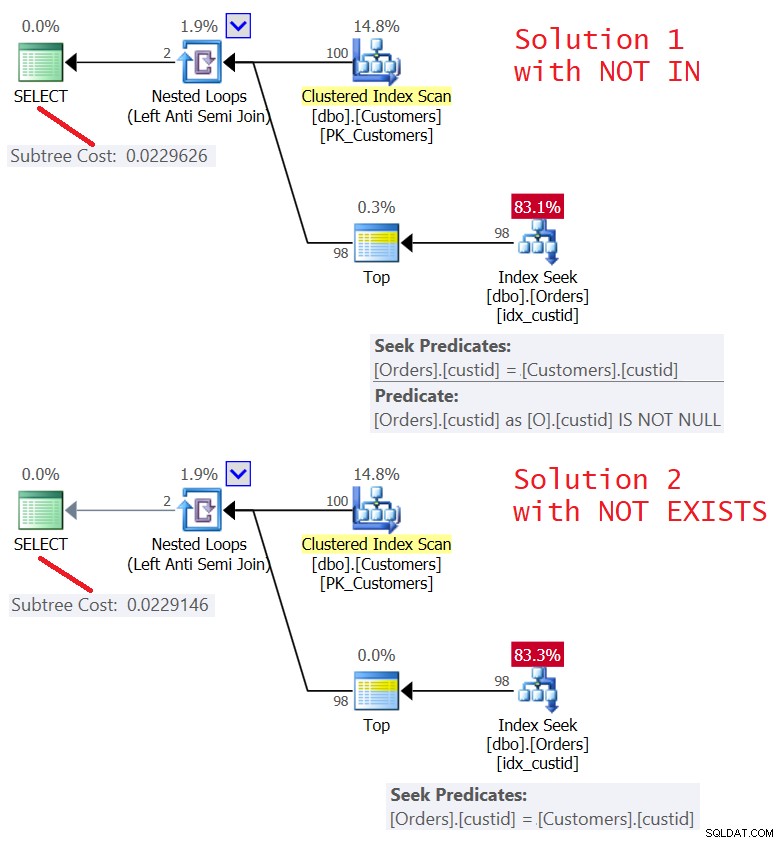 Figura 5:Planes para Consulta 4 (Solución 1) y Consulta 5 (Solución 2 )
Figura 5:Planes para Consulta 4 (Solución 1) y Consulta 5 (Solución 2 )
Como puede ver, los planes son casi idénticos. También son bastante eficientes, ya que utilizan una optimización de Left Semi Join con un cortocircuito. Ambos realizan solo 100 búsquedas en el índice idx_custid en Pedidos, y con el operador Top, aplican un cortocircuito después de tocar una fila en la hoja.
Las estadísticas de E/S para ambas consultas son las mismas:
Table 'Orders'. Scan count 100, logical reads 348
Sin embargo, una cosa a considerar es si existe alguna posibilidad de que la tabla externa tenga valores NULL en la columna correlacionada (custid en nuestro caso). Es muy poco probable que sea relevante en un escenario como los pedidos de los clientes, pero podría ser relevante en otros escenarios. Si ese es el caso, ambas soluciones manejan un NULL externo incorrectamente.
Para demostrar esto, suelte y vuelva a crear la tabla Clientes con un NULL como uno de los ID de cliente ejecutando el siguiente código:
DROP TABLE IF EXISTS dbo.Customers;
GO
CREATE TABLE dbo.Customers
(
custid INT NULL
CONSTRAINT UNQ_Customers_custid UNIQUE CLUSTERED,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT CAST(NULL AS INT) AS custid, 'Cust NULL' AS companyname
UNION ALL
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100); La solución 1 no devolverá un NULL externo independientemente de si hay un NULL interno presente o no.
La solución 2 devolverá un NULL externo independientemente de si hay un NULL interno presente o no.
Si desea manejar NULL como maneja valores que no son NULL, es decir, devuelve NULL si está presente en Clientes pero no en Pedidos, y no lo devuelve si está presente en ambos, debe cambiar la lógica de la solución para usar una distinción -comparación basada en lugar de una comparación basada en la igualdad. Esto se puede lograr combinando el predicado EXISTS y el operador de conjunto EXCEPT, así (llame a esta Solución 3/Consulta 6):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Dado que actualmente hay NULL tanto en Clientes como en Pedidos, esta consulta correctamente no devuelve NULL. Aquí está el resultado de la consulta:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Ejecute el siguiente código para eliminar la fila con NULL de la tabla Pedidos y vuelva a ejecutar la Solución 3:
DELETE FROM dbo.Orders WHERE custid IS NULL; SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Esta vez, dado que NULL está presente en Clientes pero no en Pedidos, el resultado incluye NULL:
custid companyname ------- ------------ NULL Cust NULL 17 Cust 17 59 Cust 59 (3 rows affected)
El plan para esta solución se muestra en la Figura 6:
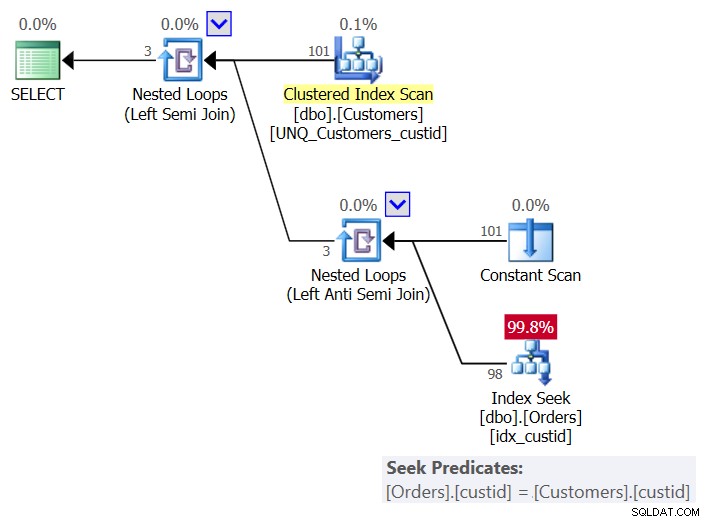 Figura 6:Plan para la Consulta 6 (Solución 3)
Figura 6:Plan para la Consulta 6 (Solución 3)
Por cliente, el plan utiliza un operador Constant Scan para crear una fila con el cliente actual y aplica una sola búsqueda en el índice idx_custid en Pedidos para verificar si el cliente existe en Pedidos. Terminas con una búsqueda por cliente. Dado que actualmente tenemos 101 clientes en la tabla, obtenemos 101 búsquedas.
Estas son las estadísticas de E/S para esta consulta:
Table 'Orders'. Scan count 101, logical reads 415
Conclusión
Este mes cubrí los errores, las trampas y las mejores prácticas relacionadas con las subconsultas. Cubrí errores de sustitución y problemas de lógica de tres valores. Recuerde usar nombres de columna coherentes en todas las tablas y siempre calificar las columnas en las subconsultas, incluso cuando sean independientes. Recuerde también aplicar una restricción NOT NULL cuando se supone que la columna no debe permitir valores NULL, y tener siempre en cuenta los valores NULL cuando sean posibles en sus datos. Asegúrese de incluir NULL en sus datos de muestra cuando estén permitidos para que pueda detectar errores en su código más fácilmente cuando lo pruebe. Tenga cuidado con el predicado NOT IN cuando se combina con subconsultas. Si NULL es posible en el resultado de la consulta interna, el predicado NOT EXISTS suele ser la alternativa preferida.