En un consejo reciente, describí un escenario en el que una instancia de SQL Server 2016 parecía tener problemas con los tiempos de los puntos de control. El registro de errores se completó con una cantidad alarmante de entradas de FlushCache como esta:
FlushCache: cleaned up 394031 bufs with 282252 writes in 65544 ms (avoided 21 new dirty bufs) for db 19:0
average writes per second: 4306.30 writes/sec
average throughput: 46.96 MB/sec, I/O saturation: 53644, context switches 101117
last target outstanding: 639360, avgWriteLatency 1 Estaba un poco perplejo por este problema, ya que el sistema ciertamente no se quedó atrás:muchos núcleos, 3 TB de memoria y almacenamiento XtremIO. Y ninguno de estos mensajes de FlushCache se emparejó con las advertencias reveladoras de E/S de 15 segundos en el registro de errores. Aún así, si acumula un montón de bases de datos de alta transacción allí, el procesamiento del punto de control puede volverse bastante lento. No tanto por la E/S directa, sino por una mayor reconciliación que se debe hacer con una gran cantidad de páginas sucias (no solo de confirmadas transacciones) dispersos en una cantidad tan grande de memoria, y potencialmente esperando al escritor perezoso (ya que solo hay uno para toda la instancia).
Hice una lectura rápida de "refresco" de algunas publicaciones muy valiosas:
- Cómo funcionan los puntos de control y qué se registra
- Puntos de control de la base de datos (SQL Server)
- ¿Qué hace el punto de control para tempdb?
- Un mito de SQL Server DBA al día:(15/30) el punto de control solo escribe páginas de transacciones confirmadas
- Es posible que los mensajes de FlushCache no sean un bloqueo de E/S real
- Punto de control indirecto y tempdb:lo bueno, lo malo y el programador que no rinde
- Cambiar el tiempo de recuperación objetivo de una base de datos
- Cómo funciona:¿Cuándo se agrega el mensaje FlushCache al registro de errores de SQL Server?
- Cambios en el comportamiento del punto de control de SQL Server 2016
- Intervalo de recuperación de destino y punto de control indirecto:nuevo valor predeterminado de 60 segundos en SQL Server 2016
- SQL 2016:simplemente se ejecuta más rápido:punto de control indirecto predeterminado
- Servidor SQL:RAM grande y puntos de control de base de datos
Rápidamente decidí que quería realizar un seguimiento de la duración de los puntos de control para algunas de estas bases de datos más problemáticas, antes y después de cambiar su intervalo de recuperación objetivo de 0 (la forma antigua) a 60 segundos (la forma nueva). En enero, tomé prestada una sesión de eventos extendidos de mi amiga y compañera canadiense Hannah Vernon:
CREATE EVENT SESSION CheckpointTracking ON SERVER
ADD EVENT sqlserver.checkpoint_begin
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
, ADD EVENT sqlserver.checkpoint_end
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
ADD TARGET package0.event_file
(
SET filename = N'L:\SQL\CP\CheckPointTracking.xel',
max_file_size = 50, -- MB
max_rollover_files = 50
)
WITH
(
MAX_MEMORY = 4096 KB,
MAX_DISPATCH_LATENCY = 30 SECONDS,
TRACK_CAUSALITY = ON,
STARTUP_STATE = ON
);
GO
ALTER EVENT SESSION CheckpointTracking ON SERVER
STATE = START; Marqué la hora en que cambié cada base de datos y luego analicé los resultados de los datos de eventos extendidos usando una consulta publicada en la sugerencia original. Los resultados mostraron que después de cambiar a puntos de control indirectos, cada base de datos pasó de puntos de control con un promedio de 30 segundos a puntos de control con un promedio de menos de una décima de segundo (y muchos menos puntos de control en la mayoría de los casos también). Hay mucho que desempaquetar de este gráfico, pero estos son los datos sin procesar que usé para presentar mi argumento (haga clic para ampliar):
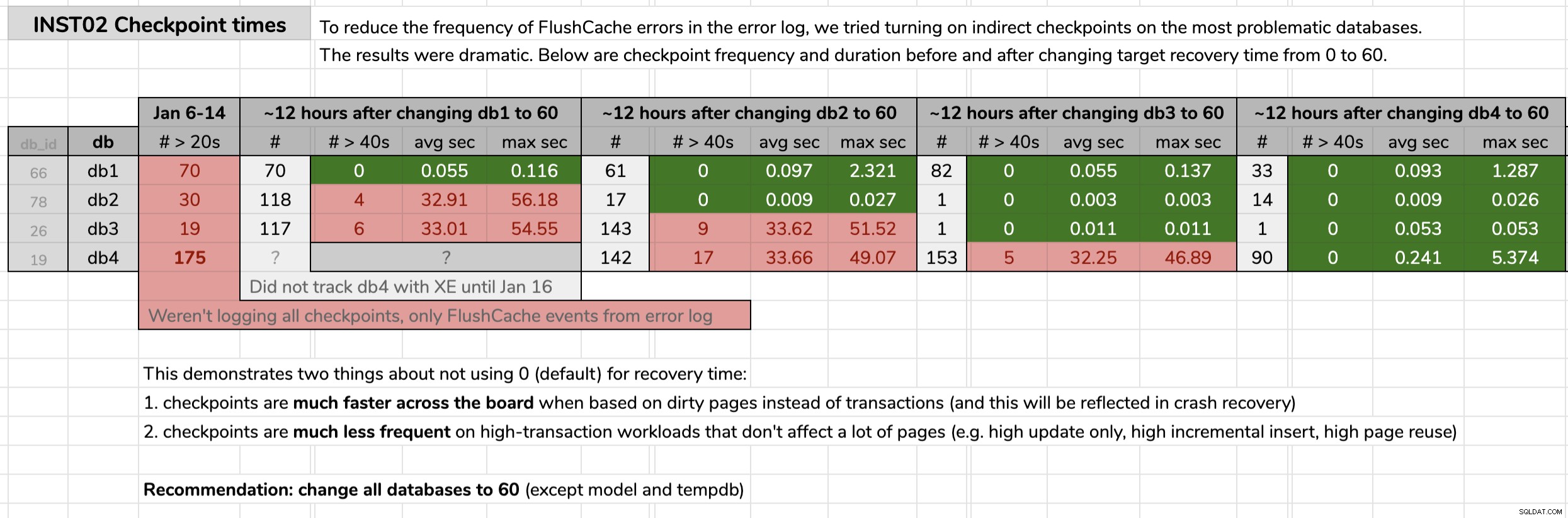 Mi evidencia
Mi evidencia
Una vez que probé mi caso en estas bases de datos problemáticas, obtuve luz verde para implementar esto en todas nuestras bases de datos de usuarios en todo nuestro entorno. Primero en desarrollo y luego en producción, ejecuté lo siguiente a través de una consulta de CMS para obtener un indicador de cuántas bases de datos estábamos hablando:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += CASE
WHEN (ag.role = N'PRIMARY' AND ag.ag_status = N'READ_WRITE') OR ag.role IS NULL THEN N'
ALTER DATABASE ' + QUOTENAME(d.name) + N' SET TARGET_RECOVERY_TIME = 60 SECONDS;'
ELSE N'
PRINT N''-- fix ' + QUOTENAME(d.name) + N' on Primary.'';'
END
FROM sys.databases AS d
OUTER APPLY
(
SELECT role = s.role_desc,
ag_status = DATABASEPROPERTYEX(c.database_name, N'Updateability')
FROM sys.dm_hadr_availability_replica_states AS s
INNER JOIN sys.availability_databases_cluster AS c
ON s.group_id = c.group_id
AND d.name = c.database_name
WHERE s.is_local = 1
) AS ag
WHERE d.target_recovery_time_in_seconds <> 60
AND d.database_id > 4
AND d.[state] = 0
AND d.is_in_standby = 0
AND d.is_read_only = 0;
SELECT DatabaseCount = @@ROWCOUNT, Version = @@VERSION, cmd = @sql;
--EXEC sys.sp_executesql @sql; Algunas notas sobre la consulta:
database_id > 4
No quería tocarmasteren absoluto, y no quería cambiartempdbsin embargo, debido a que no estamos en la última CU de SQL Server 2017 (consulte KB #4497928 por una razón, ese detalle es importante). Este último descartamodel, también, porque cambiar el modelo afectaría atempdben la próxima conmutación por error/reinicio. Podría haber cambiadomsdb, y es posible que vuelva a hacerlo en algún momento, pero mi enfoque aquí estaba en las bases de datos de los usuarios.
[state] / is_read_only / is_in_standby
Debemos asegurarnos de que las bases de datos que estamos tratando de cambiar estén en línea y no sean de solo lectura (pulsé una que actualmente estaba configurada como solo lectura y tendré que volver a esa más tarde).
OUTER APPLY (...)
Queremos restringir nuestras acciones a las bases de datos que son primarias en un AG o que no están en ningún AG (y también tenemos que tener en cuenta los AG distribuidos, donde podemos ser primarios y locales, pero aún así no se puede escribir) . Si ejecuta la verificación en un secundario, no puede solucionar el problema allí, pero aún debería recibir una advertencia al respecto. Gracias a Erik Darling por ayudar con esta lógica y a Taylor Martell por motivar las mejoras.
- Si tiene instancias que ejecutan versiones anteriores como SQL Server 2008 R2 (¡encontré una!), tendrá que modificar esto un poco, ya que el
target_recovery_time_in_secondsla columna no existe allí. Tuve que usar SQL dinámico para solucionar esto en un caso, pero también podría mover o eliminar temporalmente donde caen esas instancias en su jerarquía de CMS. Tampoco podría ser perezoso como yo y ejecutar el código en Powershell en lugar de una ventana de consulta de CMS, donde podría filtrar fácilmente las bases de datos dadas cualquier cantidad de propiedades antes de encontrar problemas de tiempo de compilación.
En producción, había 102 instancias (aproximadamente la mitad) y 1590 bases de datos en total que usaban la configuración anterior. Todo estaba en SQL Server 2017, entonces, ¿por qué esta configuración era tan frecuente? Porque se crearon antes de que los puntos de control indirectos se convirtieran en los predeterminados en SQL Server 2016. Aquí hay una muestra de los resultados:
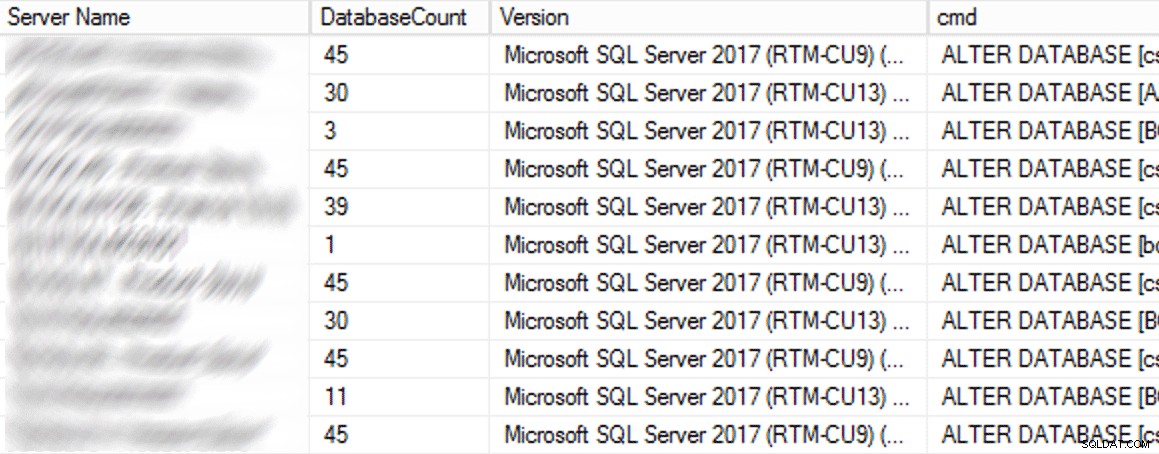 Resultados parciales de la consulta CMS.
Resultados parciales de la consulta CMS.
Luego ejecuté la consulta CMS nuevamente, esta vez con sys.sp_executesql sin comentar Se tardó unos 12 minutos en ejecutarlo en las 1590 bases de datos. En una hora, ya estaba recibiendo informes de personas que observaban una caída significativa en la CPU en algunas de las instancias más ocupadas.
Todavía tengo más que hacer. Por ejemplo, necesito probar el impacto potencial en tempdb , y si hay algún peso en nuestro caso de uso para las historias de terror que he escuchado. Y debemos asegurarnos de que la configuración de 60 segundos sea parte de nuestra automatización y de todas las solicitudes de creación de bases de datos, especialmente aquellas que están codificadas o restauradas a partir de copias de seguridad.