Uno de los problemas más comunes que ocurren al ejecutar transacciones simultáneas es el problema de lectura sucia. Una lectura sucia ocurre cuando se permite que una transacción lea datos que están siendo modificados por otra transacción que se ejecuta simultáneamente pero que aún no se ha comprometido.
Si la transacción que modifica los datos se compromete, el problema de lectura sucia no ocurre. Sin embargo, si la transacción que modifica los datos se revierte después de que la otra transacción haya leído los datos, la última transacción tiene datos sucios que en realidad no existen.
Como siempre, asegúrese de tener una buena copia de seguridad antes de experimentar con un nuevo código. Consulte este artículo sobre cómo realizar copias de seguridad de bases de datos MS SQL si no está seguro.
Entendamos esto con la ayuda de un ejemplo. Supongamos que tenemos una tabla llamada "Producto" que almacena la identificación, el nombre y los artículos en stock para el producto.
La tabla se ve así:
[identificación de la tabla=20 /]
Suponga que tiene un sistema en línea donde un usuario puede comprar productos y verlos al mismo tiempo. Fíjate en la siguiente figura.
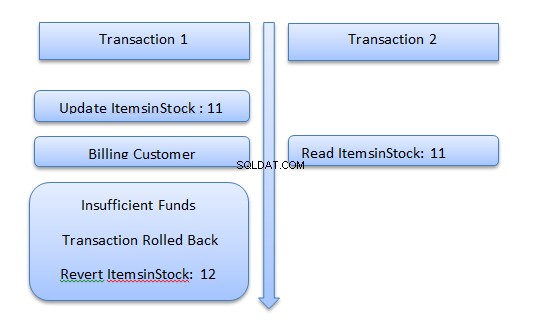
Considere un escenario en el que un usuario intenta comprar un producto. La transacción 1 realizará la tarea de compra para el usuario. El primer paso en la transacción será actualizar los ItemsinStock.
Antes de la transacción, hay 12 artículos en stock; la transacción actualizará esto a 11. La transacción ahora se comunicará con un portal de facturación externo.
Si en este momento, otra transacción, digamos la Transacción 2, lee ItemsInStock para computadoras portátiles, será 11. Sin embargo, si posteriormente, el usuario detrás de la Transacción 1 resulta que no tiene fondos suficientes en su cuenta, la Transacción 1 se transferirá atrás y el valor de la columna ItemsInStock volverá a 12.
Sin embargo, la transacción 2 tiene 11 como valor para la columna ItemsInStock. Estos son datos sucios y el problema se llama problema de lectura sucia.
Ejemplo práctico de problema de lectura sucia
Echemos un vistazo al problema de lectura sucia en acción en SQL Server. Como siempre, primero, creemos nuestra tabla y agreguemos algunos datos ficticios. Ejecute el siguiente script en su servidor de base de datos.
CREATE DATABASE pos;
USE pos;
CREATE TABLE products
(
Id INT PRIMARY KEY,
Name VARCHAR(50) NOT NULL,
ItemsinStock INT NOT NULL
)
INSERT into products
VALUES
(1, 'Laptop', 12),
(2, 'iPhone', 15),
(3, 'Tablets', 10)Ahora, abra dos instancias de SQL Server Management Studio una al lado de la otra. Ejecutaremos una transacción en cada una de estas instancias.
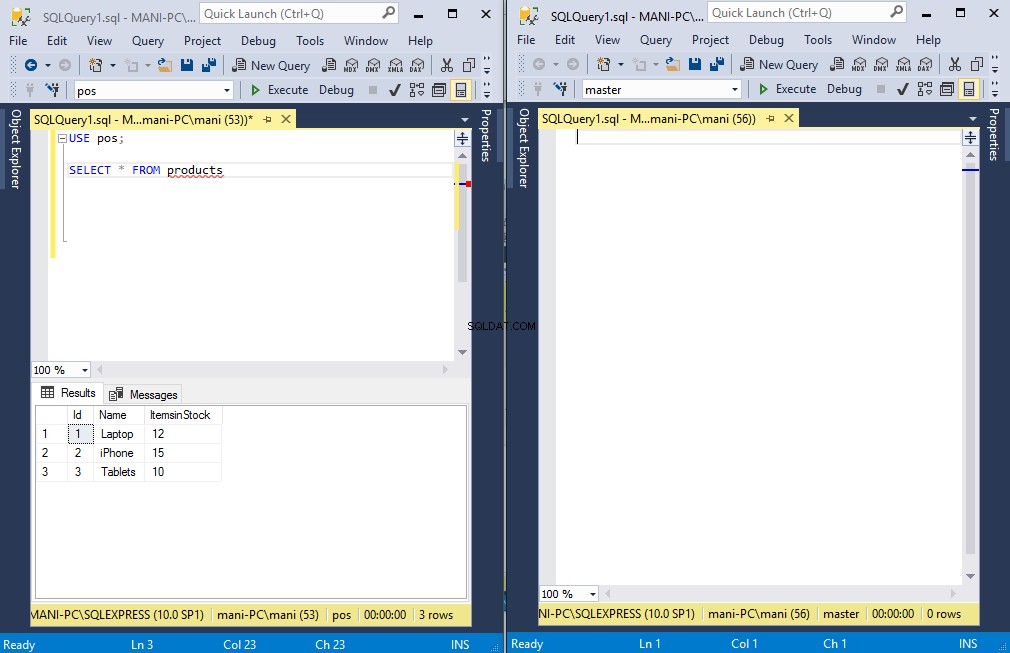
Agregue el siguiente script a la primera instancia de SSMS.
USE pos;
SELECT * FROM products
-- Transaction 1
BEGIN Tran
UPDATE products set ItemsInStock = 11
WHERE Id = 1
-- Billing the customer
WaitFor Delay '00:00:10'
Rollback TransactionEn el script anterior, comenzamos una nueva transacción que actualiza el valor de la columna "Artículos en stock" de la tabla de productos donde Id es 1. Luego simulamos el retraso para facturar al cliente usando las funciones 'Esperar' y 'Retraso'. Se ha establecido un retraso de 10 segundos en el script. Después de eso, simplemente revertimos la transacción.
En la segunda instancia de SSMS, simplemente agregamos la siguiente instrucción SELECT.
USE pos;
-- Transaction 2
SELECT * FROM products
WHERE Id = 1Ahora, primero ejecute la primera transacción, es decir, ejecute el script en la primera instancia de SSMS y luego ejecute inmediatamente el script en la segunda instancia de SSMS.
Verá que ambas transacciones seguirán ejecutándose durante 10 segundos y después de eso, verá que el valor de la columna "Artículos en stock" para el registro con Id 1 sigue siendo 12, como se muestra en la segunda transacción. Aunque la primera transacción lo actualizó a 11, esperó 10 segundos y luego lo revirtió a 12, el valor que muestra la segunda transacción es 12 en lugar de 11.
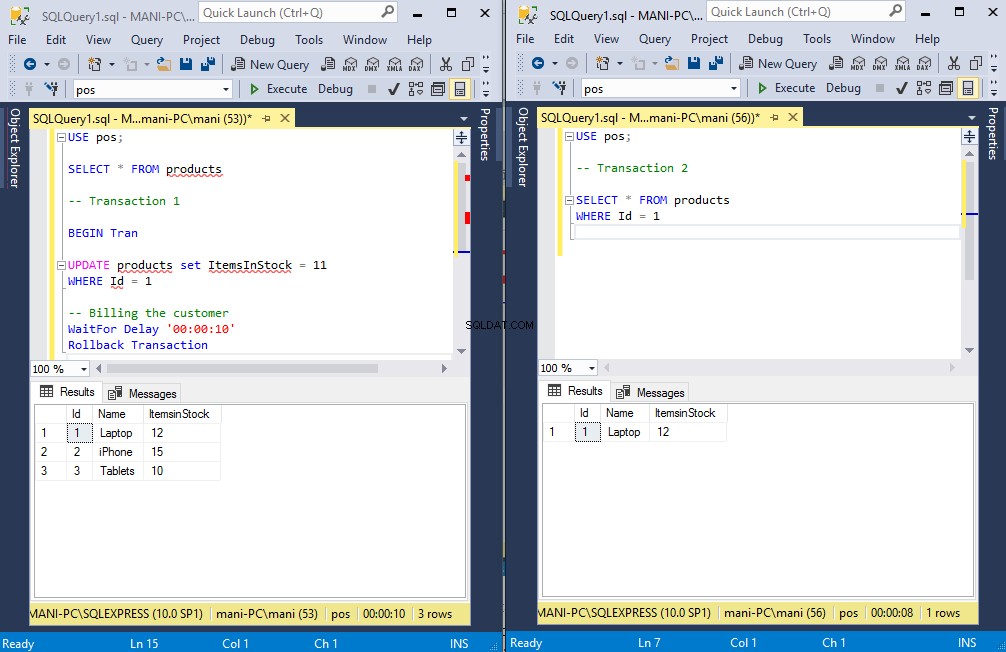
Lo que realmente sucedió es que cuando ejecutamos la primera transacción, actualizó el valor de la columna "Artículos en stock". Luego esperó 10 segundos y luego revirtió la transacción.
Aunque comenzamos la segunda transacción inmediatamente después de la primera, tuvo que esperar a que se completara la primera transacción. Es por eso que la segunda transacción también esperó 10 segundos y por qué la segunda transacción se ejecutó inmediatamente después de que la primera transacción completara su ejecución.
Leer nivel de aislamiento comprometido
¿Por qué la transacción 2 tuvo que esperar a que se completara la transacción 1 antes de ejecutarse?
La respuesta es que el nivel de aislamiento predeterminado entre transacciones es "lectura confirmada". El nivel de aislamiento de lectura confirmada garantiza que una transacción solo pueda leer los datos si se encuentran en el estado confirmado.
En nuestro ejemplo, la transacción 1 actualizó los datos pero no los comprometió hasta que se revirtió. Esta es la razón por la que la transacción 2 tuvo que esperar a que la transacción 1 confirmara los datos o revirtiera la transacción antes de poder leer los datos.
Ahora, en escenarios prácticos, a menudo tenemos múltiples transacciones en una sola base de datos al mismo tiempo y no queremos que cada transacción tenga que esperar su turno. Esto puede hacer que las bases de datos sean muy lentas. ¡Imagine comprar algo en línea en un sitio web grande que solo puede procesar una transacción a la vez!
Lectura de datos no confirmados
La respuesta a este problema es permitir que sus transacciones funcionen con datos no comprometidos.
Para leer datos no confirmados, simplemente establezca el nivel de aislamiento de la transacción en "lectura no confirmada". Actualice la transacción 2 agregando un nivel de aislamiento según el siguiente script.
USE pos;
-- Transaction 2
set transaction isolation level read uncommitted
SELECT * FROM products
WHERE Id = 1Ahora, si ejecuta la transacción 1 y luego ejecuta inmediatamente la transacción 2, verá que la transacción 2 no esperará a que la transacción 1 confirme los datos. La transacción 2 leerá inmediatamente los datos sucios. Esto se muestra en la siguiente figura:
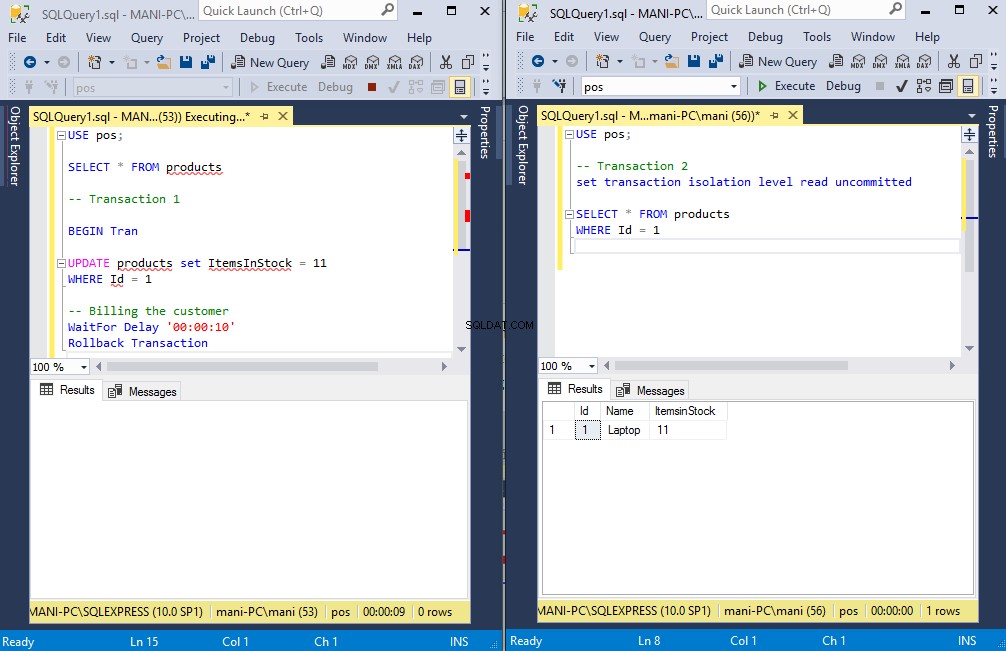
Aquí, la instancia de la izquierda ejecuta la transacción 1 y la instancia de la derecha ejecuta la transacción 2.
Ejecutamos primero la transacción 1, que actualiza el valor de "Artículos en stock" para los ID 1 a 11 desde 12 y luego espera 10 segundos antes de revertirse.
Mientras tanto, la transacción w lee los datos sucios que son 11, como se muestra en la ventana de resultados de la derecha. Debido a que la transacción 1 se retrotrae, este no es el valor real en la tabla. El valor real es 12. Intenta ejecutar la transacción 2 nuevamente y verás que esta vez recupera 12.
Lectura no confirmada es el único nivel de aislamiento que tiene el problema de lectura sucia. Este nivel de aislamiento es el menos restrictivo de todos los niveles de aislamiento y permite leer datos no confirmados.
Obviamente, el uso de Read Uncommitted tiene ventajas y desventajas, depende de la aplicación para la que se use su base de datos. Obviamente, sería una muy mala idea usar esto para la base de datos detrás de los sistemas ATM y otros sistemas muy seguros. Sin embargo, para las aplicaciones en las que la velocidad es muy importante (ejecutar grandes tiendas de comercio electrónico), el uso de Lectura no confirmada tiene más sentido.