Introducción
En este artículo, analizaremos cómo los diferentes tipos de índices en las tablas optimizadas para memoria de SQL Server afectan el rendimiento. Examinaremos ejemplos de cómo los diferentes tipos de índices pueden afectar el rendimiento de las tablas optimizadas para memoria.
Para facilitar la discusión del tema, haremos uso de un ejemplo bastante grande. Para simplificar, este ejemplo presentará diferentes réplicas de una sola tabla, contra las cuales ejecutaremos diferentes consultas. Estas réplicas utilizarán índices diferentes, o ningún índice (excepto, por supuesto, las claves primarias:PK).
Tenga en cuenta que el propósito real de este artículo no es comparar el rendimiento entre tablas basadas en disco y tablas optimizadas para memoria en SQL Server per se. Su propósito es examinar cómo los índices afectan el rendimiento en las tablas optimizadas para memoria. Sin embargo, para tener una imagen completa de los experimentos, también se proporcionan tiempos para las consultas de tablas basadas en disco correspondientes y las aceleraciones se calculan utilizando la configuración más óptima de tablas basadas en disco como referencia.
Escenario
Los datos de muestra para nuestro escenario se basan en una sola tabla definida de la siguiente manera:
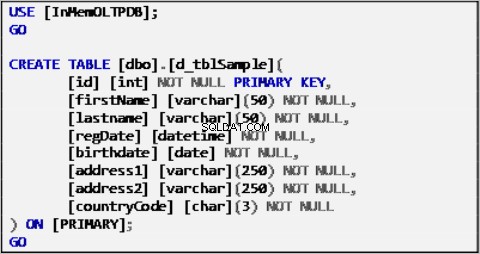
Listado 1:Tabla de fuente de datos de muestra.
La tabla anterior se completó con datos de muestra y actuará como fuente de datos para el resto de las tablas.
Entonces, según la tabla anterior, creamos las siguientes 9 variaciones de tabla y las completamos con los mismos datos de muestra:
- 3 tablas basadas en disco:
- d_tblMuestra1
- Índice agrupado en la columna "id":clave principal (PK)
- d_tblMuestra2
- Índice agrupado en la columna "id" (PK)
- Índice no agrupado en la columna "countryCode"
- d_tblMuestra3
- Índice agrupado en la columna "id" (PK)
- Índices no agrupados en la columna "regDate"
- Índices no agrupados en la columna "countryCode"
- d_tblMuestra1
- 3 tablas optimizadas para memoria (conjunto 1:índices hash):
- m1_tblMuestra1
- Índice hash no agrupado en la columna "id":clave principal (PK)
- m1_tblMuestra2
- Índice hash no agrupado en la columna "id" (PK)
- Índice hash en la columna "countryCode"
- m1_tblMuestra3
- Índice hash no agrupado en la columna "id" (PK)
- Índice hash en la columna "regDate"
- Índice hash en la columna "countryCode"
- 3 tablas optimizadas para memoria (conjunto 2:índices no agrupados):
- m2_tblMuestra1
- Índice no agrupado en la columna "id":clave principal (PK)
- m2_tblMuestra2
- Índice no agrupado en la columna "id" (PK)
- Índice no agrupado en la columna "countryCode"
- m2_tblMuestra3
- Índice no agrupado en la columna "id" (PK)
- Índice no agrupado en la columna "regDate"
- Índice no agrupado en la columna "countryCode"
- m2_tblMuestra1
- m1_tblMuestra1
En los listados a continuación, puede encontrar las definiciones de las tablas anteriores.
La lógica del escenario es que realizamos diferentes operaciones de base de datos contra variaciones de la misma tabla (pero con diferentes índices) y observamos cómo se ve afectado el rendimiento en cada caso.
Definiciones
Tablas basadas en disco
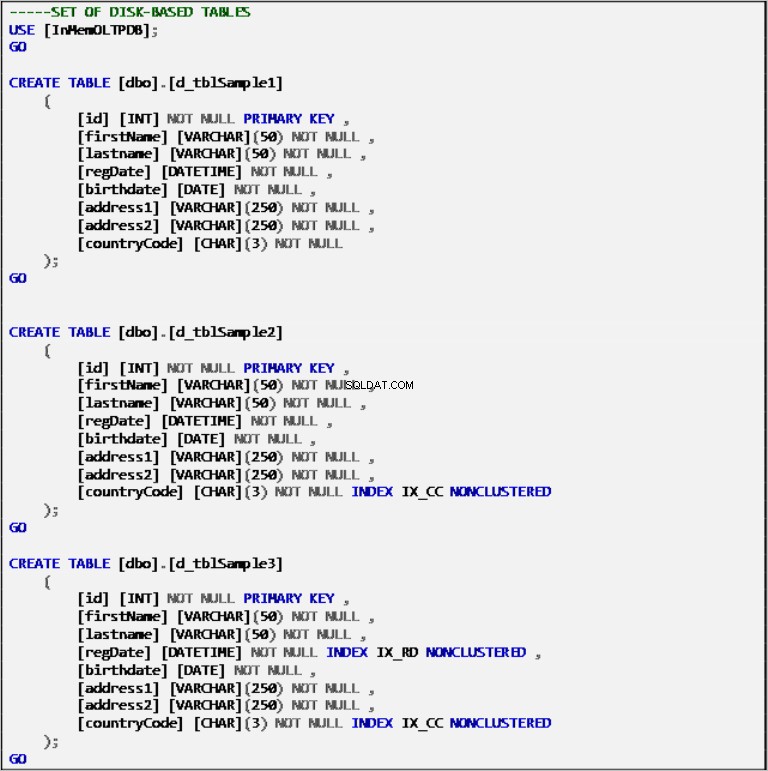
Listado 2:Definición de tablas basadas en disco.
Tablas optimizadas para memoria (Conjunto 1:índices hash)

Listado 3:Tablas optimizadas para memoria:conjunto 1 (índices hash).
Tablas optimizadas para memoria (Conjunto 2:índices no agrupados)

Listado 4:Tablas optimizadas para memoria:conjunto 2 (índices no agrupados).
Luego, completamos todas las tablas anteriores con los mismos datos de muestra, que son un total de 5 millones de registros en cada tabla.
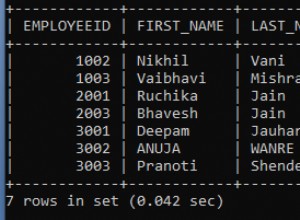
Aquí está el resultado del comando de conteo para cada conjunto de tablas:
Figura 1:Número total de registros para el primer conjunto de tablas.
Figura 2:Número total de registros para el segundo conjunto de tablas.
Figura 3:Número total de registros para el tercer conjunto de tablas.
Consultas y Ejecuciones de Escenarios
Ahora, ejecutaremos un conjunto de consultas en las tablas anteriores y veremos cómo funciona cada tabla.
Estas consultas realizan las siguientes operaciones:
- Consulta 1:Agregación (GRUPO POR)
- Consulta 2:búsqueda de índice en predicados de igualdad
- Consulta 3:Búsqueda de índice sobre predicados de igualdad y desigualdad
El plan es ejecutar las consultas como se indica a continuación:
Consulta 1 – Ejecución contra las siguientes tablas:
- d_tblMuestra3
- m1_tblMuestra3
- m2_tblMuestra3
- m1_tblSample1 (sin índice en las columnas de destino)
- m2_tblSample1 (sin índice en las columnas de destino)
Consulta 2 – Ejecución contra las siguientes tablas:
- d_tblMuestra2
- m1_tblMuestra2
- m2_tblMuestra2
- m1_tblSample1 (sin índice en las columnas de destino)
- m2_tblSample1 (sin índice en las columnas de destino)
Consulta 3 – Ejecución contra las siguientes tablas:
- d_tblMuestra3
- m1_tblMuestra3
- m2_tblMuestra3
- m1_tblSample1 (sin índice en las columnas de destino)
- m2_tblSample1 (sin índice en las columnas de destino)
Nota :Aunque la definición de d_tblSample1 La tabla basada en disco se incluye en las definiciones de tabla anteriores, no se usa en las consultas proporcionadas en este artículo. La razón es que, en cada escenario, se usa la configuración más óptima posible para la tabla basada en disco, ya que queremos que nuestra línea de base sea lo más rápida posible cuando la comparamos con el rendimiento de las tablas optimizadas para memoria. Para ello, el d_tblSample1 la tabla solo se presenta con fines informativos.
A continuación puede encontrar los scripts T-SQL para las tres consultas junto con los mecanismos de medición del tiempo de ejecución.

Listado 5:Consulta 1:Agregación (con índices).
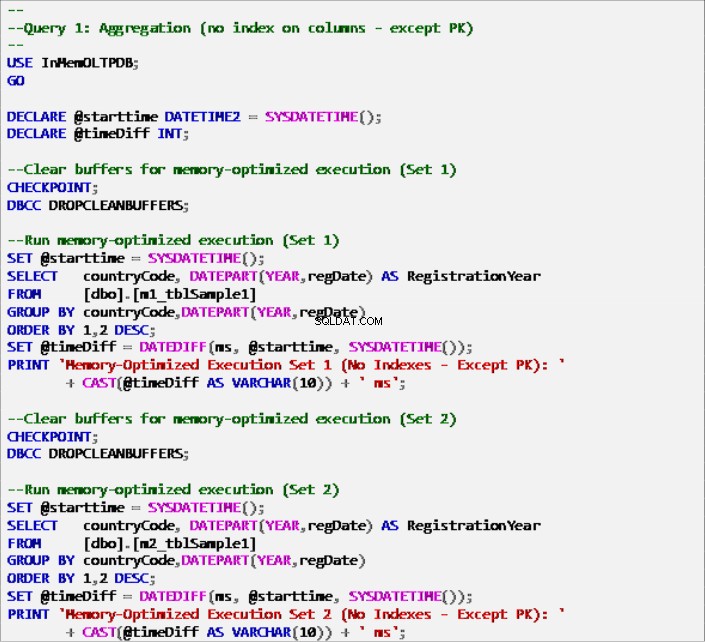
Listado 6:Consulta 1:agregación (sin índices, excepto clave principal).
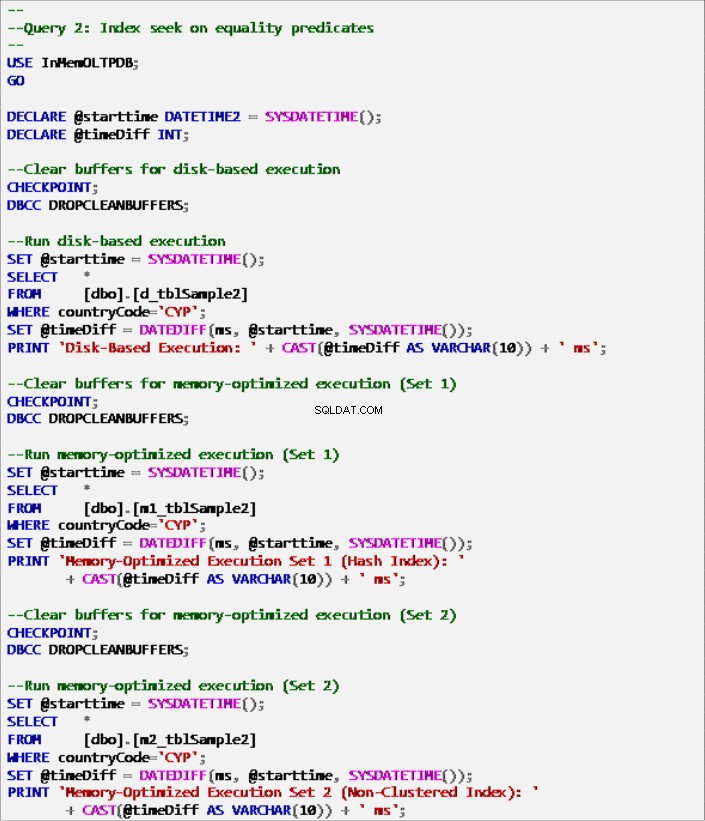
Listado 7:Consulta 2:búsqueda de índices sobre predicados de igualdad (con índices).

Listado 8:Consulta 2:búsqueda de índices sobre predicados de igualdad (sin índices, excepto clave principal).
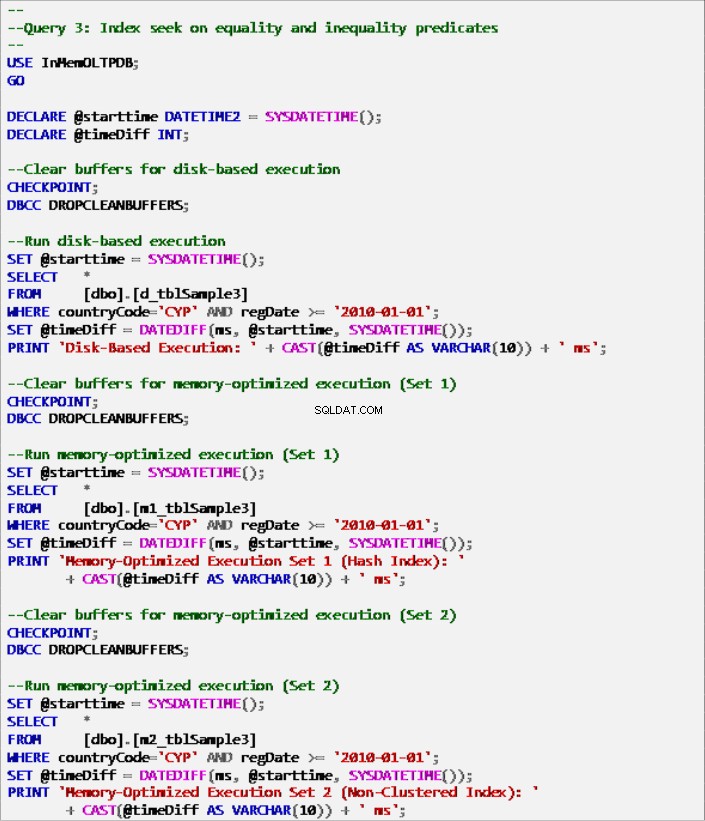
Listado 9:Consulta 3:búsqueda de índices sobre predicados de igualdad y desigualdad (con índices).

Listado 10:Consulta 3:búsqueda de índices sobre predicados de igualdad y desigualdad (sin índices, excepto clave principal).
Las capturas de pantalla a continuación muestran el resultado de cada ejecución de consulta:
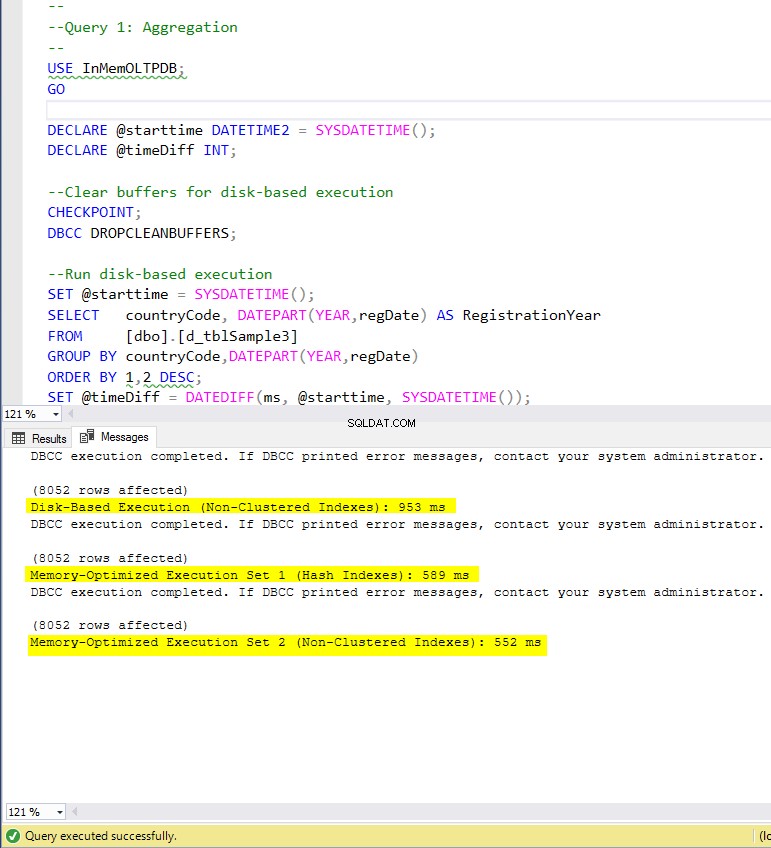
Figura 4:Tiempo de ejecución de la consulta 1 (con índices).
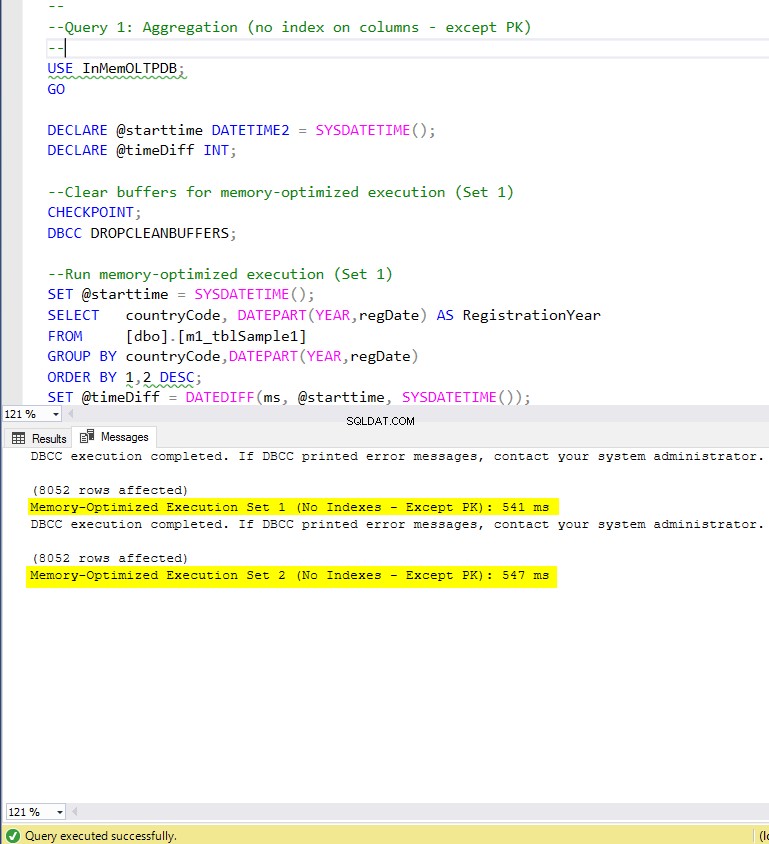
Figura 5:Tiempo de ejecución de la consulta 1 (sin índices, excepto PK).
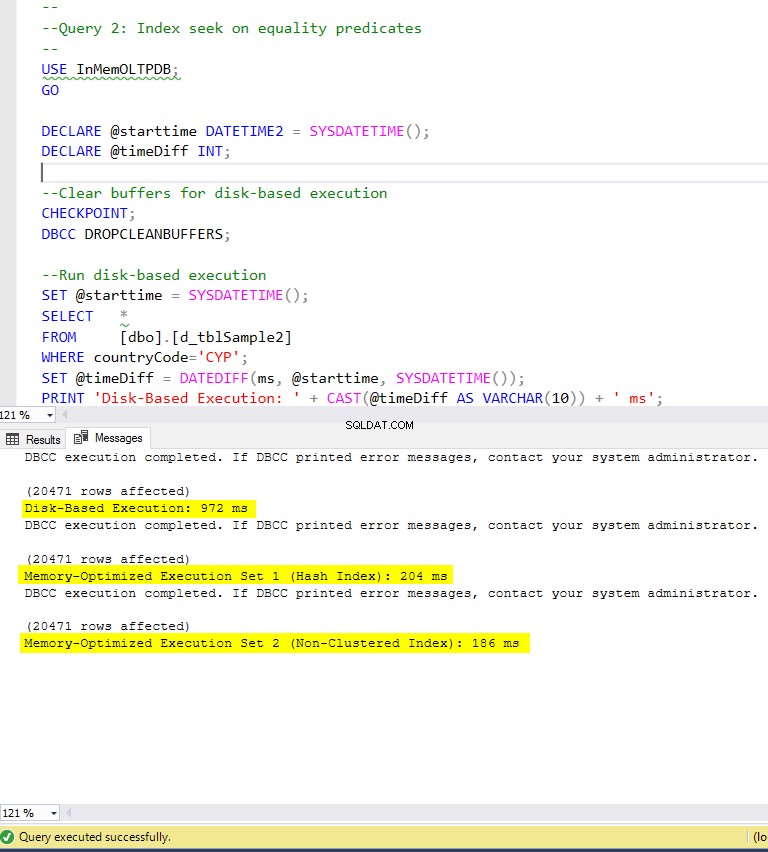
Figura 6:Tiempo de ejecución de la consulta 2 (con índices).
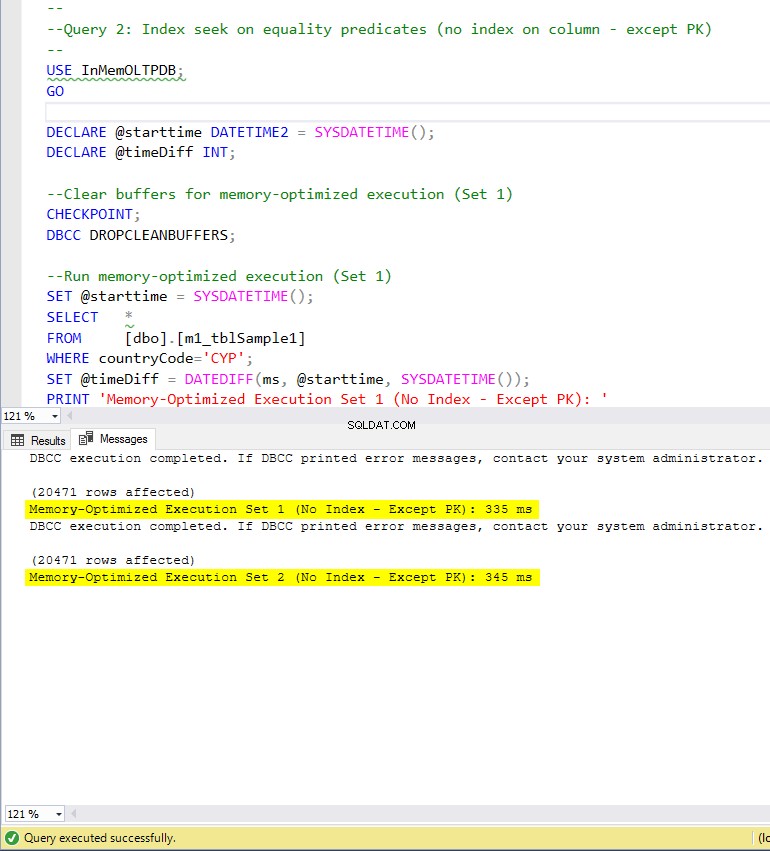
Figura 7:Tiempo de ejecución de la consulta 2 (sin índices, excepto PK).
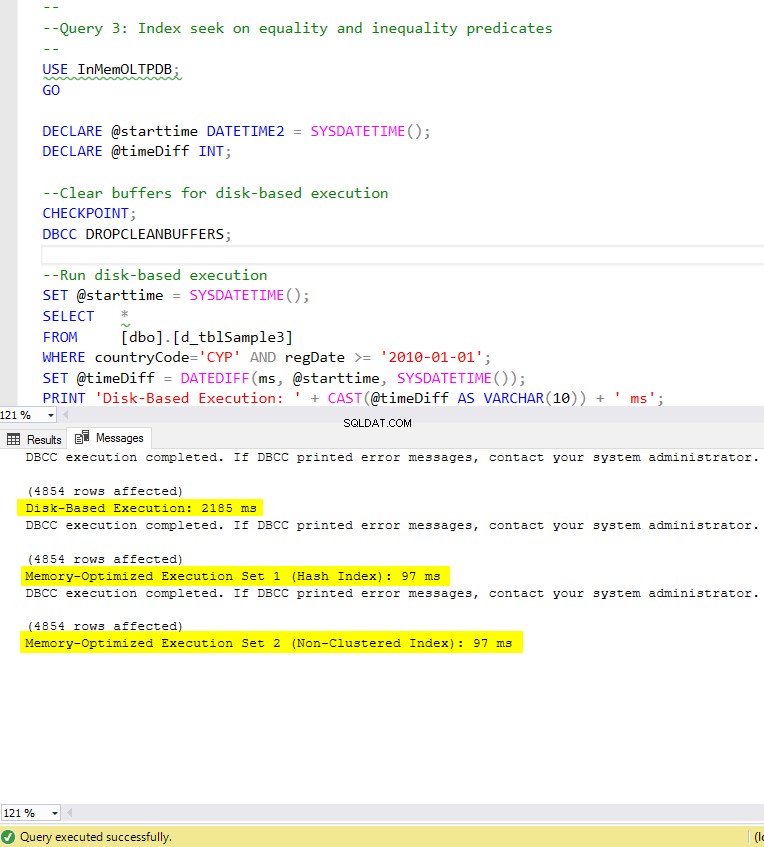
Figura 8:Tiempo de ejecución de la consulta 3 (con índices).
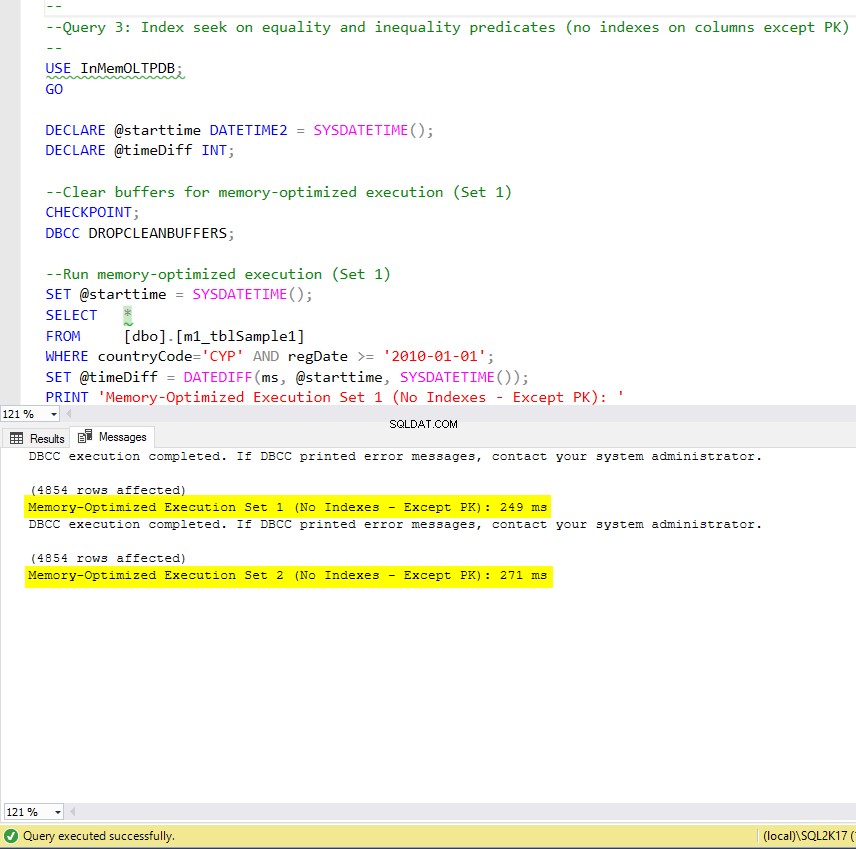
Figura 9:Tiempo de ejecución de la consulta 3 (sin índices, excepto PK).
Ahora, resumamos los resultados obtenidos anteriormente. La siguiente tabla muestra los tiempos de ejecución medidos para todas las consultas anteriores y combinaciones de tabla/índice.
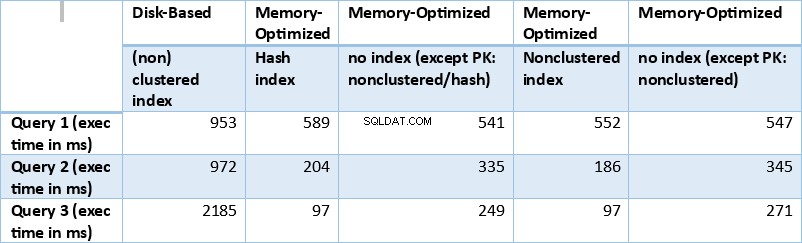
Tabla 1:Resumen de tiempos de ejecución (ms) para todas las consultas.
Discusión
Si examinamos los resultados de ejecución resumidos en la tabla anterior, podemos llegar a ciertas conclusiones. Tracemos cada resultado de la consulta en un gráfico. Los gráficos a continuación ilustran los tiempos de ejecución, así como la aceleración de las tablas optimizadas para memoria sobre las tablas basadas en disco.
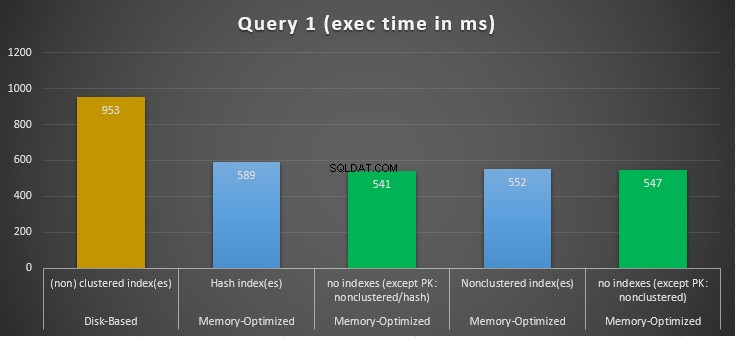
Figura 10:Comparación de los tiempos de ejecución de la consulta 1.
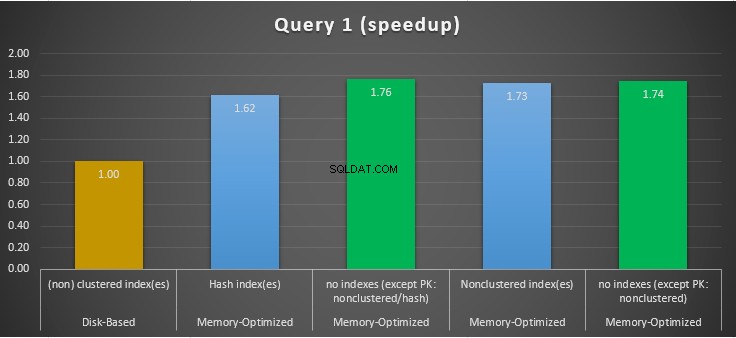
Figura 11:Comparación de aceleración de consulta 1.
Con respecto a la Consulta 1, que era una agregación GROUP BY, podemos ver que ambas versiones (índices frente a no índices) de las tablas optimizadas para memoria funcionan casi de la misma manera con una aceleración sobre la tabla basada en disco (habilitada con índices) entre
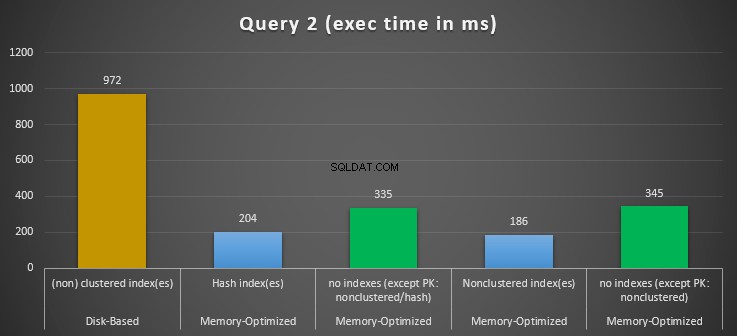
Figura 12:Comparación de los tiempos de ejecución de la consulta 2.
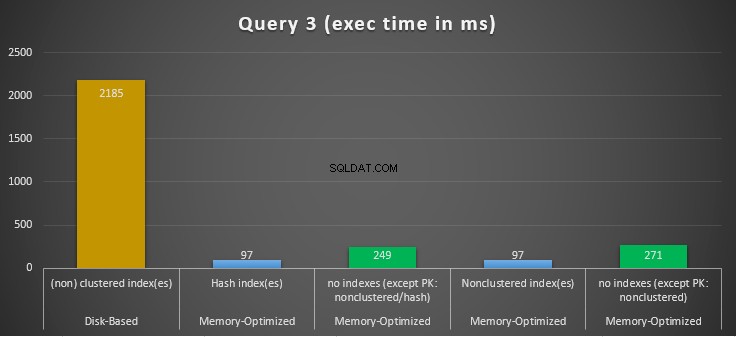
Figura 13:Comparación de aceleración de consulta 2.
Con respecto a la Consulta 2, que involucró una búsqueda de índice en predicados de igualdad, podemos ver que las tablas optimizadas para memoria con índices funcionaron mucho mejor que las tablas optimizadas para memoria sin índices. Además, observamos que la tabla optimizada para memoria con índice no agrupado en la columna utilizada como predicado funcionó mejor que la que tenía el índice hash.
Entonces, para la consulta 2, el ganador es la tabla optimizada para memoria con el índice no agrupado, que tiene una aceleración general de 5.23 veces más rápido que la ejecución basada en disco.
Figura 14:Comparación de los tiempos de ejecución de la consulta 3.
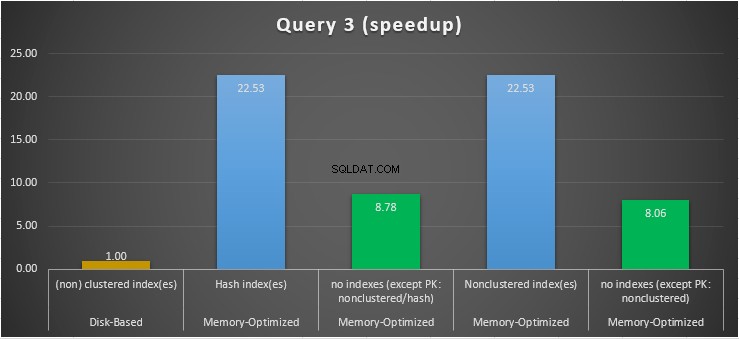
Figura 15:Comparación de aceleración de consulta 3.
Con respecto a la Consulta 3, que involucró una búsqueda de índice en predicados de igualdad y desigualdad combinados, podemos ver que las tablas optimizadas para memoria con índices se desempeñaron mucho mejor que las tablas optimizadas para memoria sin índices. Además, observamos que la tabla optimizada para memoria con índice no agrupado en la columna utilizada como predicado se desempeñó igual que la tabla con índice hash.
Con este fin, podemos ver que ambas tablas optimizadas para memoria que hacen uso de índices en las columnas utilizadas como predicados, se desempeñaron más rápido que las que no tienen índices y lograron una aceleración de 22,53 veces más rápido. sobre la ejecución basada en disco.
Conclusión
En este artículo, examinamos el uso de índices en tablas optimizadas para memoria en SQL Server. Usamos como línea de base para cada consulta, la mejor configuración de tabla basada en disco posible, y luego comparamos el rendimiento de tres consultas con las tablas basadas en disco y 4 variaciones de tablas optimizadas para memoria. Dos de las cuatro tablas optimizadas para memoria usaban índices (hash/no agrupados) y las otras dos no usaban índices, excepto los usados para las claves principales.
La conclusión general es que siempre debe examinar cómo los índices afectan el rendimiento, no solo para las tablas optimizadas para memoria sino también para las basadas en disco, y cada vez que identifique que mejoran el rendimiento, utilícelos. Los hallazgos de los ejemplos de este artículo muestran que si utiliza los índices adecuados en tablas optimizadas para memoria, puede lograr un rendimiento mucho mejor para consultas similares a las que se usan en este artículo en comparación con solo usar tablas optimizadas para memoria sin índices. .
Referencias y lecturas adicionales:
- Microsoft Docs:tablas optimizadas para memoria
- Microsoft Docs:Directrices para el uso de índices en tablas optimizadas para memoria
- Microsoft Docs:índices en tablas optimizadas para memoria
Herramienta útil:
dbForge Index Manager:práctico complemento de SSMS para analizar el estado de los índices SQL y solucionar problemas con la fragmentación de índices.