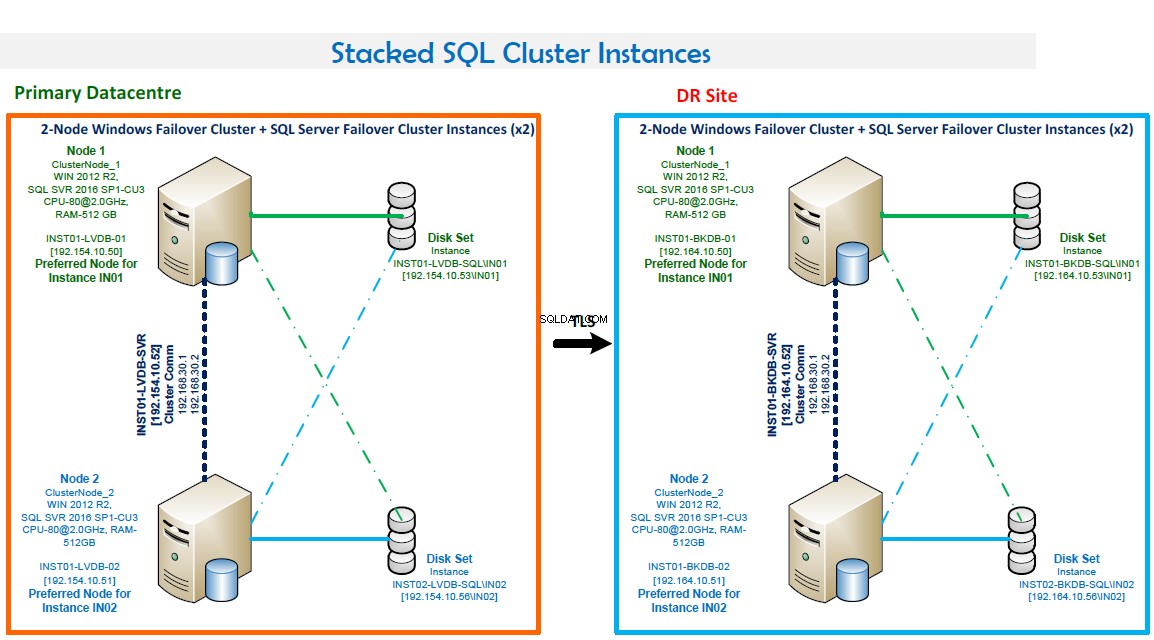
NOTAS:
- Clústeres de conmutación por error de Windows que consta de dos nodos.
- Dos instancias de clúster de conmutación por error de SQL Server. Esta configuración optimiza el hardware. Se prefiere IN01 en el Nodo1 y se prefiere IN02 en el Nodo2.
- Números de puerto:IN01 escucha en el puerto 1435 e IN02 escucha en el puerto 1436.
- Alta disponibilidad. Ambos nodos se respaldan mutuamente. La conmutación por error es automática en caso de falla.
- El modo de quórum es mayoría de nodos y discos.
- Copia de seguridad de LAN en el lugar y copia de seguridad de rutina configurada usando Veritas
Introducción
No es raro que los desarrolladores y administradores de proyectos exijan una nueva instancia de SQL Server para cada nueva aplicación o servicio. Si bien las tecnologías como la virtualización y la nube han facilitado la creación de nuevas instancias, algunas técnicas antiguas integradas con SQL Server permiten lograr tiempos de respuesta bajos cuando es necesario proporcionar una nueva base de datos para un nuevo servicio o aplicación. Este estado de cosas puede ser creado por un DBA que puede diseñar e implementar un gran clúster de SQL Server capaz de admitir la mayoría de las bases de datos de SQL Server requeridas por la organización. Hay ventajas añadidas a este tipo de consolidación, como costos de licencia más bajos, mejor gobierno y facilidad de administración. En el artículo, destacaremos algunas consideraciones que hemos tenido la oportunidad de experimentar al usar la agrupación en clústeres y el apilamiento como medio para consolidar las bases de datos de SQL Server.
Agrupación
Windows Server Failover Clustering es una solución de alta disponibilidad muy conocida que ha sobrevivido a muchas versiones de Windows Server y en la que Microsoft pretende seguir invirtiendo y mejorando. Las instancias de clúster de conmutación por error de SQL Server se basan en WSFC. Tanto la edición estándar como la empresarial de SQL Server admiten instancias de clúster de conmutación por error de SQL Server, pero la edición estándar está limitada a solo dos nodos. La consolidación de bases de datos en una sola FCI de SQL Server brinda beneficios tales como:
- HA por defecto — ¡Todas las bases de datos implementadas en una instancia de SQL Server en clúster tienen alta disponibilidad de forma predeterminada! Una vez que se crea una instancia en clúster, las nuevas implementaciones se gestionan en términos de alta disponibilidad con anticipación.
- Facilidad de administración – Menos DBA pueden dedicar tiempo a configurar, monitorear y, cuando sea necesario, solucionar problemas de UNA instancia en clúster que admita muchas aplicaciones. Correctamente, la documentación de la instancia también se hace mucho más fácil cuando se trata de un entorno grande. La configuración de una solución Enterprise Backup para manejar todas las bases de datos en su entorno es más fácil por el hecho de que tiene que hacer esta configuración solo una cuando usa instancias consolidadas.
- Cumplimiento – Requisitos clave como la aplicación de parches e incluso el endurecimiento se pueden realizar una vez con un tiempo de inactividad mínimo en una gran cantidad de bases de datos en un solo esfuerzo administrativo. En nuestra tienda, hemos utilizado el envío de registros de transacciones entre instancias agrupadas en dos centros de datos para garantizar que las bases de datos estén protegidas contra el riesgo de desastres.
- Estandarización – Hacer cumplir estándares tales como convenciones de nomenclatura, administración de acceso, autenticación de Windows, auditoría y administración basada en políticas es mucho más fácil cuando se trata de uno o dos entornos, según el tamaño de su tienda
Listado 1: Extraer información sobre su instancia
-- Extract Instance Details
-- Includes a Column to Check Whether Instance is Clustered
SELECT SERVERPROPERTY('MachineName') AS [MachineName]
, SERVERPROPERTY('ServerName') AS [ServerName]
, SERVERPROPERTY('InstanceName') AS [Instance]
, SERVERPROPERTY('IsClustered') AS [IsClustered]
, SERVERPROPERTY('ComputerNamePhysicalNetBIOS') AS [ComputerNamePhysicalNetBIOS]
, SERVERPROPERTY('Edition') AS [Edition]
, SERVERPROPERTY('ProductLevel') AS [ProductLevel]
, SERVERPROPERTY('ProductVersion') AS [ProductVersion]
, SERVERPROPERTY('ProcessID') AS [ProcessID]
, SERVERPROPERTY('Collation') AS [Collation]
, SERVERPROPERTY('IsFullTextInstalled') AS [IsFullTextInstalled]
, SERVERPROPERTY('IsIntegratedSecurityOnly') AS [IsIntegratedSecurityOnly]
, SERVERPROPERTY('IsHadrEnabled') AS [IsHadrEnabled]
, SERVERPROPERTY('HadrManagerStatus') AS [HadrManagerStatus]
, SERVERPROPERTY('IsXTPSupported') AS [IsXTPSupported];
Apilamiento
SQL Server admite hasta cincuenta instancias individuales en un servidor y hasta 25 instancias de clúster de conmutación por error en un clúster de conmutación por error de Windows Server. Se pueden apilar diferentes versiones de SQL Server en el mismo entorno para proporcionar un entorno sólido que admitirá diferentes aplicaciones. En tal configuración, la actualización de las bases de datos puede tomar la forma de simplemente promoverlas de una instancia de SQL Server a la siguiente versión en el mismo clúster hasta que el hardware envejezca. Una consideración clave a tener en cuenta al apilar SQL Server es que debe asignar memoria a cada instancia de tal manera que la cantidad total de memoria asignada no exceda la memoria disponible en el sistema operativo. El otro punto en esta dirección es asegurarse de que la cuenta de servicio de SQL Server para cada instancia debe tener las páginas de bloqueo en privilegios de memoria. La asignación de páginas bloqueadas en la memoria garantiza que cuando SQL Server adquiera memoria, el sistema operativo no intente recuperar dicha memoria cuando otros procesos del servidor la necesiten. La configuración de una cuenta de servicio de SQL Server definida, la configuración de MAX_SERVER_MEMORY y el privilegio de Bloquear páginas en memoria son un trío esencial cuando se apilan instancias de SQL Server.
Microsoft cobra unos miles de dólares por par de núcleos de CPU. El apilamiento de instancias de SQL Server le permite aprovechar este modelo de licencia al hacer que las instancias compartan el mismo conjunto de CPU (sudando el activo). Ya mencionamos que puede apilar diferentes versiones de SQL Server, cuidando así las aplicaciones heredadas que aún ejecutan versiones anteriores a SQL Server 2016, por ejemplo. Al usar diferentes ediciones de SQL Server, es posible que desee considerar usar Processor Affinity como lo describe Glen Berry en este artículo. La afinidad del procesador también se puede usar para controlar cómo se comparten los recursos de la CPU entre las instancias, al igual que controla la memoria. El apilamiento también aborda problemas de seguridad para aplicaciones que deben usar la cuenta SA, por ejemplo, o problemas de configuración para aplicaciones que requieren una instancia dedicada, o dichas opciones son una colación específica. La preocupación por el rendimiento de la TempDB compartida es otra razón por la que quizás desee apilar en lugar de agrupar todas las bases de datos en una instancia agrupada.
Vale la pena señalar que el valor de la agrupación, como se destacó anteriormente, se extiende aún más con el apilamiento. Por ejemplo, al parchear una instancia de SQL Server con varias FCI, todas las FCI se pueden parchear de una sola vez.
Puntos a tener en cuenta
Cuando se utiliza la agrupación en clústeres, ciertas convenciones harán que la administración y la gestión del entorno sean un poco más sencillas y mejorarán los activos. Nos referiremos a algunos de ellos brevemente:
- Herramientas de cliente actuales:es posible que reciba errores inusuales al intentar administrar una instancia de SQL Server 2016 con SQL Server Management Studio 2012. Los errores no le indican específicamente que el problema es la versión de la herramienta de cliente. Por lo general, tenemos una instancia de SQL Server Management Studio 17.3 en el cliente que deseamos usar para conectarnos a nuestras instancias.
- Convenciones de nomenclatura:una convención de nomenclatura le facilita estar seguro de en qué instancia está trabajando en cualquier momento. Al usar alias, puede reducir aún más la carga de recordar nombres largos de instancias para los usuarios finales que necesitan acceder a la base de datos.
- Nodo preferido:establecer un nodo preferido para cada función de SQL Server en el Administrador de clústeres de conmutación por error es una buena idea, una buena manera de asegurarse de que se utiliza la potencia de procesamiento de todos sus nodos de clúster. En nuestra tienda, después de configurar los nodos preferidos, configuramos el rol para que vuelva a funcionar entre las 05:00 HRS y las 06:00 HRS en caso de que haya una conmutación por error inadvertida.
- Envío de registros de transacciones:al configurar la recuperación ante desastres para FCI, tiene sentido identificar todas las rutas UNC mediante nombres virtuales, no los nombres o la dirección IP de los nodos del clúster. Esto garantiza que las cosas sigan funcionando correctamente si se produce una conmutación por error. También es muy importante asegurarse de que las cuentas del Agente SQL Server en ambos sitios tengan control total sobre estas rutas.
Listado 2: Configurar la supervisión para el envío de registros de transacciones mediante correo electrónico
-- Create Table to Store Log Shipping Data
create table msdb dbo log_shipping_report
(status bit,
is_primary bit,
server sysname,
database_name sysname,
time_since_last_backup int,
last_backup_file nvarchar (500),
backup_threshold int,
is_backup_alert_enabled bit,
time_since_last_copy int,
last_copied_file nvarchar 500),
time_since_last_restore int,
last_restored_file nvarchar(500),
last_restored_latency int,
restore_threshold int,
is_restore_alert_enabled bit);
go
-- Create an SQL Agent Job with the Following Script
-- This will send an Email at Intervals determined by the job Schedule
-- The Job Should be Created on the Log Shipping Secondary Clustered Instance
-- This Job Requires that Database Mail is Enabled
truncate table msdb dbo log_shipping_report
go
insert into msdb dbo log_shipping_report
EXEC sp_help_log_shipping_monitor;
go
/*
select [server]
, database_name [database]
, time_since_last_copy [Last Copy Time]
, last_copied_file [Last Copied File]
, time_since_last_restore [Last Restore Time]
, last_restored_file [Last Restored File]
, restore_threshold [Restore Threshold]
, restore_threshold - time_since_last_restore [Restore Latency]
from msdb.dbo.log_shipping_report;
go
*/
DECLARE @tableHTML NVARCHAR(MAX) ;
DECLARE @SecServer SYSNAME ;
SET @SecServer = @@SERVERNAME
SET @tableHTML =
N'<H1><font face="Verdana" size="4">Transaction Logshipping Status from Secondary
Server ' + @SecServer + N'</H1>' +
N'<p style="margin-top: 0; margin-bottom: 0"><font face="Verdana" size="2">Please
find below status of Secondary databases: </font></p> ' +
N'<table border="1" style="BORDER-COLLAPSE: collapse" borderColor="#111111"
cellPadding="0" width="2000" bgColor="#ffffff" borderColorLight="#000000"
border="1"><font face="Verdana" size="2">' +
N'<tr><th><font face="Verdana" size="2">Secondary Server</th>
<th><font face="Verdana" size="2">Secondary Database</th>
<th><font face="Verdana" size="2">Last Copy Time</th>' +
N'<th><font face="Verdana" size="2">Last Copied File</th><th>
<font face="Verdana" size="2">Last Restore Time</th>' +
N'<th><font face="Verdana" size="2">Last Restored File</th><th>
<font face="Verdana" size="2">Restore Threshold</th>
<th><font face="Verdana" size="2">Restore Latency</th>' +
CAST ( ( SELECT td = lsr.server, '',
td = lsr [database_name], td = lsr time_since_last_copy '',
td = lsr last_copied_file td = lsr time_since_last_restore '',
td = lsr last_restored_file, '',
td = lsr restore_threshold '',
td =
case
when lsr restore_threshold
lsr time_since_last_restore < 0 then + '<td bgcolor="#FFCC99"><b><font face="Verdana"
size="1">' + 'CRITICAL' + '</font></b></td>'
when lsr restore_threshold
lsr time_since_last_restore < 20 and lsr restore_threshold
lsr time_since_last_restore > 0 then + '<td bgcolor="#FFBB33"><b><font face="Verdana
size="1">' + 'WARNING' + '</font></b></td>'
when lsr restore_threshold
lsr time_since_last_restore > 20 then + '<td bgcolor="#21B63F"><b><font face="Verdana
size="1">' + 'OK' + '</font></b></td>'
end , ''
FROM msdb dbo log_shipping_report as lsr
ORDER BY lsr.[database_name]
FOR XML PATH('tr'), TYPE ) AS NVARCHAR(MAX) ) +
N'</table>' + ' ';
EXEC msdb dbo.sp_send_dbmail
@recipients='example@sqldat.com',
@copy_recipients='example@sqldat.com',
@subject = 'Transaction Log Shipping Report',
@body = @tableHTML,
@body_format = 'HTML' ;
Unidades de disco
Un efecto secundario de apilar instancias de SQL Server y hacer provisiones para varias bases de datos es la tendencia a quedarse sin letras de unidad. Eludimos este problema configurando puntos de montaje de volumen. Cada disco asignado a una función de clúster se configura como un punto de montaje con una letra de unidad que solo es necesaria para una o dos unidades por instancia. Un punto importante a tener en cuenta al usar puntos de montaje de volumen en un clúster es que en el futuro, cuando necesite agregar más puntos de montaje para realizar tareas de mantenimiento similares, será necesario colocar AMBOS, la unidad principal que posee la letra de la unidad y la unidad de montaje. punto en modo de mantenimiento en el clúster.
En nuestro caso, encontramos el nombre de cada punto de montaje de volumen según el rol de clúster al que estaba asignado. Con tantas unidades con las que lidiar, definitivamente necesitará encontrar una manera para que tanto usted como el administrador de almacenamiento identifiquen un disco único para que mantener los discos en el nivel de almacenamiento, por ejemplo, no sea una gran molestia.
Listado 3: Supervisar el uso del espacio en disco al usar puntos de montaje de volumen
-- The Following Script Will Show Disk Space Usage from Within SQL Server -- It is Especially Helpful When Using Volume Mount Points -- Volume Mount Point Space Usage Can Also Be Monitored from Computer Management (OS Level) SELECT DISTINCT vs volume_mount_point , vs file_system_type , vs logical_volume_name , CONVERT(DECIMAL!18 2 vs total_bytes 1073741824.0) AS [Total Size (GB)] , CONVERT(DECIMAL(18 2 vs available_bytes 1073741824.0' AS [Available Size (GB)] , CAST(CAST(vs available_bytes AS FLOAT)/ CAST(vs total_bytes AS FLOAT) AS DECIMAL (18,2)) * 100 AS [Space Free %] FROM sys.master_files AS f WITH (NOLOCK) CROSS APPLY sys.dm_os_volume_stats f database_id, f [file_id]i AS vs OPTION (RECOMPILE);
Despliegue de base de datos
En nuestro caso, nuestra estrategia fue asegurar que las nuevas bases de datos siguieran nuestro estándar. Las bases de datos más antiguas se manejaron con un poco más de cuidado ya que estábamos consolidando y actualizando al mismo tiempo. El Asistente de migración de bases de datos nos ayudó a decirnos qué bases de datos definitivamente no serían compatibles con nuestra sagrada instancia de SQL Server 2016 y las dejamos en paz (algunas con niveles de compatibilidad tan bajos como 100). Cada base de datos implementada debe tener sus propios volúmenes de datos y archivos de registro según su tamaño. El uso de volúmenes separados para cada base de datos es otro paso para tener un entorno muy bien organizado, lo cual es importante considerando la complejidad potencial de este entorno consolidado. La última declaración también implica que cuando permite que una aplicación cree sus propias bases de datos, debe, como DBA, reubicar los archivos de datos después de que se complete la implementación porque la aplicación usará las mismas ubicaciones de archivo que usa la base de datos modelo.
Listado 4: Reubicación de bases de datos de usuarios
-- 1. Set the database offline -- Be sure to replace DB_NAME with the actual database name ALTER DATABASE DB_NAME SET OFFLINE -- 2. Move the file or files to the new location. -- This means actually copying the datafiles at OS level -- You may also need grant the SQL Server Service account full permissions on the data file -- 3. For each file moved, run the following statement. ALTER DATABASE DB_NAME MODIFY FILE ( NAME = logical_name FILENAME = 'new_path\os_file_name') -- 4. Bring the database back online ALTER DATABASE database name SET ONLINE -- 5. Verify the file change: SELECT name, physical_name AS CurrentLocation, state_desc FROM sys.master_files WHERE database_id = DB_ID(N'DB_NAME');
Gestión de acceso
Estará de acuerdo en que, en nuestro entorno consolidado, podríamos terminar teniendo una lista muy larga de objetos de nivel de servidor, como inicios de sesión. El uso de grupos de Windows ayudará a acortar esta lista y simplificar la administración de acceso en cada instancia en clúster. Por lo general, necesitará grupos creados en Active Directory para administradores de aplicaciones que necesitan acceso, cuentas de servicio de aplicaciones, usuarios comerciales que necesitan obtener informes y, por supuesto, administradores de bases de datos. Un beneficio clave de usar Grupos de Windows es que el acceso se puede otorgar o revocar simplemente administrando la membresía de estos grupos directamente en Active Directory.
Probablemente ahora sea obvio que este beneficio en el área de administración de acceso solo es posible con la autenticación de Windows. Los inicios de sesión de SQL Server no se pueden administrar en grupos.
Listado 5: Inicios de sesión de instancias, usuarios de bases de datos y sus funciones
create table #userlist (
[Server Name] varchar(20)
,[Database Name] varchar(50)
,[Database User] varchar(50)
, [Database Role] varchar(50)
, [Instance Login] varchar(50)
, [Status] varchar(15)
)
go
insert into #userlist
exec sp_MSforeachdb @command1 ='
USE [?]
IF ''?'' NOT IN ("tempdb","model"J"msdb"J"master")
BEGIN
select @@servername as instance_name , ''?'' as database_name , rp.name as database_user , mp.name as database_role , sp.name as instance_login , case
when sp.is_disabled = 1 then ''Disabled'' when sp.is_disabled = 0 then ''Enabled'' end
[login_status]
from sys.database_principals rp
left outer join sys.database_role_members drm on (drm.member_principal_id = rp.principal_id)
left outer join sys.database_principals mp on (drm.role_principal_id = mp.principal_id)
left outer join sys.server_principals sp on (rp.sid=sp.sid)
where rp.type_desc in (''WINDOWS_GROUP'',''WINDOWS_USER'',''SQL_USER'')
END' go
select * from #userlist go
drop table #userlist
Conclusión
Hemos examinado a un nivel muy alto los beneficios que se pueden obtener al agrupar y apilar instancias de SQL Server como un medio para lograr la consolidación, la optimización de costos y la facilidad de administración. Si se encuentra capaz de comprar hardware grande, puede explorar esta opción y obtener los beneficios que hemos descrito anteriormente.



