Una descripción general de la recuperación tradicional
Al igual que con todos los sistemas de bases de datos relacionales, SQL Server garantiza la durabilidad de los datos mediante la implementación de la recuperación de fallas. Durabilidad en el acrónimo ACID que hace referencia a las características de las transacciones en bases de datos relacionales significa que podemos estar seguros de que si la base de datos falla repentinamente, nuestros datos están seguros.
SQL Server implementa esta capacidad mediante el registro de transacciones. Los cambios realizados por todas las operaciones de manipulación de datos en SQL Server se capturan en el registro de transacciones antes de aplicarse a los archivos de datos (a través del proceso de punto de control) en caso de que sea necesario retroceder o avanzar.
El proceso de recuperación de bloqueo de tres fases en SQL Server es el siguiente:
Análisis – SQL Server lee el registro de transacciones desde el último punto de control hasta el final del registro de transacciones
Rehacer – SQL Server reproduce el registro desde la transacción no confirmada más antigua hasta el final del registro
Deshacer – SQL Server lee el registro desde el final del registro hasta la transacción no confirmada más antigua y revierte todas las transacciones que estaban activas durante el bloqueo
Los administradores de bases de datos experimentados habrían tenido en algún momento u otro de sus carreras la desalentadora experiencia de esperar impotentes a que se completara la recuperación de fallas en una base de datos muy grande. La transacción ROLLBACK utiliza un mecanismo similar al proceso de recuperación de bloqueo. Microsoft ha mejorado significativamente el proceso de recuperación en SQL Server 2019.
Recuperación acelerada de bases de datos
La recuperación acelerada de la base de datos es una nueva función basada en el control de versiones que aumenta significativamente la tasa de recuperación en el caso de un ROLLBACK o recuperación de un bloqueo.
En SQL Server 2019, tres nuevos mecanismos dentro del motor de SQL Server modifican la forma en que se maneja la recuperación y reducen efectivamente el tiempo requerido para realizar una reversión/retroceso.
Almacén de versiones persistentes (PVS) – Captura versiones de fila dentro de la base de datos en cuestión. El Almacén de versiones persistentes se puede definir en un grupo de archivos separado por motivos de rendimiento o tamaño
Reversión lógica – Utiliza las versiones de fila almacenadas en PVS para realizar una reversión cuando se invoca una reversión para una transacción en particular o cuando se invoca la fase de deshacer de la recuperación de bloqueo.
sLog – Esto posiblemente significa secundario registro . Es un flujo de registro en memoria que se utiliza para capturar operaciones que no se pueden versionar. Cuando ADR está habilitado en la base de datos, el sLog siempre se reconstruye durante la fase de análisis de la recuperación de fallas. Durante el rehacer fase, se utiliza el sLog en lugar del registro de transacciones real, lo que hace que el proceso sea más rápido, ya que se encuentra en la memoria y contiene menos transacciones. El proceso de recuperación tradicional maneja las transacciones desde el último punto de control. El sLog también se usa durante deshacer fase.
Limpiador – Elimina versiones de filas innecesarias del PVS. Microsoft también proporciona un procedimiento almacenado para forzar manualmente una limpieza de versiones de filas innecesarias.
-- LISTING 1: INVOKE THE BACKGROUND CLEANER USE TSQLV4_ADR GO EXECUTE sys.sp_persistent_version_cleanup; USE master GO EXECUTE master.sys.sp_persistent_version_cleanup 'TSQLV4_ADR';
La recuperación acelerada de la base de datos está DESACTIVADA de forma predeterminada
El hecho de que ADR esté desactivado en SQL Server 2019 de forma predeterminada puede parecer sorprendente para algunos DBA dado que parece ser una característica excelente. ADR utiliza el control de versiones en la base de datos de usuarios en la que está habilitado. Esto puede afectar significativamente el tamaño de la base de datos. Además, es posible que deba planificar el crecimiento de la base de datos, así como la posible ubicación del PVS para garantizar un buen rendimiento si ADR está habilitado. Por lo tanto, tiene sentido habilitar deliberadamente esta funcionalidad.
El Experimento:Fase Preparatoria
Configuramos un experimento para explorar la nueva función y ver el impacto de ADR en el tamaño del registro de transacciones, así como en la velocidad de ROLLBACK. En nuestro experimento, creamos dos bases de datos idénticas utilizando un solo conjunto de respaldo y luego habilitamos ADR solo en una de estas bases de datos. El Listado 2 muestra las etapas preparatorias para la tarea.
[expandir título =”Código”]
-- LISTING 2: PREPARE THE DATABASES AND CONFIGURE ADR
-- 2a. Backup a sample database and restore as two identical databases
BACKUP DATABASE TSQLV4 TO DISK='TSQLV4.BAK' WITH COMPRESSION;
-- Restore Database TSQLV4_NOADR (ADR will not be enabled)
RESTORE DATABASE TSQLV4_NOADR FROM DISK='TSQLV4.BAK' WITH
MOVE 'TSQLV4' TO 'C:\MSSQL\DATA\TSQLV4_NOADR.MDF',
MOVE 'TSQLV4_log' TO 'E:\MSSQL\LOG\TSQLV4_NOADR_LOG.LDF';
-- Restore Database TSQLV4_ADR (ADR will be enabled)
RESTORE DATABASE TSQLV4_ADR FROM DISK='TSQLV4.BAK' WITH
MOVE 'TSQLV4' TO 'C:\MSSQL\DATA\TSQLV4_ADR.MDF',
MOVE 'TSQLV4_log' TO 'E:\MSSQL\LOG\TSQLV4_ADR_LOG.LDF';
-- 2b. Enable ADR in TSQLV4_ADR
USE [master]
GO
-- First create a separate filegroup and add a file to the filegroup
ALTER DATABASE [TSQLV4_ADR] ADD FILEGROUP [ADR_FG];
ALTER DATABASE [TSQLV4_ADR] ADD FILE ( NAME = N'TSQLV4_ADR01', FILENAME = N'C:\MSSQL\Data\TSQLV4_ADR01.ndf' ,
SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [ADR_FG]
GO
-- Enable ADR
ALTER DATABASE TSQLV4_ADR SET ACCELERATED_DATABASE_RECOVERY = ON (PERSISTENT_VERSION_STORE_FILEGROUP = ADR_FG);
GO
-- 2c. Check if all ADR is enabled as planned
SELECT name
, compatibility_level
, snapshot_isolation_state_desc
, recovery_model_desc
, target_recovery_time_in_seconds
, is_accelerated_database_recovery_on FROM SYS.DATABASES
WHERE name LIKE 'TSQLV4_%';
-- 2d. Check sizes of all files in the databases
SELECT DB_NAME(database_id) AS database_name
, name AS file_name
, physical_name
, (size * 8)/1024 AS [size (MB)]
, type_desc
FROM SYS.master_files
WHERE DB_NAME(database_id) LIKE 'TSQLV4_%';
-- 2e. Check size of log used
CREATE TABLE ##LogSpaceUsage (database_name VARCHAR(50)
, database_id INT, total_log_size_in_bytes BIGINT
, used_log_space_in_bytes BIGINT
, used_log_space_in_percent BIGINT
, log_space_in_bytes_since_last_backup BIGINT)
INSERT INTO ##LogSpaceUsage
EXEC sp_MSforeachdb @command1='
IF ''?'' LIKE ("TSQLV4_%")
SELECT DB_NAME(database_id), * FROM ?.SYS.dm_db_log_space_usage;'
SELECT * FROM ##LogSpaceUsage;
DROP TABLE ##LogSpaceUsage; [/expandir]
La Fig. 1 muestra el resultado de la instrucción SQL del Listado 2, sección 2c. También capturamos el tamaño de los archivos de la base de datos y el uso del archivo de registro de transacciones. (ver Fig. 3).
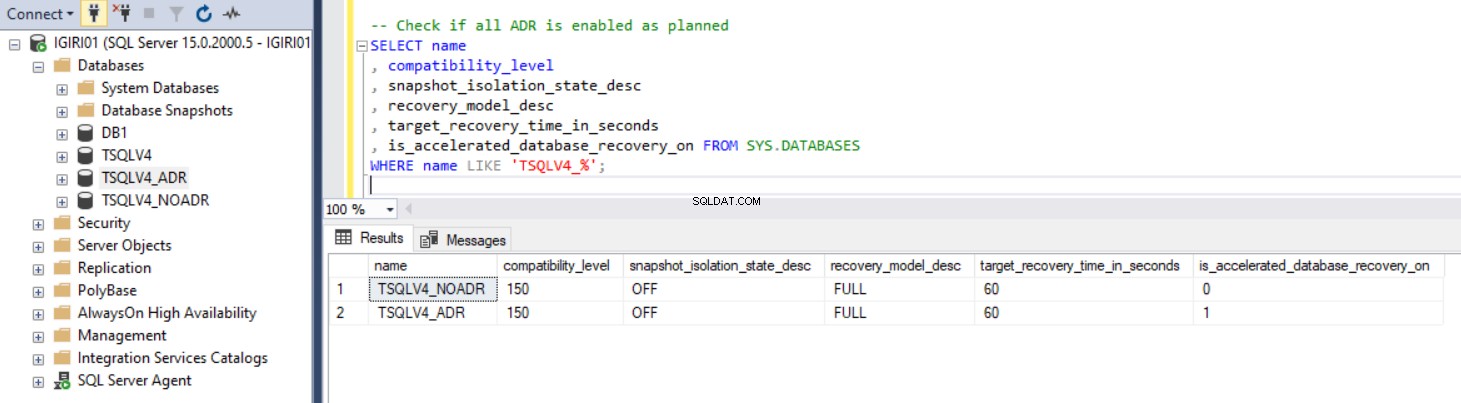
fig. 1 Confirme que ADR está configurado
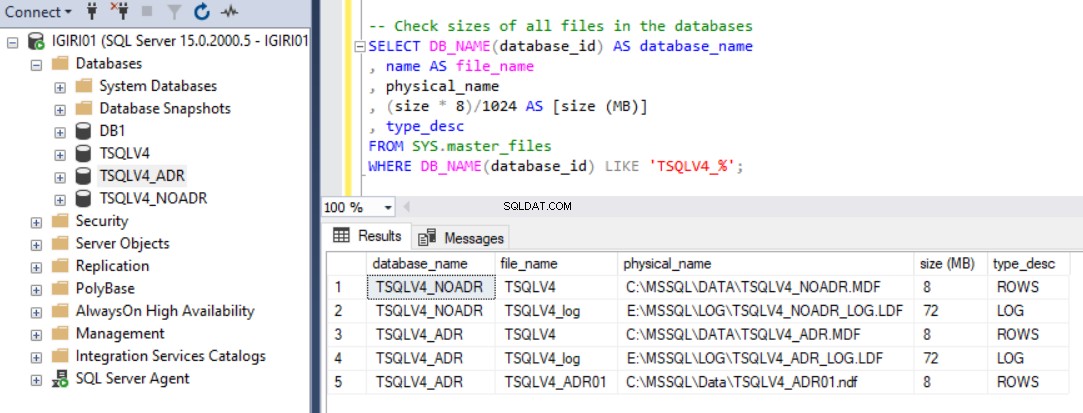
fig. 2 Revisar los tamaños de los archivos de datos de la base de datos
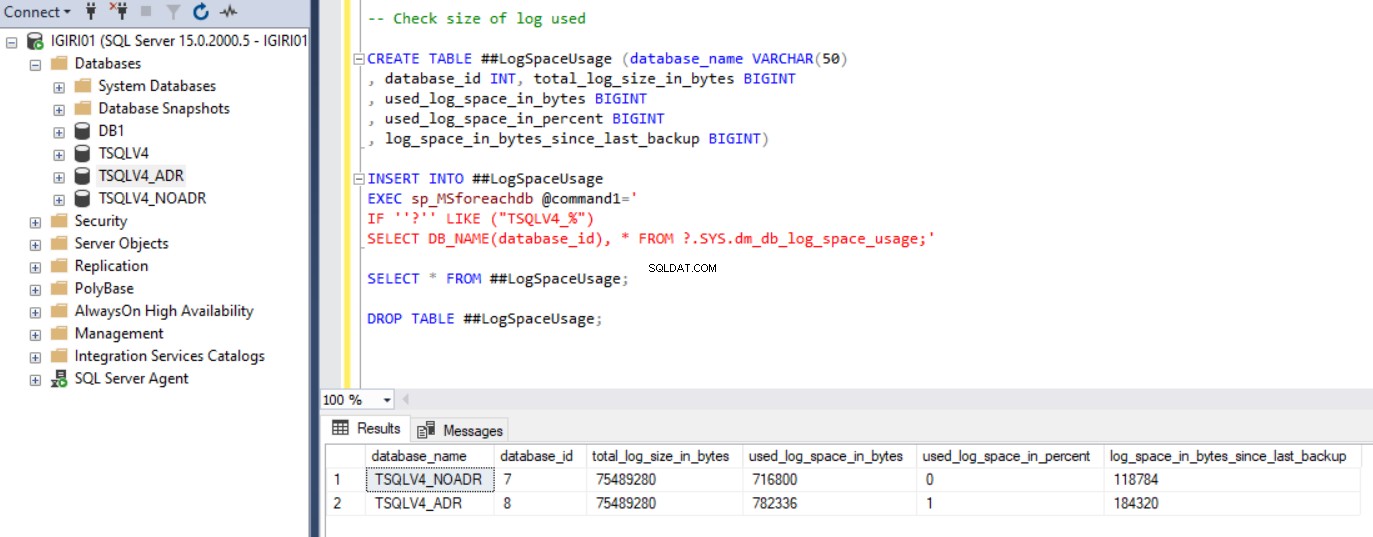
fig. 3 Comprobar el tamaño del registro utilizado para ambas bases de datos
El Experimento:Fase de Ejecución
Una vez que hemos capturado los detalles que necesitamos para continuar, ejecutamos el código SQL de los Listados 3 y 4 en etapas. Los dos listados son equivalentes, pero los estamos ejecutando en dos bases de datos idénticas por separado. Primero, hacemos una INSERCIÓN (Listado 3, 3a), luego realizamos una ELIMINACIÓN (Listado 3, 3b) que posteriormente revertiremos. Tenga en cuenta que tanto en INSERT como en DELETE, hemos encapsulado las operaciones en transacciones. Además, tenga en cuenta que INSERT se ejecuta 50 veces. En cada etapa de ejecución, es decir, entre 3a, 3b y 3c, capturamos el uso del registro de transacciones con la ayuda del código del Listado 2,2e. Esto es lo mismo para las secciones 4a, 4b y 4c.
-- LISTING 3: EXECUTE DML IN TSQLV4_NOADR DATABASE -- 3a. Execute INSERT Statement in TSQLV4_NOADR Database USE TSQLV4_NOADR GO BEGIN TRAN SET STATISTICS IO ON; SET STATISTICS TIME ON; SELECT * INTO [Sales].[OrderDetails_noadr] FROM [Sales].[OrderDetails]; GO INSERT INTO [Sales].[OrderDetails_noadr] SELECT * FROM [Sales].[OrderDetails]; GO 50 COMMIT; -- 3b. Execute DELETE in TSQLV4_NOADR Database USE TSQLV4_NOADR GO BEGIN TRAN SET STATISTICS IO ON; SET STATISTICS TIME ON; DELETE FROM [Sales].[OrderDetails_noadr] GO -- 3c. Perform Rollback and Capture Time ROLLBACK;
Fig. 4 y 5 nos muestran que la operación SELECT INTO tomó 6 milisegundos más en la base de datos TSQLV4_ADR donde habilitamos la recuperación acelerada de la base de datos. También vemos en la Fig. 6 que tenemos un mayor uso del registro de transacciones en la base de datos TSQLV4_ADR. Esto me sorprendió especialmente, así que repetí el experimento varias veces para asegurarme de que obtenía este resultado de forma constante.
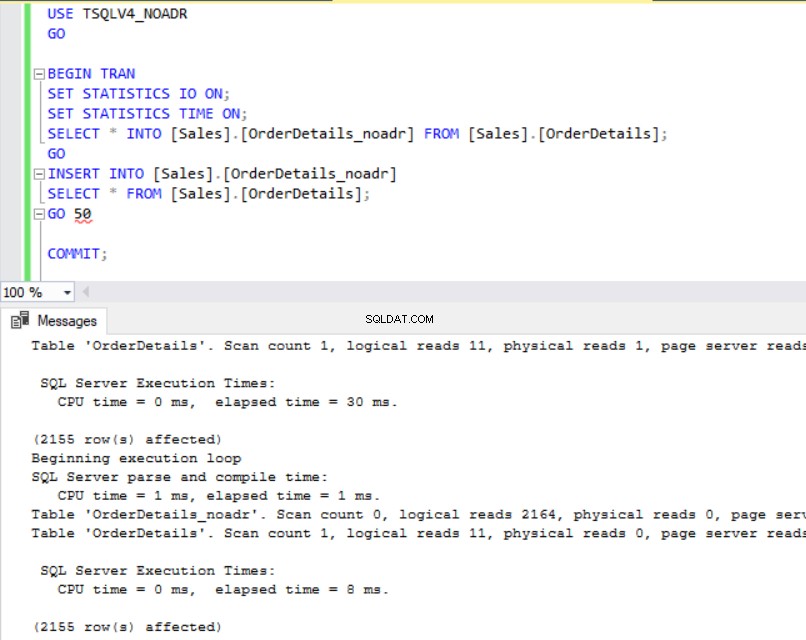
fig. 4 Insertar tiempo de ejecución para TSQLV4_NOADR
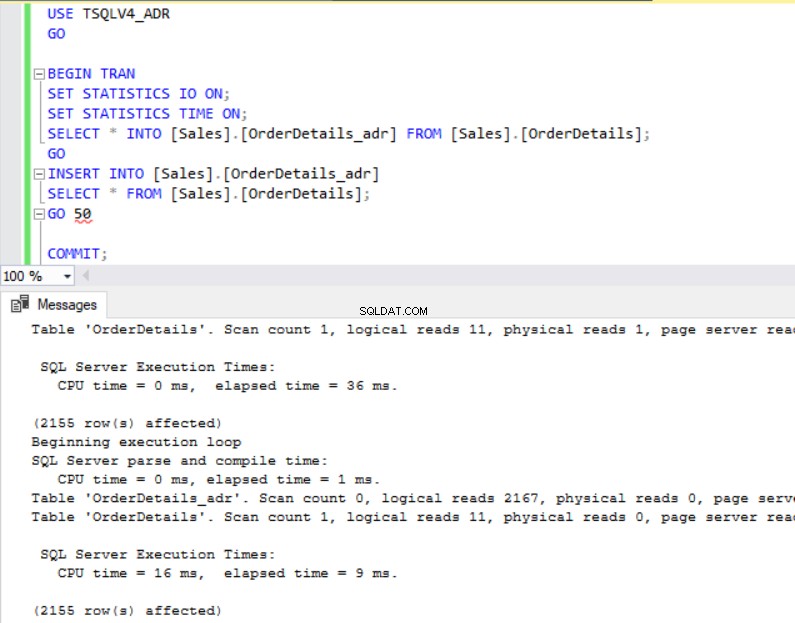
fig. 5 Insertar tiempo de ejecución para TSQLV4_ADR
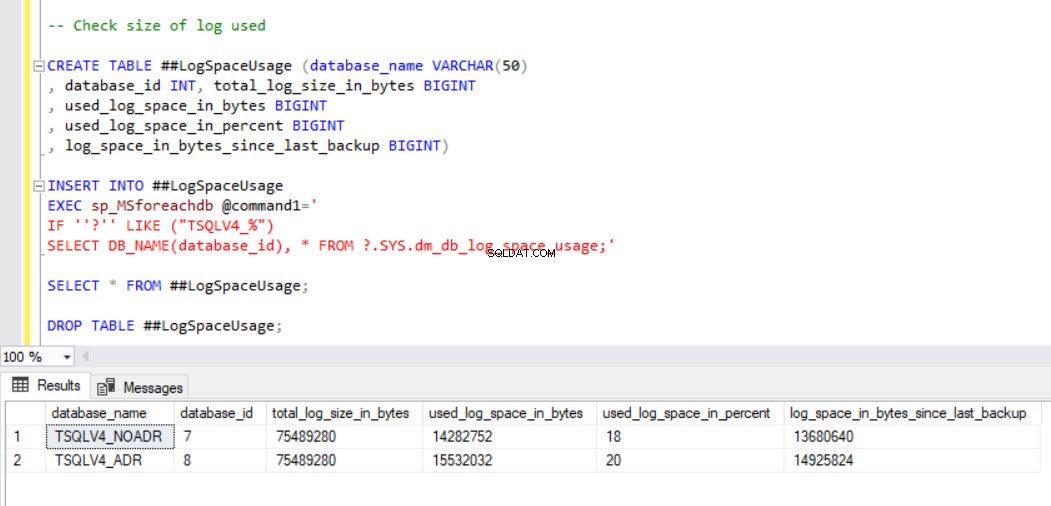
fig. 6 Uso del registro de transacciones después de las inserciones
-- LISTING 4: EXECUTE DML IN TSQLV4_ADR DATABASE -- 4a. Execute INSERT Statement in TSQLV4_ADR Database USE TSQLV4_ADR GO BEGIN TRAN SET STATISTICS IO ON; SET STATISTICS TIME ON; SELECT * INTO [Sales].[OrderDetails_adr] FROM [Sales].[OrderDetails]; GO INSERT INTO [Sales].[OrderDetails_adr] SELECT * FROM [Sales].[OrderDetails]; GO 50 COMMIT; -- 4b. Execute DELETE in TSQLV4_ADR Database USE TSQLV4_ADR GO BEGIN TRAN SET STATISTICS IO ON; SET STATISTICS TIME ON; DELETE FROM [Sales].[OrderDetails_adr] GO -- 4c. Perform Rollback and Capture Time ROLLBACK;
Fig. 7 y 8 nos muestran que la operación DELETE tardó considerablemente más en completarse en la base de datos TSQLV4_ADR donde habilitamos la Recuperación acelerada de la base de datos aunque se eliminó la misma cantidad de filas en ambas bases de datos. Esta vez, sin embargo, tenemos un mayor uso del registro de transacciones en la base de datos TSQLV4_NOADR.
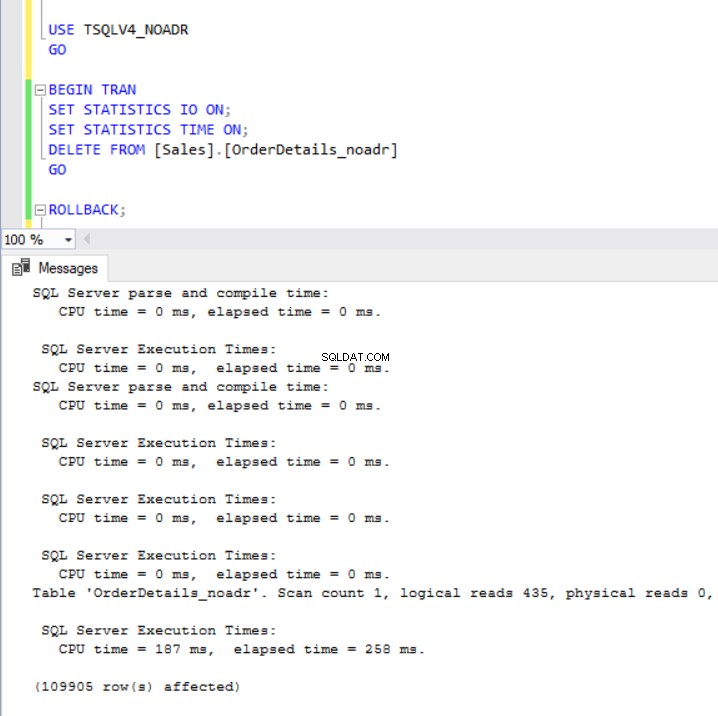
fig. 7 Eliminar tiempo de ejecución para TSQLV4_NOADR
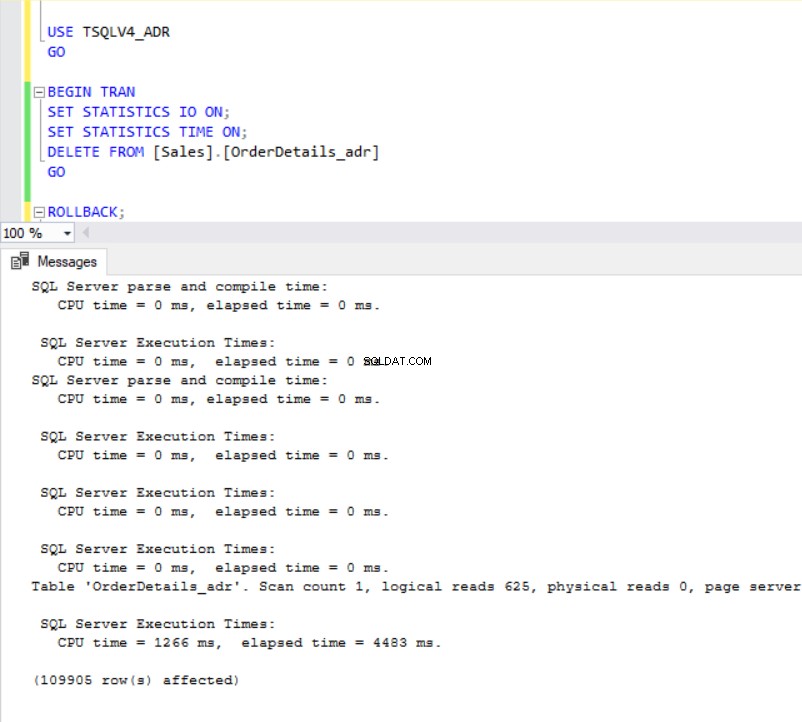
fig. 8 Eliminar tiempo de ejecución para TSQLV4_ADR
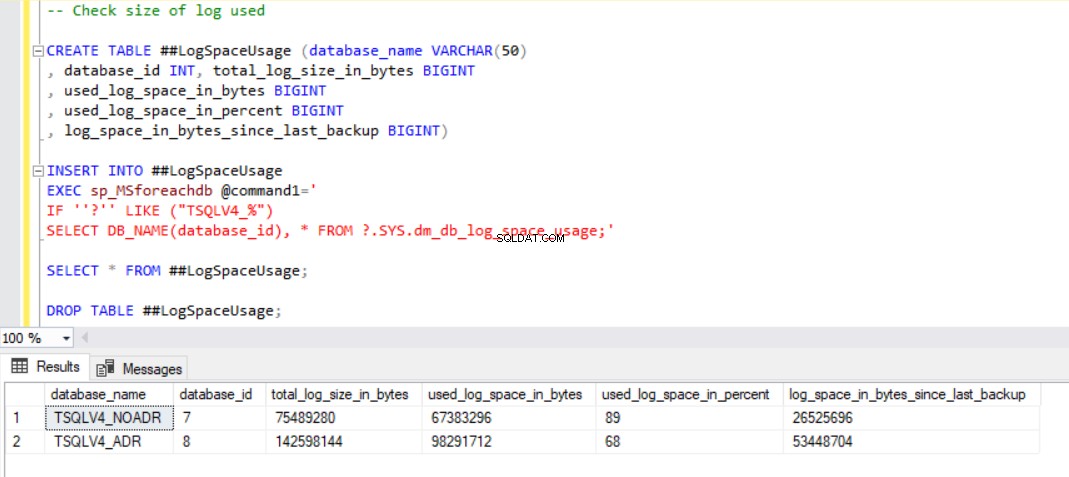
fig. 9 Uso del registro de transacciones después de las eliminaciones
A estas alturas, se estaba volviendo obvio que las operaciones DML tardan más en las bases de datos con ADR habilitado. Esto explica en parte por qué la función está desactivada en primer lugar. Pensándolo profundamente, tiene sentido ya que SQL Server debe almacenar las versiones de fila en el PVS mientras se ejecuta una operación de inserción, actualización o eliminación. Independientemente de la cantidad de tiempo que tome el DML, encontramos que emitir un ROLLBACK con ADR activado toma menos de 1 milisegundo (ver Figs. 10 - 13). En algunos casos, la reversión rápida puede compensar la sobrecarga del propio DML, ¡pero no en todos los casos!
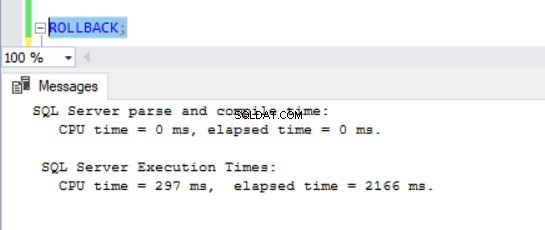
fig. 10 Tiempo de ejecución para ROLLBACK (después de DELETE) en TSQLV4_NOADR
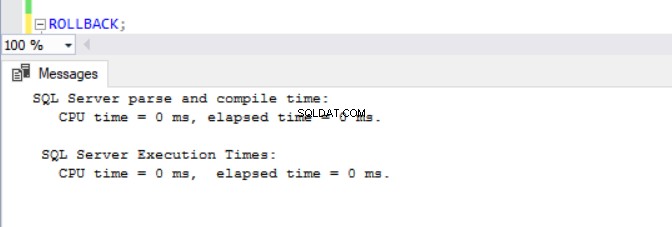
fig. 11 Tiempo de ejecución para ROLLBACK (después de DELETE) en TSQLV4_ADR
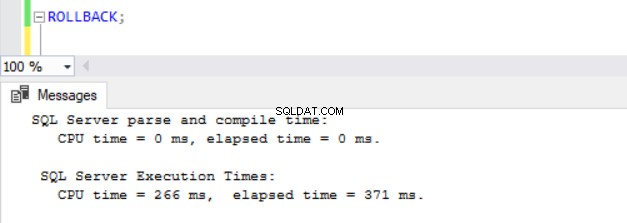
fig. 12 Tiempo de ejecución para ROLLBACK (después de INSERT) en TSQLV4_NOADR
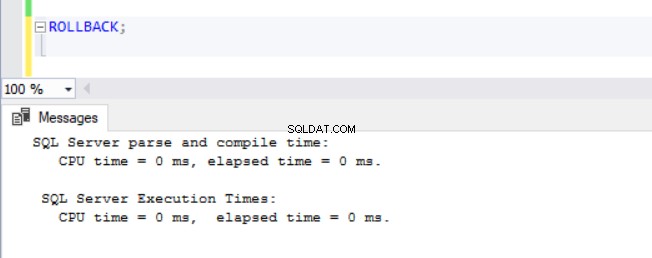
fig. 13 Tiempo de ejecución para ROLLBACK (después de DELETE) en TSQLV4_ADR
Conclusión
La recuperación acelerada de la base de datos es una de las excelentes características lanzadas en SQL Server 2019. Sin embargo, como sucede con todas las cosas extremadamente agradables de la vida, alguien tiene que pagar por ella. ADR puede tener un impacto negativo en el rendimiento en ciertos escenarios, por lo que es importante evaluar su escenario cuidadosamente antes de implementar ADR en su base de datos de producción. Microsoft recomienda específicamente la recuperación acelerada de bases de datos para bases de datos que admitan cargas de trabajo con transacciones de ejecución muy prolongada, crecimiento excesivo del registro de transacciones o interrupciones frecuentes relacionadas con una recuperación de ejecución prolongada.
Referencias
Recuperación acelerada de bases de datos
¿Cómo funciona la recuperación acelerada de bases de datos?
Recuperación acelerada de bases de datos