¿Qué es la optimización de consultas en SQL Server? Es un gran tema. Cada técnica o problema necesita un artículo separado para cubrir las bases. Pero cuando recién comienza a subir de nivel su juego con consultas, necesita algo más simple en lo que confiar. Este es el objetivo de este artículo.
Podría decir que sus consultas son óptimas, todo funciona bien y los usuarios están contentos. Por supuesto, el rendimiento no lo es todo. Los resultados también deben ser correctos. Ya sea una combinación, una subconsulta, un sinónimo, un CTE, una vista o lo que sea, debe funcionar de manera aceptable.
Y al final del día, puede irse a casa con sus usuarios. No querrás quedarte en la oficina solucionando las consultas lentas durante la noche.
Antes de comenzar, permítanme asegurarles que el viaje no será difícil. Esto será solo una cartilla. Tendremos ejemplos que tampoco te resultarán demasiado extraños. Finalmente, cuando esté listo para un estudio más profundo, le presentaremos algunos enlaces que puede consultar.
Comencemos.
1. La optimización de consultas SQL comienza desde el diseño y la arquitectura
¿Sorprendido? La optimización de consultas SQL no es una ocurrencia tardía o una curita cuando algo se rompe. Su consulta se ejecuta tan rápido como lo permita su diseño. Estamos hablando de tablas normalizadas, los tipos de datos correctos, el uso de índices, el archivo de datos antiguos y cualquiera de las mejores prácticas que se le ocurran.
Un buen diseño de base de datos funciona en sinergia con el hardware adecuado y la configuración de SQL Server. ¿Lo diseñó para que funcionara sin problemas durante varios años y todavía se sintiera como nuevo? Es un gran sueño, pero solo tenemos una cierta cantidad de tiempo (por lo general, breve) para pensar en ello.
No será perfecto el día 1 en producción, pero deberíamos haber cubierto las bases. Minimizaremos la deuda técnica. Si estás trabajando con un equipo, eso es genial en comparación con un espectáculo de un solo hombre. Puede cubrir gran parte de las campanas y silbatos.
Aún así, ¿qué pasa si la base de datos se está ejecutando en vivo y golpea el muro de rendimiento? Estos son algunos consejos y trucos para la optimización de consultas SQL.
2. Detecte consultas problemáticas con el informe estándar de SQL Server
Cuando está codificando, es fácil detectar una larga serie de código o un procedimiento almacenado. Puedes depurarlo línea por línea. La línea que se atrasa es la que hay que arreglar.
Pero, ¿qué pasa si su servicio de asistencia arroja una docena de tickets porque es lento? Los usuarios no pueden identificar la ubicación exacta en el código, ni tampoco el servicio de asistencia técnica. El tiempo es tu peor enemigo.
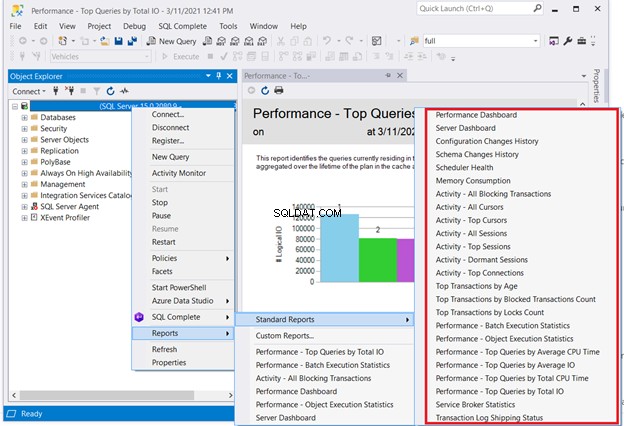
Una solución que no requerirá codificación es verificar los informes estándar de SQL Server. Haga clic derecho en el servidor necesario en SQL Server Management Studio> Informes> Informes estándar . Nuestro punto de interés puede ser Panel de rendimiento o Rendimiento:consultas principales por E/S total . Elija la primera consulta que tenga un mal rendimiento. A continuación, inicie la optimización de consultas SQL o el ajuste del rendimiento SQL desde allí.
3. Ajuste de consulta SQL con STATISTICS IO
Después de identificar la consulta en cuestión, puede comenzar a verificar las lecturas lógicas en STATISTICS IO. Esta es una de las herramientas de optimización de consultas SQL.
Hay algunos puntos de E/S, pero debe centrarse en las lecturas lógicas. Cuanto más altas sean las lecturas lógicas, más problemático será el rendimiento de la consulta.
Al reducir los siguientes 3 factores, puede acelerar las consultas de ajuste de rendimiento en SQL:
- lecturas lógicas altas,
- lecturas lógicas LOB altas,
- o lecturas lógicas altas de WorkTable/WorkFile.
Para obtener información sobre lecturas lógicas, active STATISTICS IO en la ventana de consulta de SQL Server Management Studio.
ACTIVAR ESTADÍSTICAS IO
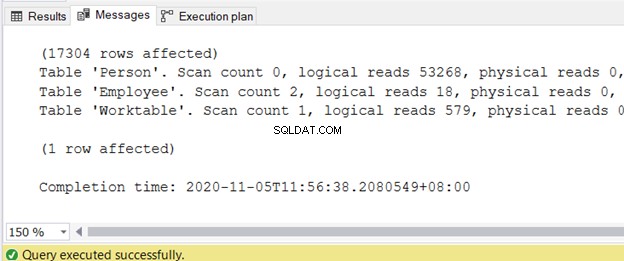
Puede obtener el resultado en la pestaña Mensajes después de realizar la consulta. La Figura 2 muestra el resultado de muestra:
He escrito un artículo separado sobre la reducción de lecturas lógicas en 3 estadísticas de E/S desagradables que retrasan el rendimiento de consultas SQL. Consúltelo para conocer los pasos exactos y ejemplos de código con lecturas lógicas altas y formas de reducirlas.
4. Ajuste de consultas SQL con planes de ejecución
Las lecturas lógicas por sí solas no le darán la imagen completa. La serie de pasos elegidos por el optimizador de consultas contará la historia de su conjunto de resultados. ¿Cómo comienza todo después de ejecutar la consulta?
La figura 3 a continuación es un diagrama de lo que sucede después de activar la ejecución hasta el momento en que obtiene el conjunto de resultados.
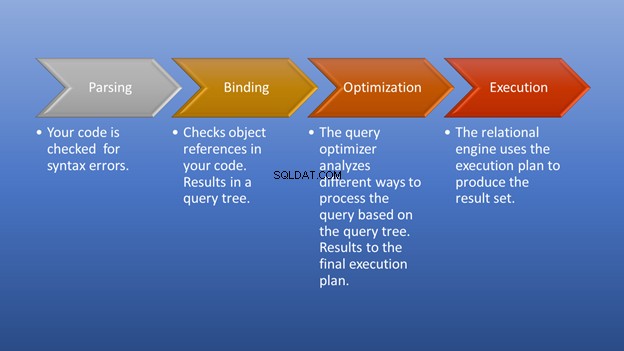
El análisis y la vinculación ocurrirán en un instante. La parte asombrosa es la etapa de optimización, que es nuestro enfoque. En esta etapa, el optimizador de consultas juega un papel fundamental en la selección del mejor plan de ejecución posible. Aunque esta parte necesita algunos recursos, ahorra mucho tiempo cuando elige un plan de ejecución eficiente. Esto sucede dinámicamente, ya que la base de datos cambia con el tiempo. De esta manera, el programador puede concentrarse en cómo formar el resultado final.
Cada plan que considera el optimizador de consultas tiene su costo de consulta. Entre muchas opciones, el optimizador elegirá el plan con el costo más razonable. Nota :El costo razonable no es igual al menor costo. También debe considerar qué plan producirá los resultados más rápidos. El plan de menor coste no siempre es el más rápido. Por ejemplo, el optimizador puede optar por utilizar varios núcleos de procesador. A esto lo llamamos ejecución paralela. Esto consumirá más recursos pero se ejecutará más rápido en comparación con la ejecución en serie.
Otro punto a considerar son las estadísticas. El optimizador de consultas se basa en él para crear planes de ejecución. Si las estadísticas están desactualizadas, no espere la mejor decisión del optimizador de consultas.
Cuando se decida el plan y proceda la ejecución, verá los resultados. ¿Y ahora qué?
Inspeccionar el plan de ejecución de consultas en SQL Server
Cuando realiza una consulta, primero desea ver los resultados. Los resultados tienen que ser correctos. Cuando lo esté, habrás terminado.
¿Es así?
Si tiene poco tiempo y el trabajo está en juego, puede aceptarlo. Además, siempre puedes volver. Sin embargo, si surgen otros problemas, puede olvidarlos una y otra vez. Y luego, el fantasma del pasado te perseguirá.
Ahora, ¿qué es lo mejor que se puede hacer después de obtener los resultados correctos?
Inspeccionar el plan de ejecución real o las Estadísticas de consultas en vivo !
Este último es bueno si su consulta se ejecuta lentamente y desea ver qué sucede cada segundo a medida que se procesan las filas.
A veces, la situación lo obligará a inspeccionar el plan de inmediato. Para comenzar, presiona Control-M o haga clic en Incluir plan de ejecución real desde la barra de herramientas de SQL Server Management Studio. Si prefiere dbForge Studio para SQL Server, vaya a Query Profiler – proporciona la misma información + algunas campanas y silbatos que no puede encontrar en SSMS.
Hemos visto el Plan de ejecución real . Avancemos más.
¿Falta un índice o recomendaciones de índice?
Un índice faltante es fácil de detectar:recibe la advertencia de inmediato.
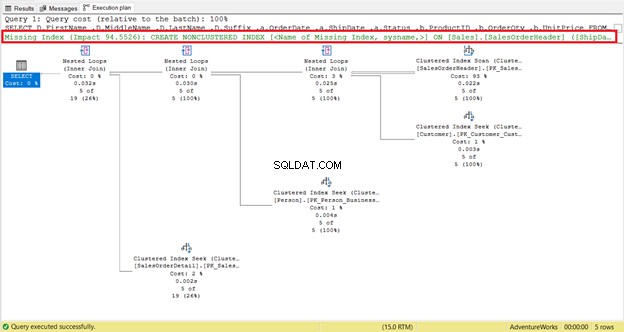
Para obtener un código instantáneo para crear el índice, haga clic con el botón derecho en Índice faltante mensaje (recuadro en rojo). A continuación, seleccione Faltan detalles del índice. . Aparecerá una nueva ventana de consulta con el código para crear el índice faltante. Crea el índice.
Esta parte es fácil de seguir. Es un buen punto de partida para lograr una ejecución más rápida. Pero en algunos casos, no tendrá ningún efecto. ¿Por qué? Algunas columnas que necesita su consulta no están en el índice. Por lo tanto, volverá a un escaneo de índice agrupado.
Debe volver a inspeccionar el plan de ejecución después de crear el índice para ver si se necesitan columnas incluidas. Luego, ajuste el índice en consecuencia y vuelva a ejecutar su consulta. Después de eso, verifique nuevamente el plan de ejecución.
Pero, ¿y si no falta ningún índice?
Leer el Plan de Ejecución
Necesita saber algunas cosas básicas para comenzar:
- Operadores
- Propiedades
- Dirección de lectura
- Advertencias
OPERADORES
El optimizador de consultas utiliza una especie de miniprogramas llamados operadores. Ha visto algunos de ellos en la Figura 4:búsqueda de índice agrupado , Escaneo de índice agrupado , Bucles anidados y Seleccionar .
Para obtener una lista completa con nombres, iconos y descripciones, puede consultar esta referencia de Microsoft.
PROPIEDADES
Los diagramas gráficos no son suficientes para comprender lo que sucede detrás de escena. Debe profundizar en las propiedades de cada operador. Por ejemplo, el Análisis de índice agrupado en la Figura 4 tiene las siguientes propiedades:
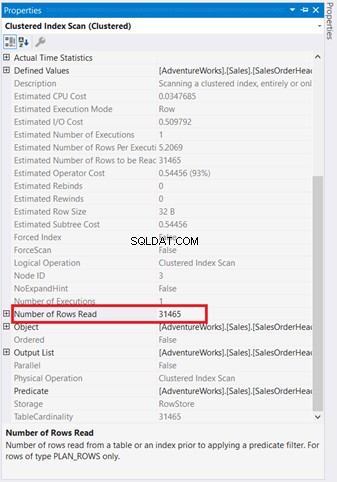
Si lo examina detenidamente, el Escaneo de índice agrupado El operador es terrible. Como muestra la Figura 5, leyó 31 465 filas, pero el conjunto de resultados final es solo de 5 filas. Es por eso que hay una recomendación de índice en la Figura 4 para reducir la cantidad de filas leídas. Las lecturas lógicas de la consulta también son altas y esto explica por qué.
Para conocer más de estas propiedades, consulte la lista de propiedades de operadores comunes y propiedades de planes.
DIRECCIÓN DE LECTURA
En general, es como leer manga japonés, de derecha a izquierda. Siga las flechas que apuntan a la izquierda. Aquí hay un ejemplo simple de dbForge Studio para SQL Server.
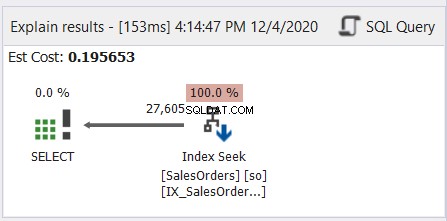
Como muestra la figura 6, la flecha apunta hacia la izquierda desde el operador de búsqueda de índice hasta el operador SELECCIONAR.
Sin embargo, leer de derecha a izquierda no siempre es correcto. Consulte la Figura 7 con un ejemplo de SSMS:
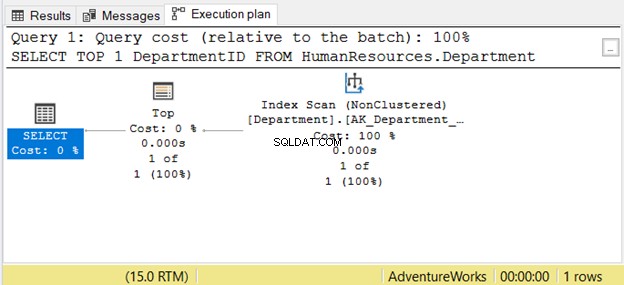
Si lo lee de derecha a izquierda, verá que el Index Scan la salida del operador es 1 de 1 fila. ¿Cómo podría saber solo 1 fila para buscar? Es por el Top operador. Esto nos confundirá si lo leemos de derecha a izquierda.
Para comprender mejor este caso, léalo como "el operador SELECT usa Top para buscar 1 fila usando Index Scan". Eso es de izquierda a derecha.
¿Qué debemos usar? ¿De derecha a izquierda o de izquierda a derecha?
Es una especie de ambos, lo que le ayude a comprender el plan.
Mientras que la flecha nos da la dirección del flujo de datos, su grosor nos da algunas pistas sobre el tamaño de los datos. Volvamos a la Figura 4 nuevamente.
El análisis de índice agrupado yendo al bucle anidado tiene una flecha más gruesa en comparación con los demás. Las Propiedades detalles de Escaneo de índice en la Figura 5, díganos por qué es grueso (31 465 filas leídas para un resultado final de 5 filas).
ADVERTENCIAS
Un icono de advertencia que aparece en el operador del plan de ejecución nos dice que algo malo ha sucedido en ese operador. Esto puede dificultar la optimización de consultas SQL al consumir más recursos.
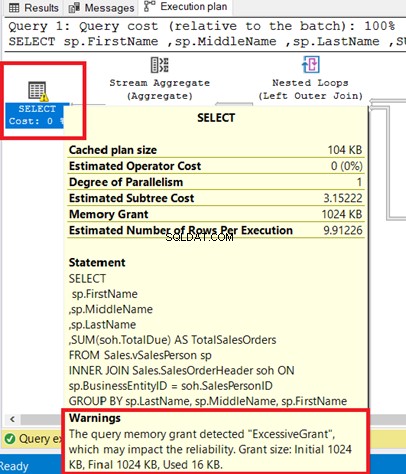
Puede ver la advertencia en el operador SELECCIONAR. Pasar el cursor sobre ese operador revela el mensaje de advertencia. Una subvención excesiva ha causado esta advertencia.
Concesión excesiva sucede cuando se usa menos memoria de la que se reservó para la consulta. Para obtener más información, consulte esta documentación de Microsoft.
La figura 8 muestra la consulta utilizada como INNER JOIN de una vista de una tabla. Puede eliminar la advertencia uniendo las tablas base en lugar de la vista.
Ahora que tiene una idea básica de cómo leer planes de ejecución, ¿cómo definir qué hace que su consulta sea lenta?
Conozca los 5 pícaros del operador del plan común
El retraso en la ejecución de su consulta es como un crimen. Tienes que perseguir y arrestar a estos pícaros.
1. Escaneo de índice agrupado o no agrupado
El primer pícaro del que todo el mundo se entera es Clustered o Escaneo de índice no agrupado . Es de conocimiento común en la optimización de consultas SQL que los escaneos son malos y las búsquedas son buenas. Hemos visto uno en la Figura 4. Debido al índice faltante, el Análisis del índice agrupado lee 31,465 para obtener 5 filas.
Sin embargo, no siempre es así. Considere 2 consultas en la misma tabla en la Figura 9. Una tendrá una búsqueda y otra tendrá una exploración.
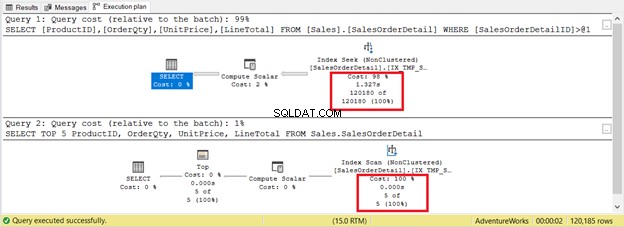
Si solo basa los criterios en la cantidad de registros, la exploración del índice gana con solo 5 registros frente a 120 180. La búsqueda de índice tardará más en ejecutarse.
Aquí hay otra instancia en la que escanear o buscar casi no importa. Devuelven los mismos 6 registros de la misma tabla. Las lecturas lógicas son las mismas y el tiempo transcurrido es cero en ambos casos. La tabla es muy pequeña con solo 6 registros. Incluya el plan de ejecución real y ejecute las declaraciones a continuación.
-- Run this with Include Actual Execution Plan
USE AdventureWorks
GO
SET STATISTICS IO ON
GO
SELECT AddressTypeID, Name
FROM Person.AddressType
WHERE AddressTypeID >= 1
ORDER BY AddressTypeID DESC
Luego, guarde el plan de ejecución para compararlo más tarde. Haga clic con el botón derecho en el plan de ejecución> Guardar plan de ejecución como .
Ahora, ejecuta la siguiente consulta.
SELECT AddressTypeID, Name
FROM Person.AddressType
ORDER BY AddressTypeID DESC
SET STATISTICS IO OFF
GO
A continuación, haga clic con el botón derecho en el Plan de ejecución y seleccione Comparar plan de presentación. . Luego, seleccione el archivo que guardó anteriormente. Debería tener el mismo resultado que en la Figura 10 a continuación.
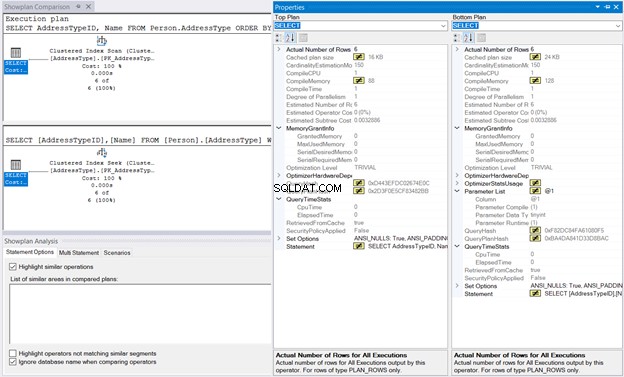
El MemoryGrant y QueryTimeStats son lo mismo. CompileMemory de 128 KB utilizado en la búsqueda de índice agrupado en comparación con los 88 KB del análisis de índice agrupado es casi insignificante. Sin estas cifras para comparar, la ejecución se sentirá igual.
2. Evitar escaneos de tablas
Esto sucede cuando no tienes un índice. En lugar de buscar valores usando un índice, SQL Server escaneará las filas una por una hasta que obtenga lo que necesita en su consulta. Esto se retrasará mucho en tablas grandes. La solución simple es agregar el índice apropiado.
Este es un ejemplo de un plan de ejecución con Table Scan operador en la Figura 11.
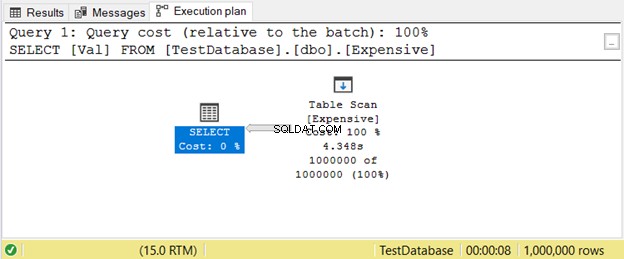
3. Gestión del rendimiento de clasificación
Como viene del nombre, cambia el orden de las filas. Esta puede ser una operación costosa.
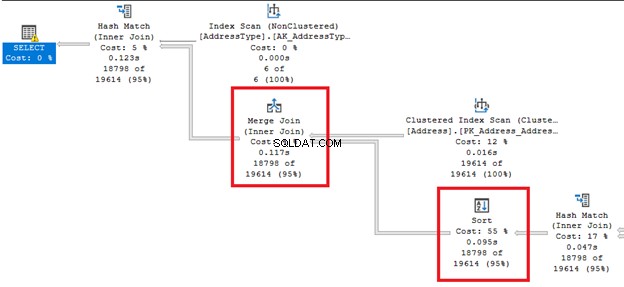
Mire esas gruesas líneas de flecha desde la derecha y la izquierda de Ordenar operador. Dado que el optimizador de consultas decidió hacer una combinación de combinación , un tipo es requerido. Nótese también que tiene el costo porcentual más alto de todos los operadores (55%).
Ordenar puede ser más problemático si SQL Server necesita ordenar las filas varias veces. Puede evitar este operador si su tabla está ordenada previamente según el requisito de consulta. O puede dividir una sola consulta en varias.
4. Eliminar búsquedas de claves
En la Figura 4 anterior, SQL Server recomendó agregar otro índice. Lo hice, pero no me dio exactamente lo que quería. En cambio, me dio una búsqueda de índice al nuevo índice combinado con una búsqueda de clave operador.
Entonces, el nuevo índice agregó un paso adicional.
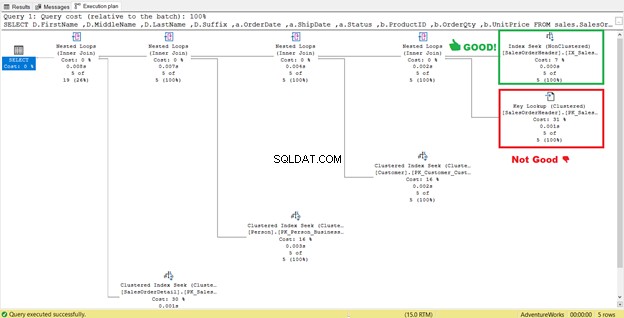
¿Qué hace esta búsqueda de claves operador hacer?
El procesador de consultas usó un nuevo índice no agrupado en un recuadro verde en la Figura 13. Como nuestra consulta requiere columnas que no están en el nuevo índice, debe obtener esos datos con la ayuda de una Búsqueda de clave del índice agrupado. Cómo sabemos esto? Pasar el mouse sobre la Búsqueda de claves revela algunas de sus propiedades y prueba nuestro punto.
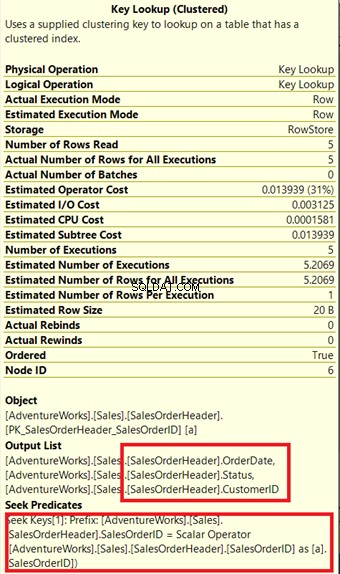
En la Figura 14, observe la Lista de salida. Necesitamos recuperar 3 columnas usando el PK_SalesOrderHeader_SalesOrderID índice agrupado. Para eliminar esto, debe incluir estas columnas en el nuevo índice. Aquí está el nuevo plan una vez que se incluyen estas columnas.
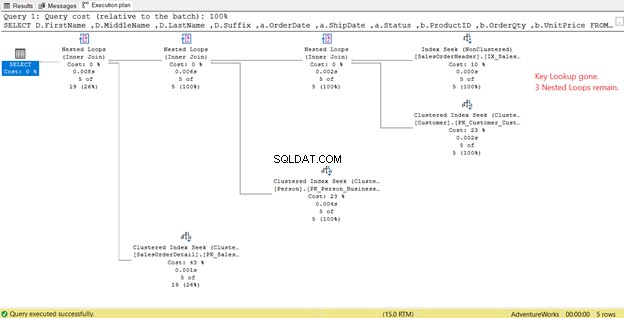
En la Figura 14, vimos 4 bucles anidados . El cuarto es necesario para la Búsqueda de claves añadida . Pero después de agregar 3 columnas como columnas incluidas en el nuevo índice, solo 3 bucles anidados quedan, y la búsqueda de claves es removido. No necesitamos ningún paso adicional.
5. Paralelismo en el Plan de Ejecución de SQL Server
Hasta ahora, vio planes de ejecución en ejecución en serie. Pero aquí está el plan que aprovecha la ejecución en paralelo. Esto significa que el optimizador de consultas utiliza más de 1 procesador para ejecutar la consulta. Cuando usamos la ejecución en paralelo, vemos paralelismo operadores en el plan, y otros cambios también.
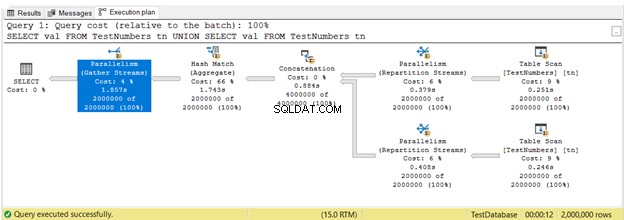
En la Figura 16, 3 Paralelismo Se utilizaron operadores. Observe también que el Escaneo de tabla el ícono del operador es un poco diferente. Esto sucede cuando se usa la ejecución en paralelo.
El paralelismo no es inherentemente malo. Aumenta la velocidad de las consultas al utilizar más núcleos de procesador. Sin embargo, utiliza más recursos de CPU. Cuando muchas de sus consultas usan paralelismos, ralentiza el servidor. Es posible que desee verificar el umbral de costo para la configuración de paralelismo en su servidor SQL.
5. Prácticas recomendadas para la optimización de consultas SQL
Hasta ahora, nos hemos ocupado de la optimización de consultas SQL con métodos que descubren problemas que son difíciles de detectar. Pero hay formas de detectarlo en el código. Aquí hay algunos olores de código en SQL.
Usando SELECCIONAR *
¿Apurado? Entonces escribir * puede ser más fácil que especificar los nombres de las columnas. Sin embargo, hay una trampa. Las columnas que no necesita retrasarán su consulta.
Hay prueba. La consulta de muestra que utilicé para la Figura 15 es esta:
USE AdventureWorks
GO
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
Ya lo hemos optimizado. Pero cambiémoslo a SELECT *
USE AdventureWorks
GO
SELECT *
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
Es más corto, está bien, pero revisa el Plan de Ejecución a continuación:
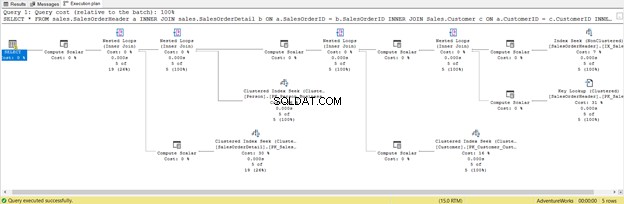
Esta es la consecuencia de incluir todas las columnas, incluso aquellas que no necesita. Devolvió búsqueda de clave y mucha computación escalar . En resumen, esta consulta tiene una gran carga y, como resultado, se retrasará. Observe también la advertencia en el operador SELECT. No estaba allí antes. ¡Qué desperdicio!
Funciones en una cláusula WHERE o JOIN
Otro olor de código es tener una función en la cláusula WHERE. Considere las siguientes 2 declaraciones SELECT que tienen el mismo conjunto de resultados. La diferencia está en la cláusula WHERE.
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE YEAR(a.ShipDate) = 2011
AND MONTH(a.ShipDate) = 7
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate BETWEEN '07/1/2011' AND '07/31/2011'
La primera instrucción SELECT usa funciones de fecha AÑO y MES para indicar fechas de envío dentro de julio de 2011. La segunda instrucción SELECT usa el operador BETWEEN con literales de fecha.
La primera declaración SELECT tendrá un plan de ejecución similar a la Figura 4 pero sin la recomendación de índice. El segundo tendrá un mejor plan de ejecución similar a la Figura 15.
El optimizado mejor es obvio.
Uso de comodines
¿Cómo pueden los comodines afectar nuestra optimización de consultas SQL? Pongamos un ejemplo.
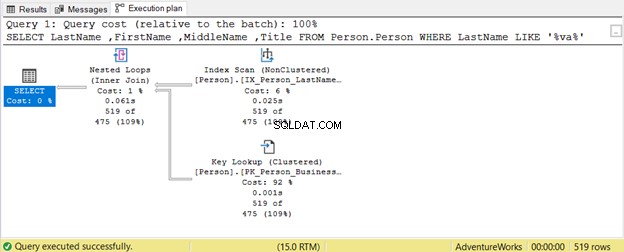
La consulta intenta buscar la presencia de una cadena dentro de Lastname en cualquier posición. Por lo tanto, Apellido LIKE '%va%' . Esto es ineficiente en tablas grandes porque las filas se inspeccionarán una por una para detectar la presencia de esa cadena. Es por eso que un Escaneo de índice se usa Dado que ningún índice incluye el Título columna, una Búsqueda de claves también se usa.
Esto se puede arreglar por diseño.
¿La aplicación de llamadas requiere eso? ¿O será suficiente usar LIKE 'va%'?
LIKE 'va%' usa una búsqueda de índice porque la tabla tiene un índice en lastname , nombre y segundo nombre .
¿Puede agregar más filtros en la cláusula WHERE para reducir la lectura de registros?
Tus respuestas a estas preguntas te ayudarán a solucionar esta consulta.
Conversión implícita
SQL Server realiza una conversión implícita en segundo plano para reconciliar los tipos de datos al comparar valores. Por ejemplo, es conveniente asignar un número a una columna de cadena sin comillas. Pero hay una trampa. El efecto es similar cuando usa una función en una cláusula WHERE.
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
WHERE NationalIDNumber = 56920285
El número de identificación nacional es NVARCHAR(15) pero se equipara a un número. Se ejecutará correctamente debido a la conversión implícita. Pero observe el plan de ejecución en la Figura 19 a continuación.
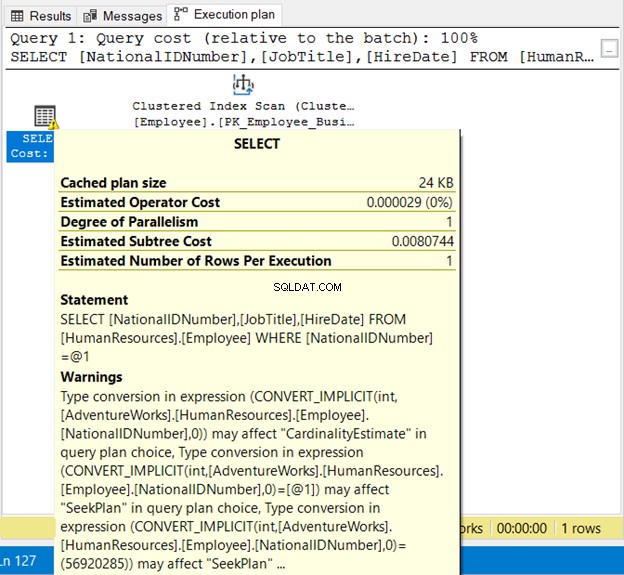
Vemos 2 cosas malas aquí. Primero, la advertencia. Luego, el Escaneo de índice . La exploración del índice se produjo debido a una conversión implícita. Por lo tanto, asegúrese de encerrar cadenas entre comillas o probar valores literales con el mismo tipo de datos que la columna.
Conclusiones de la optimización de consultas SQL
Eso es todo. ¿Los fundamentos de la optimización de consultas SQL te hicieron sentir un poco preparado para tus consultas? Hagamos un resumen.
- Si desea optimizar sus consultas, comience con un buen diseño de base de datos.
- Si la base de datos ya está en producción, detecte las consultas problemáticas utilizando los informes estándar de SQL Server.
- Aprenda qué tan grande es el impacto de la consulta lenta con lecturas lógicas de STATISTICS IO.
- Profundice en la historia de su consulta lenta con planes de ejecución.
- Observe 4 olores de código que ralentizan sus consultas.
Hay otros consejos de optimización de consultas SQL para hacer que una consulta lenta se ejecute rápidamente. Como dije al principio, este es un gran tema. Entonces, háganos saber en la sección de Comentarios qué más nos perdimos.
Y si te gusta esta publicación, compártela en tus plataformas de redes sociales favoritas.
Más optimización de consultas SQL de artículos anteriores
Si necesita más ejemplos, aquí hay algunas publicaciones útiles relacionadas con las técnicas de optimización de consultas en SQL Server.
- ¿Las subconsultas son malas para el rendimiento? Consulte La guía fácil sobre cómo usar subconsultas en SQL Server .
- Usar HierarchyID versus diseño principal/secundario:¿cuál es más rápido? Visite Cómo usar SQL Server HierarchyID a través de ejemplos sencillos .
- ¿Pueden las consultas de bases de datos gráficas superar a sus equivalentes relacionales en un sistema de recomendaciones en tiempo real? Consulte Cómo hacer uso de las características de la base de datos gráfica de SQL Server .
- ¿Qué es más rápido:COALESCE o ISNULL? Descúbralo en Respuestas principales a 5 preguntas candentes sobre la función SQL COALESCE .
- SELECCIONAR DE la vista frente a SELECCIONAR DE las tablas base:¿cuál se ejecutará más rápido? Visite Los 3 consejos principales que necesita saber para escribir vistas SQL más rápidas .
- CTE frente a tablas temporales frente a subconsultas. Sepa cuál ganará en Todo lo que necesita saber sobre SQL CTE en un solo lugar .
- Uso de SQL SUBSTRING en una cláusula WHERE:¿una trampa de rendimiento? Vea si es cierto con ejemplos en ¿Cómo analizar cadenas como un profesional usando la función SQL SUBSTRING()?
- SQL UNION ALL es más rápido que UNION. Sepa por qué en Hoja de trucos de SQL UNION con 10 consejos fáciles y útiles .