En la parte anterior de este artículo, discutimos cómo importar archivos CSV a SQL Server con la ayuda de la instrucción BULK INSERT. Discutimos la metodología principal del proceso de inserción masiva y también los detalles de las opciones BATSIZE y MAXERRORS en escenarios. En esta parte, veremos algunas otras opciones (FIRE_TRIGGERS, CHECK_CONSTRAINTS y TABLOCK) del proceso de inserción masiva en varios escenarios.
Escenario 1:¿Podemos habilitar disparadores en la tabla de destino durante la operación de inserción masiva?
De forma predeterminada, durante el proceso de inserción masiva, los activadores de inserción que se especifican en la tabla de destino no se activan; sin embargo, en algunas situaciones es posible que deseemos habilitar estos activadores. Una solución a este problema es usar la opción FIRE_TRIGGERS en declaraciones de inserción masiva. Quiero agregar un aviso de que esta opción puede afectar y disminuir el rendimiento de la operación de inserción masiva porque el desencadenador/disparadores pueden realizar operaciones separadas en la base de datos. En el siguiente ejemplo, demostraremos esto. Al principio, no estableceremos el parámetro FIRE_TRIGGERS y el proceso de inserción masiva no activará el activador de inserción. En el siguiente script T-SQL, definiremos un activador de inserción para la tabla Ventas.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
DROP TABLE IF EXISTS SalesLog
CREATE TABLE SalesLog (OrderIDLog bigint)
GO
CREATE TRIGGER OrderLogIns ON Sales
FOR INSERT
AS
BEGIN
SET NOCOUNT ON
INSERT INTO SalesLog
SELECT OrderId from inserted
end
GO
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
SELECT Count(*) FROM SalesLog
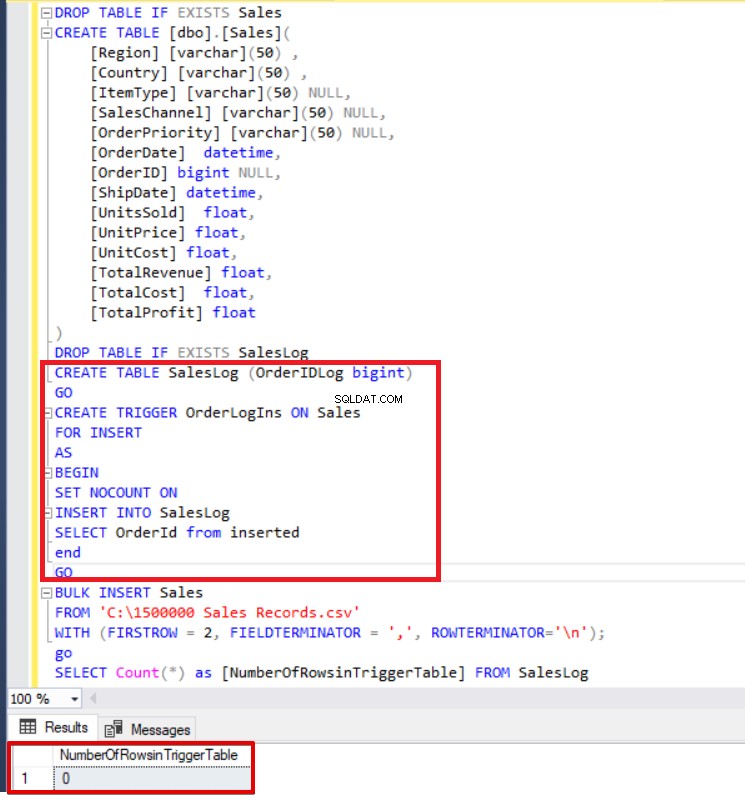
Como puede ver arriba, el activador de inserción no se activó porque no configuramos la opción FIRE_TRIGGERS. Ahora, agregaremos la opción FIRE_TRIGGERS a la declaración de inserción masiva para que esta opción permita insertar un disparador de disparo.
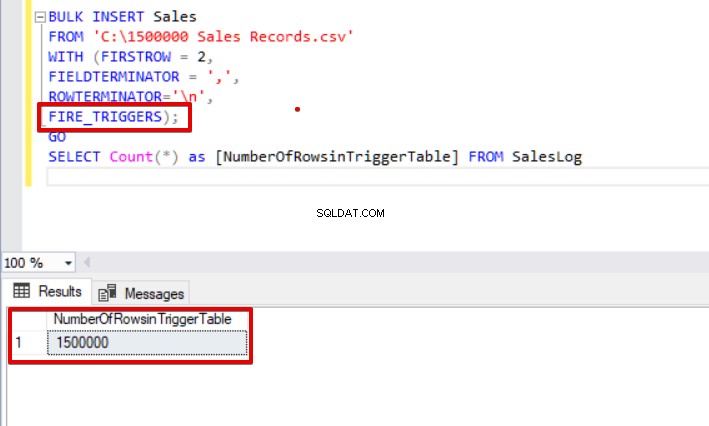
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FIRSTROW = 2, FIELDTERMINATOR = ',', ROWTERMINATOR='\n', FIRE_TRIGGERS); GO SELECT Count(*) as [NumberOfRowsinTriggerTable] FROM SalesLog
Escenario 2:¿Cómo se puede habilitar una restricción de verificación durante la operación de inserción masiva?
Las restricciones de verificación nos permiten hacer cumplir la integridad de los datos en las tablas de SQL Server. El propósito de la restricción es verificar los valores insertados, actualizados o eliminados de acuerdo con su regulación de sintaxis. Por ejemplo, la restricción NOT NULL establece que una columna específica no puede ser modificada por el valor NULL. Ahora, nos centraremos en las restricciones y la interacción de inserción masiva. De forma predeterminada, durante el proceso de inserción masiva, se ignoran las restricciones de verificación y clave externa, pero esta opción tiene algunas excepciones. De acuerdo con la documentación de Microsoft, “las restricciones ÚNICAS y CLAVE PRINCIPAL siempre se aplican. Al importar a una columna de caracteres para la que se define la restricción NOT NULL, BULK INSERT inserta una cadena en blanco cuando no hay ningún valor en el archivo de texto". En el siguiente script T-SQL, agregaremos una restricción de verificación a la columna OrderDate que controla la fecha del pedido posterior al 01.01.2016.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
ALTER TABLE [Sales] ADD CONSTRAINT OrderDate_Check
CHECK(OrderDate >'20160101')
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
GO
SELECT COUNT(*) AS [UnChekedData] FROM
Sales WHERE OrderDate <'20160101'
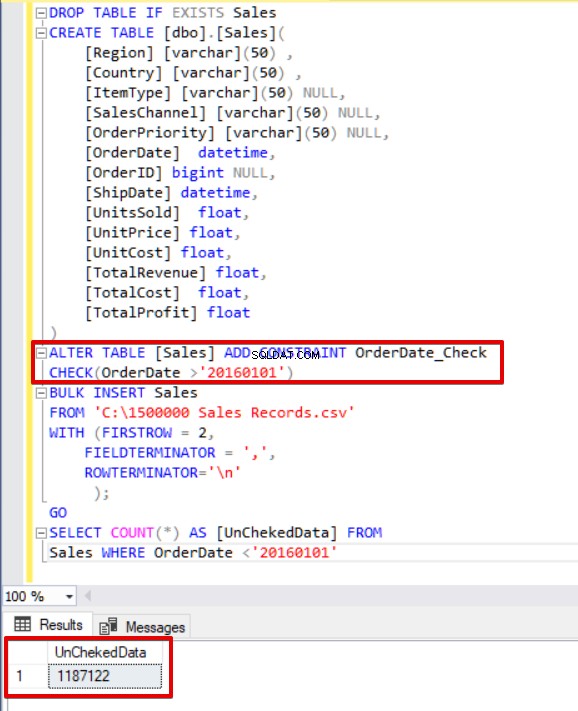
Como puede ver en el ejemplo anterior, el proceso de inserción masiva omite el control de restricción de verificación. Sin embargo, SQL Server indica que la restricción de verificación no es de confianza.
SELECT is_not_trusted ,* FROM sys.check_constraints where name='OrderDate_Check'
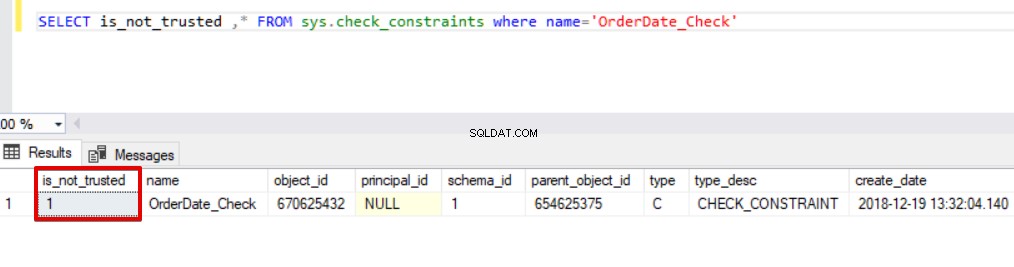
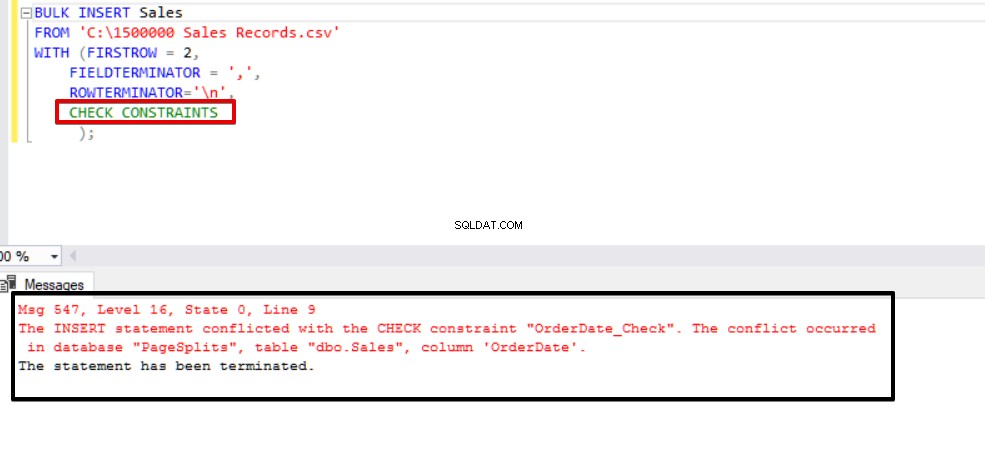
Este valor indica que alguien insertó o actualizó algunos datos en esta columna omitiendo la restricción de verificación, al mismo tiempo, esta columna puede contener datos inconsistentes con referencia a esa restricción. Ahora, intentaremos ejecutar la declaración de inserción masiva con la opción CHECK_CONSTRAINTS. El resultado es muy simple, la restricción de verificación devuelve un error debido a datos incorrectos.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
Escenario 3:¿Cómo aumentar el rendimiento en múltiples inserciones masivas en una tabla de destino?
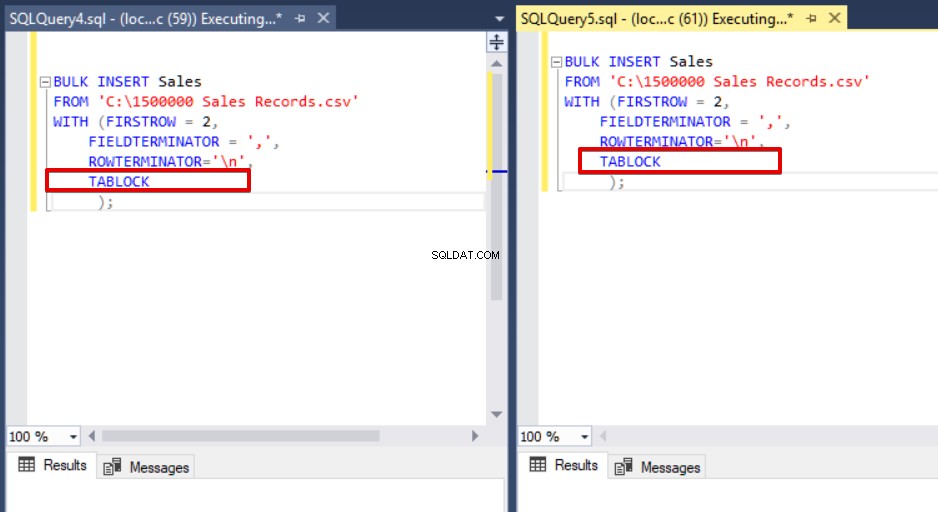
El objetivo principal del mecanismo de bloqueo en SQL Server es proteger y garantizar la integridad de los datos. En el artículo Concepto principal de bloqueo de SQL Server, puede encontrar detalles sobre el mecanismo de bloqueo. Ahora, nos centraremos en los detalles de bloqueo del proceso de inserción masiva. Si ejecuta la declaración de inserción masiva sin la opción TABLELOCK, adquiere el bloqueo de filas o tabla según la jerarquía de bloqueo. Sin embargo, en algunos casos, es posible que queramos ejecutar varios procesos de inserción masiva en una tabla de destino, por lo que podemos reducir el tiempo de operación de la inserción masiva. Primero, ejecutaremos dos declaraciones de inserción masiva simultáneamente y analizaremos el comportamiento del mecanismo de bloqueo. Abriremos dos ventanas de consulta en SQL Server Management Studio y ejecutaremos las siguientes declaraciones de inserción masiva simultáneamente.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
Cuando ejecutamos la siguiente consulta dmv (Dynamic Management View), que ayuda a monitorear el estado del proceso de inserción masiva.
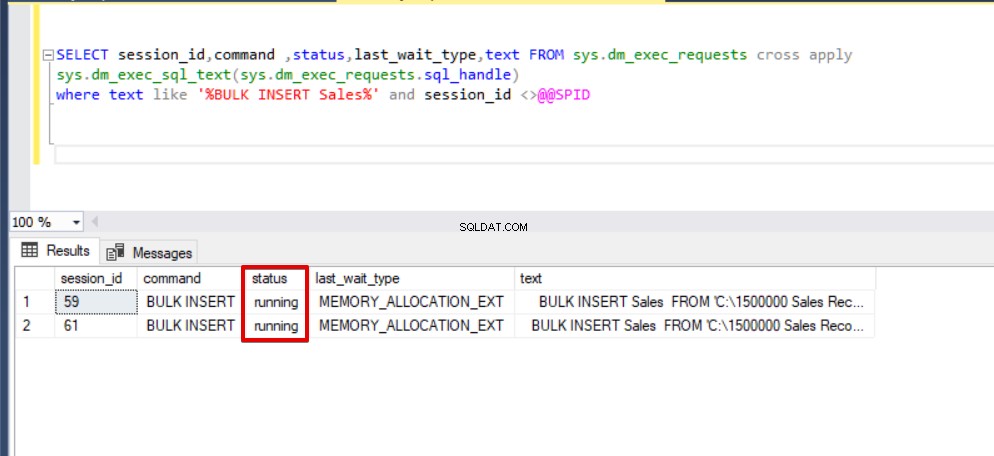
SELECT session_id,command ,status,last_wait_type,text FROM sys.dm_exec_requests cross apply sys.dm_exec_sql_text(sys.dm_exec_requests.sql_handle) where text like '%BULK INSERT Sales%' and session_id <>@@SPID
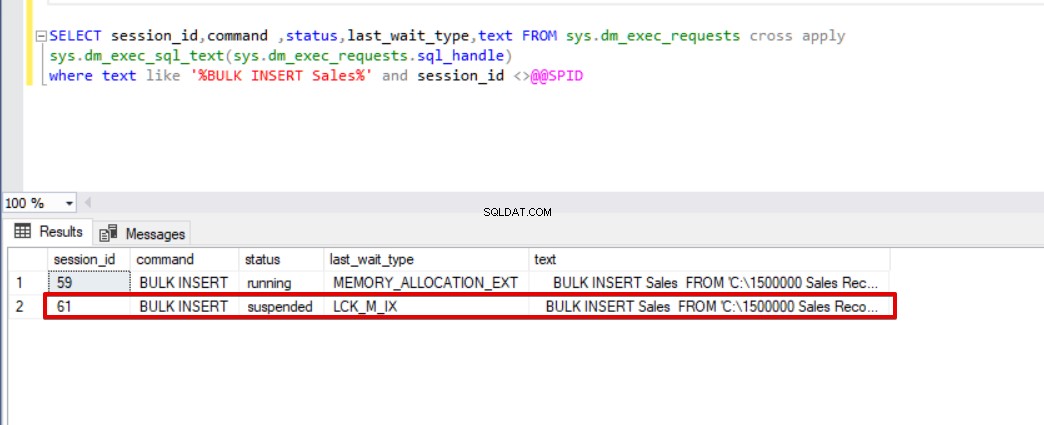
Como puede ver en la imagen de arriba, sesión 61, el estado del proceso de inserción masiva está suspendido debido a un bloqueo. Si verificamos el problema, la sesión 59 bloquea la tabla de destino de inserción masiva y la sesión 61 espera a que se libere este bloqueo para continuar con el proceso de inserción masiva. Ahora, agregaremos la opción TABLOCK a las declaraciones de inserción masiva y ejecutaremos las consultas.
Cuando volvemos a ejecutar la consulta de monitoreo de dmv, no podemos ver ningún proceso de inserción masiva suspendido porque SQL Server usa un tipo de bloqueo especial llamado bloqueo de actualización masiva (BU). Este tipo de bloqueo permite procesar varias operaciones de inserción masiva contra la misma tabla simultáneamente y esta opción también reduce el tiempo total del proceso de inserción masiva.
Cuando ejecutamos la siguiente consulta durante el proceso de inserción masiva, podemos monitorear los detalles de bloqueo y los tipos de bloqueo.
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'OBJECT'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()
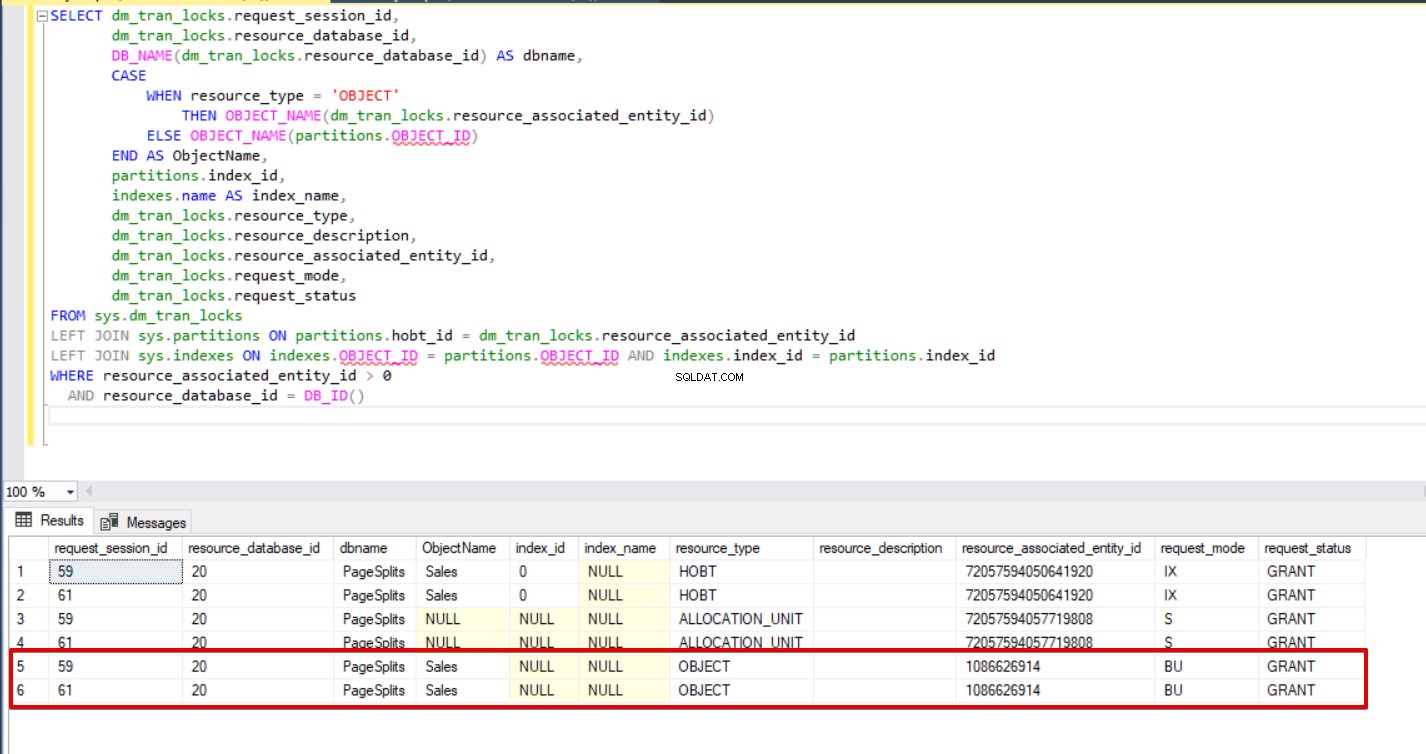
Conclusión
En este artículo, exploramos todos los detalles de la operación de inserción masiva en SQL Server. En particular, mencionamos el comando BULK INSERT y su configuración y opciones, y también analizamos varios escenarios que se acercan a los problemas de la vida real.
Referencias
INSERCIÓN A GRANEL (Transact-SQL)
Requisitos previos para el inicio de sesión mínimo en la importación masiva
Control del comportamiento de bloqueo para la importación masiva
Lecturas adicionales
Exportación de datos a un archivo plano con la utilidad BCP e importación de datos con inserción masiva
Herramienta útil:
dbForge Data Pump:un complemento de SSMS para llenar bases de datos SQL con datos de fuentes externas y migrar datos entre sistemas.