Introducción
Una tabla es una estructura lógica. Cuando crea una tabla, normalmente no le importará en qué unidades se encuentra en la capa de almacenamiento. Sin embargo, si es administrador de una base de datos, este conocimiento puede volverse esencial si necesita mover ciertas partes de la base de datos a un almacenamiento o volumen alternativo. Luego, es posible que desee que las tablas definidas estén en un volumen o conjunto de discos en particular.
Los grupos de archivos en SQL Server ofrecen esa capa de abstracción que nos permite controlar la ubicación física de nuestras estructuras lógicas:tablas, índices, etc.
Grupos de archivos
Un grupo de archivos es una estructura lógica para agrupar archivos de datos en SQL Server. Si creamos un grupo de archivos y lo asociamos con un conjunto de archivos de datos, cualquier objeto lógico creado en ese grupo de archivos se ubicará físicamente en ese conjunto de archivos físicos.
El objetivo principal de dicha agrupación de archivos físicos es la asignación y ubicación de datos. Por ejemplo, queremos que nuestros datos de transacciones se almacenen en un conjunto de discos rápidos. Simultáneamente, necesitamos los datos históricos almacenados en otro conjunto de discos menos costosos. En tal escenario, crearíamos el Tran tabla en el grupo de archivos TXN y el TranHist tabla en un grupo de archivos HIST diferente. Más adelante en este artículo, veremos cómo esto se traduce en tener los datos en diferentes discos.
Creación de grupos de archivos
La sintaxis para crear grupos de archivos se muestra en el Listado 1 . Nota :El contexto de la base de datos es el maestro base de datos. Al emitir las declaraciones, estamos alterando la base de datos DB2 al agregarle nuevos grupos de archivos. Esencialmente, estos grupos de archivos son simplemente construcciones lógicas en este punto. No contienen ningún dato.
-- Listing 1: Creating File Groups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [TXN]
GO
Adición de archivos a grupos de archivos
El siguiente paso es agregar un archivo a cada uno de los grupos de archivos. Podemos agregar más de un archivo, pero lo mantenemos simple para fines de demostración. Tenga en cuenta que cada archivo está en una unidad diferente por completo, y la sintaxis nos permite especificar el grupo de archivos previsto.
-- Listing 2: Adding Files to Filegroups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_HIST_01', FILENAME = N'E:\MSSQL\Data\DB2_HIST_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_TXN_01', FILENAME = N'C:\MSSQL\Data\DB2_TXN_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [TXN]
GO
Creación de tablas para grupos de archivos
Aquí nos aseguramos de que las tablas estén en los discos deseados. La sintaxis para crear tablas nos permite especificar el grupo de archivos que queremos.
-- Listing 3: Creating a table on Filegroups TXN and HIST
USE [DB2]
GO
CREATE TABLE [dbo].[tran](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [TXN]
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [TXN]
GO
CREATE TABLE [dbo].[tranhist](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [HIST]
GO
Dando un paso atrás, notamos que ahora hemos logrado lo siguiente:
- Se crearon dos grupos de archivos.
- Determinó los archivos de datos (y discos) asociados con cada grupo de archivos.
- Determiné las tablas asociadas con cada grupo de archivos.
En esencia, el grupo de archivos es la capa de abstracción .
Comprobar en qué grupos de archivos se ubican nuestras tablas
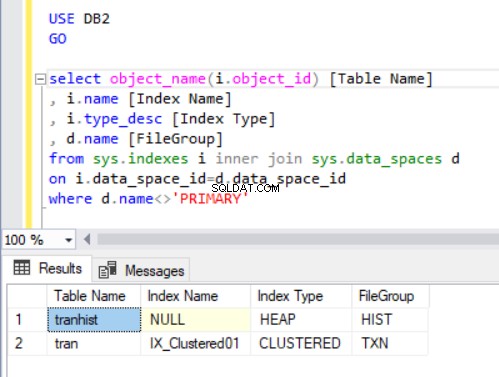
Para comprobar a qué grupo de archivos pertenece cada tabla, ejecutaremos el código del Listado 4. Usamos dos vistas principales del catálogo del sistema:sys.indexes y sys.data_spaces . Los sys.data_spaces La vista de catálogo contiene información sobre grupos de archivos y particiones, y las principales estructuras lógicas donde se almacenan las tablas y los índices.
Nota:No usamos sys.tables . SQL Server asocia índices en una tabla con espacios de datos en lugar de tablas, como podríamos pensar intuitivamente.
-- Listing 4: Check the filegroup of an index or table
USE DB2
GO
select object_name(i.object_id) [Table Name]
, i.name [Index Name]
, i.type_desc [Index Type]
, d.name [FileGroup]
from sys.indexes i inner join sys.data_spaces d
on i.data_space_id=d.data_space_id
where d.name<>'PRIMARY'
El resultado de la consulta en el Listado 4 muestra dos tablas que acabamos de crear. Observe que el tranhist la tabla no tiene un índice. Aún así, aparece en el conjunto de resultados, identificado como un montón .
Un montón es una tabla que no tiene un índice agrupado que determine los datos de orden almacenados físicamente en una tabla. Solo puede haber un índice agrupado en una tabla.
Rellenar la tabla Tran
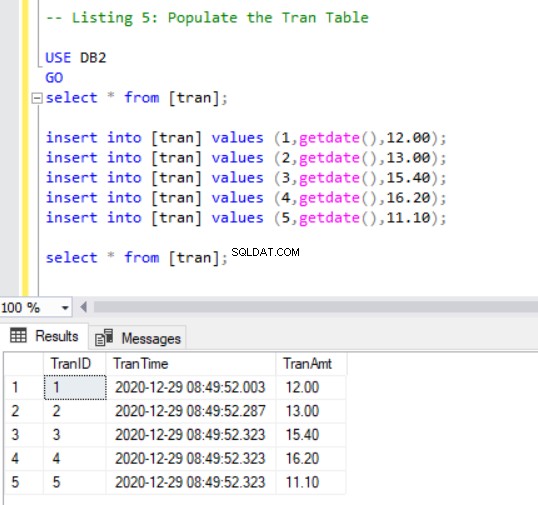
Ahora, tenemos que agregar algunos registros al tran tabla usando el siguiente código:
-- Listing 5: Populate the Tran Table
USE DB2
GO
SELECT * FROM [tran];
INSERT INTO [tran] VALUES (1, GETDATE(),12.00);
INSERT INTO [tran] VALUES (2, GETDATE(),13.00);
INSERT INTO [tran] VALUES (3, GETDATE(),15.40);
INSERT INTO [tran] VALUES (4, GETDATE(),16.20);
INSERT INTO [tran] VALUES (5, GETDATE(),11.10);
SELECT * FROM [tran];
Mover una tabla a otro grupo de archivos
Para mover el tran tabla a otro grupo de archivos, solo necesitamos reconstruir el índice agrupado y especifique el nuevo grupo de archivos mientras realiza esta reconstrucción. El Listado 5 muestra este enfoque.
Realizamos dos pasos:primero, suelte el índice, luego, vuelva a crearlo. En el medio, verificamos para confirmar que los datos y la ubicación de las dos tablas que creamos anteriormente permanecen intactos.
-- Listing 6: Check what filegroup an index or table belongs to
USE [DB2]
GO
DROP INDEX [IX_Clustered01] ON [dbo].[tran] WITH ( ONLINE = OFF )
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [HIST]
GO
Al eliminar el índice agrupado del tran tabla, la hemos convertido en un montón :
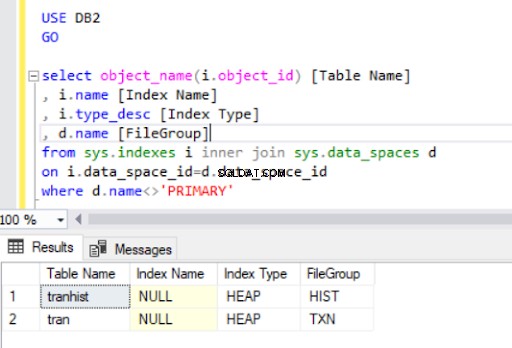
Cuando recreamos el índice agrupado, también se indica en el resultado del Listado 4.
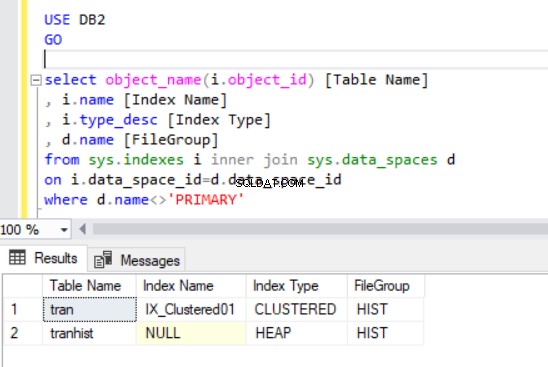
Ahora tenemos el tran tabla en el grupo de archivos HIST.
Conclusión
Este artículo demostró la relación entre tablas, índices, archivos y grupos de archivos en términos de nuestro almacenamiento de datos de SQL Server. También hemos explicado cómo mover una tabla de un grupo de archivos a otro al recrear el índice agrupado.
Esta habilidad será útil cuando necesite migrar datos a un nuevo almacenamiento (discos más rápidos o discos más lentos para archivar). En escenarios más avanzados, puede usar grupos de archivos para administrar el ciclo de vida de los datos mediante la implementación de particiones de tablas.
Referencias
- Archivos de base de datos y grupos de archivos
- Cómo cambiar las particiones de la mesa:un tutorial