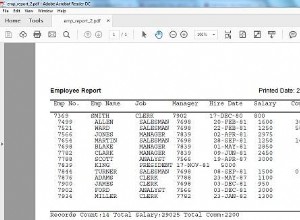
No dijo qué versión estaba usando, pero en SQL 2005 y superior, puede usar una expresión de tabla común con la cláusula OVER. Va un poco como esto:
WITH cte AS (
SELECT[foo], [bar],
row_number() OVER(PARTITION BY foo, bar ORDER BY baz) AS [rn]
FROM TABLE
)
DELETE cte WHERE [rn] > 1
Juega con él y mira lo que obtienes.
(Editar:En un intento de ser útil, alguien editó el ORDER BY cláusula dentro del CTE. Para que quede claro, puede ordenar por lo que quiera aquí, no es necesario que sea una de las columnas devueltas por el cte. De hecho, un caso de uso común aquí es que "foo, bar" son el identificador de grupo y "baz" es una especie de marca de tiempo. Para mantener lo último, haría ORDER BY baz desc )