Veo muchos consejos por ahí que dicen algo como:"Cambie su cursor a una operación basada en conjuntos; eso lo hará más rápido". Si bien ese puede ser el caso a menudo, no siempre es cierto. Un caso de uso que veo donde un cursor supera repetidamente el enfoque típico basado en conjuntos es el cálculo de los totales acumulados. Esto se debe a que el enfoque basado en conjuntos por lo general tiene que observar una parte de los datos subyacentes más de una vez, lo que puede ser un problema exponencialmente malo a medida que los datos aumentan; mientras que un cursor, por doloroso que parezca, puede pasar por cada fila/valor exactamente una vez.
Estas son nuestras opciones básicas en las versiones más comunes de SQL Server. En SQL Server 2012, sin embargo, se han realizado varias mejoras a las funciones de ventanas y la cláusula OVER, en su mayoría derivadas de varias sugerencias excelentes enviadas por su compañero MVP Itzik Ben-Gan (aquí está una de sus sugerencias). De hecho, Itzik tiene un nuevo libro de MS-Press que cubre todas estas mejoras con mucho más detalle, titulado "Microsoft SQL Server 2012 High-Performance T-SQL usando funciones de ventana".
Así que, naturalmente, tenía curiosidad; ¿La nueva funcionalidad de ventana haría obsoletas las técnicas de cursor y autounión? ¿Sería más fácil de codificar? ¿Serían más rápidos en cualquier caso (no importa en todos)? ¿Qué otros enfoques podrían ser válidos?
La configuración
Para hacer algunas pruebas, configuremos una base de datos:
USE [master];
GO
IF DB_ID('RunningTotals') IS NOT NULL
BEGIN
ALTER DATABASE RunningTotals SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE RunningTotals;
END
GO
CREATE DATABASE RunningTotals;
GO
USE RunningTotals;
GO
SET NOCOUNT ON;
GO Y luego llene una tabla con 10,000 filas que podemos usar para realizar algunos totales acumulados. Nada demasiado complicado, solo una tabla resumen con una fila para cada fecha y un número que representa cuántas multas por exceso de velocidad se emitieron. No he tenido una multa por exceso de velocidad en un par de años, así que no sé por qué esta fue mi elección subconsciente para un modelo de datos simplista, pero ahí está.
CREATE TABLE dbo.SpeedingTickets ( [Date] DATE NOT NULL, TicketCount INT ); GO ALTER TABLE dbo.SpeedingTickets ADD CONSTRAINT pk PRIMARY KEY CLUSTERED ([Date]); GO ;WITH x(d,h) AS ( SELECT TOP (250) ROW_NUMBER() OVER (ORDER BY [object_id]), CONVERT(INT, RIGHT([object_id], 2)) FROM sys.all_objects ORDER BY [object_id] ) INSERT dbo.SpeedingTickets([Date], TicketCount) SELECT TOP (10000) d = DATEADD(DAY, x2.d + ((x.d-1)*250), '19831231'), x2.h FROM x CROSS JOIN x AS x2 ORDER BY d; GO SELECT [Date], TicketCount FROM dbo.SpeedingTickets ORDER BY [Date]; GO
Resultados resumidos:
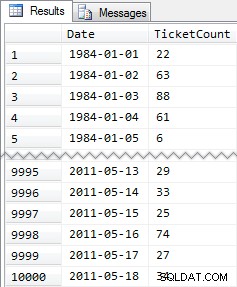
De nuevo, 10 000 filas de datos bastante simples:pequeños valores INT y una serie de fechas desde 1984 hasta mayo de 2011.
Los enfoques
Ahora mi tarea es relativamente simple y típica de muchas aplicaciones:devolver un conjunto de resultados que tenga las 10 000 fechas, junto con el total acumulado de todas las multas por exceso de velocidad hasta esa fecha incluida. La mayoría de las personas probarían primero algo como esto (lo llamaremos "unión interna " método):
SELECT st1.[Date], st1.TicketCount, RunningTotal = SUM(st2.TicketCount) FROM dbo.SpeedingTickets AS st1 INNER JOIN dbo.SpeedingTickets AS st2 ON st2.[Date] <= st1.[Date] GROUP BY st1.[Date], st1.TicketCount ORDER BY st1.[Date];
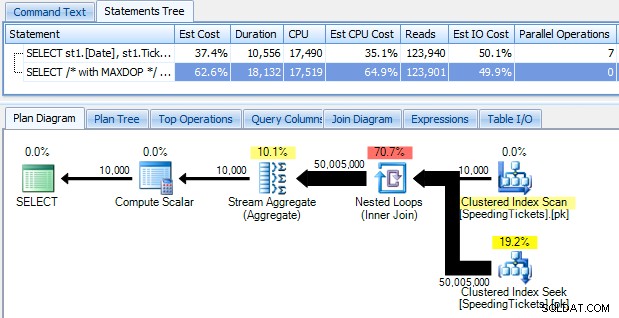
…y sorpréndase al descubrir que tarda casi 10 segundos en ejecutarse. Examinemos rápidamente por qué al ver el plan de ejecución gráfico, usando SQL Sentry Plan Explorer:

Las flechas grandes y gordas deberían dar una indicación inmediata de lo que está pasando:el ciclo anidado lee una fila para la primera agregación, dos filas para la segunda, tres filas para la tercera, y así sucesivamente a través del conjunto completo de 10,000 filas. Esto significa que deberíamos ver aproximadamente ((10000 * (10000 + 1)) / 2) filas procesadas una vez que se recorre todo el conjunto, y eso parece coincidir con la cantidad de filas que se muestran en el plan.
Tenga en cuenta que ejecutar la consulta sin paralelismo (usando la sugerencia de consulta OPTION (MAXDOP 1)) hace que la forma del plan sea un poco más simple, pero no ayuda en absoluto en el tiempo de ejecución ni en la E/S; como se muestra en el plan, la duración en realidad casi se duplica y las lecturas solo disminuyen en un porcentaje muy pequeño. En comparación con el plan anterior:
Hay muchos otros enfoques que la gente ha probado para obtener totales acumulados eficientes. Un ejemplo es el "método de subconsulta " que solo usa una subconsulta correlacionada de la misma manera que el método de unión interna descrito anteriormente:
SELECT [Date], TicketCount, RunningTotal = TicketCount + COALESCE( ( SELECT SUM(TicketCount) FROM dbo.SpeedingTickets AS s WHERE s.[Date] < o.[Date]), 0 ) FROM dbo.SpeedingTickets AS o ORDER BY [Date];
Comparando esos dos planes:
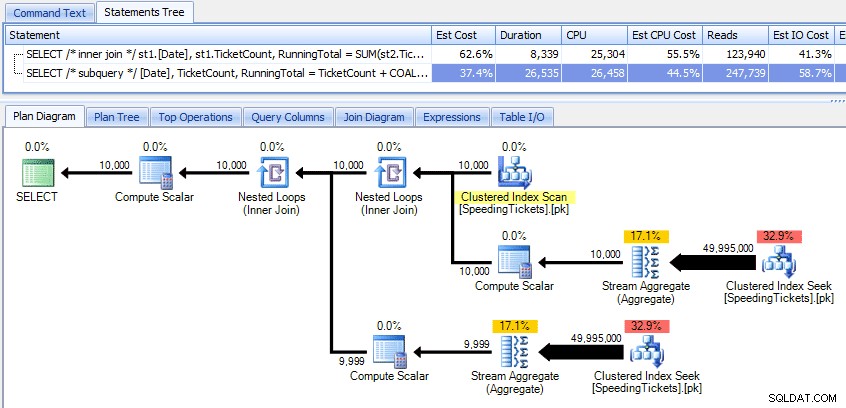
Entonces, si bien el método de subconsulta parece tener un plan general más eficiente, es peor donde importa:duración y E/S. Podemos ver qué contribuye a esto profundizando un poco más en los planes. Al movernos a la pestaña Operaciones principales, podemos ver que en el método de unión interna, la búsqueda de índice agrupado se ejecuta 10,000 veces, y todas las demás operaciones solo se ejecutan unas pocas veces. Sin embargo, varias operaciones se ejecutan 9.999 o 10.000 veces en el método de subconsulta:
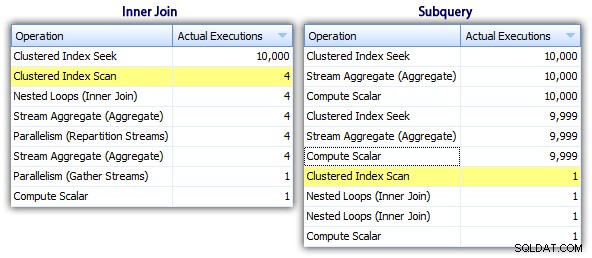
Entonces, el enfoque de la subconsulta parece ser peor, no mejor. El próximo método que probaremos, lo llamaré "actualización peculiar " método. No se garantiza exactamente que funcione, y nunca lo recomendaría para el código de producción, pero lo incluyo para que esté completo. Básicamente, la actualización peculiar aprovecha el hecho de que durante una actualización puede redirigir la asignación y las matemáticas para que que la variable aumenta entre bastidores a medida que se actualiza cada fila.
DECLARE @st TABLE ( [Date] DATE PRIMARY KEY, TicketCount INT, RunningTotal INT ); DECLARE @RunningTotal INT = 0; INSERT @st([Date], TicketCount, RunningTotal) SELECT [Date], TicketCount, RunningTotal = 0 FROM dbo.SpeedingTickets ORDER BY [Date]; UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st; SELECT [Date], TicketCount, RunningTotal FROM @st ORDER BY [Date];
Reafirmaré que no creo que este enfoque sea seguro para la producción, independientemente del testimonio que escuchará de personas que indican que "nunca falla". A menos que el comportamiento esté documentado y garantizado, trato de mantenerme alejado de las suposiciones basadas en el comportamiento observado. Nunca se sabe cuándo algún cambio en la ruta de decisión del optimizador (basado en un cambio de estadísticas, un cambio de datos, un paquete de servicio, un indicador de seguimiento, una sugerencia de consulta, etc.) alterará drásticamente el plan y podría conducir a un orden diferente. Si realmente le gusta este enfoque poco intuitivo, puede sentirse un poco mejor usando la opción de consulta ORDEN FORZADO (y esto intentará usar un escaneo ordenado del PK, ya que ese es el único índice elegible en la variable de la tabla):
UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st OPTION (FORCE ORDER);
Para tener un poco más de confianza a un costo de E/S ligeramente más alto, puede volver a poner en juego la tabla original y asegurarse de que se use el PK en la tabla base:
UPDATE st SET @RunningTotal = st.RunningTotal = @RunningTotal + t.TicketCount FROM dbo.SpeedingTickets AS t WITH (INDEX = pk) INNER JOIN @st AS st ON t.[Date] = st.[Date] OPTION (FORCE ORDER);
Personalmente, no creo que esté mucho más garantizado, ya que la parte SET de la operación podría influir potencialmente en el optimizador independientemente del resto de la consulta. Una vez más, no recomiendo este enfoque, solo incluyo la comparación para que esté completo. Aquí está el plan de esta consulta:
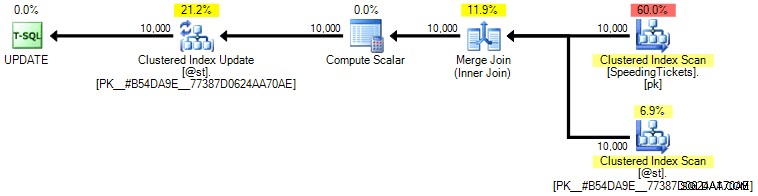
Según el número de ejecuciones que vemos en la pestaña Operaciones principales (le ahorraré la captura de pantalla; es 1 para cada operación), está claro que incluso si realizamos una unión para sentirnos mejor al ordenar, el peculiar La actualización permite que los totales acumulados se calculen en un solo paso de los datos. En comparación con las consultas anteriores, es mucho más eficiente, aunque primero vuelca los datos en una variable de tabla y se separa en varias operaciones:

Esto nos lleva a un "CTE recursivo " método. Este método utiliza el valor de la fecha y se basa en la suposición de que no hay espacios. Dado que completamos estos datos anteriormente, sabemos que es una serie completamente contigua, pero en muchos escenarios no puede hacer eso suposición. Entonces, si bien lo he incluido para completar, este enfoque no siempre será válido. En cualquier caso, esto usa un CTE recursivo con la primera fecha (conocida) en la tabla como ancla, y el recursivo porción determinada sumando un día (agregando la opción MAXRECURSION ya que sabemos exactamente cuántas filas tenemos):
;WITH x AS ( SELECT [Date], TicketCount, RunningTotal = TicketCount FROM dbo.SpeedingTickets WHERE [Date] = '19840101' UNION ALL SELECT y.[Date], y.TicketCount, x.RunningTotal + y.TicketCount FROM x INNER JOIN dbo.SpeedingTickets AS y ON y.[Date] = DATEADD(DAY, 1, x.[Date]) ) SELECT [Date], TicketCount, RunningTotal FROM x ORDER BY [Date] OPTION (MAXRECURSION 10000);
Esta consulta funciona tan eficientemente como el peculiar método de actualización. Podemos compararlo con los métodos de subconsulta y unión interna:

Al igual que el método de actualización peculiar, no recomendaría este enfoque CTE en producción a menos que pueda garantizar absolutamente que su columna clave no tenga espacios. Si puede tener lagunas en sus datos, puede construir algo similar usando ROW_NUMBER(), pero no será más eficiente que el método de autounión anterior.
Y luego tenemos el "cursor " enfoque:
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
DECLARE
@Date DATE,
@TicketCount INT,
@RunningTotal INT = 0;
DECLARE c CURSOR
LOCAL STATIC FORWARD_ONLY READ_ONLY
FOR
SELECT [Date], TicketCount
FROM dbo.SpeedingTickets
ORDER BY [Date];
OPEN c;
FETCH NEXT FROM c INTO @Date, @TicketCount;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @RunningTotal = @RunningTotal + @TicketCount;
INSERT @st([Date], TicketCount, RunningTotal)
SELECT @Date, @TicketCount, @RunningTotal;
FETCH NEXT FROM c INTO @Date, @TicketCount;
END
CLOSE c;
DEALLOCATE c;
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date]; …que es mucho más código, pero contrariamente a lo que podría sugerir la opinión popular, regresa en 1 segundo. Podemos ver por qué a partir de algunos de los detalles del plan anteriores:la mayoría de los otros enfoques terminan leyendo los mismos datos una y otra vez, mientras que el enfoque del cursor lee cada fila una vez y mantiene el total acumulado en una variable en lugar de calcular la suma sobre y otra vez Podemos ver esto mirando las declaraciones capturadas al generar un plan real en Plan Explorer:
Podemos ver que se han recopilado más de 20,000 declaraciones, pero si ordenamos por filas estimadas o reales de forma descendente, encontramos que solo hay dos operaciones que manejan más de una fila. Lo cual está muy lejos de algunos de los métodos anteriores que provocan lecturas exponenciales debido a la lectura de las mismas filas anteriores una y otra vez para cada fila nueva.
Ahora, echemos un vistazo a las nuevas mejoras de ventanas en SQL Server 2012. En particular, ahora podemos calcular SUM OVER() y especificar un conjunto de filas relativas a la fila actual. Entonces, por ejemplo:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] RANGE UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date]; SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] ROWS UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date];
Estas dos consultas dan la misma respuesta, con totales acumulados correctos. Pero, ¿funcionan exactamente igual? Los planes sugieren que no. La versión con FILAS tiene un operador adicional, un proyecto de secuencia de 10 000 filas:
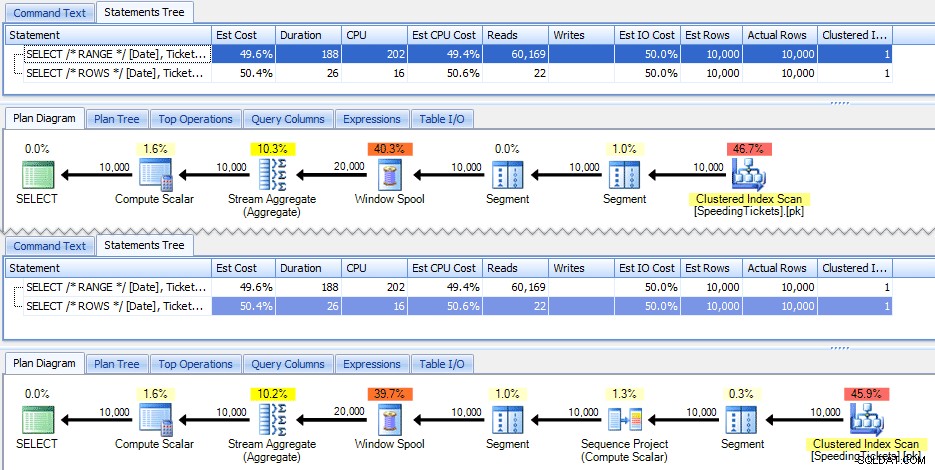
Y ese es el alcance de la diferencia en el plan gráfico. Pero si observa un poco más de cerca las métricas de tiempo de ejecución reales, verá pequeñas diferencias en la duración y la CPU, y una gran diferencia en las lecturas. ¿Por qué es esto? Bueno, esto se debe a que RANGE usa un spool en disco, mientras que ROWS usa un spool en memoria. Con conjuntos pequeños, la diferencia es probablemente insignificante, pero el costo de la bobina en disco ciertamente puede volverse más evidente a medida que los conjuntos aumentan. No quiero estropear el final, pero es posible que sospeches que una de estas soluciones funcionará mejor que la otra en una prueba más exhaustiva.
Aparte, la siguiente versión de la consulta arroja los mismos resultados, pero funciona como la versión RANGE más lenta anterior:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date]) FROM dbo.SpeedingTickets ORDER BY [Date];
Mientras juega con las nuevas funciones de ventana, querrá tener en cuenta pequeños detalles como este:la versión abreviada de una consulta, o la que haya escrito primero, no es necesariamente la que desea. para pasar a producción.
Las pruebas reales
Para realizar pruebas justas, creé un procedimiento almacenado para cada enfoque y medí los resultados capturando declaraciones en un servidor donde ya estaba monitoreando con SQL Sentry (si no está utilizando nuestra herramienta, puede recopilar eventos SQL:BatchCompleted de manera similar usando SQL Server Profiler).
Por "pruebas imparciales" me refiero a que, por ejemplo, el peculiar método de actualización requiere una actualización real de los datos estáticos, lo que significa cambiar el esquema subyacente o usar una tabla temporal/variable de tabla. Así que estructuré los procedimientos almacenados para que cada uno cree su propia variable de tabla y almacene los resultados allí, o almacene los datos sin procesar allí y luego actualice el resultado. El otro problema que quería eliminar era devolver los datos al cliente, por lo que cada uno de los procedimientos tiene un parámetro de depuración que especifica si no devolverá ningún resultado (predeterminado), 5 arriba/abajo o todos. En las pruebas de rendimiento, lo configuré para que no arrojara resultados, pero, por supuesto, validé cada uno para asegurarme de que arrojaban los resultados correctos.
Todos los procedimientos almacenados están modelados de esta manera (he adjuntado un script que crea la base de datos y los procedimientos almacenados, por lo que solo incluyo una plantilla aquí para abreviar):
CREATE PROCEDURE [dbo].[RunningTotals_]
@debug TINYINT = 0
-- @debug = 1 : show top/bottom 3
-- @debug = 2 : show all 50k
AS
BEGIN
SET NOCOUNT ON;
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
INSERT @st([Date], TicketCount, RunningTotal)
-- one of seven approaches used to populate @t
IF @debug = 1 -- show top 3 and last 3 to verify results
BEGIN
;WITH d AS
(
SELECT [Date], TicketCount, RunningTotal,
rn = ROW_NUMBER() OVER (ORDER BY [Date])
FROM @st
)
SELECT [Date], TicketCount, RunningTotal
FROM d
WHERE rn < 4 OR rn > 9997
ORDER BY [Date];
END
IF @debug = 2 -- show all
BEGIN
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date];
END
END
GO Y los llamé en un lote de la siguiente manera:
EXEC dbo.RunningTotals_DateCTE @debug = 0; GO EXEC dbo.RunningTotals_Cursor @debug = 0; GO EXEC dbo.RunningTotals_Subquery @debug = 0; GO EXEC dbo.RunningTotals_InnerJoin @debug = 0; GO EXEC dbo.RunningTotals_QuirkyUpdate @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Range @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; GO
Rápidamente me di cuenta de que algunas de estas llamadas no aparecían en Top SQL porque el umbral predeterminado es de 5 segundos. Lo cambié a 100 milisegundos (¡algo que nunca querrás hacer en un sistema de producción!) de la siguiente manera:
Repito:¡este comportamiento no está permitido para los sistemas de producción!
Todavía descubrí que uno de los comandos anteriores no estaba siendo atrapado por el umbral de SQL superior; era la versión Windowed_Rows. Así que agregué lo siguiente solo a ese lote:
EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; WAITFOR DELAY '00:00:01'; GO
Y ahora estaba obteniendo las 7 filas devueltas en Top SQL. Aquí están ordenados por uso de CPU de forma descendente:
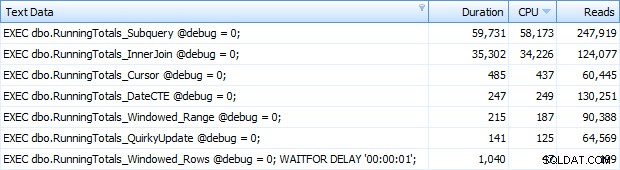
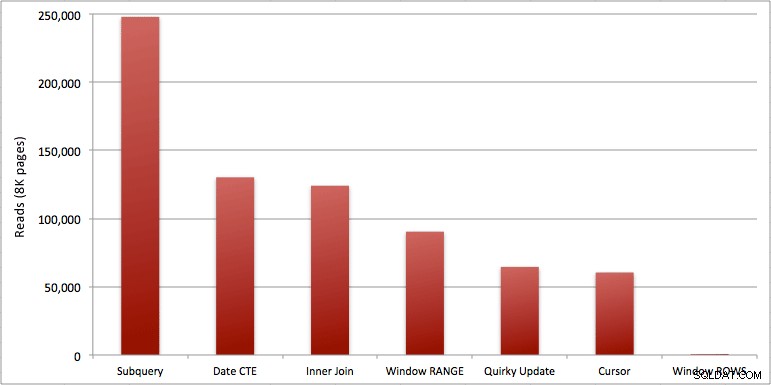
Puede ver el segundo adicional que agregué al lote Windowed_Rows; ¡no estaba siendo atrapado por el umbral de SQL superior porque se completó en solo 40 milisegundos! Este es claramente nuestro mejor desempeño y, si tenemos SQL Server 2012 disponible, debería ser el método que usamos. El cursor tampoco está nada mal, dado el rendimiento u otros problemas con las soluciones restantes. Trazar la duración en un gráfico no tiene mucho sentido:dos puntos altos y cinco puntos bajos indistinguibles. Pero si la E/S es su cuello de botella, puede encontrar interesante la visualización de lecturas:
Conclusión
De estos resultados podemos sacar algunas conclusiones:
- Los agregados en ventana en SQL Server 2012 hacen que los problemas de rendimiento con los cálculos de totales en ejecución (y muchos otros problemas de fila(s) siguiente/fila(s) anterior(es)) sean alarmantemente más eficientes. Cuando vi el bajo número de lecturas, pensé con certeza que había algún tipo de error, que debí haber olvidado realizar cualquier trabajo. Pero no, obtiene la misma cantidad de lecturas si su procedimiento almacenado solo realiza un SELECT ordinario de la tabla SpeedingTickets. (Siéntase libre de probar esto usted mismo con STATISTICS IO.)
- Los problemas que señalé anteriormente sobre RANGE vs. ROWS producen tiempos de ejecución ligeramente diferentes (diferencia de duración de aproximadamente 6x; recuerde ignorar el segundo que agregué con WAITFOR), pero las diferencias de lectura son astronómicas debido a la cola en disco. Si su agregado en ventana se puede resolver usando ROWS, evite RANGE, pero debe probar que ambos dan el mismo resultado (o al menos que ROWS da la respuesta correcta). También debe tener en cuenta que si está utilizando una consulta similar y no especifica RANGO ni FILAS, el plan funcionará como si hubiera especificado RANGO).
- Los métodos de subconsulta y combinación interna son relativamente malos. ¿De 35 segundos a un minuto para generar estos totales acumulados? Y esto fue en una sola mesa delgada sin devolver resultados al cliente. Estas comparaciones se pueden usar para mostrar a las personas por qué una solución puramente basada en conjuntos no siempre es la mejor respuesta.
- De los enfoques más rápidos, asumiendo que aún no está listo para SQL Server 2012, y asumiendo que descarta tanto el método de actualización peculiar (no compatible) como el método de fecha CTE (no se puede garantizar una secuencia contigua), solo el cursor funciona aceptablemente. Tiene la mayor duración de las soluciones "más rápidas", pero la menor cantidad de lecturas.
Espero que estas pruebas ayuden a apreciar mejor las mejoras de ventanas que Microsoft agregó a SQL Server 2012. Asegúrese de agradecer a Itzik si lo ve en línea o en persona, ya que él fue la fuerza impulsora detrás de estos cambios. Además, espero que esto ayude a abrir algunas mentes de que un cursor puede no ser siempre la solución malvada y temida que a menudo se representa.
(Como anexo, probé la función CLR ofrecida por Pavel Pawlowski, y las características de rendimiento fueron casi idénticas a las de la solución SQL Server 2012 usando ROWS. Las lecturas fueron idénticas, la CPU fue 78 frente a 47 y la duración general fue 73 en lugar de 40. Entonces, si no va a cambiarse a SQL Server 2012 en un futuro próximo, es posible que desee agregar la solución de Pavel a sus pruebas).
Archivos adjuntos:RunningTotals_Demo.sql.zip (2kb)