Las siete clases de implementación de clasificación de SQL Server son:
- CQScanSortNuevo
- CQScanTopSortNuevo
- CQScanIndexSortNuevo
- CQScanPartitionSortNew (solo SQL Server 2014)
- CQScanInMemSortNuevo
- In-Memory OLTP (Hekaton) procedimiento compilado de forma nativa Top N Sort (solo SQL Server 2014)
- In-Memory OLTP (Hekaton) procedimiento compilado de forma nativa Ordenación general (solo SQL Server 2014)
Los primeros cuatro tipos se cubrieron en la primera parte de este artículo.
5. CQScanInMemOrdenarNuevo
Esta clase de clasificación tiene una serie de características interesantes, algunas de ellas únicas:
- Como sugiere el nombre, siempre se ordena por completo en la memoria; nunca se extenderá a tempdb
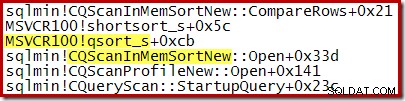
- La clasificación siempre se realiza mediante quicksort qsort_s en la biblioteca de tiempo de ejecución C estándar MSVCR100
- Puede realizar los tres tipos de clasificación lógica:General, Top N y Distinct Sort
- Se puede usar para clasificaciones suaves por partición de almacén de columnas agrupadas (consulte la sección 4 en la parte 1)
- La memoria que usa puede almacenarse en caché con el plan en lugar de reservarse justo antes de la ejecución
- Se puede identificar como una ordenación en memoria en los planes de ejecución.
- Se puede ordenar un máximo de 500 valores
- Nunca se usa para ordenaciones de creación de índices (consulte la sección 3 en la parte 1)
CQScanInMemSortNuevo es una clase de clasificación que no encontrará a menudo. Dado que siempre ordena en la memoria utilizando un algoritmo de ordenación rápida de biblioteca estándar, no sería una buena opción para las tareas generales de ordenación de bases de datos. De hecho, esta clase de clasificación solo se usa cuando todas sus entradas son constantes de tiempo de ejecución (incluidas las referencias @variable). Desde la perspectiva del plan de ejecución, eso significa que la entrada al operador Ordenar debe ser un Escaneo constante operador, como demuestran los siguientes ejemplos:
-- Regular Sort on system scalar functions
SELECT X.i
FROM
(
SELECT @@TIMETICKS UNION ALL
SELECT @@TOTAL_ERRORS UNION ALL
SELECT @@TOTAL_READ UNION ALL
SELECT @@TOTAL_WRITE
) AS X (i)
ORDER BY X.i;
-- Distinct Sort on constant literals
WITH X (i) AS
(
SELECT 3 UNION ALL
SELECT 1 UNION ALL
SELECT 1 UNION ALL
SELECT 2
)
SELECT DISTINCT X.i
FROM X
ORDER BY X.i;
-- Top N Sort on variables, constants, and functions
DECLARE
@x integer = 1,
@y integer = 2;
SELECT TOP (1)
X.i
FROM
(
VALUES
(@x), (@y), (123),
(@@CONNECTIONS)
) AS X (i)
ORDER BY X.i; Los planes de ejecución son:
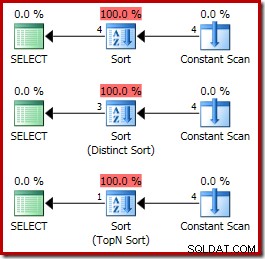
A continuación se muestra una pila de llamadas típica durante la clasificación. Observe la llamada a qsort_s en la biblioteca MSVCR100:
Los tres planes de ejecución que se muestran arriba son ordenaciones en memoria usando CQScanInMemSortNew con entradas lo suficientemente pequeñas para que la memoria de clasificación se almacene en caché. Esta información no se expone de forma predeterminada en los planes de ejecución, pero se puede revelar mediante el indicador de seguimiento no documentado 8666. Cuando ese indicador está activo, aparecen propiedades adicionales para el operador Ordenar:
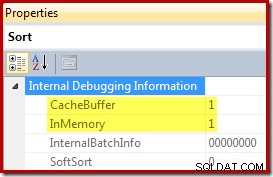
El búfer de caché está limitado a 62 filas en este ejemplo, como se muestra a continuación:
-- Cache buffer limited to 62 rows
SELECT X.i
FROM
(
VALUES
(001),(002),(003),(004),(005),(006),(007),(008),(009),(010),
(011),(012),(013),(014),(015),(016),(017),(018),(019),(020),
(021),(022),(023),(024),(025),(026),(027),(028),(029),(030),
(031),(032),(033),(034),(035),(036),(037),(038),(039),(040),
(041),(042),(043),(044),(045),(046),(047),(048),(049),(050),
(051),(052),(053),(054),(055),(056),(057),(058),(059),(060),
(061),(062)--, (063)
) AS X (i)
ORDER BY X.i; Quite el comentario del elemento final en ese script para ver el cambio de la propiedad Ordenar búfer de caché de 1 a 0:
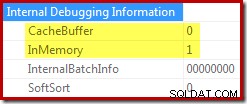
Cuando el búfer no se almacena en caché, la ordenación en memoria debe asignar memoria a medida que se inicializa y según sea necesario a medida que lee las filas de su entrada. Cuando se puede usar un búfer almacenado en caché, se evita este trabajo de asignación de memoria.
El siguiente script se puede usar para demostrar que el número máximo de elementos para un CQScanInMemSortNew ordenación rápida en memoria es 500:
SELECT X.i
FROM
(
VALUES
(001),(002),(003),(004),(005),(006),(007),(008),(009),(010),
(011),(012),(013),(014),(015),(016),(017),(018),(019),(020),
(021),(022),(023),(024),(025),(026),(027),(028),(029),(030),
(031),(032),(033),(034),(035),(036),(037),(038),(039),(040),
(041),(042),(043),(044),(045),(046),(047),(048),(049),(050),
(051),(052),(053),(054),(055),(056),(057),(058),(059),(060),
(061),(062),(063),(064),(065),(066),(067),(068),(069),(070),
(071),(072),(073),(074),(075),(076),(077),(078),(079),(080),
(081),(082),(083),(084),(085),(086),(087),(088),(089),(090),
(091),(092),(093),(094),(095),(096),(097),(098),(099),(100),
(101),(102),(103),(104),(105),(106),(107),(108),(109),(110),
(111),(112),(113),(114),(115),(116),(117),(118),(119),(120),
(121),(122),(123),(124),(125),(126),(127),(128),(129),(130),
(131),(132),(133),(134),(135),(136),(137),(138),(139),(140),
(141),(142),(143),(144),(145),(146),(147),(148),(149),(150),
(151),(152),(153),(154),(155),(156),(157),(158),(159),(160),
(161),(162),(163),(164),(165),(166),(167),(168),(169),(170),
(171),(172),(173),(174),(175),(176),(177),(178),(179),(180),
(181),(182),(183),(184),(185),(186),(187),(188),(189),(190),
(191),(192),(193),(194),(195),(196),(197),(198),(199),(200),
(201),(202),(203),(204),(205),(206),(207),(208),(209),(210),
(211),(212),(213),(214),(215),(216),(217),(218),(219),(220),
(221),(222),(223),(224),(225),(226),(227),(228),(229),(230),
(231),(232),(233),(234),(235),(236),(237),(238),(239),(240),
(241),(242),(243),(244),(245),(246),(247),(248),(249),(250),
(251),(252),(253),(254),(255),(256),(257),(258),(259),(260),
(261),(262),(263),(264),(265),(266),(267),(268),(269),(270),
(271),(272),(273),(274),(275),(276),(277),(278),(279),(280),
(281),(282),(283),(284),(285),(286),(287),(288),(289),(290),
(291),(292),(293),(294),(295),(296),(297),(298),(299),(300),
(301),(302),(303),(304),(305),(306),(307),(308),(309),(310),
(311),(312),(313),(314),(315),(316),(317),(318),(319),(320),
(321),(322),(323),(324),(325),(326),(327),(328),(329),(330),
(331),(332),(333),(334),(335),(336),(337),(338),(339),(340),
(341),(342),(343),(344),(345),(346),(347),(348),(349),(350),
(351),(352),(353),(354),(355),(356),(357),(358),(359),(360),
(361),(362),(363),(364),(365),(366),(367),(368),(369),(370),
(371),(372),(373),(374),(375),(376),(377),(378),(379),(380),
(381),(382),(383),(384),(385),(386),(387),(388),(389),(390),
(391),(392),(393),(394),(395),(396),(397),(398),(399),(400),
(401),(402),(403),(404),(405),(406),(407),(408),(409),(410),
(411),(412),(413),(414),(415),(416),(417),(418),(419),(420),
(421),(422),(423),(424),(425),(426),(427),(428),(429),(430),
(431),(432),(433),(434),(435),(436),(437),(438),(439),(440),
(441),(442),(443),(444),(445),(446),(447),(448),(449),(450),
(451),(452),(453),(454),(455),(456),(457),(458),(459),(460),
(461),(462),(463),(464),(465),(466),(467),(468),(469),(470),
(471),(472),(473),(474),(475),(476),(477),(478),(479),(480),
(481),(482),(483),(484),(485),(486),(487),(488),(489),(490),
(491),(492),(493),(494),(495),(496),(497),(498),(499),(500)
--, (501)
) AS X (i)
ORDER BY X.i; Nuevamente, descomente el último elemento para ver el InMemory La propiedad de clasificación cambia de 1 a 0. Cuando esto sucede, CQScanInMemSortNew se reemplaza por CQScanSortNew (ver sección 1) o CQScanTopSortNew (sección 2). Un no CQScanInMemSortNew la ordenación aún se puede realizar en la memoria, por supuesto, solo usa un algoritmo diferente y se le permite pasar a tempdb si es necesario.
6. Procedimiento almacenado compilado de forma nativa OLTP en memoria Top N Sort
La implementación actual de procedimientos almacenados compilados de forma nativa OLTP en memoria (anteriormente con el nombre en código Hekaton) utiliza una cola de prioridad seguida de qsort_s para Top N Sorts, cuando se cumplen las siguientes condiciones:
- La consulta contiene TOP (N) con una cláusula ORDER BY
- El valor de N es un literal constante (no una variable)
- N tiene un valor máximo de 8192; aunque
- La presencia de uniones o agregaciones puede reducir el valor 8192 como se documenta aquí
El siguiente código crea una tabla Hekaton que contiene 4000 filas:
CREATE DATABASE InMemoryOLTP;
GO
-- Add memory optimized filegroup
ALTER DATABASE InMemoryOLTP
ADD FILEGROUP InMemoryOLTPFileGroup
CONTAINS MEMORY_OPTIMIZED_DATA;
GO
-- Add file (adjust path if necessary)
ALTER DATABASE InMemoryOLTP
ADD FILE
(
NAME = N'IMOLTP',
FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.SQL2014\MSSQL\DATA\IMOLTP.hkf'
)
TO FILEGROUP InMemoryOLTPFileGroup;
GO
USE InMemoryOLTP;
GO
CREATE TABLE dbo.Test
(
col1 integer NOT NULL,
col2 integer NOT NULL,
col3 integer NOT NULL,
CONSTRAINT PK_dbo_Test
PRIMARY KEY NONCLUSTERED HASH (col1)
WITH (BUCKET_COUNT = 8192)
)
WITH
(
MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_ONLY
);
GO
-- Add numbers from 1-4000 using
-- Itzik Ben-Gan's number generator
WITH
L0 AS (SELECT 1 AS c UNION ALL SELECT 1),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
INSERT dbo.Test
(col1, col2, col3)
SELECT
N.n,
ABS(CHECKSUM(NEWID())),
ABS(CHECKSUM(NEWID()))
FROM Nums AS N
WHERE N.n BETWEEN 1 AND 4000; La siguiente secuencia de comandos crea un Top N Sort adecuado en un procedimiento almacenado compilado de forma nativa:
-- Natively-compiled Top N Sort stored procedure
CREATE PROCEDURE dbo.TestP
WITH EXECUTE AS OWNER, SCHEMABINDING, NATIVE_COMPILATION
AS
BEGIN ATOMIC
WITH
(
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'us_english'
)
SELECT TOP (2) T.col2
FROM dbo.Test AS T
ORDER BY T.col2
END;
GO
EXECUTE dbo.TestP; El plan de ejecución estimado es:

Una pila de llamadas capturada durante la ejecución muestra la inserción en la cola de prioridad en curso:

Una vez que se completa la construcción de la cola de prioridad, la siguiente pila de llamadas muestra un paso final a través de la ordenación rápida de la biblioteca estándar:
El xtp_p_* La biblioteca que se muestra en esas pilas de llamadas es el dll compilado de forma nativa para el procedimiento almacenado, con el código fuente guardado en la instancia local de SQL Server. El código fuente se genera automáticamente a partir de la definición del procedimiento almacenado. Por ejemplo, el archivo C para este procedimiento almacenado nativo contiene el siguiente fragmento:
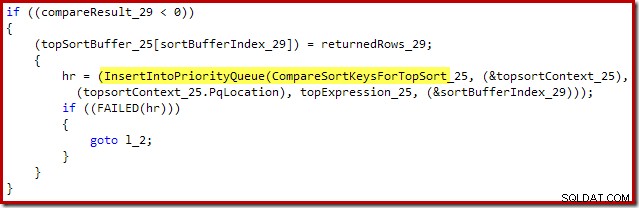
Esto es lo más cerca que podemos estar de tener acceso al código fuente de SQL Server.
7. Clasificación de procedimiento almacenado compilado de forma nativa de OLTP en memoria
Actualmente, los procedimientos compilados de forma nativa no admiten la ordenación diferenciada, pero sí la ordenación general no diferenciada, sin restricciones en el tamaño del conjunto. Para demostrarlo, primero agregaremos 6000 filas a la tabla de prueba, dando un total de 10 000 filas:
WITH
L0 AS (SELECT 1 AS c UNION ALL SELECT 1),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
INSERT dbo.Test
(col1, col2, col3)
SELECT
N.n,
ABS(CHECKSUM(NEWID())),
ABS(CHECKSUM(NEWID()))
FROM Nums AS N
WHERE N.n BETWEEN 4001 AND 10000; Ahora podemos descartar el procedimiento de prueba anterior (los procedimientos compilados de forma nativa no se pueden modificar actualmente) y crear uno nuevo que realice una ordenación ordinaria (no top-n) de las 10 000 filas:
DROP PROCEDURE dbo.TestP;
GO
CREATE PROCEDURE dbo.TestP
WITH EXECUTE AS OWNER, SCHEMABINDING, NATIVE_COMPILATION
AS
BEGIN ATOMIC
WITH
(
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'us_english'
)
SELECT T.col2
FROM dbo.Test AS T
ORDER BY T.col2
END;
GO
EXECUTE dbo.TestP; El plan de ejecución estimado es:

El seguimiento de la ejecución de esta ordenación muestra que comienza generando varias ejecuciones ordenadas pequeñas utilizando de nuevo la ordenación rápida de la biblioteca estándar:
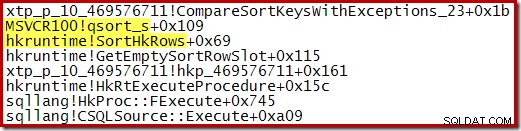
Una vez que se completa ese proceso, las ejecuciones ordenadas se fusionan, utilizando un esquema de cola de prioridad:
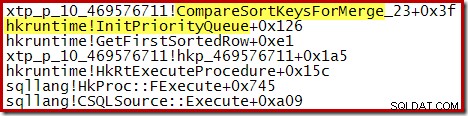
Nuevamente, el código fuente C para el procedimiento muestra algunos de los detalles:
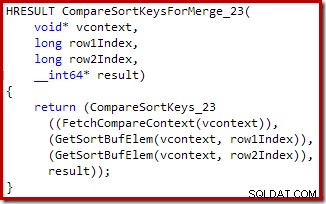
Resumen de la Parte 2
- CQScanInMemSortNuevo es siempre una ordenación rápida en memoria. Está limitado a 500 filas de un escaneo constante y puede almacenar en caché su memoria de clasificación para entradas pequeñas. Una clasificación se puede identificar como CQScanInMemSortNew ordenar usando las propiedades del plan de ejecución expuestas por el indicador de rastreo 8666.
- La ordenación N superior compilada nativa de Hekaton requiere un valor literal constante para N <=8192 y ordena usando una cola de prioridad seguida de una ordenación rápida estándar
- La clasificación general compilada de forma nativa de Hekaton puede ordenar cualquier número de filas, utilizando la clasificación rápida de la biblioteca estándar para generar ejecuciones de clasificación y una ordenación de combinación de cola de prioridad para combinar ejecuciones. No es compatible con Distinct Sort.