SQL Server 2008 introdujo columnas dispersas como método para reducir el almacenamiento de valores nulos y proporcionar esquemas más extensibles. La compensación es que hay una sobrecarga adicional cuando almacena y recupera valores que no son NULL. Estaba interesado en comprender el costo de almacenar valores que no son NULL, después de hablar con un cliente que estaba usando este tipo de datos en un entorno de prueba. Buscan optimizar el rendimiento de escritura y me preguntaba si el uso de columnas dispersas tenía algún efecto, ya que su método requería insertar una fila en la tabla y luego actualizarla. Creé un ejemplo artificial para esta demostración, que se explica a continuación, para determinar si esta era una buena metodología para que la usaran.
Revisión interna
Como revisión rápida, recuerde que cuando crea una columna para una tabla que permite valores NULL, si es una columna de longitud fija (por ejemplo, un INT), siempre consumirá todo el ancho de la columna en la página, incluso cuando la columna esté NULO. Si es una columna de longitud variable (por ejemplo, VARCHAR), consumirá al menos dos bytes en la matriz de desplazamiento de columna cuando sea NULL, a menos que las columnas estén después de la última columna poblada (consulte la publicación de blog de Kimberly El orden de las columnas no importa... generalmente , pero – DEPENDE). Una columna dispersa no requiere ningún espacio en la página para valores NULL, ya sea una columna de longitud fija o de longitud variable, e independientemente de qué otras columnas se completen en la tabla. La compensación es que cuando se llena una columna dispersa, se necesitan cuatro (4) bytes más de almacenamiento que una columna no dispersa. Por ejemplo:
| Tipo de columna | Requisito de almacenamiento |
|---|---|
| columna BIGINT, no dispersa, con no valor | 8 bytes |
| columna BIGINT, no dispersa, con un valor | 8 bytes |
| columna BIGINT, escasa, sin no valor | 0 bytes |
| columna BIGINT, escasa, con un valor | 12 bytes |
Por lo tanto, es esencial confirmar que el beneficio del almacenamiento supera el posible impacto en el rendimiento de la recuperación, que puede ser insignificante en función del equilibrio de lecturas y escrituras en los datos. El ahorro de espacio estimado para diferentes tipos de datos se documenta en el enlace de Libros en línea que se proporciona arriba.
Escenarios de prueba
Configuré cuatro escenarios diferentes para la prueba, que se describen a continuación, y cada tabla tenía una columna de ID (INT), una columna de Nombre (VARCHAR(100)) y una columna de Tipo (INT), y luego 997 columnas NULLABLE.
| ID de prueba | Descripción de la tabla | Operaciones DML |
|---|---|---|
| 1 | 997 columnas de tipo de datos INT, NULLABLE, no disperso | Insertar una fila a la vez, completando ID, Nombre, Tipo y diez (10) columnas aleatorias NULLABLE |
| 2 | 997 columnas de tipo de datos INT, NULLABLE, escasa | Insertar una fila a la vez, completando ID, Nombre, Tipo y diez (10) columnas aleatorias NULLABLE |
| 3 | 997 columnas de tipo de datos INT, NULLABLE, no disperso | Inserte una fila a la vez, completando ID, Nombre, Tipo solamente, luego actualice la fila, agregando valores para diez (10) columnas aleatorias NULLABLE |
| 4 | 997 columnas de tipo de datos INT, NULLABLE, escasa | Inserte una fila a la vez, completando ID, Nombre, Tipo solamente, luego actualice la fila, agregando valores para diez (10) columnas aleatorias NULLABLE |
| 5 | 997 columnas de tipo de datos VARCHAR, NULLABLE, no disperso | Insertar una fila a la vez, completando ID, Nombre, Tipo y diez (10) columnas aleatorias NULLABLE |
| 6 | 997 columnas de tipo de datos VARCHAR, NULLABLE, escasa | Insertar una fila a la vez, completando ID, Nombre, Tipo y diez (10) columnas aleatorias NULLABLE |
| 7 | 997 columnas de tipo de datos VARCHAR, NULLABLE, no disperso | Inserte una fila a la vez, completando ID, Nombre, Tipo solamente, luego actualice la fila, agregando valores para diez (10) columnas aleatorias NULLABLE |
| 8 | 997 columnas de tipo de datos VARCHAR, NULLABLE, escasa | Inserte una fila a la vez, completando ID, Nombre, Tipo solamente, luego actualice la fila, agregando valores para diez (10) columnas aleatorias NULLABLE |
Cada prueba se ejecutó dos veces con un conjunto de datos de 10 millones de filas. Los scripts adjuntos se pueden usar para replicar las pruebas, y los pasos fueron los siguientes para cada prueba:
- Cree una nueva base de datos con datos de tamaño predeterminado y archivos de registro
- Cree la tabla apropiada
- Estadísticas de espera de instantáneas y estadísticas de archivos
- Tenga en cuenta la hora de inicio
- Ejecute el DML (una inserción o una inserción y una actualización) para 10 millones de filas
- Tenga en cuenta la hora de parada
- Tome una instantánea de las estadísticas de espera y las estadísticas de archivo y escriba en una tabla de registro en una base de datos separada en un almacenamiento separado
- Instantánea dm_db_index_physical_stats
- Descartar la base de datos
La prueba se realizó en un Dell PowerEdge R720 con 64 GB de memoria y 12 GB asignados a la instancia SQL Server 2014 SP1 CU4. Se utilizaron SSD Fusion-IO para el almacenamiento de datos para los archivos de la base de datos.
Resultados
Los resultados de las pruebas se presentan a continuación para cada escenario de prueba.
Duración
En todos los casos, tomó menos tiempo (promedio de 11,6 minutos) completar la tabla cuando se usaron columnas dispersas, incluso cuando la fila se insertó por primera vez y luego se actualizó. Cuando la fila se insertó por primera vez y luego se actualizó, la prueba tardó casi el doble en ejecutarse en comparación con cuando se insertó la fila, ya que se ejecutaron el doble de modificaciones de datos.
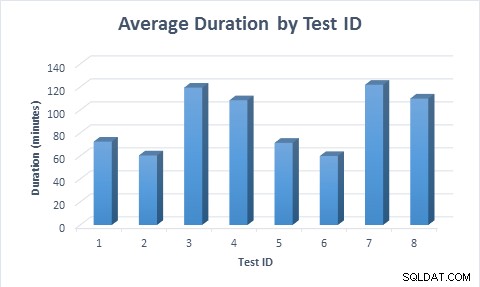 Duración promedio para cada escenario de prueba
Duración promedio para cada escenario de prueba
Estadísticas de espera
| ID de prueba | Porcentaje promedio | Espera promedio (segundos) |
|---|---|---|
| 1 | 16.47 | 0,0001 |
| 2 | 14.00 | 0,0001 |
| 3 | 16,65 | 0,0001 |
| 4 | 15.07 | 0,0001 |
| 5 | 12,80 | 0,0001 |
| 6 | 13,99 | 0,0001 |
| 7 | 14,85 | 0,0001 |
| 8 | 15.02 | 0,0001 |
Las estadísticas de espera fueron consistentes para todas las pruebas y no se pueden sacar conclusiones basadas en estos datos. El hardware satisfizo suficientemente las demandas de recursos en todos los casos de prueba.
Estadísticas de archivo
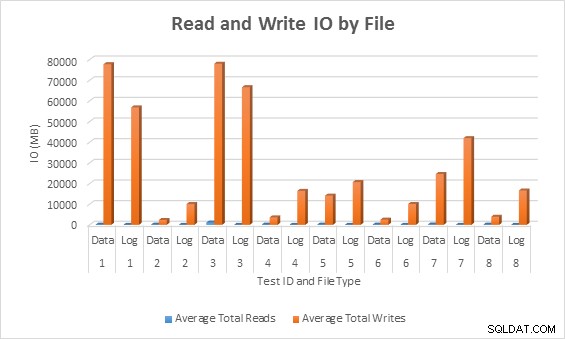 E/S promedio (lectura y escritura) por archivo de base de datos
E/S promedio (lectura y escritura) por archivo de base de datos
En todos los casos, las pruebas con columnas dispersas generaron menos IO (sobre todo escrituras) en comparación con las columnas no dispersas.
Estadísticas Físicas del Índice
| Caso de prueba | Recuento de filas | Recuento total de páginas (índice agrupado) | Espacio total (GB) | Espacio promedio utilizado para páginas de hoja en CI (%) | Tamaño promedio de registro (bytes) |
|---|---|---|---|---|---|
| 1 | 10,000,000 | 10,037,312 | 76 | 51,70 | 4184,49 |
| 2 | 10,000,000 | 301.429 | 2 | 98,51 | 237,50 |
| 3 | 10,000,000 | 10,037,312 | 76 | 51,70 | 4184,50 |
| 4 | 10,000,000 | 460.960 | 3 | 64.41 | 237,50 |
| 5 | 10,000,000 | 1,823,083 | 13 | 90.31 | 1326,08 |
| 6 | 10,000,000 | 324.162 | 2 | 98,40 | 255,28 |
| 7 | 10,000,000 | 3.161.224 | 24 | 52.09 | 1326,39 |
| 8 | 10,000,000 | 503.592 | 3 | 63,33 | 255,28 |
Existen diferencias significativas en el uso del espacio entre las tablas dispersas y no dispersas. Esto es más notable cuando se analizan los casos de prueba 1 y 3, donde se usó un tipo de datos de longitud fija (INT), en comparación con los casos de prueba 5 y 7, donde se usó un tipo de datos de longitud variable (VARCHAR(255)). Las columnas enteras consumen espacio en disco incluso cuando son NULL. Las columnas de longitud variable consumen menos espacio en disco, ya que solo se usan dos bytes en la matriz de desplazamiento para las columnas NULL y ningún byte para las columnas NULL que están después de la última columna poblada de la fila.
Además, el proceso de insertar una fila y luego actualizarla provoca la fragmentación de la prueba de columna de longitud variable (caso 7), en comparación con simplemente insertar la fila (caso 5). El tamaño de la tabla casi se duplica cuando la inserción va seguida de la actualización, debido a las divisiones de página que se producen al actualizar las filas, lo que deja las páginas medio llenas (frente al 90 % de su capacidad).
Resumen
En conclusión, observamos una reducción significativa en el espacio en disco y la E/S cuando se utilizan columnas dispersas, y funcionan un poco mejor que las columnas no dispersas en nuestras pruebas simples de modificación de datos (tenga en cuenta que también se debe considerar el rendimiento de recuperación; quizás el tema de otro publicación).
Las columnas dispersas tienen un escenario de uso muy específico y es importante examinar la cantidad de espacio en disco ahorrado, según el tipo de datos de la columna y la cantidad de columnas que normalmente se completarán en la tabla. En nuestro ejemplo, teníamos 997 columnas dispersas y solo completamos 10 de ellas. Como máximo, en el caso de que el tipo de datos utilizado fuera un número entero, una fila en el nivel de hoja del índice agrupado consumiría 188 bytes (4 bytes para el ID, 100 bytes como máximo para el Nombre, 4 bytes para el tipo y luego 80 bytes para 10 columnas). Cuando 997 columnas no eran dispersas, se asignaban 4 bytes para cada columna, incluso cuando eran NULL, por lo que cada fila tenía al menos 4000 bytes en el nivel de hoja. En nuestro escenario, las columnas dispersas son absolutamente aceptables. Pero si completamos 500 o más columnas dispersas con valores para una columna INT, entonces se pierde el ahorro de espacio y es posible que el rendimiento de la modificación ya no sea mejor.
Según el tipo de datos de sus columnas y la cantidad esperada de columnas que se completarán del total, es posible que desee realizar pruebas similares para asegurarse de que, al usar columnas dispersas, el rendimiento y el almacenamiento de inserción sean comparables o mejores que cuando se usan columnas no -columnas dispersas. Para los casos en los que no se completan todas las columnas, definitivamente vale la pena considerar las columnas dispersas.