La semana pasada, hice un par de comparaciones rápidas de rendimiento, comparando el nuevo STRING_AGG() función contra el tradicional FOR XML PATH enfoque que he utilizado durante siglos. Probé tanto el orden indefinido/arbitrario como el orden explícito y STRING_AGG() salió ganando en ambos casos:
- SQL Server v.Next:Rendimiento de STRING_AGG(), Parte 1
Para esas pruebas, omití varias cosas (no todas intencionalmente):
- Mikael Eriksson y Grzegorz Łyp señalaron que no estaba usando el
FOR XML PATHmás eficiente. construir (y para ser claros, nunca lo he hecho). - No realicé ninguna prueba en Linux; solo en Windows. No espero que sean muy diferentes, pero dado que Grzegorz vio duraciones muy diferentes, vale la pena investigar más a fondo.
- También probé solo cuando la salida sería una cadena finita, no LOB, que creo que es el caso de uso más común (no creo que las personas concatenen comúnmente cada fila en una tabla en una sola fila separada por comas). cadena, pero es por eso que pregunté en mi publicación anterior por su(s) caso(s) de uso).
- Para las pruebas de pedido, no creé un índice que pudiera ser útil (ni intenté nada donde todos los datos provinieran de una sola tabla).
En esta publicación, voy a tratar un par de estos elementos, pero no todos.
PARA RUTA XML
Estuve usando lo siguiente:
... FOR XML PATH, TYPE).value(N'.[1]', ...
Después de este comentario de Mikael, actualicé mi código para usar esta construcción ligeramente diferente en su lugar:
... FOR XML PATH(''), TYPE).value(N'text()[1]', ... Linux frente a Windows
Inicialmente, solo me había molestado en ejecutar pruebas en Windows:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. Developer Edition (64-bit) on Windows Server 2016 Datacenter 6.3(Build 14393: ) (Hypervisor)
Pero Grzegorz señaló claramente que él (y presumiblemente muchos otros) solo tenían acceso a la versión Linux de CTP 1.1. Así que agregué Linux a mi matriz de prueba:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. on Linux (Ubuntu 16.04.1 LTS)
Algunas observaciones interesantes pero completamente tangenciales:
@@VERSIONno muestra la edición en esta compilación, peroSERVERPROPERTY('Edition')devuelve laDeveloper Edition (64-bit)esperada .- Según los tiempos de compilación codificados en los archivos binarios, parece que las versiones de Windows y Linux ahora se compilan al mismo tiempo y desde la misma fuente. O esto fue una loca coincidencia.
Pruebas desordenadas
Comencé probando la salida ordenada arbitrariamente (donde no hay un orden definido explícitamente para los valores concatenados). Siguiendo a Grzegorz, usé WideWorldImporters (Standard), pero realicé una unión entre Sales.Orders y Sales.OrderLines . El requisito ficticio aquí es generar una lista de todos los pedidos y, junto con cada pedido, una lista separada por comas de cada StockItemID .
Desde StockItemID es un número entero, podemos usar un varchar definido , lo que significa que la cadena puede tener 8000 caracteres antes de que tengamos que preocuparnos por necesitar MAX. Dado que un int puede tener una longitud máxima de 11 (realmente 10, si no está firmado), más una coma, esto significa que un pedido debería admitir alrededor de 8000/12 (666) artículos en stock en el peor de los casos (por ejemplo, todos los valores de StockItemID tienen 11 dígitos). En nuestro caso, la identificación más larga es de 3 dígitos, por lo que hasta que se agreguen los datos, en realidad necesitaríamos 8000/4 (2000) artículos únicos en stock en cualquier pedido para justificar MAX. En nuestro caso, solo hay 227 artículos en stock en total, por lo que MAX no es necesario, pero debe vigilarlo. Si una cadena tan grande es posible en su escenario, deberá usar varchar(max) en lugar del predeterminado (STRING_AGG() devuelve nvarchar(max) , pero se trunca a 8000 bytes a menos que la entrada es un tipo MAX).
Las consultas iniciales (para mostrar resultados de muestra y observar duraciones para ejecuciones individuales):
SET STATISTICS TIME ON;
GO
SELECT o.OrderID, StockItemIDs = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT o.OrderID,
StockItemIDs = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Sample output:
OrderID StockItemIDs
======= ============
1 67
2 50,10
3 114
4 206,130,50
5 128,121,155
Important SET STATISTICS TIME metrics (SQL Server Execution Times):
Windows:
STRING_AGG: CPU time = 217 ms, elapsed time = 405 ms.
FOR XML PATH: CPU time = 1954 ms, elapsed time = 2097 ms.
Linux:
STRING_AGG: CPU time = 627 ms, elapsed time = 472 ms.
FOR XML PATH: CPU time = 2188 ms, elapsed time = 2223 ms.
*/
Ignoré los datos de tiempo de análisis y compilación por completo, ya que siempre eran exactamente cero o lo suficientemente cerca como para ser irrelevantes. Hubo variaciones menores en los tiempos de ejecución para cada ejecución, pero no mucho:los comentarios anteriores reflejan el delta típico en tiempo de ejecución (STRING_AGG parecía aprovechar un poco el paralelismo allí, pero solo en Linux, mientras que FOR XML PATH no en ninguna de las dos plataformas). Ambas máquinas tenían un solo socket, CPU de cuatro núcleos asignada, 8 GB de memoria, configuración lista para usar y ninguna otra actividad.
Luego quise probar a escala (simplemente una sola sesión ejecutando la misma consulta 500 veces). No quería devolver todo el resultado, como en la consulta anterior, 500 veces, ya que eso habría abrumado a SSMS y, con suerte, no representa escenarios de consulta del mundo real de todos modos. Así que asigné la salida a las variables y solo medí el tiempo total para cada lote:
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID, @x = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID,
@x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Realicé esas pruebas tres veces y la diferencia fue profunda, casi un orden de magnitud. Esta es la duración promedio de las tres pruebas:
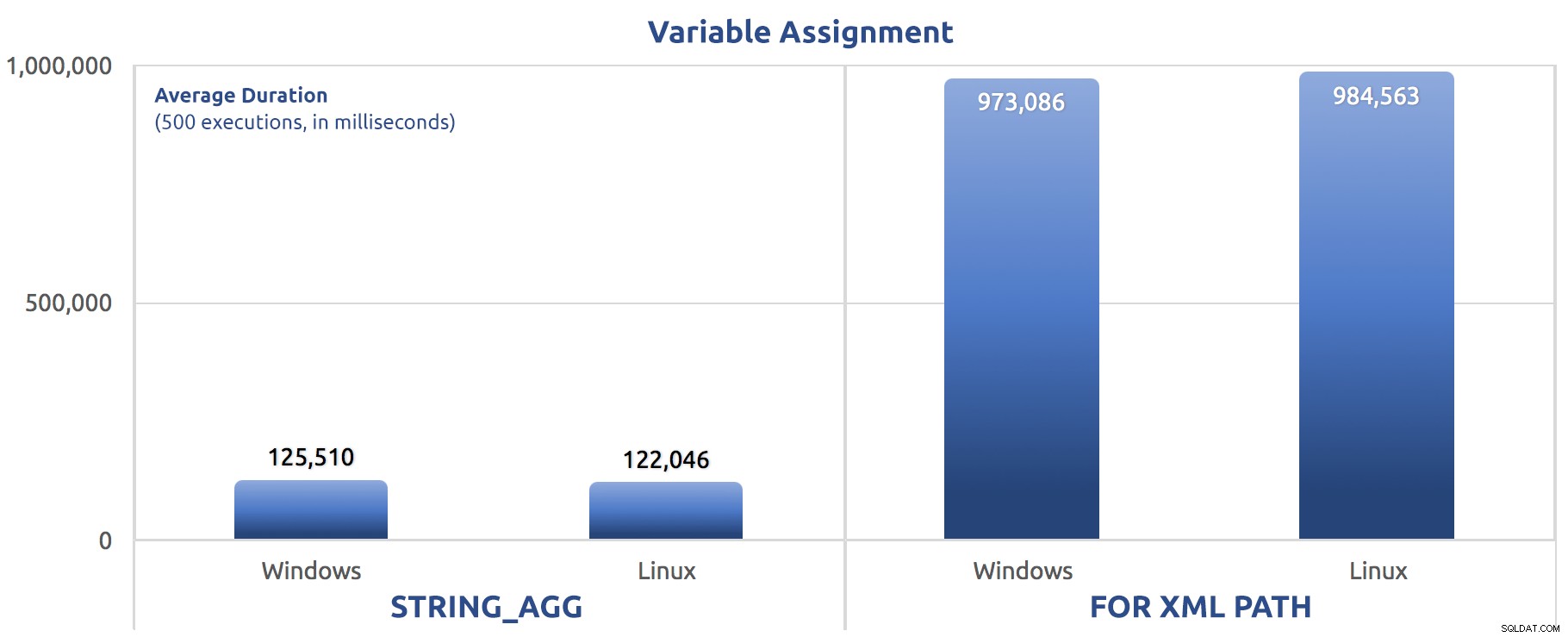 Duración promedio, en milisegundos, para 500 ejecuciones de asignación de variables
Duración promedio, en milisegundos, para 500 ejecuciones de asignación de variables
También probé una variedad de otras cosas de esta manera, principalmente para asegurarme de que estaba cubriendo los tipos de pruebas que Grzegorz estaba ejecutando (sin la parte LOB).
- Seleccionar solo la longitud de la salida
- Obtener la longitud máxima de la salida (de una fila arbitraria)
- Seleccionar toda la salida en una nueva tabla
Seleccionar solo la longitud de la salida
Este código simplemente se ejecuta a través de cada pedido, concatena todos los valores de StockItemID y luego devuelve solo la longitud.
SET STATISTICS TIME ON;
GO
SELECT LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 142 ms, elapsed time = 351 ms.
FOR XML PATH: CPU time = 1984 ms, elapsed time = 2120 ms.
Linux:
STRING_AGG: CPU time = 310 ms, elapsed time = 191 ms.
FOR XML PATH: CPU time = 2149 ms, elapsed time = 2167 ms.
*/ Para la versión por lotes, nuevamente, usé la asignación de variables, en lugar de intentar devolver muchos conjuntos de resultados a SSMS. La asignación de la variable terminaría en una fila arbitraria, pero esto aún requiere escaneos completos, porque la fila arbitraria no se selecciona primero.
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Métricas de rendimiento de 500 ejecuciones:
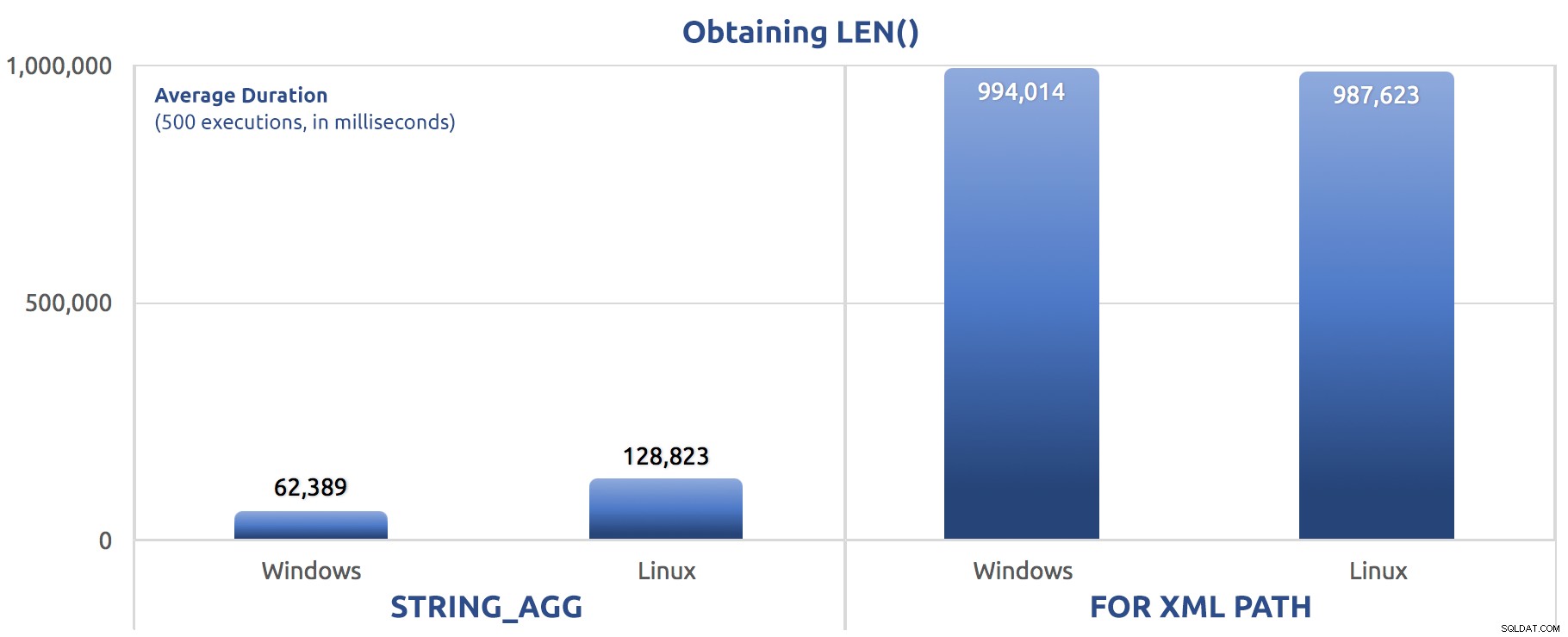 500 ejecuciones de asignación de LEN() a una variable
500 ejecuciones de asignación de LEN() a una variable
Nuevamente, vemos FOR XML PATH es mucho más lento, tanto en Windows como en Linux.
Seleccionar la longitud máxima de la salida
Una ligera variación de la prueba anterior, esta solo recupera el máximo longitud de la salida concatenada:
SET STATISTICS TIME ON;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STUFF(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 188 ms, elapsed time = 48 ms.
FOR XML PATH: CPU time = 1891 ms, elapsed time = 907 ms.
Linux:
STRING_AGG: CPU time = 270 ms, elapsed time = 83 ms.
FOR XML PATH: CPU time = 2725 ms, elapsed time = 1205 ms.
*/ Y a escala, simplemente volvemos a asignar esa salida a una variable:
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STUFF
(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime(); Resultados de rendimiento, para 500 ejecuciones, promediadas en tres ejecuciones:
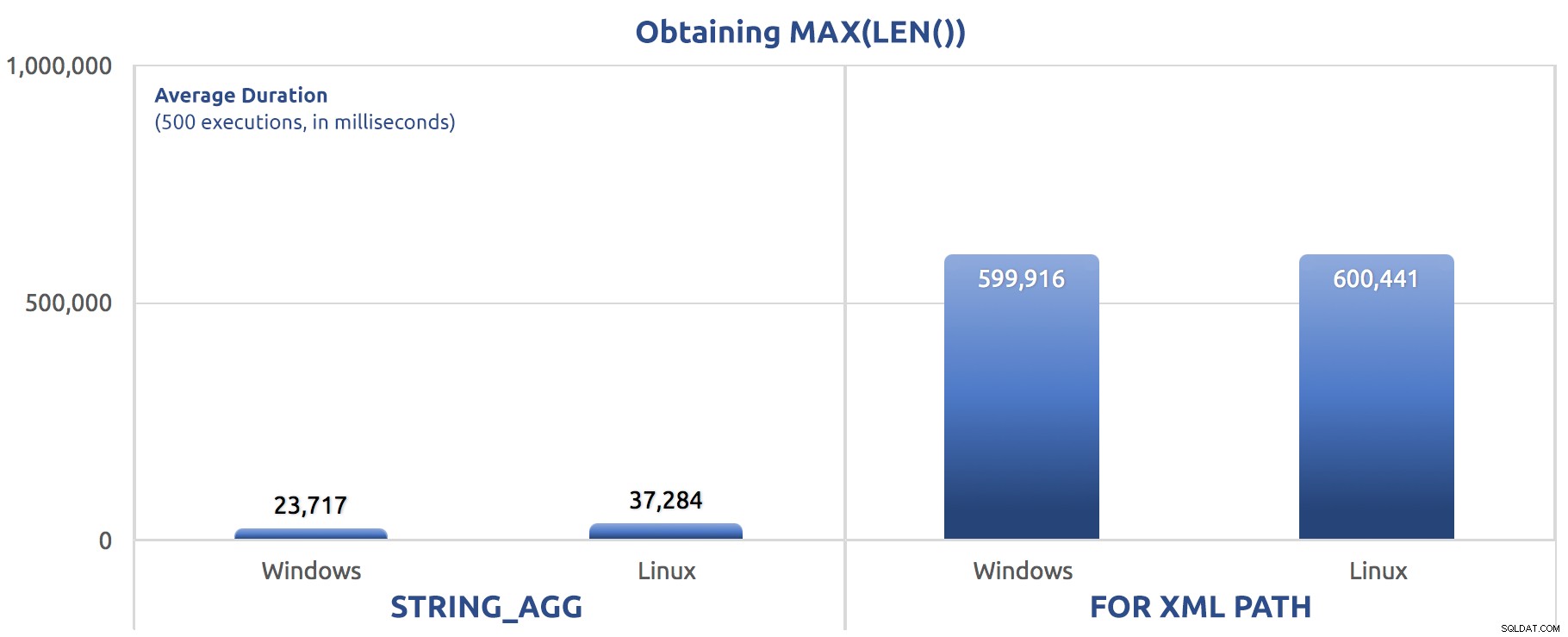 500 ejecuciones de asignación de MAX(LEN()) a una variable
500 ejecuciones de asignación de MAX(LEN()) a una variable
Es posible que comience a notar un patrón en estas pruebas:FOR XML PATH siempre es un perro, incluso con las mejoras de rendimiento sugeridas en mi publicación anterior.
SELECCIONAR EN
Quería ver si el método de concatenación tenía algún impacto en la escritura los datos de vuelta al disco, como es el caso en algunos otros escenarios:
SET NOCOUNT ON;
GO
SET STATISTICS TIME ON;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_AGG;
SELECT o.OrderID, x = STRING_AGG(ol.StockItemID, ',')
INTO dbo.HoldingTank_AGG
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_XML;
SELECT o.OrderID, x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
INTO dbo.HoldingTank_XML
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 218 ms, elapsed time = 90 ms.
FOR XML PATH: CPU time = 4202 ms, elapsed time = 1520 ms.
Linux:
STRING_AGG: CPU time = 277 ms, elapsed time = 108 ms.
FOR XML PATH: CPU time = 4308 ms, elapsed time = 1583 ms.
*/
En este caso vemos que quizás SELECT INTO pudo aprovechar un poco de paralelismo, pero aún vemos FOR XML PATH lucha, con tiempos de ejecución un orden de magnitud más largos que STRING_AGG .
La versión por lotes acaba de cambiar los comandos SET STATISTICS por SELECT sysdatetime(); y agregó el mismo GO 500 después de los dos lotes principales como en las pruebas anteriores. Así es como resultó (nuevamente, dime si has escuchado esto antes):
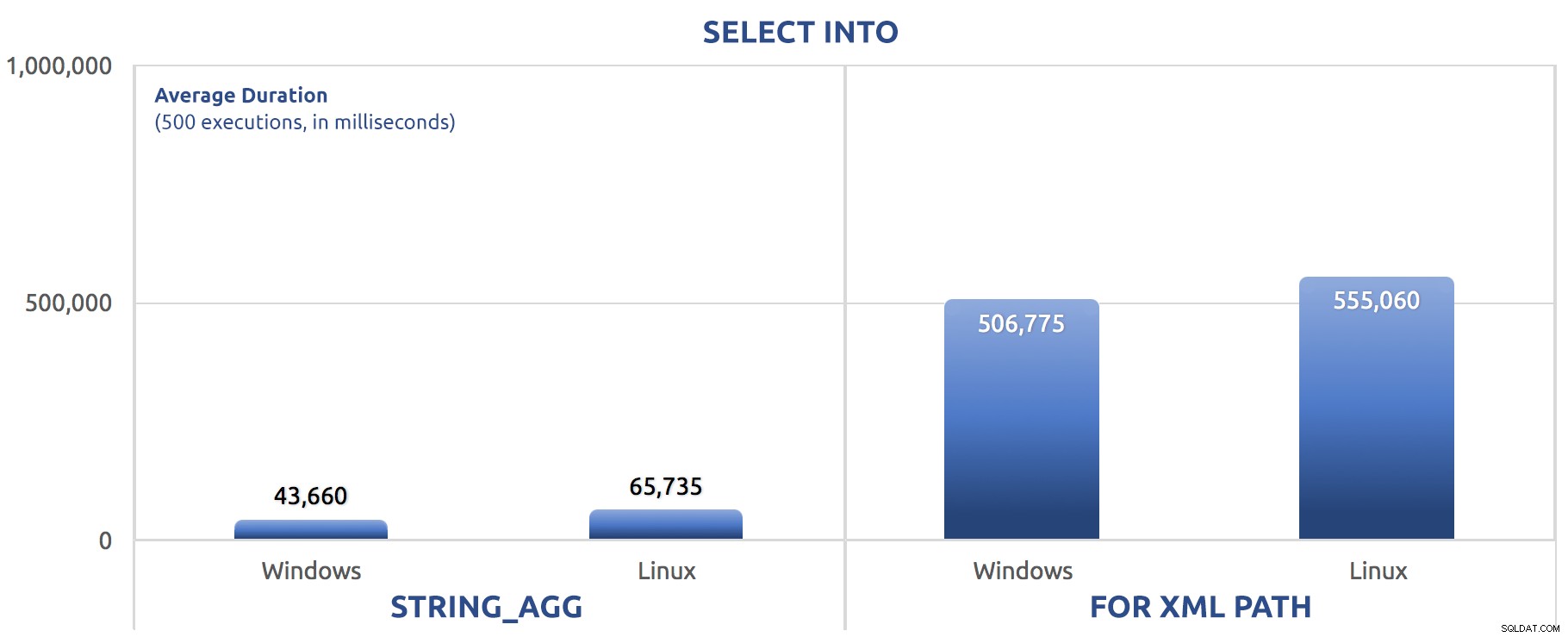 500 ejecuciones de SELECT INTO
500 ejecuciones de SELECT INTO
Pruebas ordenadas
Ejecuté las mismas pruebas usando la sintaxis ordenada, por ejemplo:
... STRING_AGG(ol.StockItemID, ',')
WITHIN GROUP (ORDER BY ol.StockItemID) ...
... WHERE ol.OrderID = o.OrderID
ORDER BY ol.StockItemID
FOR XML PATH('') ... Esto tuvo muy poco impacto en nada:el mismo conjunto de cuatro plataformas de prueba mostró métricas y patrones casi idénticos en todos los ámbitos.
Tendré curiosidad por ver si esto es diferente cuando la salida concatenada no es LOB o cuando la concatenación necesita ordenar cadenas (con o sin un índice de soporte).
Conclusión
Para cadenas que no sean LOB , me queda claro que STRING_AGG tiene una ventaja de rendimiento definitiva sobre FOR XML PATH , tanto en Windows como en Linux. Tenga en cuenta que, para evitar el requisito de varchar(max) o nvarchar(max) , no usé nada similar a las pruebas que ejecutó Grzegorz, lo que habría significado simplemente concatenar todos los valores de una columna, en toda una tabla, en una sola cadena. En mi próxima publicación, analizaré el caso de uso en el que la salida de la cadena concatenada podría ser superior a 8000 bytes, por lo que se tendrían que utilizar tipos LOB y conversiones.