Hola,
El uso de Index en la base de datos de SQL Server ocurre en entornos que requieren el mayor rendimiento, velocidad y ahorro de memoria.
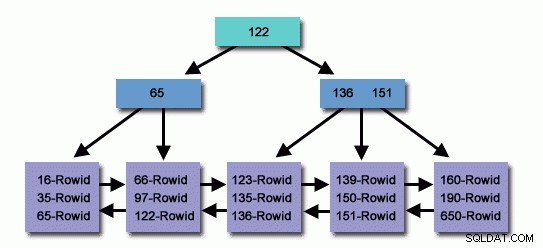
En una tabla con millones o miles de millones de registros, podemos usar un Índice para leer menos registros y buscar menos para encontrar registros relacionados.
Índice creado con precisión, millones de registros dentro de la base de datos que hemos buscado en muy poco tiempo para traer el registro de la conveniencia de la persona que llama, mientras que al mismo tiempo leemos menos el registro al alcanzar el registro de destino, usamos los recursos del sistema operativo de manera efectiva.
Debe crear un índice para la mayoría de las consultas de solo lectura en una tabla. Si eliminar, las operaciones de actualización son más que consultas de solo lectura, no debe crear un índice de esa tabla.
Puede ver la recomendación de índice faltante de SQL Server con el siguiente script. Puede crear un índice faltante, pero debe monitorear estos índices. Si no son útiles, debe eliminarlos.
SELECT MID.[statement] AS ObjectName
,MID.equality_columns AS EqualityColumns
,MID.inequality_columns AS InequalityColms
,MID.included_columns AS IncludedColumns
,MIGS.last_user_seek AS LastUserSeek
,MIGS.avg_total_user_cost
* MIGS.avg_user_impact
* (MIGS.user_seeks + MIGS.user_scans) AS Impact
,N'CREATE NONCLUSTERED INDEX <TYPE_Index_Name> ' +
N'ON ' + MID.[statement] +
N' (' + MID.equality_columns
+ ISNULL(', ' + MID.inequality_columns, N'') +
N') ' + ISNULL(N'INCLUDE (' + MID.included_columns + N');', ';')
AS CreateStatement
FROM sys.dm_db_missing_index_group_stats AS MIGS
INNER JOIN sys.dm_db_missing_index_groups AS MIG
ON MIGS.group_handle = MIG.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS MID
ON MIG.index_handle = MID.index_handle
WHERE database_id = DB_ID()
AND MIGS.last_user_seek >= DATEDIFF(month, GetDate(), -1)
ORDER BY Impact DESC;