Completamente de acuerdo con @PaulStock en que es mejor dejar los agregados en los sistemas de origen. Un agregado en SSIS es un componente de bloqueo completo muy parecido a una ordenación y he ya expliqué mi argumento sobre ese punto .
Pero hay momentos en los que hacer esas operaciones en el sistema de origen simplemente no va a funcionar. Lo mejor que he podido encontrar es básicamente duplicar el procesamiento de los datos. Sí, ick, pero nunca pude encontrar una manera de pasar una columna sin verse afectada. Para escenarios Mín./Máx., lo querría como una opción, pero obviamente algo como una Suma dificultaría que el componente supiera a qué fila de "origen" se vincularía.
2005
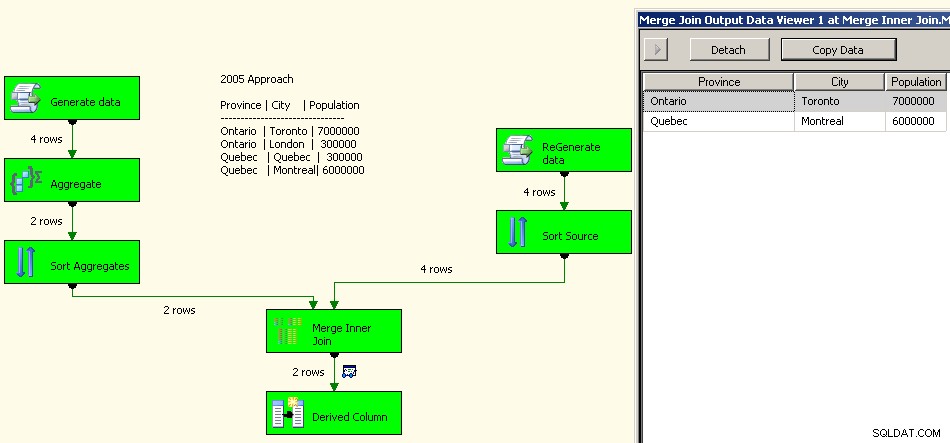
Una implementación de 2005 se vería así. Su rendimiento no va a ser bueno, de hecho, algunos órdenes de magnitud de bueno, ya que tendrá todas estas transformaciones de bloqueo allí además de tener que volver a procesar sus datos de origen.
fusionar unirse 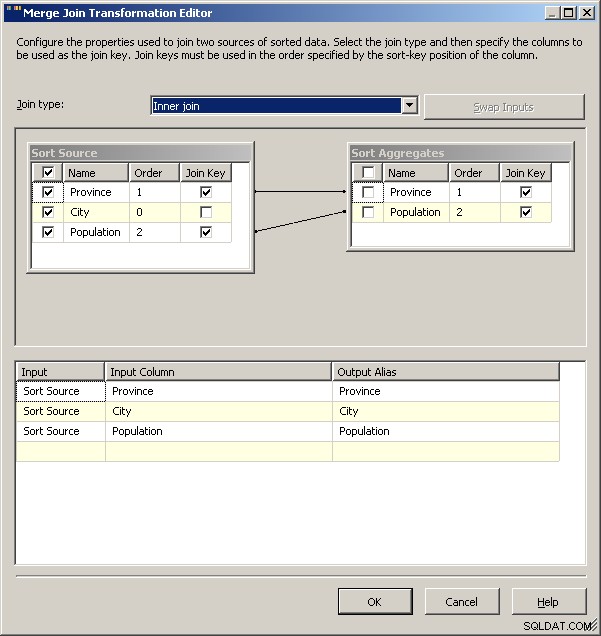
2008
En 2008, tiene la opción de usar el Administrador de conexión de caché lo que ayudaría a eliminar las transformaciones de bloqueo, al menos donde importa, pero aún tendrá que pagar el costo del doble procesamiento de sus datos de origen.
Arrastre dos flujos de datos al lienzo. El primero llenará el administrador de conexión de caché y debería estar donde se lleva a cabo el agregado.
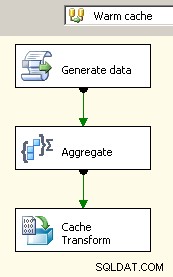
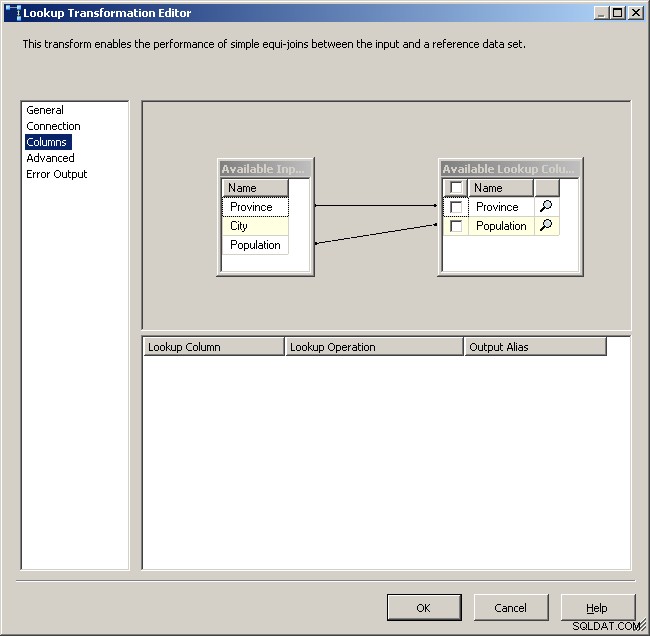
Ahora que el caché tiene los datos agregados allí, suelte una tarea de búsqueda en su flujo de datos principal y realice una búsqueda en el caché.
Pestaña de búsqueda general
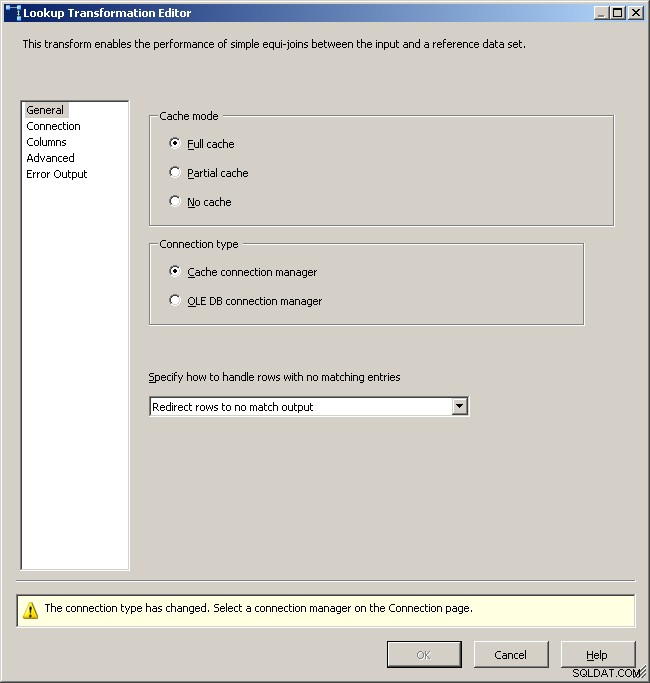
Seleccione el administrador de conexión de caché
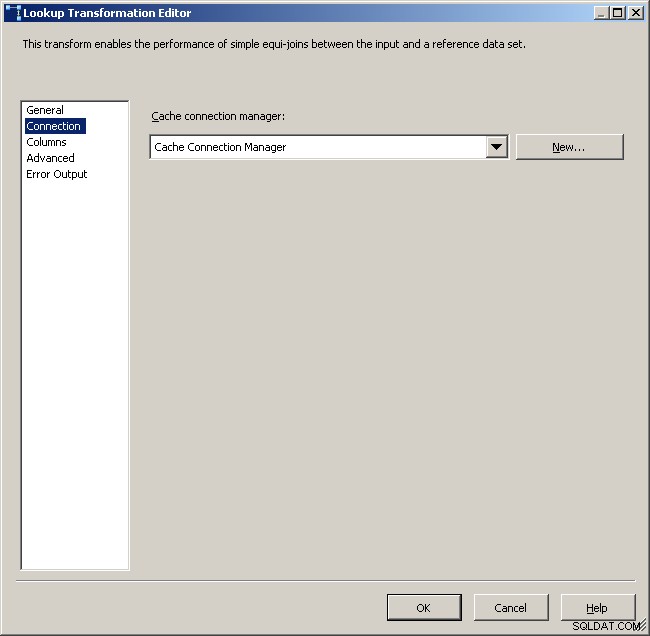
Asigne las columnas apropiadas
Gran éxito 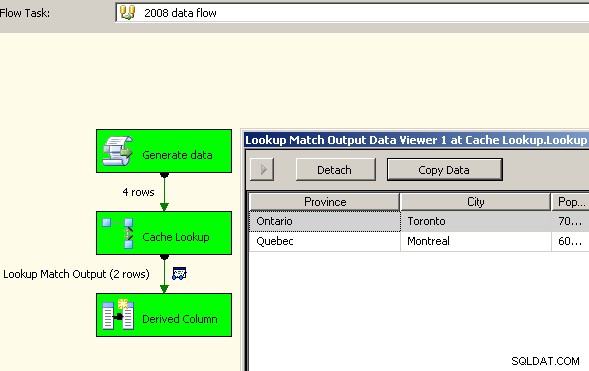
Tarea de guión
El tercer enfoque que se me ocurre, 2005 o 2008, es escribirlo tú mismo. Como regla general, trato de evitar las tareas del script, pero este es un caso en el que probablemente tenga sentido. Deberá convertirlo en un Transformación de script asíncrono pero simplemente maneje sus agregaciones allí. Más código para mantener, pero puede ahorrarse la molestia de volver a procesar sus datos de origen.
Finalmente, como advertencia general, investigaría qué impacto tendrán los lazos en su solución. Para este conjunto de datos, esperaría que algo como Guelph aumentara repentinamente y empatara a Toronto, pero si lo hiciera, ¿qué debería hacer el paquete? En este momento, ambos darán como resultado 2 filas para Ontario, pero ¿es ese el comportamiento previsto? El guión, por supuesto, te permite definir lo que sucede en caso de empate. Probablemente podría poner de cabeza la solución de 2008 almacenando en caché los datos "normales" y usándolos como su condición de búsqueda y usando los agregados para recuperar solo uno de los lazos. 2005 probablemente pueda hacer lo mismo simplemente colocando el agregado como la fuente izquierda para la combinación de combinación
Ediciones
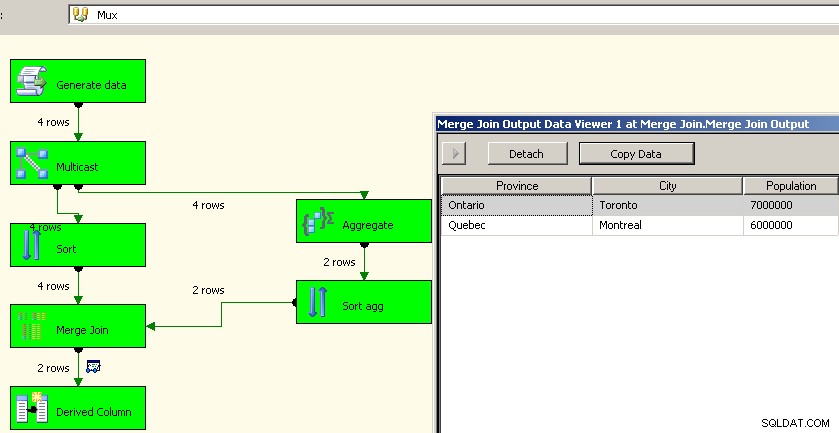
Jason Horner tuvo una buena idea en su comentario. Un enfoque diferente sería usar una transformación de multidifusión y realizar la agregación en una secuencia y volver a unirla. No pude averiguar cómo hacer que funcionara con una unión, pero podríamos usar sorts y merge join de manera muy similar a la anterior. Este es probablemente un mejor enfoque, ya que nos ahorra la molestia de volver a procesar los datos de origen.