Demostración de posible explicación.
Crear script de tabla
SELECT *
INTO #T
FROM master.dbo.spt_values
CREATE NONCLUSTERED INDEX [IX_T] ON #T ([name] DESC,[number] DESC);
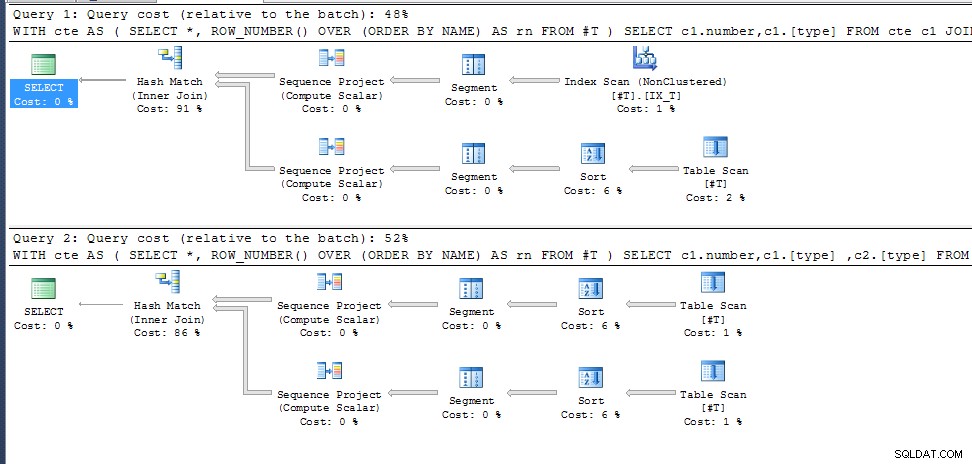
Consulta uno (devuelve 35 resultados)
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Consulta dos (Igual que antes pero agregando c2.[tipo] a la lista de selección hace que arroje 0 resultados);
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type] ,c2.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
¿Por qué?
row_number() para NOMBRES duplicados no se especifica, por lo que solo elige el que se ajuste al mejor plan de ejecución para las columnas de salida requeridas. En la segunda consulta, esto es lo mismo para ambas invocaciones de cte, en la primera elige una ruta de acceso diferente con una numeración de fila diferente resultante.
Solución sugerida
Usted se está uniendo al CTE el ROW_NUMBER() over (order by t.[Date])
Al contrario de lo que se podría haber esperado, es probable que el CTE no materializarse
lo que habría asegurado la coherencia para la unión automática y, por lo tanto, asume una correlación entre ROW_NUMBER() en ambos lados que bien pueden no existir para registros donde un [Date] duplicado existe en los datos.
¿Qué sucede si intenta ROW_NUMBER() over (order by t.[Date], t.[id]) para garantizar que, en caso de fechas empatadas, la numeración de filas esté en un orden coherente garantizado. (O alguna otra columna/combinación de columnas que pueda diferenciar registros si la identificación no lo hace)