El optimizador de SQL Server contiene lógica para eliminar combinaciones redundantes, pero existen restricciones y las combinaciones deben ser probablemente redundante . En resumen, una unión puede tener cuatro efectos:
- Puede agregar columnas adicionales (desde la tabla unida)
- Puede agregar filas adicionales (la tabla unida puede coincidir con una fila de origen más de una vez)
- Puede eliminar filas (la tabla unida puede no tener una coincidencia)
- Puede introducir
NULLs (para unRIGHToFULL JOIN)
Para eliminar con éxito una combinación redundante, la consulta (o vista) debe tener en cuenta las cuatro posibilidades. Cuando esto se hace correctamente, el efecto puede ser sorprendente. Por ejemplo:
USE AdventureWorks2012;
GO
CREATE VIEW dbo.ComplexView
AS
SELECT
pc.ProductCategoryID, pc.Name AS CatName,
ps.ProductSubcategoryID, ps.Name AS SubCatName,
p.ProductID, p.Name AS ProductName,
p.Color, p.ListPrice, p.ReorderPoint,
pm.Name AS ModelName, pm.ModifiedDate
FROM Production.ProductCategory AS pc
FULL JOIN Production.ProductSubcategory AS ps ON
ps.ProductCategoryID = pc.ProductCategoryID
FULL JOIN Production.Product AS p ON
p.ProductSubcategoryID = ps.ProductSubcategoryID
FULL JOIN Production.ProductModel AS pm ON
pm.ProductModelID = p.ProductModelID
El optimizador puede simplificar con éxito la siguiente consulta:
SELECT
c.ProductID,
c.ProductName
FROM dbo.ComplexView AS c
WHERE
c.ProductName LIKE N'G%';
Para:

Rob Farley escribió sobre estas ideas en profundidad en el libro original MVP Deep Dives , y hay una grabación de él presentando el tema en SQLBits.
Las principales restricciones son que las relaciones de clave externa debe basarse en una sola clave para contribuir al proceso de simplificación, y el tiempo de compilación para las consultas contra dicha vista puede volverse bastante largo, particularmente a medida que aumenta el número de uniones. Podría ser todo un desafío escribir una vista de 100 tablas que obtenga toda la semántica exactamente correcta. Me inclinaría por encontrar una solución alternativa, quizás usando SQL dinámico .
Dicho esto, las cualidades particulares de su tabla desnormalizada pueden significar que la vista es bastante simple de ensamblar, requiriendo solo FOREIGN KEYs forzadas no NULL columnas a las que se puede hacer referencia y UNIQUE apropiado restricciones para hacer que esta solución funcione como se espera, sin la sobrecarga de 100 operadores físicos de unión en el plan.
Ejemplo
Usar diez tablas en lugar de cien:
-- Referenced tables
CREATE TABLE dbo.Ref01 (col01 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref02 (col02 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref03 (col03 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref04 (col04 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref05 (col05 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref06 (col06 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref07 (col07 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref08 (col08 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref09 (col09 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref10 (col10 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
La definición de la tabla principal (con compresión de página):
CREATE TABLE dbo.Normalized
(
pk integer IDENTITY NOT NULL,
col01 tinyint NOT NULL REFERENCES dbo.Ref01,
col02 tinyint NOT NULL REFERENCES dbo.Ref02,
col03 tinyint NOT NULL REFERENCES dbo.Ref03,
col04 tinyint NOT NULL REFERENCES dbo.Ref04,
col05 tinyint NOT NULL REFERENCES dbo.Ref05,
col06 tinyint NOT NULL REFERENCES dbo.Ref06,
col07 tinyint NOT NULL REFERENCES dbo.Ref07,
col08 tinyint NOT NULL REFERENCES dbo.Ref08,
col09 tinyint NOT NULL REFERENCES dbo.Ref09,
col10 tinyint NOT NULL REFERENCES dbo.Ref10,
CONSTRAINT PK_Normalized
PRIMARY KEY CLUSTERED (pk)
WITH (DATA_COMPRESSION = PAGE)
);
La vista:
CREATE VIEW dbo.Denormalized
WITH SCHEMABINDING AS
SELECT
item01 = r01.item,
item02 = r02.item,
item03 = r03.item,
item04 = r04.item,
item05 = r05.item,
item06 = r06.item,
item07 = r07.item,
item08 = r08.item,
item09 = r09.item,
item10 = r10.item
FROM dbo.Normalized AS n
JOIN dbo.Ref01 AS r01 ON r01.col01 = n.col01
JOIN dbo.Ref02 AS r02 ON r02.col02 = n.col02
JOIN dbo.Ref03 AS r03 ON r03.col03 = n.col03
JOIN dbo.Ref04 AS r04 ON r04.col04 = n.col04
JOIN dbo.Ref05 AS r05 ON r05.col05 = n.col05
JOIN dbo.Ref06 AS r06 ON r06.col06 = n.col06
JOIN dbo.Ref07 AS r07 ON r07.col07 = n.col07
JOIN dbo.Ref08 AS r08 ON r08.col08 = n.col08
JOIN dbo.Ref09 AS r09 ON r09.col09 = n.col09
JOIN dbo.Ref10 AS r10 ON r10.col10 = n.col10;
Hackea las estadísticas para que el optimizador piense que la tabla es muy grande:
UPDATE STATISTICS dbo.Normalized WITH ROWCOUNT = 100000000, PAGECOUNT = 5000000;
Ejemplo de consulta de usuario:
SELECT
d.item06,
d.item07
FROM dbo.Denormalized AS d
WHERE
d.item08 = 'Banana'
AND d.item01 = 'Green';
Nos da este plan de ejecución:
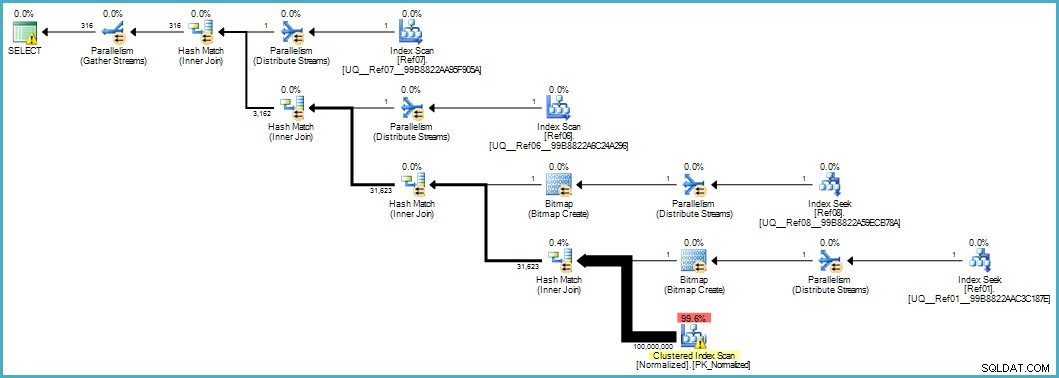
El escaneo de la tabla Normalizada se ve mal, pero el motor de almacenamiento aplica ambos mapas de bits del filtro Bloom durante el escaneo (por lo que las filas que no pueden coincidir ni siquiera aparecen hasta el procesador de consultas). Esto puede ser suficiente para dar un rendimiento aceptable en su caso, y ciertamente mejor que escanear la tabla original con sus columnas desbordadas.
Si puede actualizar a SQL Server 2012 Enterprise en algún momento, tiene otra opción:crear un índice de almacén de columnas en la tabla Normalizada:
CREATE NONCLUSTERED COLUMNSTORE INDEX cs
ON dbo.Normalized (col01,col02,col03,col04,col05,col06,col07,col08,col09,col10);
El plan de ejecución es:
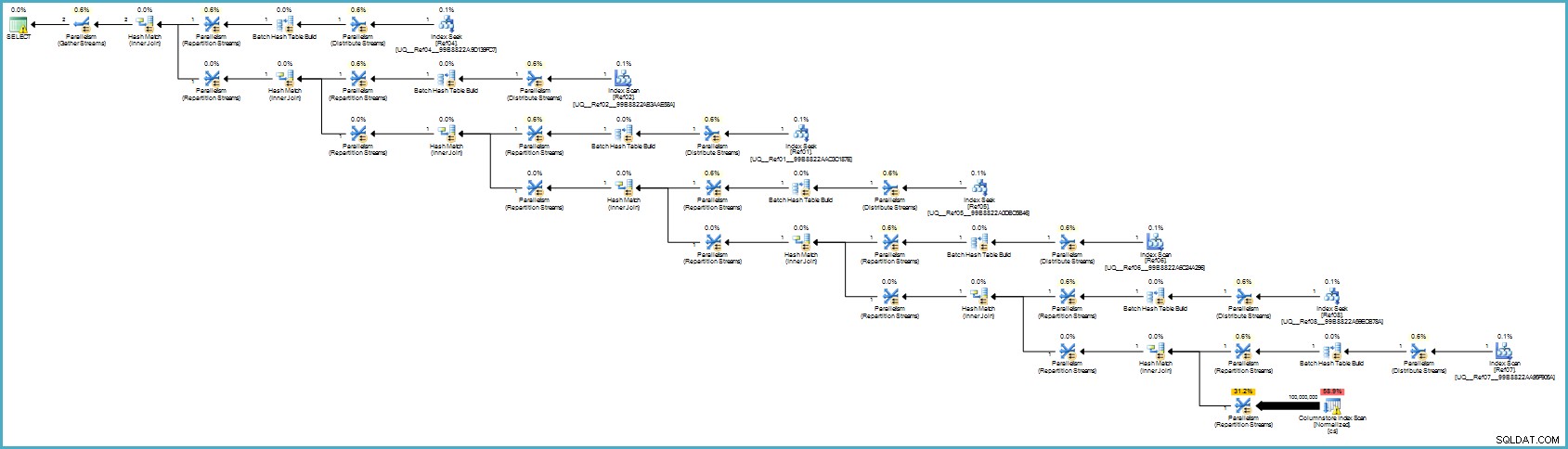
Probablemente le parezca peor, pero el almacenamiento de columnas proporciona una compresión excepcional y todo el plan de ejecución se ejecuta en modo por lotes con filtros para todas las columnas que contribuyen. Si el servidor tiene hilos adecuados y memoria disponible, esta alternativa realmente podría funcionar.
En última instancia, no estoy seguro de que esta normalización sea el enfoque correcto teniendo en cuenta la cantidad de tablas y las posibilidades de obtener un plan de ejecución deficiente o requerir un tiempo de compilación excesivo. Probablemente corregiría primero el esquema de la tabla desnormalizada (tipos de datos adecuados, etc.), posiblemente aplicaría compresión de datos... lo habitual.
Si los datos realmente pertenecen a un esquema en estrella, probablemente necesite más trabajo de diseño que simplemente dividir los elementos de datos repetidos en tablas separadas.