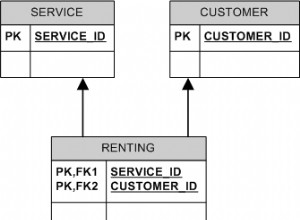
Estoy de acuerdo con @marc_s y @KM en que este gran diseño está condenado desde el principio.
Se han invertido millones de horas de desarrollador de Microsoft en la creación y el ajuste fino de un motor de base de datos robusto y potente, pero lo reinventará todo metiendo todo en una pequeña cantidad de tablas genéricas y reimplementando todo lo que SQL Server ya es. diseñado para hacer por usted.
SQL Server ya tiene tablas que contienen nombres de entidades, nombres de columnas, etc. El hecho de que normalmente no interactúes directamente con estas tablas del sistema es algo bueno:se llama abstracción. Y es poco probable que haga un mejor trabajo al implementar esa abstracción que SQL Server.
Al final del día, con su enfoque (a) incluso las consultas más simples serán monstruosas; y (b) nunca se acercará al rendimiento óptimo, porque está renunciando a toda la optimización de consultas que de otro modo obtendría de forma gratuita.
Sin saber nada más sobre su aplicación o sus requisitos, es difícil dar algún tipo de consejo específico. Pero sugeriría que una buena normalización antigua sería de gran ayuda. Cualquier base de datos no trivial bien implementada tiene muchas tablas; diez mesas más diez mesas xtab no deberían asustarte.
Y no tenga miedo de la generación de código SQL como una forma de implementar interfaces comunes en tablas dispares. Un poco puede recorrer un largo camino.