A menudo necesitamos encontrar y eliminar filas duplicadas de la tabla de Oracle debido a muchas razones en la base de datos. Necesitamos eliminar para eliminar los problemas de datos a menudo. Hay muchas maneras de que Oracle elimine las filas duplicadas pero mantenga el original. En esta publicación, mostraría algunos métodos más rápidos para lograrlo. Mostraré el método donde se usa el ID de fila y el método donde no se usa el ID de fila. Tenga en cuenta que debe identificar todas las columnas que hacen que la fila sea un duplicado en la tabla y especificar todas esas columnas en la declaración de eliminación adecuada en SQL
Cómo eliminar filas duplicadas de Oracle
Estas son algunas de las formas de eliminar filas duplicadas de manera fácil
(A) Método rápido, pero necesita volver a crear todos los índices y activadores de Oracle
create table my_table1 as select distinct * from my_table; drop my_table; rename my_table1 to my_table;
Ejemplo
SQL> select * from mytest;ID NAME------1 TST2 TST1 TSTSQL> create table mytest1 as select distinct * from mytest; Table created. SQL> select * from mytest1;ID NAME-------2 TST1 TSTSQL> drop table mytest; Table dropped. SQL> rename mytest1 to mytest; Table renamed. SQL> select * from mytest;ID NAME-------2 TST1 TST
(B) Cómo encontrar y eliminar registros duplicados en Oracle usando rowid. El siguiente ejemplo muestra una columna. Si tiene una eliminación basada en dos columnas, puede especificar dos columnas
Delete from my_table where rowid not in ( select max(rowid) from my_table group by my_col_name );
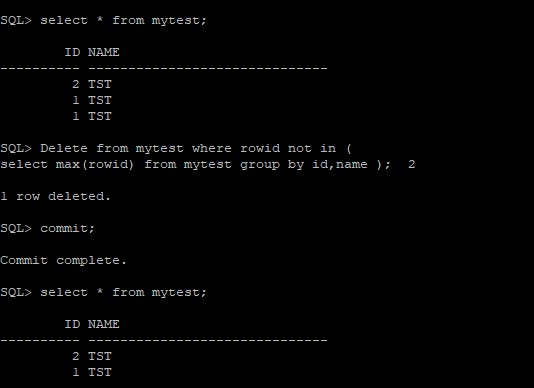
(C) Utilice Oracle Self-Join para eliminar filas duplicadas
DELETE FROM my_table A WHERE ROWID > (SELECT min(rowid) FROM my_table B WHERE A.key_values = B.key_values);
(D) Usar cláusula existe
delete from my_table t1 where exists (select 'x' from my_table t2 where t2.key_value1 = t1.key_value1 and t2.key_value2 = t1.key_value2 and t2.rowid > t1.rowid);
(E) eliminar registros duplicados al usar las funciones analíticas de Oracle
delete from my_table where rowid in (select rid from ( select rowid rid, row_number() over (partition by column_name order by rowid) rn from my_table) where rn <> 1 )
Entonces, como se muestra, hay muchas formas de eliminar filas duplicadas en las tablas. Estos comandos podrían ser útiles en muchas situaciones y se pueden usar según los requisitos. Siempre asegúrese de tener una copia de seguridad disponible antes de ejecutar cualquier declaración. También debemos encontrar primero el duplicado usando la consulta y luego verificarlo antes de enviarlo
cómo encontrar registros duplicados en Oracle usando rowid
select * from my_table
where rowid not in
(select max(rowid) from my_table group by column_name);
Entonces, primero encuentre el duplicado usando la consulta anterior, luego elimínelo y el recuento de eliminaciones debería ser el mismo que el recuento de filas de la consulta anterior. Ahora ejecute la consulta de búsqueda de duplicados nuevamente. Si no hay duplicados, entonces estamos listos para confirmar
Consulte el siguiente artículo para profundizar en Sql
Tutoriales de Oracle Sql:contiene la lista de todos los artículos útiles de Oracle sql. Explórelos para aprender sobre Oracle Sql incluso si sabe Oracle Sql
Preguntas de la entrevista de Oracle:consulte esta página para ver las 49 preguntas y respuestas principales de la entrevista de Oracle:Conceptos básicos, Oracle SQL para ayudarlo en las entrevistas. También se proporciona material adicional
cláusula where en oracle:restricción del conjunto de datos, cláusula where, cláusula what is where en declaración sql, funciones de fila única del operador de comparación
en Oracle:consulte esto para averiguar funciones de fila única en sql, datos de Oracle funciones, funciones numéricas en sql, función de caracteres en sql
consultas de Oracle sql
blog.oracle.com