A veces sucede que tiene que procesar un archivo de texto o CSV muy grande, pero primero desea crear archivos más pequeños de ese archivo grande. Porque ese archivo grande puede tardar demasiado en procesarse o abrirse. Así que doy un ejemplo a continuación para dividir un archivo grande de texto/CSV en varios archivos en PL SQL usando el procedimiento almacenado.
Solo necesita pasar dos parámetros a este procedimiento PL SQL, primero es el nombre del objeto del directorio de la base de datos, donde residen los archivos de texto y el segundo es el nombre del archivo fuente (el archivo que desea dividir).
Si el objeto de directorio de Oracle no existe para la ubicación de los archivos de texto, puede crearlo como se muestra a continuación:
For windows: CREATE OR REPLACE DIRECTORY CSV_FILE_DIR AS 'D:\plsql\text_files';
For Linux/Unix (due to difference in path): CREATE OR REPLACE DIRECTORY CSV_FILE_DIR AS '/plsql/text_files';
Cambie la ruta anterior según la ubicación de sus archivos. Luego cree el siguiente procedimiento ejecutando su script:
CREATE OR REPLACE PROCEDURE split_file (p_db_dir IN VARCHAR2, p_file_name IN VARCHAR2) IS read_file UTL_FILE.file_type; write_file UTL_FILE.file_type; v_string VARCHAR2 (32767); j NUMBER := 1; BEGIN read_file := UTL_FILE.fopen (p_db_dir, p_file_name, 'r'); WHILE j > 0 LOOP write_file := UTL_FILE.fopen (p_db_dir, j || '_' || p_file_name, 'w'); FOR i IN 1 .. 100 LOOP -- example to dividing into 100 rows for each file.. you can increase the number as per your requirement UTL_FILE.get_line (read_file, v_string); UTL_FILE.put_line (write_file, v_string); END LOOP; UTL_FILE.fclose (write_file); j := J + 1; END LOOP; EXCEPTION WHEN OTHERS THEN -- this will handle if reading source file contents finish UTL_FILE.fclose (read_file); UTL_FILE.fclose (write_file); END;
Este procedimiento divide 100 filas para cada archivo, que puede modificar según sus necesidades. Ahora ejecute este procedimiento como se muestra a continuación pasando el nombre del objeto del directorio de la base de datos y el nombre del archivo:
BEGIN
split_file ('CSV_FILE_DIR', 'text_file.csv');
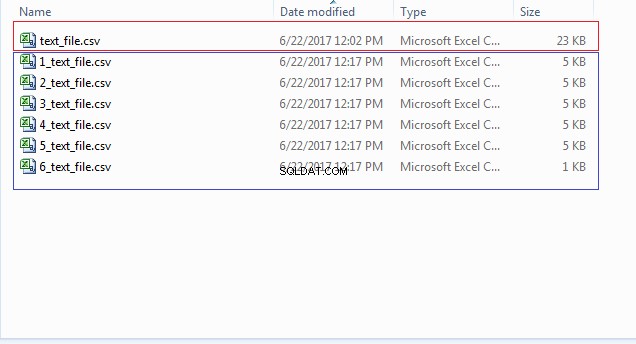
END; Puede verificar la ubicación de su archivo (CSV_FILE_DIR) para los múltiples archivos que comienzan con números como 1_text_file.csv, 2_text_file.csv, etc., como se muestra en la imagen a continuación: