¡Gran pregunta! Aquí hay un violín mostrando cómo consultar las coincidencias en un conjunto de resultados.
Y aquí está la explicación larga en caso de que la consulta en Fiddle no tenga sentido :)
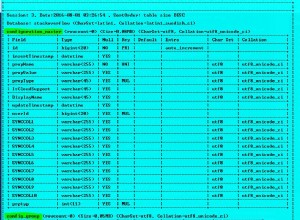
Estoy usando una tabla llamada RegEx_Test con una columna MyVal . Aquí está el contenido de la tabla:
MyVal
------------------------------
[A1][abc][B23][D123]a33[bx5]
[Z15][ax0][B0][F13]R3
[X215][A3A][J99]F33F33G24[43][R3]
[Z99][c1][F3][d33]3x24[Y3][f13]
[9a][D41][Q39][XX12]B27[T03][J12]
Su expresión regular es esta:\[[[:alpha:]][[:digit:]]{1,2}\] . Es lo mismo que en la otra respuesta excepto con POSIX :alpha: y :digit: indicadores, que son más seguros en el caso de conjuntos de caracteres internacionales.
Primero, necesita saber el número máximo de coincidencias en cualquier línea. Usa REGEXP_COUNT por esto:
SELECT MAX(REGEXP_COUNT(MyVal, '\[[[:alpha:]][[:digit:]]{1,2}\]'))
FROM Regex_Test
MAX(REGEXP_COUNT(My...
----------------------
6
Use ese recuento máximo para obtener una tabla de "contador" (esa es la SELECT ... FROM DUAL a continuación) y únase a la tabla de contador con una consulta que extraerá sus valores usando REGEXP_SUBSTR . REGEXP_SUBSTR tiene un parámetro de "ocurrencia" y usará el Counter :
SELECT
MyVal,
Counter,
REGEXP_SUBSTR(MyVal, '\[[[:alpha:]][[:digit:]]{1,2}\]', 1, Counter) Matched
FROM Regex_Test
CROSS JOIN (
SELECT LEVEL Counter
FROM DUAL
CONNECT BY LEVEL <= (
SELECT MAX(REGEXP_COUNT(MyVal, '\[[[:alpha:]][[:digit:]]{1,2}\]'))
FROM Regex_Test)) Counters
Aquí hay una muestra de mi tabla (resultados parciales):
MyVal Counter Matched
---------------------------------- ------- -------
[9a][D41][Q39][XX12]B27[T03][J12] 1 [D41]
[9a][D41][Q39][XX12]B27[T03][J12] 2 [Q39]
[9a][D41][Q39][XX12]B27[T03][J12] 3 [T03]
[9a][D41][Q39][XX12]B27[T03][J12] 4 [J12]
[9a][D41][Q39][XX12]B27[T03][J12] 5
[9a][D41][Q39][XX12]B27[T03][J12] 6
[A1][abc][B23][D123]a33[bx5] 1 [A1]
[A1][abc][B23][D123]a33[bx5] 2 [B23]
[A1][abc][B23][D123]a33[bx5] 3
... and so on - total is 30 rows
En este punto, tiene un conjunto de resultados de coincidencias individuales, más nulos donde una fila tenía menos coincidencias que el máximo. Los partidos todavía tienen sus corchetes circundantes. Rodee todo con una consulta externa que filtrará los nulos y eliminará los corchetes, y tendrá su lista final:
SELECT SUBSTR(Matched, 2, LENGTH(Matched)-2) FROM (
SELECT
MyVal,
Counter,
REGEXP_SUBSTR(MyVal, '\[[[:alpha:]][[:digit:]]{1,2}\]', 1, Counter) Matched
FROM Regex_Test
CROSS JOIN (
SELECT LEVEL Counter
FROM DUAL
CONNECT BY LEVEL <= (
SELECT MAX(REGEXP_COUNT(MyVal, '\[[[:alpha:]][[:digit:]]{1,2}\]'))
FROM Regex_Test)) Counters
) WHERE Matched IS NOT NULL
Esta es la consulta que está en Fiddle y se puede usar en otra consulta.