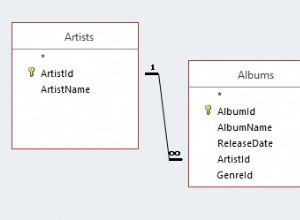
Haz un SELECT con un GROUP BY cláusula. Digamos nombre es la columna en la que desea encontrar duplicados:
SELECT name, COUNT(*) c FROM table GROUP BY name HAVING c > 1;
Esto devolverá un resultado con el nombre valor en la primera columna y un recuento de cuántas veces aparece ese valor en la segunda.