MySQL Replication ha sido la solución más común y ampliamente utilizada para alta disponibilidad por parte de grandes organizaciones como Github, Twitter y Facebook. Si bien es fácil de configurar, existen desafíos que se enfrentan al usar esta solución desde el mantenimiento, incluidas las actualizaciones de software, la deriva de datos o la inconsistencia de los datos en los nodos de réplica, los cambios de topología, la conmutación por error y la recuperación. Cuando MySQL lanzó la versión 5.6, trajo una serie de mejoras significativas, especialmente en la replicación, que incluye ID de transacciones globales (GTID), sumas de verificación de eventos, esclavos de subprocesos múltiples y esclavos/maestros a prueba de fallas. La replicación mejoró aún más con MySQL 5.7 y MySQL 8.0.
La replicación permite que los datos de un servidor MySQL (el principal/maestro) se repliquen en uno o más servidores MySQL (la réplica/esclavos). MySQL Replication es muy fácil de configurar y se utiliza para escalar cargas de trabajo de lectura, proporcionar alta disponibilidad y redundancia geográfica, y descargar copias de seguridad y trabajos analíticos.
Replicación de MySQL en la Naturaleza
Veamos un resumen rápido de cómo funciona la replicación de MySQL en la naturaleza. La replicación de MySQL es amplia y hay varias formas de configurarla y cómo se puede usar. De forma predeterminada, utiliza la replicación asíncrona, que funciona a medida que se completa la transacción en el entorno local. No hay garantía de que ningún evento llegue a ningún esclavo. Es una relación amo-esclavo débilmente acoplada, donde:
-
Principal no espera una réplica.
-
La réplica determina cuánto leer y desde qué punto en el registro binario.
-
La réplica puede estar arbitrariamente detrás del maestro al leer o aplicar cambios.
Si el principal falla, es posible que las transacciones que haya confirmado no se hayan transmitido a ninguna réplica. En consecuencia, la conmutación por error del principal a la réplica más avanzada, en este caso, puede dar como resultado una conmutación por error al principal deseado al que en realidad le faltan transacciones en relación con el servidor anterior.
La replicación asíncrona proporciona una latencia de escritura más baja, ya que un maestro reconoce localmente una escritura antes de que se escriba en los esclavos. Es excelente para la escala de lectura, ya que agregar más réplicas no afecta la latencia de replicación. Los buenos casos de uso para la replicación asíncrona incluyen la implementación de réplicas de lectura para escalado de lectura, copia de respaldo en vivo para recuperación ante desastres y análisis/informes.
Replicación semisincrónica de MySQL
MySQL también admite la replicación semisincrónica, donde el maestro no confirma las transacciones al cliente hasta que al menos un esclavo haya copiado el cambio en su registro de retransmisión y lo haya vaciado en el disco. Para habilitar la replicación semisíncrona, se requieren pasos adicionales para la instalación del complemento y deben habilitarse en los nodos maestro y esclavo de MySQL designados.
La semisíncrona parece ser una solución buena y práctica para muchos casos en los que la alta disponibilidad y la ausencia de pérdida de datos son importantes. Pero debe considerar que semisincrónico tiene un impacto en el rendimiento debido al viaje de ida y vuelta adicional y no ofrece garantías sólidas contra la pérdida de datos. Cuando una confirmación regresa con éxito, se sabe que los datos existen en al menos dos lugares (en el maestro y al menos en un esclavo). Si el maestro se compromete pero ocurre un bloqueo mientras el maestro está esperando el reconocimiento de un esclavo, es posible que la transacción no haya llegado a ningún esclavo. Este no es un problema tan grande ya que la confirmación no se devolverá a la aplicación en este caso. Es tarea de la aplicación volver a intentar la transacción en el futuro. Lo que es esencial tener en cuenta es que cuando el maestro falla y un esclavo ha sido ascendido, el antiguo maestro no puede unirse a la cadena de replicación. En algunas circunstancias, esto puede provocar conflictos con los datos de los esclavos, es decir, cuando el maestro falla después de que el esclavo recibiera el evento de registro binario pero antes de que el maestro obtuviera el reconocimiento del esclavo). Por lo tanto, la única forma segura es descartar los datos del maestro antiguo y aprovisionarlo desde cero utilizando los datos del maestro recién ascendido.
Uso incorrecto del formato de replicación
Desde MySQL 5.7.7, el formato de registro binario predeterminado o la variable binlog_format usa ROW, que era STATEMENT antes de 5.7.7. Los diferentes formatos de replicación corresponden al método utilizado para registrar los eventos de registro binario de la fuente. La replicación funciona porque los eventos escritos en el registro binario se leen desde el origen y luego se procesan en la réplica. Los eventos se registran dentro del registro binario en diferentes formatos de replicación según el tipo de evento. No saber con certeza qué usar puede ser un problema. MySQL tiene tres formatos de métodos de replicación:DECLARACIÓN, FILA y MIXTO.
-
El formato de replicación basada en STATEMENT (SBR) es exactamente lo que es:un flujo de replicación de cada instrucción ejecutada en el maestro que se reproducirá en el nodo esclavo. De forma predeterminada, la replicación tradicional (asíncrona) de MySQL no ejecuta las transacciones replicadas a los esclavos en paralelo. Por eso, significa que el orden de las declaraciones en el flujo de replicación puede no ser 100% igual. Además, reproducir una declaración puede dar resultados diferentes cuando no se ejecuta al mismo tiempo que cuando se ejecuta desde la fuente. Esto conduce a un estado incoherente frente al primario y sus réplicas. Esto no fue un problema durante muchos años, ya que no muchos ejecutaban MySQL con muchos subprocesos simultáneos. Sin embargo, con las modernas arquitecturas multi-CPU, esto se ha vuelto muy probable en una carga de trabajo diaria normal.
-
El formato de replicación ROW proporciona soluciones de las que carece el SBR. Cuando se usa el formato de registro de replicación basada en filas (RBR), el origen escribe eventos en el registro binario que indican cómo se cambian las filas de la tabla individual. La replicación del origen a la réplica funciona copiando los eventos que representan los cambios en las filas de la tabla a la réplica. Esto significa que se pueden generar más datos, lo que afecta el espacio en disco en la réplica y afecta el tráfico de red y la E/S del disco. Considere si una declaración cambia muchas filas, digamos con una declaración UPDATE, RBR escribe más datos en el registro binario, incluso para las declaraciones que se revierten. La ejecución de instantáneas de un momento dado también puede llevar más tiempo. Los problemas de simultaneidad pueden surgir debido a los tiempos de bloqueo necesarios para escribir grandes cantidades de datos en el registro binario.
-
Entonces hay un método entre estos dos; replicación en modo mixto. Este tipo de replicación siempre replicará declaraciones, excepto cuando la consulta contenga la función UUID(), disparadores, procedimientos almacenados, UDF y algunas otras excepciones. El modo mixto no resolverá el problema de la deriva de datos y, junto con la replicación basada en declaraciones, debe evitarse.
¿Planea tener una configuración multimaestro?
La replicación circular (también conocida como topología en anillo) es una configuración conocida y común para la replicación de MySQL. Se utiliza para ejecutar una configuración multimaestro (consulte la imagen a continuación) y, a menudo, es necesario si tiene un entorno de varios centros de datos. Dado que la aplicación no puede esperar a que el maestro en el otro centro de datos reconozca las escrituras, se prefiere un maestro local. Normalmente, el desplazamiento de incremento automático se usa para evitar conflictos de datos entre los maestros. Hacer que dos maestros se escriban entre sí de esta manera es una solución ampliamente aceptada.
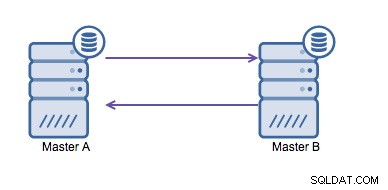
Sin embargo, si necesita escribir en varios centros de datos en la misma base de datos , termina con múltiples maestros que necesitan escribir sus datos entre sí. Antes de MySQL 5.7.6, no había ningún método para hacer un tipo de replicación de malla, por lo que la alternativa sería usar una replicación de anillo circular en su lugar.
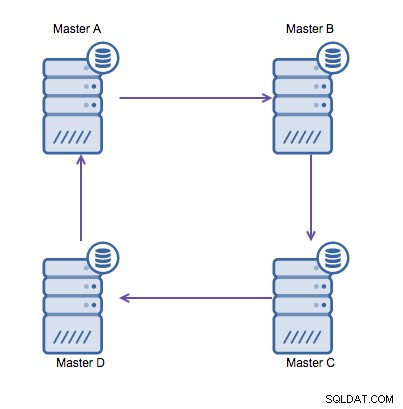
La replicación de anillo en MySQL es problemática por las siguientes razones:latencia, alta disponibilidad y deriva de datos. Escribir algunos datos en el servidor A tomaría tres saltos para terminar en el servidor D (a través del servidor B y C). Dado que la replicación de MySQL (tradicional) es de un solo subproceso, cualquier consulta de ejecución prolongada en la replicación puede detener todo el anillo. Además, si alguno de los servidores dejara de funcionar, el anillo se rompería y, actualmente, ningún software de conmutación por error puede reparar las estructuras del anillo. Entonces, la deriva de datos puede ocurrir cuando los datos se escriben en el servidor A y se modifican simultáneamente en el servidor C o D.
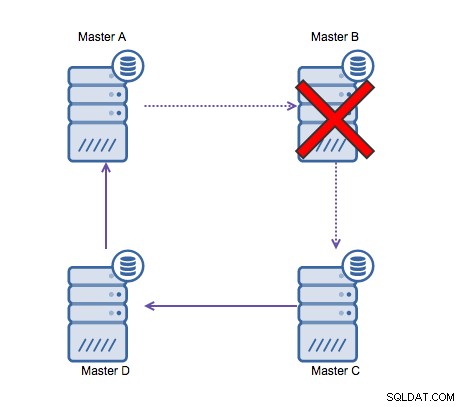
En general, la replicación circular no encaja bien con MySQL y debería ser evitado a toda costa. Como se diseñó con eso en mente, Galera Cluster sería una buena alternativa para las escrituras de varios centros de datos.
Detener su replicación con actualizaciones grandes
Diversos trabajos por lotes de limpieza a menudo realizan varias tareas, que van desde limpiar datos antiguos hasta calcular promedios de "me gusta" obtenidos de otra fuente. Esto significa que un trabajo creará mucha actividad en la base de datos a intervalos establecidos y, muy probablemente, escribirá una gran cantidad de datos en la base de datos. Naturalmente, esto significa que la actividad dentro del flujo de replicación aumentará por igual.
La replicación basada en declaraciones replicará las consultas exactas utilizadas en los trabajos por lotes, por lo que si la consulta tardó media hora en procesarse en el maestro, el subproceso esclavo se detendría durante al menos la misma cantidad de tiempo. Esto significa que no se pueden replicar otros datos y los nodos esclavos comenzarán a retrasarse respecto del maestro. Si esto supera el umbral de su herramienta de conmutación por error o proxy, puede eliminar estos nodos esclavos de los servidores disponibles en el clúster. Si está utilizando la replicación basada en declaraciones, puede evitar esto procesando los datos para su trabajo en lotes más pequeños.
Ahora, puede pensar que la replicación basada en filas no se ve afectada por esto, ya que replicará la información de la fila en lugar de la consulta. Esto es parcialmente cierto ya que, para los cambios de DDL, la replicación vuelve a un formato basado en declaraciones. Además, una gran cantidad de operaciones CRUD (Crear, Leer, Actualizar, Eliminar) afectarán el flujo de replicación. En la mayoría de los casos, esta sigue siendo una operación de un solo subproceso y, por lo tanto, cada transacción esperará a que la anterior se reproduzca a través de la replicación. Esto significa que si tiene una alta concurrencia en el maestro, el esclavo puede detenerse debido a la sobrecarga de transacciones durante la replicación.
Para evitar esto, tanto MariaDB como MySQL ofrecen replicación paralela. La implementación puede diferir según el proveedor y la versión. MySQL 5.6 ofrece replicación paralela siempre que las consultas estén separadas por el esquema. Tanto MariaDB 10.0 como MySQL 5.7 pueden manejar la replicación paralela entre esquemas, pero tienen otros límites. La ejecución de consultas a través de subprocesos esclavos paralelos puede acelerar su flujo de replicación si está escribiendo mucho. De lo contrario, sería mejor ceñirse a la replicación tradicional de un solo subproceso.
Manejo de su cambio de esquema o DDL
Desde el lanzamiento de 5.7, la gestión del cambio de esquema o cambio de DDL (lenguaje de definición de datos) en MySQL ha mejorado mucho. Hasta MySQL 8.0, los algoritmos de cambios de DDL admitidos son COPY e INPLACE.
-
COPIA:Este algoritmo crea una nueva tabla temporal con el esquema alterado. Una vez que migra los datos por completo a la nueva tabla temporal, intercambia y elimina la tabla anterior.
-
INPLACE:este algoritmo realiza operaciones en la tabla original y evita la copia y reconstrucción de la tabla siempre que sea posible.
-
INSTANTÁNEO:este algoritmo se introdujo desde MySQL 8.0 pero aún tiene limitaciones.
En MySQL 8.0, se introdujo el algoritmo INSTANT, que realiza modificaciones de tabla instantáneas y en el lugar para la adición de columnas y permite DML concurrente con capacidad de respuesta y disponibilidad mejoradas en entornos de producción ocupados. Esto ayuda a evitar grandes retrasos y paradas en la réplica que generalmente eran grandes problemas en la perspectiva de la aplicación, lo que provocaba la recuperación de datos obsoletos ya que las lecturas en el esclavo aún no se han actualizado debido al retraso.
Aunque es una mejora prometedora, todavía tienen limitaciones y, a veces, no es posible aplicar esos algoritmos INSTANTÁNE e INPLACE. Por ejemplo, para los algoritmos INSTANTÁNEO e INPLACE, cambiar el tipo de datos de una columna también es una tarea habitual del DBA, especialmente en la perspectiva del desarrollo de aplicaciones debido al cambio de datos. Estas ocasiones son inevitables; por lo tanto, no puede continuar con el algoritmo COPY ya que bloquea la tabla y provoca retrasos en el esclavo. También afecta al servidor primario/maestro durante esta ejecución, ya que acumula transacciones entrantes que también hacen referencia a la tabla afectada. No puede realizar un cambio de esquema o ALTER directo en un servidor ocupado, ya que esto acompaña el tiempo de inactividad o posiblemente corrompa su base de datos si pierde la paciencia, especialmente si la tabla de destino es enorme.
Es cierto que realizar cambios de esquema en una configuración de producción en ejecución siempre es una tarea desafiante. Una solución alternativa que se usa con frecuencia es aplicar primero el cambio de esquema a los nodos esclavos. Esto funciona bien para la replicación basada en declaraciones, pero solo puede funcionar hasta cierto punto para la replicación basada en filas. La replicación basada en filas permite que existan columnas adicionales al final de la tabla, por lo que siempre que pueda escribir las primeras columnas, estará bien. Primero, aplique el cambio a todos los esclavos, luego realice la conmutación por error a uno de los esclavos y luego aplique el cambio al maestro y conéctelo como esclavo. Si su cambio implica insertar una columna en el medio o eliminar una columna, esto funcionará con la replicación basada en filas.
Hay herramientas disponibles que pueden realizar cambios de esquema en línea de manera más confiable. Los administradores de bases de datos suelen utilizar Percona Online Schema Change (conocido como pt-osc) y gh-ost de Schlomi Noach. Estas herramientas manejan los cambios de esquema de manera efectiva al agrupar las filas afectadas en fragmentos, y estos fragmentos se pueden configurar en consecuencia dependiendo de cuántos desee agrupar.
Si va a saltar con pt-osc, esta herramienta creará una tabla oculta con la nueva estructura de tabla, insertará nuevos datos a través de activadores y rellenará los datos en segundo plano. Una vez que haya terminado de crear la nueva tabla, simplemente cambiará la tabla anterior por la nueva dentro de una transacción. Esto no funciona en todos los casos, especialmente si su tabla existente ya tiene disparadores.
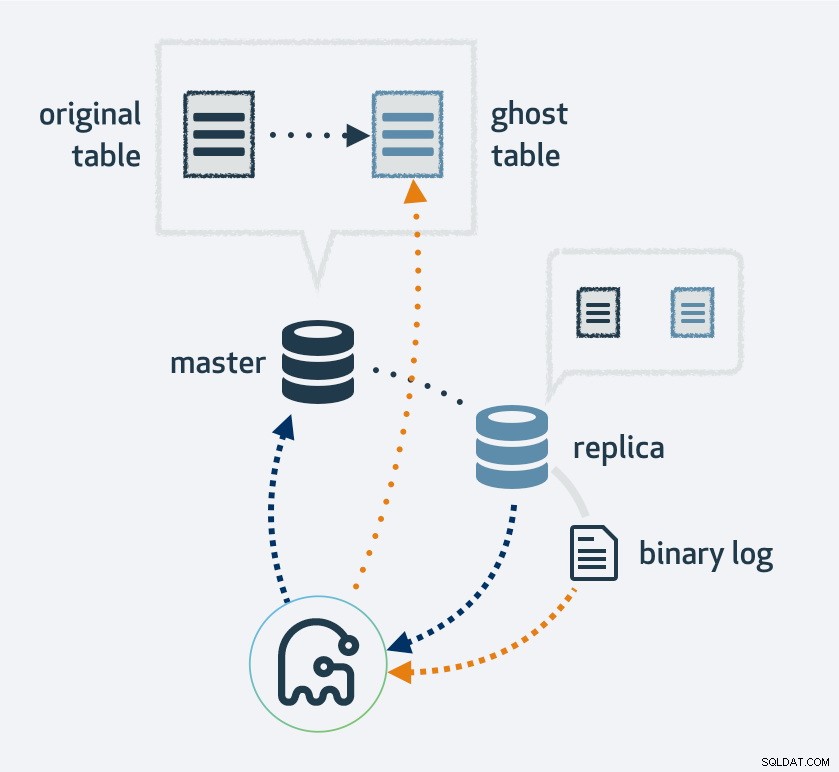
Usar gh-ost primero hará una copia de su diseño de tabla existente, modifique la tabla al nuevo diseño y luego conecte el proceso como una réplica de MySQL. Utilizará el flujo de replicación para buscar filas nuevas que se hayan insertado en la tabla original y, al mismo tiempo, rellenará la tabla. Una vez que se haya completado el relleno, las tablas originales y nuevas se intercambiarán. Naturalmente, todas las operaciones en la nueva tabla terminarán en el flujo de replicación; por lo tanto, en cada réplica, la migración ocurre simultáneamente.
Tablas de memoria y replicación
Si bien estamos en el tema de los DDL, un problema común es la creación de tablas de memoria. Las tablas de memoria son tablas no persistentes, su estructura de tabla permanece, pero pierden sus datos después de reiniciar MySQL. Al crear una nueva tabla de memoria tanto en un maestro como en un esclavo, tendrán una tabla vacía, que funcionará perfectamente bien. Una vez que se reinicia cualquiera de los dos, la tabla se vaciará y se producirán errores de replicación.
La replicación basada en filas se interrumpirá una vez que los datos en el nodo esclavo devuelvan resultados diferentes, y la replicación basada en declaraciones se interrumpirá una vez que intente insertar datos que ya existen. Para las tablas de memoria, este es un factor frecuente de interrupción de la replicación. La solución es fácil:haga una copia nueva de los datos, cambie el motor a InnoDB y ahora debería ser seguro para la replicación.
Configuración de read_only={True|1}
Este es, por supuesto, un caso posible cuando se utiliza una topología en anillo y desaconsejamos el uso de la topología en anillo si es posible. Describimos anteriormente que no tener los mismos datos en los nodos esclavos puede interrumpir la replicación. A menudo, esto es causado por algo (o alguien) que altera los datos en el nodo esclavo pero no en el nodo maestro. Una vez que se modifican los datos del nodo maestro, estos se replicarán en el esclavo donde no puede aplicar el cambio, y esto hace que la replicación se interrumpa. Esto también puede conducir a la corrupción de datos a nivel de clúster, especialmente si el esclavo ha sido promovido o ha fallado debido a un bloqueo. Eso puede ser un desastre.
La prevención fácil para esto es asegurarse de que read_only y super_read_only (solo en> 5.6) estén configurados en ON o 1. Es posible que haya entendido cómo difieren estas dos variables y cómo afecta si deshabilita o habilita a ellos. Con super_read_only (desde MySQL 5.7.8) deshabilitado, el usuario raíz puede evitar cualquier cambio en el destino o la réplica. Entonces, cuando ambos están deshabilitados, esto no permitirá que nadie realice cambios en los datos, excepto la replicación. La mayoría de los administradores de conmutación por error, como ClusterControl, establecen este indicador automáticamente para evitar que los usuarios escriban en el maestro usado durante la conmutación por error. Algunos de ellos incluso conservan esto después de la conmutación por error.
Habilitación de GTID
En la replicación de MySQL, es esencial iniciar el esclavo desde la posición correcta en los registros binarios. La obtención de esta posición se puede hacer al hacer una copia de seguridad (xtrabackup y mysqldump lo admiten) o cuando ha dejado de trabajar como esclavo en un nodo del que está haciendo una copia. Comenzar la replicación con el comando CHANGE MASTER TO se vería así:
mysql> CHANGE MASTER TO MASTER_HOST='x.x.x.x',
MASTER_USER='replication_user',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='master-bin.00001',
MASTER_LOG_POS=4;Comenzar la replicación en el lugar equivocado puede tener consecuencias desastrosas:los datos pueden escribirse dos veces o no actualizarse. Esto provoca la deriva de datos entre el nodo maestro y el esclavo.
Además, la conmutación por error de un maestro a un esclavo implica encontrar la posición correcta y cambiar el maestro al host apropiado. MySQL no conserva los registros y posiciones binarios de su maestro, sino que crea sus propios registros y posiciones binarios. Esto podría convertirse en un problema grave para volver a alinear un nodo esclavo con el nuevo maestro. La posición exacta del maestro en la conmutación por error se debe encontrar en el nuevo maestro y luego se pueden realinear todos los esclavos.
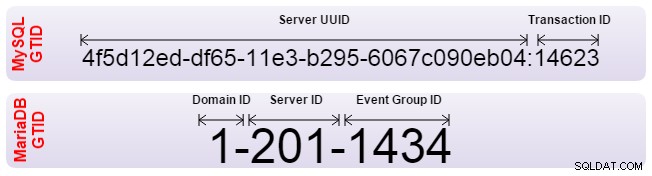
Tanto Oracle MySQL como MariaDB han implementado el Global Transaction Identifier (GTID) para resolver este problema. Los GTID permiten la alineación automática de los esclavos y el servidor determina por sí mismo cuál es la posición correcta. Sin embargo, ambos han implementado el GTID de manera diferente y, por lo tanto, son incompatibles. Si necesita configurar la replicación de uno a otro, la replicación debe configurarse con el posicionamiento de registro binario tradicional. Además, su software de conmutación por error debe tener en cuenta que no utilice GTID.
Esclavo a prueba de choques
Crash safe significa que incluso si un sistema operativo/MySQL esclavo falla, puede recuperar el esclavo y continuar con la replicación sin restaurar las bases de datos MySQL en el esclavo. Para hacer que el esclavo a prueba de fallas funcione, solo debe usar el motor de almacenamiento InnoDB, y en 5.6, debe configurar relay_log_info_repository=TABLE y relay_log_recovery=1.
Conclusión
La práctica hace a la perfección, pero sin la formación adecuada y el conocimiento de estas técnicas vitales, podría ser problemático o conducir a un desastre. Los expertos en MySQL suelen seguir estas prácticas y las grandes industrias las adaptan como parte de su trabajo de rutina diaria al administrar la replicación de MySQL en los servidores de bases de datos de producción.
Si desea obtener más información sobre la replicación de MySQL, consulte este tutorial sobre la replicación de MySQL para una alta disponibilidad.
Para obtener más actualizaciones sobre las soluciones de administración de bases de datos y las mejores prácticas para sus bases de datos basadas en código abierto, síganos en Twitter y LinkedIn y suscríbase a nuestro boletín.