Como vimos anteriormente, podría ser un desafío para las empresas mover sus datos fuera de RDS para MySQL. En la primera parte de este blog, le mostramos cómo configurar su entorno de destino en EC2 e insertar una capa de proxy (ProxySQL) entre sus aplicaciones y RDS. En esta segunda parte, le mostraremos cómo realizar la migración real de datos a su propio servidor y luego redirigir sus aplicaciones a la nueva instancia de base de datos sin tiempo de inactividad.
Copia de datos fuera de RDS
Una vez que tengamos el tráfico de nuestra base de datos ejecutándose a través de ProxySQL, podemos comenzar los preparativos para copiar nuestros datos fuera de RDS. Necesitamos hacer esto para configurar la replicación entre RDS y nuestra instancia de MySQL que se ejecuta en EC2. Una vez hecho esto, configuraremos ProxySQL para redirigir el tráfico de RDS a nuestro MySQL/EC2.
Como discutimos en la primera publicación de blog de esta serie, la única forma en que puede obtener datos del RDS es mediante un volcado lógico. Sin acceso a la instancia, no podemos usar ninguna herramienta de copia de seguridad física activa como xtrabackup. Tampoco podemos usar instantáneas, ya que no hay forma de crear otra cosa que no sea una nueva instancia de RDS a partir de la instantánea.
Estamos limitados a herramientas de volcado lógico, por lo que la opción lógica sería usar mydumper/myloader para procesar los datos. Afortunadamente, mydumper puede crear copias de seguridad consistentes para que podamos confiar en él para proporcionar coordenadas binlog para que nuestro nuevo esclavo se conecte. El principal problema al crear réplicas de RDS es la política de rotación de binlog:el volcado lógico y la carga pueden tardar incluso días en conjuntos de datos más grandes (cientos de gigabytes) y debe mantener binlogs en la instancia de RDS durante todo este proceso. Claro, puede aumentar la retención de rotación de binlog en RDS (llame a mysql.rds_set_configuration('binlog retention hours', 24); puede mantenerlos hasta 7 días), pero es mucho más seguro hacerlo de otra manera.
Antes de continuar con el volcado, agregaremos una réplica a nuestra instancia de RDS.
 Panel de RDS de Amazon
Panel de RDS de Amazon 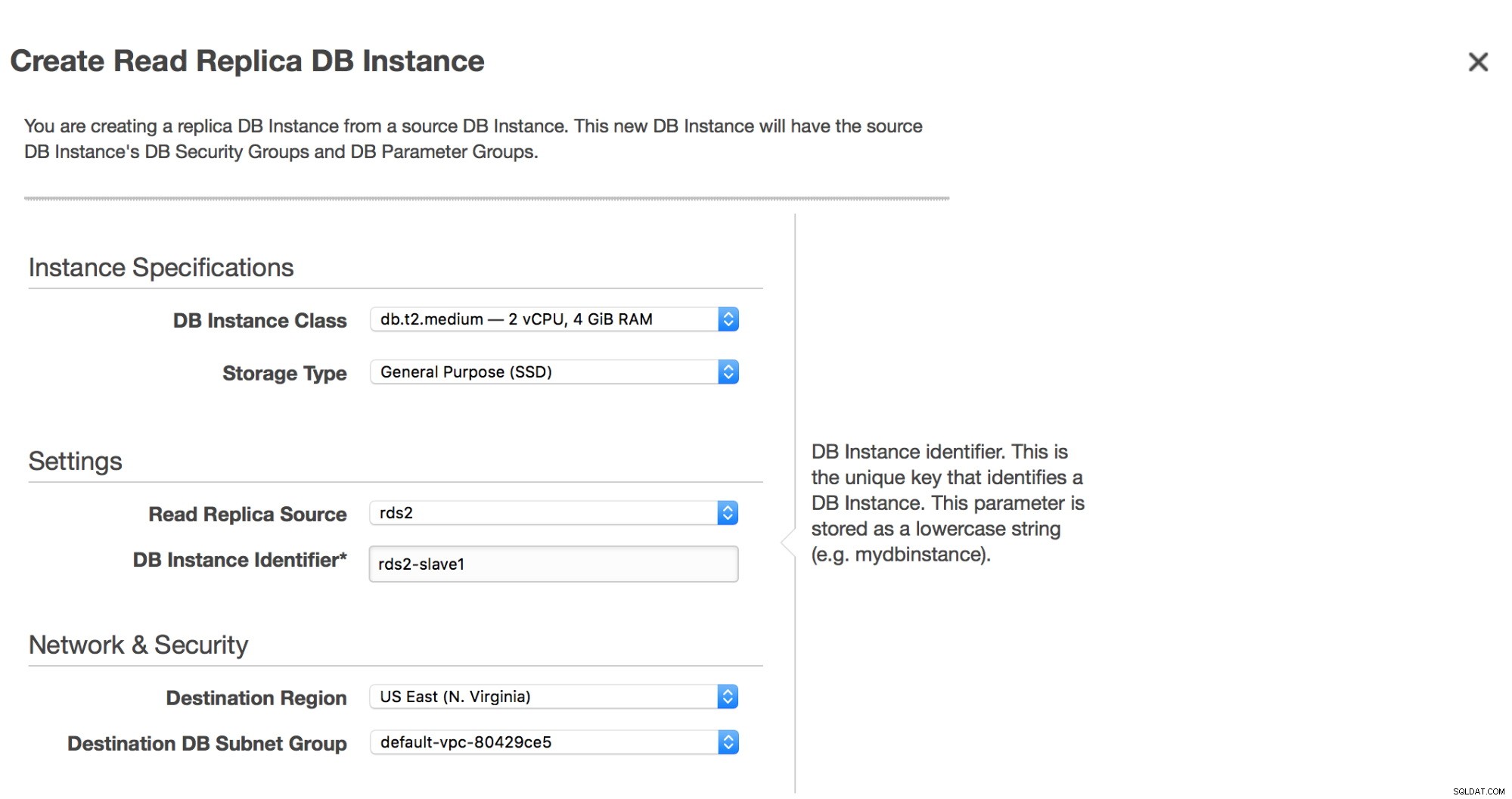 Crear base de datos réplica en RDS
Crear base de datos réplica en RDS 
Una vez que hagamos clic en el botón "Crear réplica de lectura", se iniciará una instantánea en la réplica RDS "maestra". Se utilizará para aprovisionar el nuevo esclavo. El proceso puede llevar horas, todo depende del tamaño del volumen, cuándo fue la última vez que se tomó una instantánea y el rendimiento del volumen (¿io1/gp2? ¿Magnético? ¿Cuántos pIOPS tiene un volumen?).
 Réplica maestra de RDS
Réplica maestra de RDS Cuando el esclavo está listo (su estado ha cambiado a "disponible"), podemos iniciar sesión usando su punto final RDS.
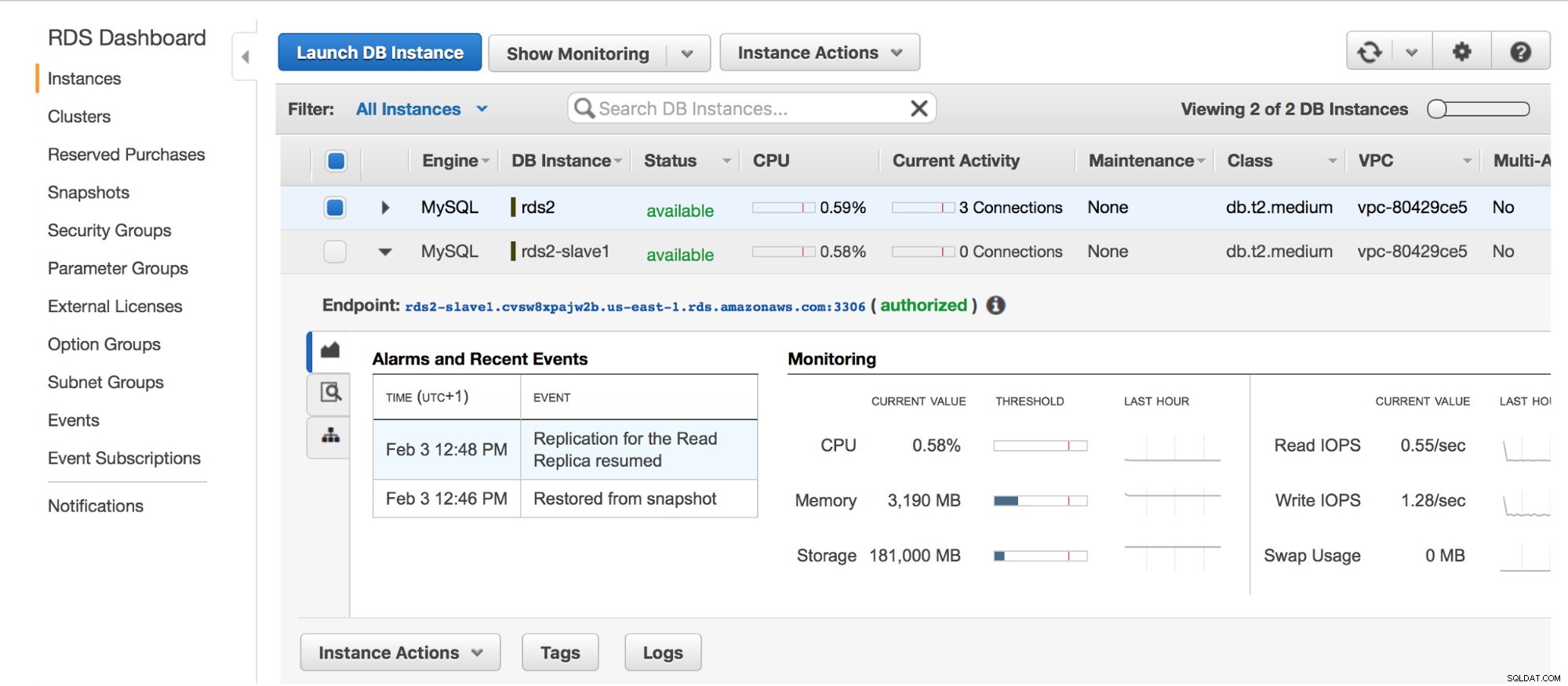 Esclavo RDS
Esclavo RDS Una vez que haya iniciado sesión, detendremos la replicación en nuestro esclavo; esto asegurará que el maestro RDS no elimine los registros binarios y seguirán estando disponibles para nuestro esclavo EC2 una vez que completemos nuestro proceso de volcado/recarga.
mysql> CALL mysql.rds_stop_replication;
+---------------------------+
| Message |
+---------------------------+
| Slave is down or disabled |
+---------------------------+
1 row in set (1.02 sec)
Query OK, 0 rows affected (1.02 sec)Ahora, finalmente es hora de copiar datos a EC2. Primero, necesitamos instalar mydumper. Puede obtenerlo de github:https://github.com/maxbube/mydumper. El proceso de instalación es bastante simple y está muy bien descrito en el archivo Léame, por lo que no lo cubriremos aquí. Lo más probable es que tenga que instalar un par de paquetes (enumerados en el archivo Léame) y la parte más difícil es identificar qué paquete contiene mysql_config; depende del tipo de MySQL (y, a veces, también de la versión de MySQL).
Una vez que haya compilado mydumper y esté listo para funcionar, puede ejecutarlo:
example@sqldat.com:~/mydumper# mkdir /tmp/rdsdump
example@sqldat.com:~/mydumper# ./mydumper -h rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.com -p tpccpass -u tpcc -o /tmp/rdsdump --lock-all-tables --chunk-filesize 100 --events --routines --triggers
. Tenga en cuenta que --lock-all-tables garantiza que la instantánea de los datos será coherente y será posible utilizarla para crear un esclavo. Ahora, tenemos que esperar hasta que mydumper complete su tarea.
Se requiere un paso más:no queremos restaurar el esquema mysql, pero necesitamos copiar los usuarios y sus permisos. Podemos usar pt-show-grants para eso:
example@sqldat.com:~# wget https://percona.com/get/pt-show-grants
example@sqldat.com:~# chmod u+x ./pt-show-grants
example@sqldat.com:~# ./pt-show-grants -h rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.com -u tpcc -p tpccpass > grants.sqlUna muestra de pt-show-grants puede verse así:
-- Grants for 'sbtest'@'%'
CREATE USER IF NOT EXISTS 'sbtest'@'%';
ALTER USER 'sbtest'@'%' IDENTIFIED WITH 'mysql_native_password' AS '*2AFD99E79E4AA23DE141540F4179F64FFB3AC521' REQUIRE NONE PASSWORD EXPIRE DEFAULT ACCOUNT UNLOCK;
GRANT ALTER, ALTER ROUTINE, CREATE, CREATE ROUTINE, CREATE TEMPORARY TABLES, CREATE USER, CREATE VIEW, DELETE, DROP, EVENT, EXECUTE, INDEX, INSERT, LOCK TABLES, PROCESS, REFERENCES, RELOAD, REPLICATION CLIENT, REPLICATION SLAVE, SELECT, SHOW DATABASES, SHOW VIEW, TRIGGER, UPDATE ON *.* TO 'sbtest'@'%';Depende de usted elegir qué usuarios deben copiarse en su instancia MySQL/EC2. No tiene sentido hacerlo por todos. Por ejemplo, los usuarios raíz no tienen el privilegio 'SUPER' en RDS, por lo que es mejor volver a crearlos desde cero. Lo que necesita copiar son concesiones para el usuario de su aplicación. También necesitamos copiar los usuarios usados por ProxySQL (proxysql-monitor en nuestro caso).
Inserción de datos en su instancia MySQL/EC2
Como se indicó anteriormente, no queremos restaurar los esquemas del sistema. Por lo tanto, moveremos los archivos relacionados con esos esquemas fuera de nuestro directorio mydumper:
example@sqldat.com:~# mkdir /tmp/rdsdump_sys/
example@sqldat.com:~# mv /tmp/rdsdump/mysql* /tmp/rdsdump_sys/
example@sqldat.com:~# mv /tmp/rdsdump/sys* /tmp/rdsdump_sys/Cuando hayamos terminado, es hora de comenzar a cargar datos en la instancia MySQL/EC2:
example@sqldat.com:~/mydumper# ./myloader -d /tmp/rdsdump/ -u tpcc -p tpccpass -t 4 --overwrite-tables -h 172.30.4.238Tenga en cuenta que usamos cuatro subprocesos (-t 4); asegúrese de configurar esto en lo que tenga sentido en su entorno. Se trata de saturar la instancia de MySQL de destino, ya sea CPU o E/S, según el cuello de botella. Queremos sacarle el máximo partido posible para asegurarnos de que utilizamos todos los recursos disponibles para cargar los datos.
Después de cargar los datos principales, hay dos pasos más a seguir, ambos están relacionados con las funciones internas de RDS y ambos pueden interrumpir nuestra replicación. Primero, RDS contiene un par de tablas rds_* en el esquema mysql. Queremos cargarlos en caso de que RDS utilice algunos de ellos:la replicación se interrumpirá si nuestro esclavo no los tiene. Podemos hacerlo de la siguiente forma:
example@sqldat.com:~/mydumper# for i in $(ls -alh /tmp/rdsdump_sys/ | grep rds | awk '{print $9}') ; do echo $i ; mysql -ppass -uroot mysql < /tmp/rdsdump_sys/$i ; done
mysql.rds_configuration-schema.sql
mysql.rds_configuration.sql
mysql.rds_global_status_history_old-schema.sql
mysql.rds_global_status_history-schema.sql
mysql.rds_heartbeat2-schema.sql
mysql.rds_heartbeat2.sql
mysql.rds_history-schema.sql
mysql.rds_history.sql
mysql.rds_replication_status-schema.sql
mysql.rds_replication_status.sql
mysql.rds_sysinfo-schema.sqlUn problema similar es con las tablas de zona horaria, necesitamos cargarlas usando datos de la instancia RDS:
example@sqldat.com:~/mydumper# for i in $(ls -alh /tmp/rdsdump_sys/ | grep time_zone | grep -v schema | awk '{print $9}') ; do echo $i ; mysql -ppass -uroot mysql < /tmp/rdsdump_sys/$i ; done
mysql.time_zone_name.sql
mysql.time_zone.sql
mysql.time_zone_transition.sql
mysql.time_zone_transition_type.sqlCuando todo esto esté listo, podemos configurar la replicación entre RDS (maestro) y nuestra instancia MySQL/EC2 (esclavo).
Configurar la replicación
Mydumper, al realizar un volcado consistente, escribe una posición de registro binario. Podemos encontrar estos datos en un archivo llamado metadatos en el directorio de volcado. Echémosle un vistazo, luego usaremos la posición para configurar la replicación.
example@sqldat.com:~/mydumper# cat /tmp/rdsdump/metadata
Started dump at: 2017-02-03 16:17:29
SHOW SLAVE STATUS:
Host: 10.1.4.180
Log: mysql-bin-changelog.007079
Pos: 10537102
GTID:
Finished dump at: 2017-02-03 16:44:46Una última cosa que nos falta es un usuario que podamos usar para configurar nuestro esclavo. Vamos a crear uno en la instancia de RDS:
example@sqldat.com:~# mysql -ppassword -h rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.commysql> CREATE USER IF NOT EXISTS 'rds_rpl'@'%' IDENTIFIED BY 'rds_rpl_pass';
Query OK, 0 rows affected (0.04 sec)mysql> GRANT REPLICATION SLAVE ON *.* TO 'rds_rpl'@'%';
Query OK, 0 rows affected (0.01 sec)Ahora es el momento de esclavizar nuestro servidor MySQL/EC2 fuera de la instancia RDS:
mysql> CHANGE MASTER TO MASTER_HOST='rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.com', MASTER_USER='rds_rpl', MASTER_PASSWORD='rds_rpl_pass', MASTER_LOG_FILE='mysql-bin-changelog.007079', MASTER_LOG_POS=10537102;
Query OK, 0 rows affected, 2 warnings (0.03 sec)mysql> START SLAVE;
Query OK, 0 rows affected (0.02 sec)mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Queueing master event to the relay log
Master_Host: rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.com
Master_User: rds_rpl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin-changelog.007080
Read_Master_Log_Pos: 13842678
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 20448
Relay_Master_Log_File: mysql-bin-changelog.007079
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 10557220
Relay_Log_Space: 29071382
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 258726
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1237547456
Master_UUID: b5337d20-d815-11e6-abf1-120217bb3ac2
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: System lock
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.01 sec)El último paso será cambiar nuestro tráfico de la instancia RDS a MySQL/EC2, pero primero debemos dejar que se ponga al día.
Cuando el esclavo se ha puesto al día, necesitamos realizar un corte. Para automatizarlo, decidimos preparar un breve script de bash que se conectará a ProxySQL y hará lo que se debe hacer.
# At first, we define old and new masters
OldMaster=rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.com
NewMaster=172.30.4.238
(
# We remove entries from mysql_replication_hostgroup so ProxySQL logic won’t interfere
# with our script
echo "DELETE FROM mysql_replication_hostgroups;"
# Then we set current master to OFFLINE_SOFT - this will allow current transactions to
# complete while not accepting any more transactions - they will wait (by default for
# 10 seconds) for a master to become available again.
echo "UPDATE mysql_servers SET STATUS='OFFLINE_SOFT' WHERE hostname=\"$OldMaster\";"
echo "LOAD MYSQL SERVERS TO RUNTIME;"
) | mysql -u admin -padmin -h 127.0.0.1 -P6032
# Here we are going to check for connections in the pool which are still used by
# transactions which haven’t closed so far. If we see that neither hostgroup 10 nor
# hostgroup 20 has open transactions, we can perform a switchover.
CONNUSED=`mysql -h 127.0.0.1 -P6032 -uadmin -padmin -e 'SELECT IFNULL(SUM(ConnUsed),0) FROM stats_mysql_connection_pool WHERE status="OFFLINE_SOFT" AND (hostgroup=10 OR hostgroup=20)' -B -N 2> /dev/null`
TRIES=0
while [ $CONNUSED -ne 0 -a $TRIES -ne 20 ]
do
CONNUSED=`mysql -h 127.0.0.1 -P6032 -uadmin -padmin -e 'SELECT IFNULL(SUM(ConnUsed),0) FROM stats_mysql_connection_pool WHERE status="OFFLINE_SOFT" AND (hostgroup=10 OR hostgroup=20)' -B -N 2> /dev/null`
TRIES=$(($TRIES+1))
if [ $CONNUSED -ne "0" ]; then
sleep 0.05
fi
done
# Here is our switchover logic - we basically exchange hostgroups for RDS and EC2
# instance. We also configure back mysql_replication_hostgroups table.
(
echo "UPDATE mysql_servers SET STATUS='ONLINE', hostgroup_id=110 WHERE hostname=\"$OldMaster\" AND hostgroup_id=10;"
echo "UPDATE mysql_servers SET STATUS='ONLINE', hostgroup_id=120 WHERE hostname=\"$OldMaster\" AND hostgroup_id=20;"
echo "UPDATE mysql_servers SET hostgroup_id=10 WHERE hostname=\"$NewMaster\" AND hostgroup_id=110;"
echo "UPDATE mysql_servers SET hostgroup_id=20 WHERE hostname=\"$NewMaster\" AND hostgroup_id=120;"
echo "INSERT INTO mysql_replication_hostgroups VALUES (10, 20, 'hostgroups');"
echo "LOAD MYSQL SERVERS TO RUNTIME;"
) | mysql -u admin -padmin -h 127.0.0.1 -P6032Cuando todo esté listo, debería ver el siguiente contenido en la tabla mysql_servers:
mysql> select * from mysql_servers;
+--------------+-----------------------------------------------+------+--------+--------+-------------+-----------------+---------------------+---------+----------------+-------------+
| hostgroup_id | hostname | port | status | weight | compression | max_connections | max_replication_lag | use_ssl | max_latency_ms | comment |
+--------------+-----------------------------------------------+------+--------+--------+-------------+-----------------+---------------------+---------+----------------+-------------+
| 20 | 172.30.4.238 | 3306 | ONLINE | 1 | 0 | 100 | 10 | 0 | 0 | read server |
| 10 | 172.30.4.238 | 3306 | ONLINE | 1 | 0 | 100 | 10 | 0 | 0 | read server |
| 120 | rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.com | 3306 | ONLINE | 1 | 0 | 100 | 10 | 0 | 0 | |
| 110 | rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.com | 3306 | ONLINE | 1 | 0 | 100 | 10 | 0 | 0 | |
+--------------+-----------------------------------------------+------+--------+--------+-------------+-----------------+---------------------+---------+----------------+-------------+En el lado de la aplicación, no debería ver mucho impacto, gracias a la capacidad de ProxySQL para poner en cola las consultas durante algún tiempo.
Con esto completamos el proceso de mover su base de datos de RDS a EC2. El último paso por hacer es eliminar nuestro esclavo RDS:hizo su trabajo y se puede eliminar.
En nuestra próxima publicación de blog, nos basaremos en eso. Analizaremos un escenario en el que moveremos nuestra base de datos fuera de AWS/EC2 a un proveedor de alojamiento independiente.