Construyendo alta disponibilidad, un paso a la vez
Cuando se trata de infraestructura de bases de datos, todos la queremos. Todos nos esforzamos por crear una configuración de alta disponibilidad. La redundancia es la clave. Comenzamos a implementar la redundancia en el nivel más bajo y continuamos hacia arriba en la pila. Comienza con el hardware:fuentes de alimentación redundantes, refrigeración redundante, discos intercambiables en caliente. Capa de red:varias NIC unidas entre sí y conectadas a diferentes conmutadores que utilizan enrutadores redundantes. Para el almacenamiento usamos discos configurados en RAID, lo que da mejor rendimiento pero también redundancia. Luego, a nivel de software, usamos tecnologías de agrupación:varios nodos de bases de datos que trabajan juntos para implementar la redundancia:MySQL Cluster, Galera Cluster.
Todo esto no es bueno si tiene todo en un solo centro de datos:cuando un centro de datos se cae, o parte de los servicios (pero importantes) se desconectan, o incluso si pierde la conectividad con el centro de datos, su servicio se caerá. sin importar la cantidad de redundancia en los niveles inferiores. Y sí, esas cosas pasan.
- La interrupción del servicio S3 causó estragos en la región US-East-1 en febrero de 2017
- Interrupción del servicio EC2 y RDS en la región Este de EE. UU. en abril de 2011
- EC2, EBS y RDS se interrumpieron en la región UE-Oeste en agosto de 2011
- Un corte de energía provocó la caída de Rackspace Texas DC en junio de 2009
- La falla del UPS hizo que cientos de servidores se desconectaran en Rackspace London DC en enero de 2010
Esta no es una lista completa de fallas, es solo el resultado de una búsqueda rápida en Google. Estos sirven como ejemplos de que las cosas pueden salir mal y saldrán mal si pones todos tus huevos en la misma canasta. Un ejemplo más sería el huracán Sandy, que provocó un enorme éxodo de datos desde EE. UU. Este a EE. UU. Oeste de DC; en ese momento, difícilmente podía activar instancias en EE. UU. Oeste, ya que todos se apresuraron a trasladar su infraestructura a la otra costa a la espera. que Virginia del Norte DC se verá seriamente afectada por el clima.
Por lo tanto, las configuraciones de varios centros de datos son imprescindibles si desea crear un entorno de alta disponibilidad. En esta publicación de blog, analizaremos cómo crear dicha infraestructura utilizando Galera Cluster para MySQL/MariaDB.
Conceptos Galera
Antes de analizar soluciones particulares, dediquemos un tiempo a explicar dos conceptos que son muy importantes en las configuraciones Galera de múltiples DC de alta disponibilidad.
Quórum
La alta disponibilidad requiere recursos, es decir, necesita una cantidad de nodos en el clúster para que esté altamente disponible. Un clúster puede tolerar la pérdida de algunos de sus miembros, pero solo hasta cierto punto. Más allá de una cierta tasa de fallas, es posible que esté viendo un escenario de cerebro dividido.
Tomemos un ejemplo con una configuración de 2 nodos. Si uno de los nodos se cae, ¿cómo puede saber el otro que su par se bloqueó y no es una falla de la red? En ese caso, el otro nodo también podría estar en funcionamiento y sirviendo tráfico. No hay una buena manera de manejar tal caso... Es por eso que la tolerancia a fallas generalmente comienza desde tres nodos. Galera utiliza un cálculo de quórum para determinar si es seguro que el clúster maneje el tráfico o si debe cesar sus operaciones. Después de una falla, todos los nodos restantes intentan conectarse entre sí y determinar cuántos de ellos están activos. Luego se compara con el estado anterior del clúster y, siempre que más del 50 % de los nodos estén activos, el clúster puede seguir funcionando.
Esto da como resultado lo siguiente:
Clúster de 2 nodos:sin tolerancia a fallas
Clúster de 3 nodos:hasta 1 bloqueo
Clúster de 4 nodos:hasta 1 bloqueo (si dos nodos se bloquean, solo el 50 % del clúster estaría disponible, necesita más del 50 % de los nodos para sobrevivir)
Clúster de 5 nodos:hasta 2 bloqueos
Clúster de 6 nodos:hasta 2 bloqueos
Probablemente vea el patrón:desea que su clúster tenga un número impar de nodos; en términos de alta disponibilidad, no tiene sentido pasar de 5 a 6 nodos en el clúster. Si desea una mejor tolerancia a fallas, debe optar por 7 nodos.
Segmentos
Por lo general, en un clúster de Galera, toda la comunicación sigue el patrón de todos a todos. Cada nodo se comunica con todos los demás nodos del clúster.
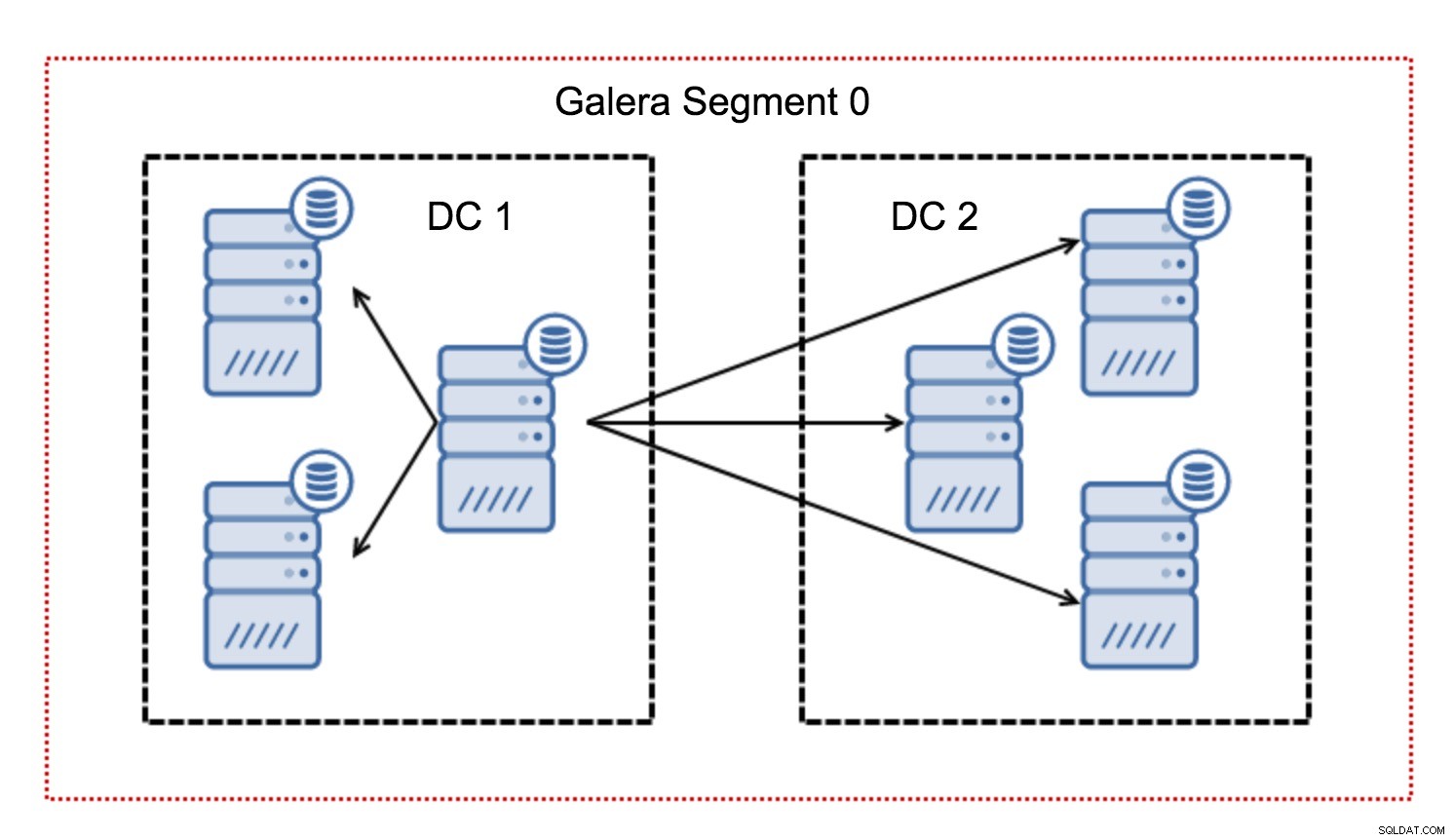
Como sabrá, cada conjunto de escritura en Galera debe estar certificado por todos los nodos del clúster; por lo tanto, cada escritura que ocurra en un nodo debe transferirse a todos los nodos del clúster. Esto funciona bien en un entorno de baja latencia. Pero si estamos hablando de configuraciones de múltiples DC, debemos considerar una latencia mucho más alta que en una red local. Para hacerlo más soportable en clústeres que se extienden sobre redes de área amplia, Galera introdujo segmentos.
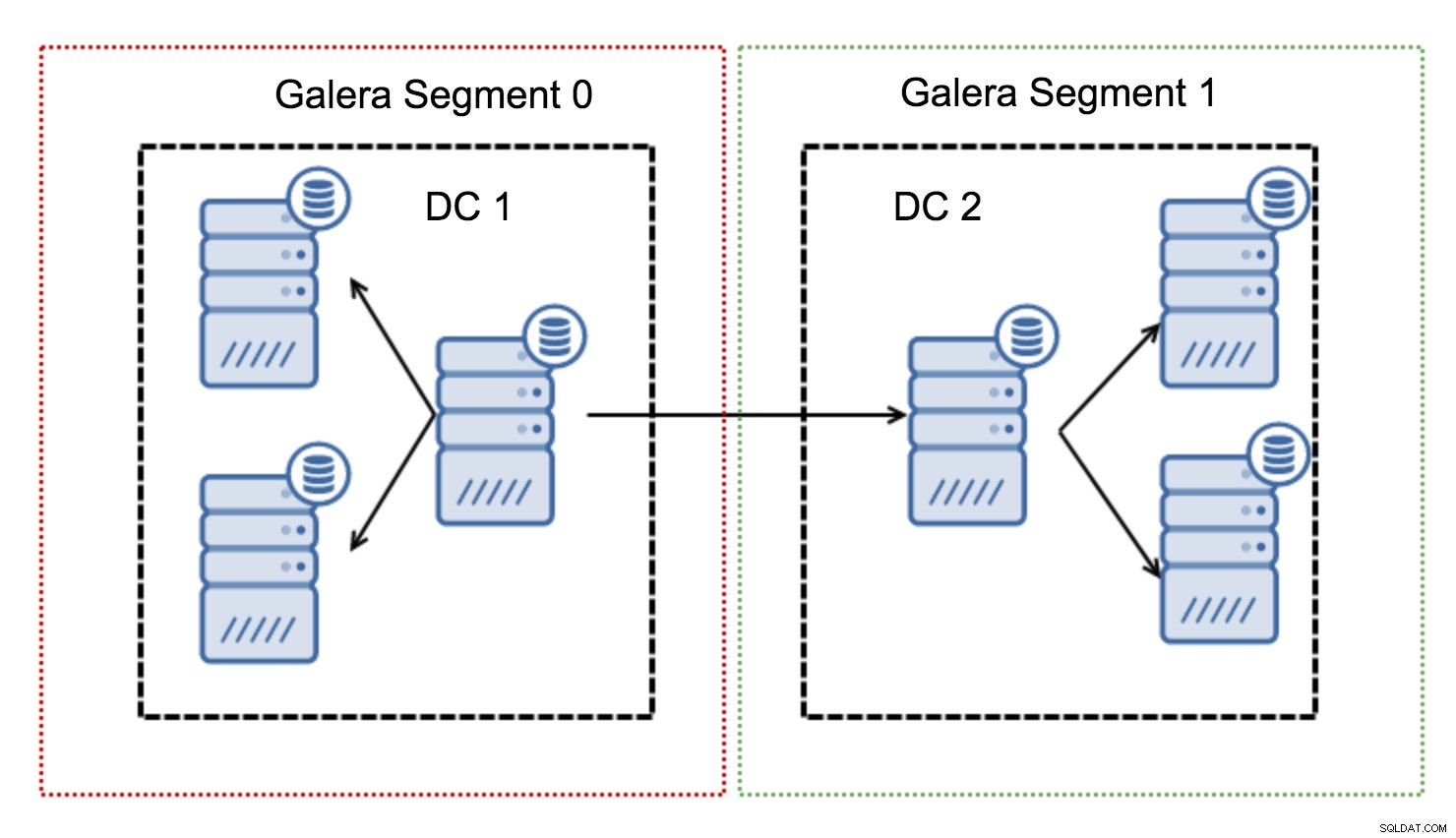
Funcionan al contener el tráfico de Galera dentro de un grupo de nodos (segmento). Todos los nodos dentro de un solo segmento actúan como si estuvieran en una red local:asumen una comunicación para todos. Para el tráfico de segmentos cruzados, las cosas son diferentes:en cada uno de los segmentos, se elige un nodo de "retransmisión", todo el tráfico de segmentos cruzados pasa por esos nodos. Cuando un nodo de retransmisión deja de funcionar, se elige otro nodo. Esto no reduce mucho la latencia; después de todo, la latencia de la WAN permanecerá igual sin importar si realiza una conexión a un host remoto o a múltiples hosts remotos, pero dado que los enlaces WAN tienden a tener un ancho de banda limitado y puede haber un cargo por la cantidad de datos transferidos, este enfoque le permite limitar la cantidad de datos intercambiados entre segmentos. Otra opción de ahorro de tiempo y costos es el hecho de que los nodos en el mismo segmento se priorizan cuando se necesita un donante; nuevamente, esto limita la cantidad de datos transferidos a través de la WAN y, muy probablemente, acelera SST como una red local casi siempre. será más rápido que un enlace WAN.
Ahora que eliminamos algunos de estos conceptos, veamos otros aspectos importantes de las configuraciones de varios centros de datos para el clúster de Galera.
Problemas que está a punto de enfrentar
Cuando se trabaja en entornos que abarcan toda la WAN, hay un par de cuestiones que debe tener en cuenta al diseñar su entorno.
Cálculo de quórum
En la sección anterior, describimos cómo se ve un cálculo de quórum en el clúster de Galera; en resumen, desea tener una cantidad impar de nodos para maximizar la capacidad de supervivencia. Todo eso sigue siendo cierto en configuraciones de múltiples DC, pero se agregan algunos elementos más a la mezcla. En primer lugar, debe decidir si desea que Galera maneje automáticamente una falla del centro de datos. Esto determinará cuántos centros de datos va a utilizar. Imaginemos dos centros de datos:si divide sus nodos en un 50 % - 50 %, si un centro de datos se cae, el segundo no tiene 50 %+1 nodos para mantener su estado "primario". Si divide sus nodos de manera desigual, utilizando la mayoría de ellos en el centro de datos "principal", cuando ese centro de datos se cae, el DC "de respaldo" no tendrá 50% + 1 nodos para formar un quórum. Puede asignar diferentes pesos a los nodos, pero el resultado será exactamente el mismo:no hay forma de realizar una conmutación por error automática entre dos DC sin intervención manual. Para implementar la conmutación por error automatizada, necesita más de dos DC. Nuevamente, idealmente un número impar:tres centros de datos es una configuración perfectamente adecuada. A continuación, la pregunta es:¿cuántos nodos necesita tener? Desea tenerlos distribuidos uniformemente en los centros de datos. El resto es solo una cuestión de cuántos nodos fallidos debe manejar su configuración.
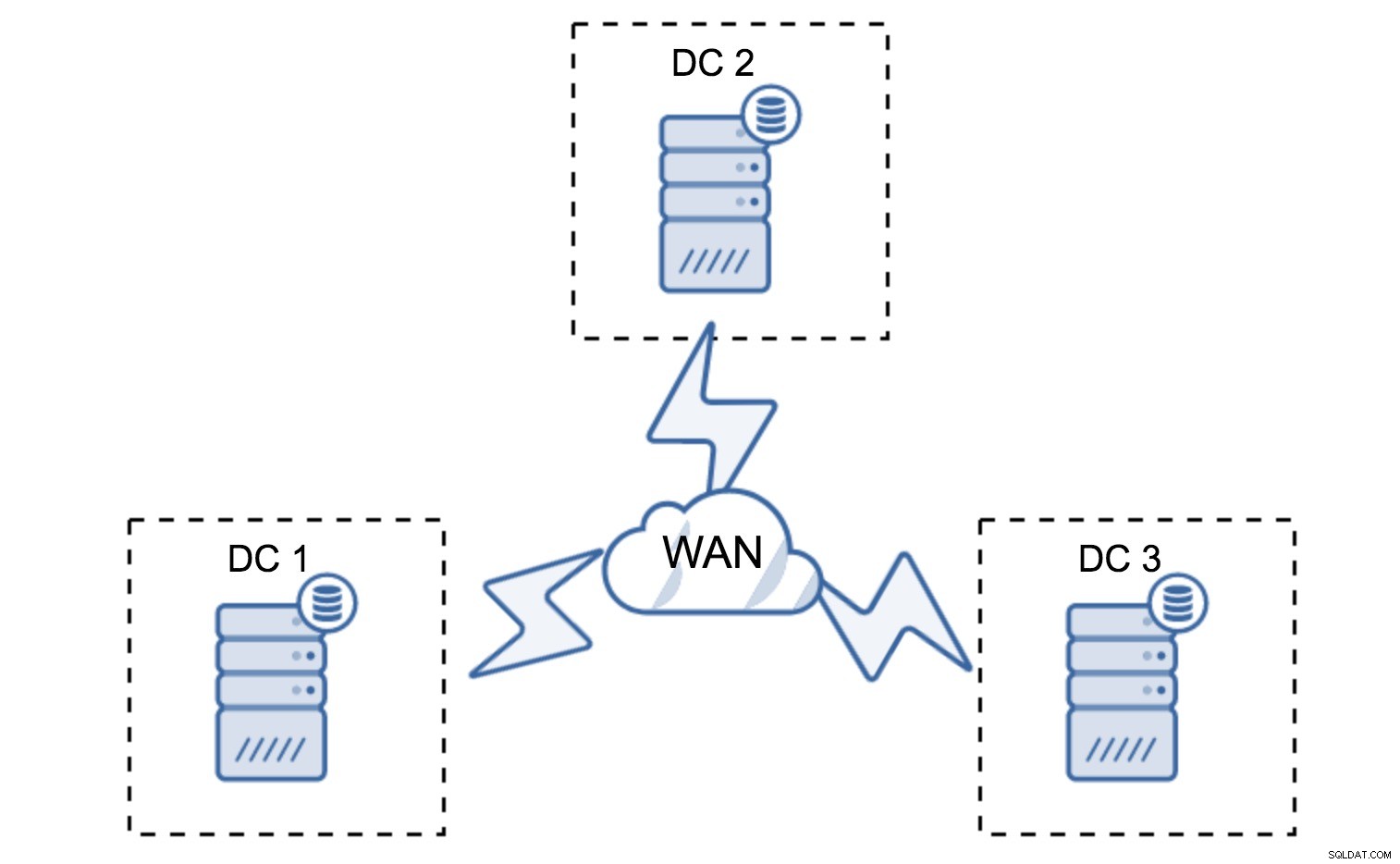
La configuración mínima utilizará un nodo por centro de datos; sin embargo, tiene serias desventajas. Cada transferencia de estado requerirá mover datos a través de la WAN y esto da como resultado que se necesite más tiempo para completar SST o costos más altos.
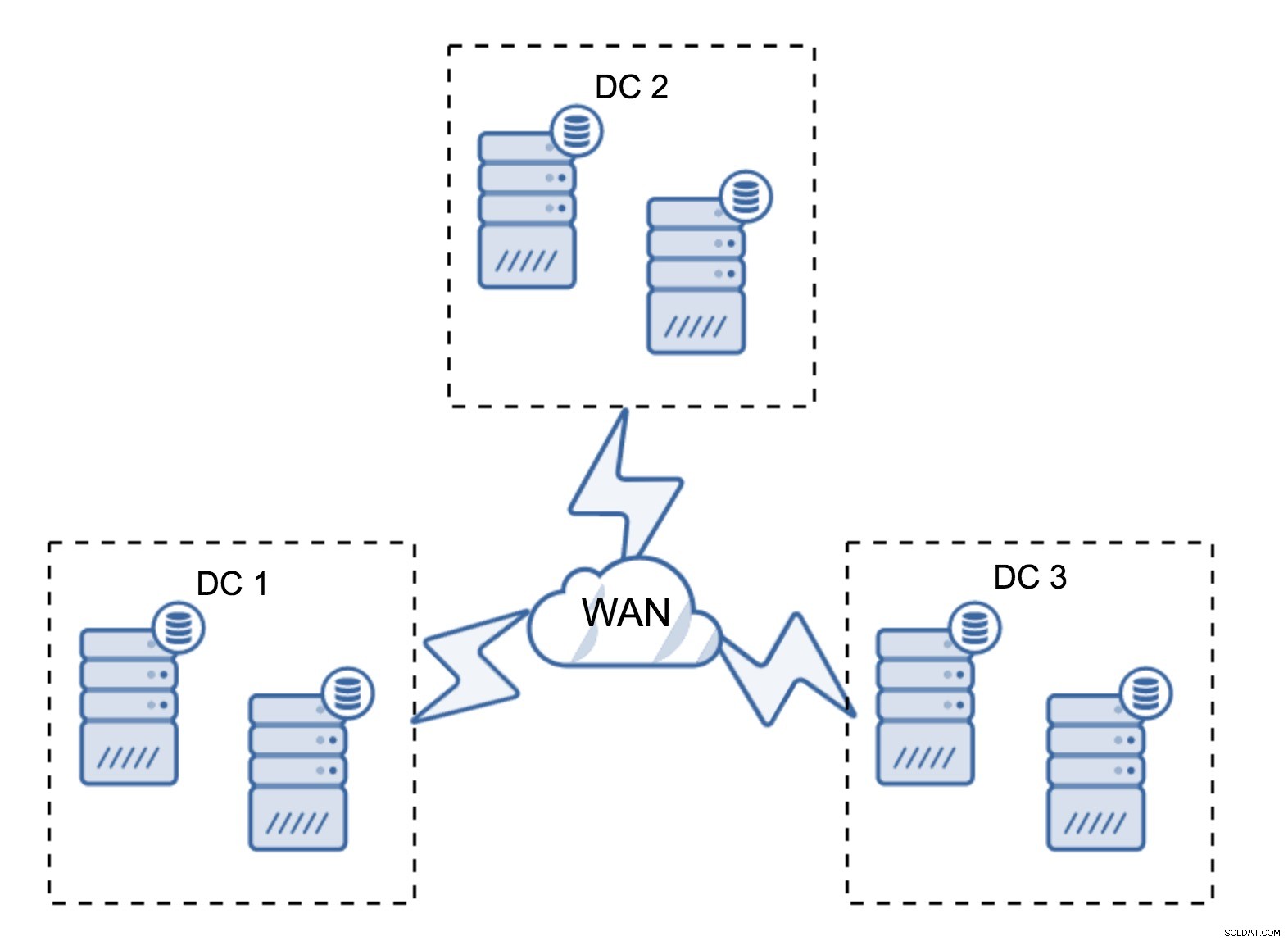
Una configuración bastante típica es tener seis nodos, dos por centro de datos. Esta configuración parece inesperada ya que tiene un número par de nodos. Pero, cuando lo piensa, puede que no sea un problema tan grande:es bastante poco probable que tres nodos se caigan a la vez, y tal configuración sobrevivirá a un bloqueo de hasta dos nodos. Un centro de datos completo puede desconectarse y los dos DC restantes continuarán operando. También tiene una gran ventaja sobre la configuración mínima:cuando un nodo se desconecta, siempre hay un segundo nodo en el centro de datos que puede servir como donante. La mayoría de las veces, la WAN no se utilizará para SST.
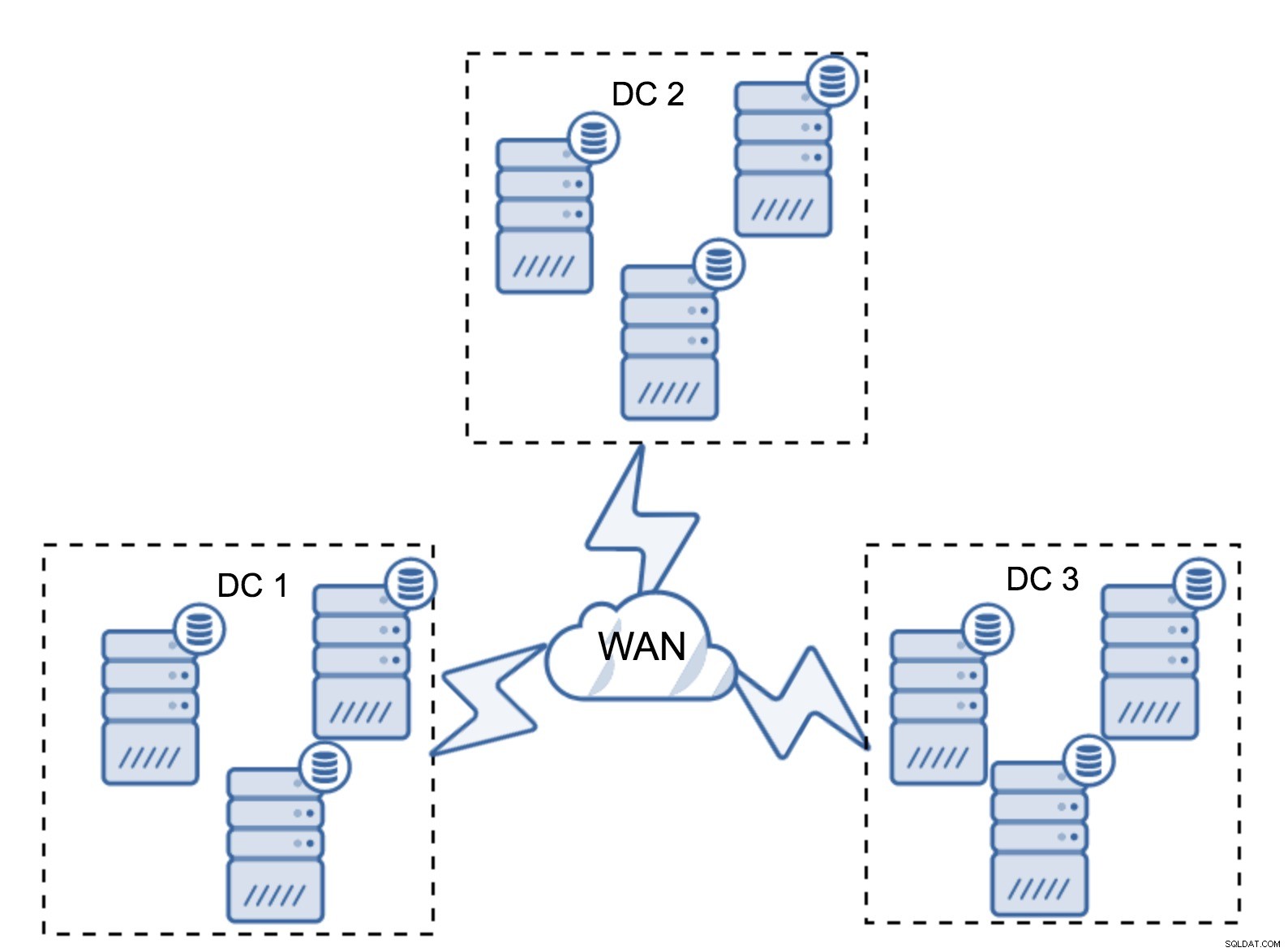
Por supuesto, puede aumentar la cantidad de nodos a tres por clúster, nueve en total. Esto le brinda una capacidad de supervivencia aún mejor:hasta cuatro nodos pueden fallar y el clúster aún sobrevivirá. Por otro lado, debe tener en cuenta que, incluso con el uso de segmentos, más nodos significan una mayor sobrecarga de operaciones y puede escalar horizontalmente el clúster de Galera solo hasta cierto punto.
Puede suceder que no sea necesario un tercer centro de datos porque, digamos, su aplicación se encuentra en solo dos de ellos. Por supuesto, el requisito de tres centros de datos sigue siendo válido, por lo que no lo eludirá, pero está perfectamente bien usar un Galera Arbitrator (garbd) en lugar de servidores de bases de datos completamente cargados.
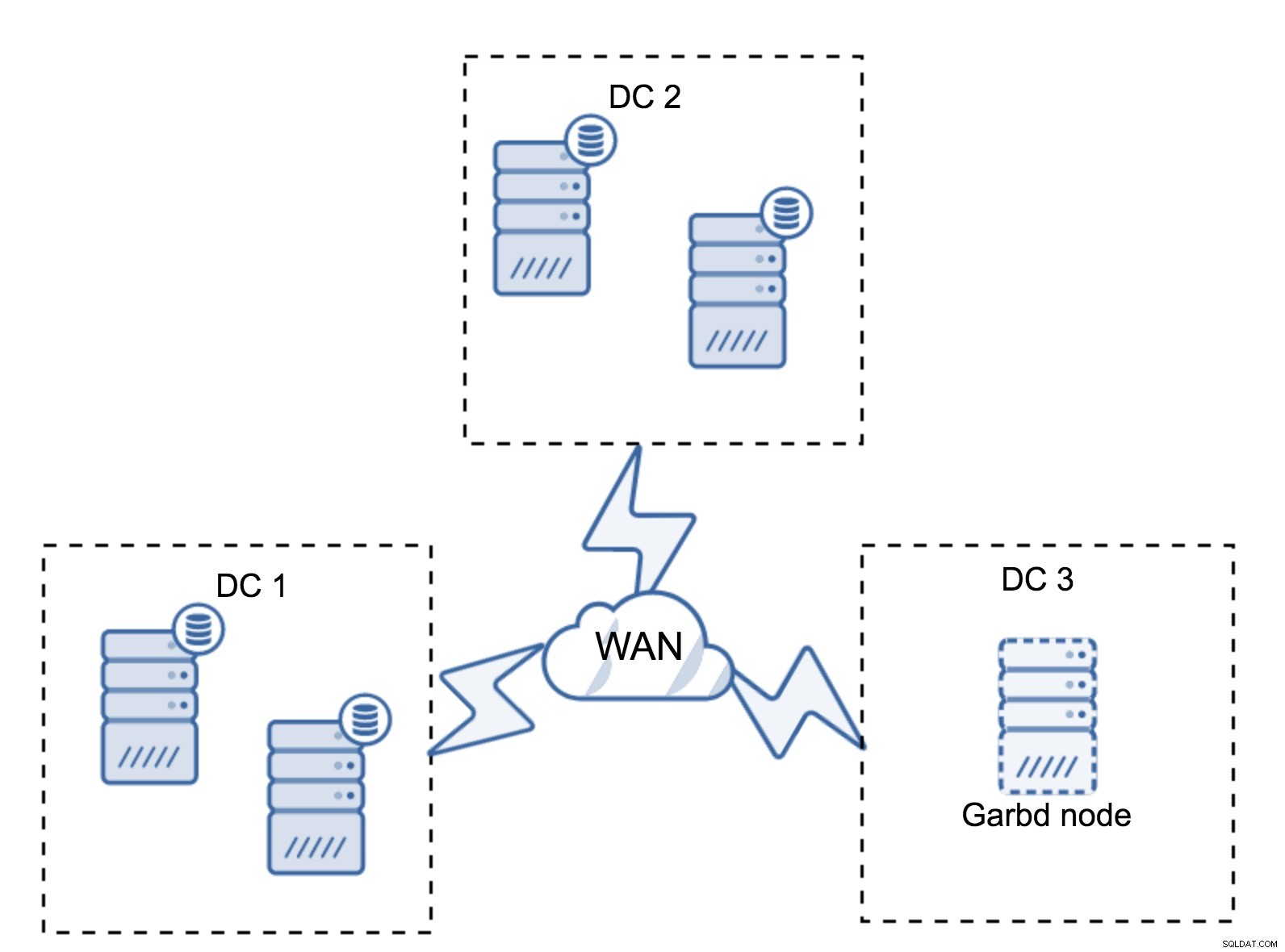
Garbd se puede instalar en nodos más pequeños, incluso en servidores virtuales. No requiere un hardware potente, no almacena ningún dato ni aplica ninguno de los conjuntos de escritura. Pero sí ve todo el tráfico de replicación y participa en el cálculo del quórum. Gracias a él, puede implementar configuraciones como cuatro nodos, dos por DC + garbd en el tercero:tiene cinco nodos en total y dicho clúster puede aceptar hasta dos fallas. Por lo tanto, significa que puede aceptar un cierre total de uno de los centros de datos.
¿Qué opción es mejor para ti? No existe la mejor solución para todos los casos, todo depende de los requisitos de su infraestructura. Afortunadamente, hay diferentes opciones para elegir:más o menos nodos, 3 DC completos o 2 DC y atuendo en el tercero; es muy probable que encuentres algo adecuado para ti.
Latencia de red
Cuando trabaje con configuraciones de múltiples DC, debe tener en cuenta que la latencia de la red será significativamente más alta de lo que esperaría de un entorno de red local. Esto puede reducir seriamente el rendimiento del clúster de Galera cuando lo compara con una instancia de MySQL independiente o una configuración de replicación de MySQL. El requisito de que todos los nodos deben certificar un conjunto de escritura significa que todos los nodos deben recibirlo, sin importar cuán lejos estén. Con la replicación asíncrona, no es necesario esperar antes de realizar una confirmación. Por supuesto, la replicación tiene otros problemas y desventajas, pero la latencia no es la principal. El problema es especialmente visible cuando su base de datos tiene puntos calientes:filas que se actualizan con frecuencia (contadores, colas, etc.). Esas filas no se pueden actualizar más de una vez por viaje de ida y vuelta de la red. Para los clústeres que se extienden por todo el mundo, esto puede significar fácilmente que no podrá actualizar una sola fila más de 2 o 3 veces por segundo. Si esto se convierte en una limitación para usted, puede significar que el clúster de Galera no es adecuado para su carga de trabajo particular.
Capa de proxy en multi-DC Galera Cluster
No es suficiente tener un clúster de Galera que abarque múltiples centros de datos, aún necesita su aplicación para acceder a ellos. Uno de los métodos populares para ocultar la complejidad de la capa de base de datos de una aplicación es utilizar un proxy. Los proxies se utilizan como punto de entrada a las bases de datos, rastrean el estado de los nodos de la base de datos y siempre deben dirigir el tráfico solo a los nodos que están disponibles. En esta sección, intentaremos proponer un diseño de capa de proxy que podría usarse para un clúster Galera de varios DC. Usaremos ProxySQL, que le brinda bastante flexibilidad en el manejo de los nodos de la base de datos, pero puede usar otro proxy, siempre que pueda rastrear el estado de los nodos de Galera.
¿Dónde ubicar los proxies?
En resumen, aquí hay dos patrones comunes:puede implementar ProxySQL en nodos separados o puede implementarlos en los hosts de la aplicación. Echemos un vistazo a los pros y los contras de cada una de estas configuraciones.
Capa de proxy como un conjunto separado de hosts
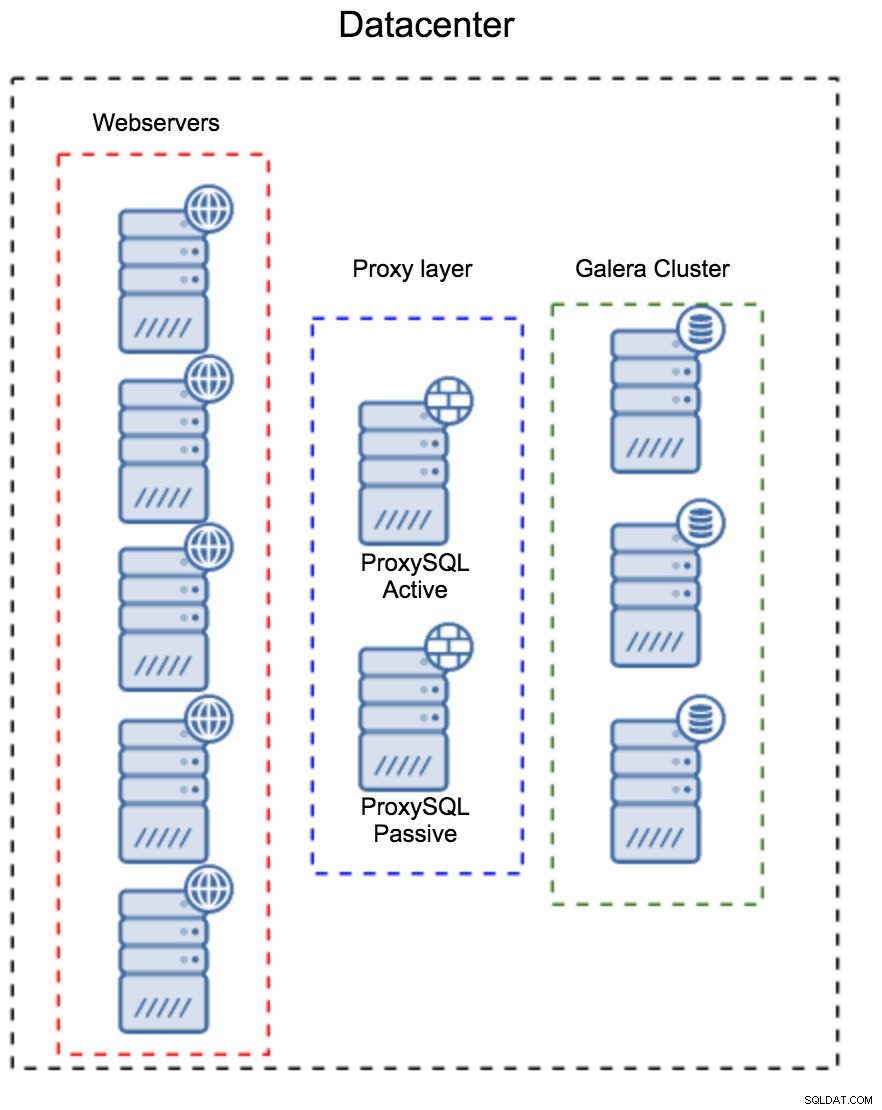
El primer patrón es construir una capa de proxy usando hosts dedicados separados. Puede implementar ProxySQL en un par de hosts y usar IP virtual y keepalive para mantener una alta disponibilidad. Una aplicación utilizará el VIP para conectarse a la base de datos y el VIP se asegurará de que las solicitudes siempre se enruten a un ProxySQL disponible. El problema principal con esta configuración es que usa como máximo una de las instancias de ProxySQL; todos los nodos en espera no se usan para enrutar el tráfico. Esto puede obligarlo a usar un hardware más potente del que normalmente usaría. Por otro lado, es más fácil mantener la configuración:tendrá que aplicar cambios de configuración en todos los nodos de ProxySQL, pero solo habrá unos pocos. También puede utilizar la opción de ClusterControl para sincronizar los nodos. Dicha configuración deberá duplicarse en cada centro de datos que utilice.
Proxy instalado en instancias de aplicación
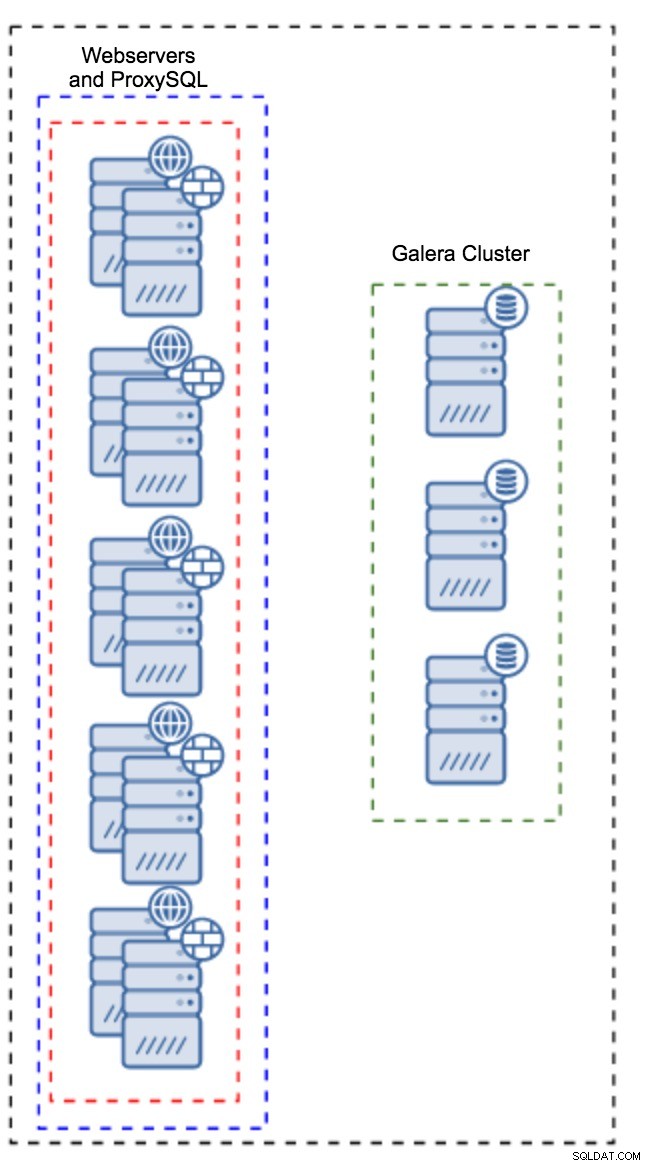
En lugar de tener un conjunto separado de hosts, ProxySQL también se puede instalar en los hosts de la aplicación. La aplicación se conectará directamente a ProxySQL en localhost, incluso podría usar un socket Unix para minimizar la sobrecarga de la conexión TCP. La principal ventaja de una configuración de este tipo es que tiene una gran cantidad de instancias de ProxySQL y la carga se distribuye uniformemente entre ellas. Si uno falla, solo ese host de aplicaciones se verá afectado. Los nodos restantes seguirán funcionando. El problema más grave al que hay que hacer frente es la gestión de la configuración. Con una gran cantidad de nodos ProxySQL, es fundamental idear un método automatizado para mantener sus configuraciones sincronizadas. Puede usar ClusterControl o una herramienta de administración de configuración como Puppet.
Ajuste de Galera en un entorno WAN
Los valores predeterminados de Galera están diseñados para la red local y si desea usarlo en un entorno WAN, se requieren algunos ajustes. Analicemos algunos de los ajustes básicos que puede realizar. Tenga en cuenta que el ajuste preciso requiere datos de producción y tráfico:no puede simplemente hacer algunos cambios y asumir que son buenos, debe realizar una evaluación comparativa adecuada.
Configuración del sistema operativo
Comencemos con la configuración del sistema operativo. No todas las modificaciones propuestas aquí están relacionadas con WAN, pero siempre es bueno recordar cuál es un buen punto de partida para cualquier instalación de MySQL.
vm.swappiness = 1Swappiness controla qué tan agresivo usará el sistema operativo el intercambio. No debe establecerse en cero porque en los núcleos más recientes, evita que el sistema operativo use el intercambio y puede causar problemas de rendimiento graves.
/sys/block/*/queue/scheduler = deadline/noopEl programador para el dispositivo de bloque, que utiliza MySQL, debe establecerse en fecha límite o noop. La elección exacta depende de los puntos de referencia, pero ambas configuraciones deberían ofrecer un rendimiento similar, mejor que el programador predeterminado, CFQ.
Para MySQL, debería considerar usar EXT4 o XFS, según el kernel (el rendimiento de esos sistemas de archivos cambia de una versión del kernel a otra). Realice algunos puntos de referencia para encontrar la mejor opción para usted.
Además de esto, es posible que desee ver la configuración de red de sysctl. No los discutiremos en detalle (puede encontrar documentación aquí), pero la idea general es aumentar los búferes, los retrasos y los tiempos de espera, para que sea más fácil adaptarse a las paradas y los enlaces WAN inestables.
net.core.optmem_max = 40960
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 87380 16777216
net.core.netdev_max_backlog = 50000
net.ipv4.tcp_max_syn_backlog = 30000
net.ipv4.tcp_congestion_control = htcp
net.ipv4.tcp_mtu_probing = 1
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_slow_start_after_idle = 0Además de ajustar el sistema operativo, debe considerar modificar la configuración relacionada con la red de Galera.
evs.suspect_timeout
evs.inactive_timeoutEs posible que desee considerar cambiar los valores predeterminados de estas variables. Ambos tiempos de espera rigen cómo el clúster expulsa los nodos fallidos. El tiempo de espera de sospecha se produce cuando todos los nodos no pueden llegar al miembro inactivo. El tiempo de espera inactivo define un límite estricto de cuánto tiempo puede permanecer un nodo en el clúster si no responde. Por lo general, encontrará que los valores predeterminados funcionan bien. Pero en algunos casos, especialmente si ejecuta su clúster de Galera a través de WAN (por ejemplo, entre regiones de AWS), el aumento de esas variables puede resultar en un rendimiento más estable. Sugerimos configurar ambos en PT1M, para que sea menos probable que la inestabilidad del enlace WAN expulse un nodo del clúster.
evs.send_window
evs.user_send_windowEstas variables, evs.send_window y evs.user_send_window , defina cuántos paquetes se pueden enviar a través de la replicación al mismo tiempo (evs.send_window ) y cuántos de ellos pueden contener datos (evs.user_send_window ). Para conexiones de alta latencia, puede valer la pena aumentar esos valores significativamente (512 o 1024, por ejemplo).
evs.inactive_check_periodLa variable anterior también se puede cambiar. evs.inactive_check_period , de forma predeterminada, está configurado en un segundo, lo que puede ser demasiado frecuente para una configuración de WAN. Sugerimos configurarlo en PT30S.
gcs.fc_factor
gcs.fc_limitAquí queremos minimizar las posibilidades de que el control de flujo se active, por lo que sugerimos configurar gcs.fc_factor a 1 y aumentar gcs.fc_limit a, por ejemplo, 260.
gcs.max_packet_sizeComo estamos trabajando con el enlace WAN, donde la latencia es significativamente mayor, queremos aumentar el tamaño de los paquetes. Un buen punto de partida sería 2097152.
Como mencionamos anteriormente, es prácticamente imposible dar una receta simple sobre cómo configurar estos parámetros, ya que depende de demasiados factores:tendrá que hacer sus propios puntos de referencia, utilizando datos lo más cerca posible de sus datos de producción, antes de puede decir que su sistema está sintonizado. Habiendo dicho eso, esas configuraciones deberían darle un punto de partida para una afinación más precisa.
Eso es todo por ahora. Galera funciona bastante bien en entornos WAN, así que pruébelo y háganos saber cómo le va.