En el último par de blogs, cubrimos cómo ejecutar un Galera Cluster en Docker, ya sea en Docker independiente o en Docker Swarm de host múltiple con red superpuesta. En esta publicación de blog, veremos cómo ejecutar Galera Cluster en Kubernetes, una herramienta de orquestación para ejecutar contenedores a escala. Algunas partes son diferentes, como la forma en que la aplicación debe conectarse al clúster, cómo Kubernetes maneja la conmutación por error y cómo funciona el equilibrio de carga en Kubernetes.
Kubernetes frente a Docker Swarm
Nuestro objetivo final es garantizar que Galera Cluster funcione de manera confiable en un entorno de contenedores. Anteriormente cubrimos Docker Swarm, y resultó que ejecutar Galera Cluster en él tiene una serie de bloqueadores que impiden que esté listo para la producción. Nuestro viaje ahora continúa con Kubernetes, una herramienta de orquestación de contenedores de nivel de producción. Veamos qué nivel de "preparación para la producción" puede admitir al ejecutar un servicio con estado como Galera Cluster.
Antes de continuar, resaltemos algunas de las diferencias clave entre Kubernetes (1.6) y Docker Swarm (17.03) al ejecutar Galera Cluster en contenedores:
- Kubernetes admite dos sondeos de verificación de estado:actividad y preparación. Esto es importante cuando se ejecuta un clúster de Galera en contenedores, porque un contenedor de Galera activo no significa que esté listo para servir y debe incluirse en el conjunto de equilibrio de carga (piense en un estado de unión/donante). Docker Swarm solo admite una prueba de verificación de estado similar a la actividad de Kubernetes, un contenedor está en buen estado y sigue funcionando o no está en buen estado y se reprograma. Lea aquí para más detalles.
- Kubernetes tiene un panel de interfaz de usuario accesible a través del "proxy kubectl".
- Docker Swarm solo admite el equilibrio de carga por turnos (ingreso), mientras que Kubernetes utiliza la conexión mínima.
- Docker Swarm admite malla de enrutamiento para publicar un servicio en la red externa, mientras que Kubernetes admite algo similar llamado NodePort, así como balanceadores de carga externos (GCE GLB/AWS ELB) y nombres de DNS externos (como para v1.7)
Instalación de Kubernetes mediante Kubeadm
Vamos a usar kubeadm para instalar un clúster de Kubernetes de 3 nodos en CentOS 7. Consta de 1 maestro y 2 nodos (secundarios). Nuestra arquitectura física se ve así:
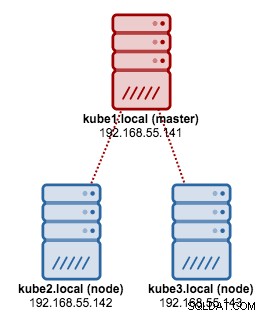
1. Instale kubelet y Docker en todos los nodos:
$ ARCH=x86_64
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-${ARCH}
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
$ setenforce 0
$ yum install -y docker kubelet kubeadm kubectl kubernetes-cni
$ systemctl enable docker && systemctl start docker
$ systemctl enable kubelet && systemctl start kubelet2. En el maestro, inicialice el maestro, copie el archivo de configuración, configure la red Pod usando Weave e instale el panel de Kubernetes:
$ kubeadm init
$ cp /etc/kubernetes/admin.conf $HOME/
$ export KUBECONFIG=$HOME/admin.conf
$ kubectl apply -f https://git.io/weave-kube-1.6
$ kubectl create -f https://git.io/kube-dashboard3. Luego, en los otros nodos restantes:
$ kubeadm join --token 091d2a.e4862a6224454fd6 192.168.55.140:64434. Verifique que los nodos estén listos:
$ kubectl get nodes
NAME STATUS AGE VERSION
kube1.local Ready 1h v1.6.3
kube2.local Ready 1h v1.6.3
kube3.local Ready 1h v1.6.3Ahora tenemos un clúster de Kubernetes para la implementación de Galera Cluster.
Clúster de Galera en Kubernetes
En este ejemplo, implementaremos MariaDB Galera Cluster 10.1 usando una imagen de Docker extraída de nuestro repositorio de DockerHub. Los archivos de definición YAML utilizados en esta implementación se pueden encontrar en el directorio example-kubernetes en el repositorio de Github.
Kubernetes admite varios controladores de implementación. Para implementar un Galera Cluster, se puede usar:
- Conjunto de réplicas
- Conjunto con estado
Cada uno de ellos tiene sus propios pros y contras. Vamos a analizar cada uno de ellos y ver cuál es la diferencia.
Requisitos
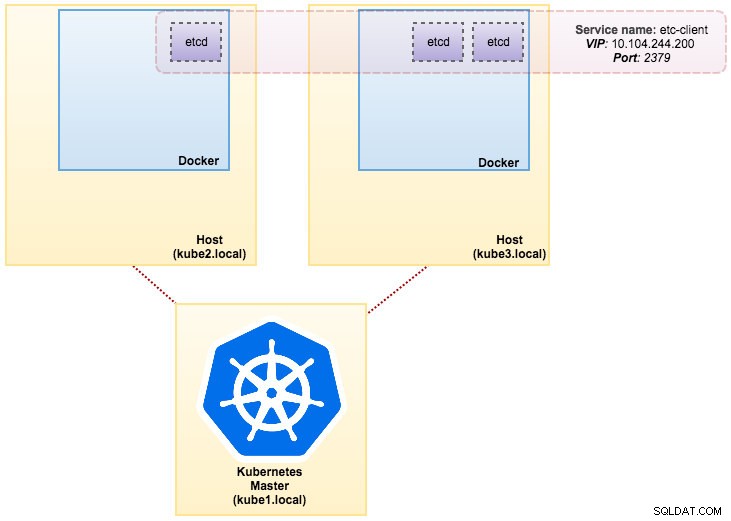
La imagen que construimos requiere un etcd (independiente o clúster) para el descubrimiento de servicios. Para ejecutar un clúster de etcd, se requiere que cada instancia de etcd se ejecute con diferentes comandos, por lo que usaremos el controlador Pods en lugar de Implementación y crearemos un servicio llamado "etcd-client" como punto final para etcd Pods. El archivo de definición etcd-cluster.yaml lo dice todo.
Para implementar un clúster etcd de 3 módulos, simplemente ejecute:
$ kubectl create -f etcd-cluster.yamlVerifique si el clúster etcd está listo:
$ kubectl get po,svc
NAME READY STATUS RESTARTS AGE
po/etcd0 1/1 Running 0 1d
po/etcd1 1/1 Running 0 1d
po/etcd2 1/1 Running 0 1d
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/etcd-client 10.104.244.200 <none> 2379/TCP 1d
svc/etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d
svc/etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d
svc/etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1dNuestra arquitectura ahora se parece a esto:
 Varios nueve MySQL en Docker:cómo contener su base de datosDescubra todo lo que necesita comprender cuando considere ejecutar un servicio MySQL en Parte superior de la virtualización de contenedores de DockerDescargue el informe técnico
Varios nueve MySQL en Docker:cómo contener su base de datosDescubra todo lo que necesita comprender cuando considere ejecutar un servicio MySQL en Parte superior de la virtualización de contenedores de DockerDescargue el informe técnico Uso de conjunto de réplicas
Un ReplicaSet garantiza que se esté ejecutando una cantidad específica de "réplicas" de pod en un momento dado. Sin embargo, una implementación es un concepto de nivel superior que administra los conjuntos de réplicas y proporciona actualizaciones declarativas a los pods junto con muchas otras características útiles. Por lo tanto, se recomienda usar Implementaciones en lugar de usar directamente ReplicaSets, a menos que requiera una orquestación de actualizaciones personalizada o no requiera actualizaciones en absoluto. Cuando usa Implementaciones, no tiene que preocuparse por administrar los ReplicaSets que crean. Las implementaciones poseen y administran sus ReplicaSets.
En nuestro caso, usaremos Deployment como controlador de carga de trabajo, como se muestra en esta definición de YAML. Podemos crear directamente Galera Cluster ReplicaSet and Service ejecutando el siguiente comando:
$ kubectl create -f mariadb-rs.ymlVerifique si el clúster está listo mirando el ReplicaSet (rs), los pods (po) y los servicios (svc):
$ kubectl get rs,po,svc
NAME DESIRED CURRENT READY AGE
rs/galera-251551564 3 3 3 5h
NAME READY STATUS RESTARTS AGE
po/etcd0 1/1 Running 0 1d
po/etcd1 1/1 Running 0 1d
po/etcd2 1/1 Running 0 1d
po/galera-251551564-8c238 1/1 Running 0 5h
po/galera-251551564-swjjl 1/1 Running 1 5h
po/galera-251551564-z4sgx 1/1 Running 1 5h
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/etcd-client 10.104.244.200 <none> 2379/TCP 1d
svc/etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d
svc/etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d
svc/etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1d
svc/galera-rs 10.107.89.109 <nodes> 3306:30000/TCP 5h
svc/kubernetes 10.96.0.1 <none> 443/TCP 1dDel resultado anterior, podemos ilustrar nuestros Pods y Servicio de la siguiente manera:
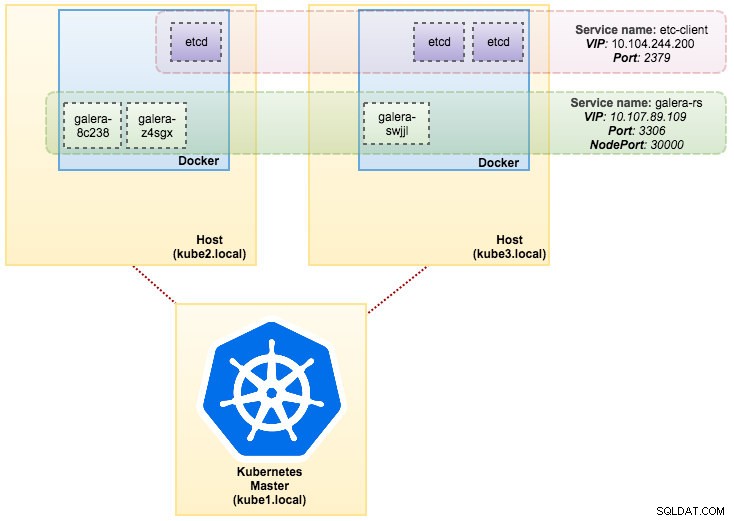
Ejecutar Galera Cluster en ReplicaSet es similar a tratarlo como una aplicación sin estado. Orquesta la creación, la eliminación y las actualizaciones de pods y puede orientarse a escalas automáticas horizontales de pods (HPA), es decir, un ReplicaSet se puede escalar automáticamente si cumple con ciertos umbrales u objetivos (uso de CPU, paquetes por segundo, solicitudes por segundo). etc.).
Si uno de los nodos de Kubernetes deja de funcionar, se programarán nuevos pods en un nodo disponible para cumplir con las réplicas deseadas. Los volúmenes asociados con el Pod se eliminarán si el Pod se elimina o se reprograma. El nombre de host del Pod se generará aleatoriamente, lo que dificultará el seguimiento de dónde pertenece el contenedor simplemente mirando el nombre de host.
Todo esto funciona bastante bien en entornos de prueba y ensayo, donde puede realizar un ciclo de vida completo del contenedor, como implementar, escalar, actualizar y destruir sin ninguna dependencia. Ampliar o reducir la escala es sencillo, actualizando el archivo YAML y publicándolo en el clúster de Kubernetes o usando el comando de escala:
$ kubectl scale replicaset galera-rs --replicas=5Uso de StatefulSet
Conocido como PetSet en la versión anterior a la 1.6, StatefulSet es la mejor manera de implementar Galera Cluster en producción porque:
- Eliminar o reducir un StatefulSet no eliminará los volúmenes asociados con el StatefulSet. Esto se hace para garantizar la seguridad de los datos, que generalmente es más valioso que una purga automática de todos los recursos de StatefulSet relacionados.
- Para un StatefulSet con N réplicas, cuando se implementan pods, se crean secuencialmente, en orden de {0 .. N-1 }.
- Cuando se eliminan pods, se terminan en orden inverso, desde {N-1 .. 0}.
- Antes de aplicar una operación de escalado a un pod, todos sus predecesores deben estar en ejecución y listos.
- Antes de que se termine un Pod, todos sus sucesores deben cerrarse por completo.
StatefulSet proporciona soporte de primera clase para contenedores con estado. Proporciona una garantía de implementación y escalado. Cuando se crea un clúster Galera de tres nodos, se implementarán tres pods en el orden db-0, db-1, db-2. db-1 no se implementará antes de que db-0 esté "En ejecución y listo", y db-2 no se implementará hasta que db-1 esté "En ejecución y listo". Si db-0 falla, después de que db-1 esté "En ejecución y listo", pero antes de que se inicie db-2, db-2 no se iniciará hasta que db-0 se reinicie correctamente y se convierta en "En ejecución y listo".
Vamos a utilizar la implementación de almacenamiento persistente de Kubernetes llamada PersistentVolume y PersistentVolumeClaim. Esto para garantizar la persistencia de los datos si el pod se reprogramara al otro nodo. Aunque Galera Cluster proporciona la copia exacta de los datos en cada réplica, tener los datos persistentes en cada pod es bueno para la resolución de problemas y la recuperación.
Para crear un almacenamiento persistente, primero debemos crear PersistentVolume para cada pod. Los PV son complementos de volumen como Volúmenes en Docker, pero tienen un ciclo de vida independiente de cualquier pod individual que use el PV. Dado que vamos a implementar un Galera Cluster de 3 nodos, necesitamos crear 3 PV:
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-0
labels:
app: galera-ss
podindex: "0"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-0/datadir
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-1
labels:
app: galera-ss
podindex: "1"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-1/datadir
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-2
labels:
app: galera-ss
podindex: "2"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-2/datadirLa definición anterior muestra que vamos a crear 3 PV, asignados a la ruta física de los nodos de Kubernetes con 10 GB de espacio de almacenamiento. Definimos ReadWriteOnce, lo que significa que el volumen se puede montar como lectura y escritura por un solo nodo. Guarde las líneas anteriores en mariadb-pv.yml y publíquelo en Kubernetes:
$ kubectl create -f mariadb-pv.yml
persistentvolume "datadir-galera-0" created
persistentvolume "datadir-galera-1" created
persistentvolume "datadir-galera-2" createdA continuación, defina los recursos de PersistentVolumeClaim:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-0
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "0"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-1
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "1"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-2
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "2"La definición anterior muestra que nos gustaría reclamar los recursos de PV y usar spec.selector.matchLabels para buscar nuestro PV (metadata.labels.app:galera-ss ) en función del índice de pod respectivo (metadata.labels.podindex ) asignado por Kubernetes. El metadatos.nombre el recurso debe usar el formato "{volumeMounts.name}-{pod}-{ordinal index}" definido en spec.templates.containers para que Kubernetes sepa qué punto de montaje mapear el reclamo en el pod.
Guarde las líneas anteriores en mariadb-pvc.yml y publíquelo en Kubernetes:
$ kubectl create -f mariadb-pvc.yml
persistentvolumeclaim "mysql-datadir-galera-ss-0" created
persistentvolumeclaim "mysql-datadir-galera-ss-1" created
persistentvolumeclaim "mysql-datadir-galera-ss-2" createdNuestro almacenamiento persistente ya está listo. A continuación, podemos iniciar la implementación de Galera Cluster creando un recurso StatefulSet junto con un recurso de servicio Headless como se muestra en mariadb-ss.yml:
$ kubectl create -f mariadb-ss.yml
service "galera-ss" created
statefulset "galera-ss" createdAhora, recupere el resumen de nuestra implementación de StatefulSet:
$ kubectl get statefulsets,po,pv,pvc -o wide
NAME DESIRED CURRENT AGE
statefulsets/galera-ss 3 3 1d galera severalnines/mariadb:10.1 app=galera-ss
NAME READY STATUS RESTARTS AGE IP NODE
po/etcd0 1/1 Running 0 7d 10.36.0.1 kube3.local
po/etcd1 1/1 Running 0 7d 10.44.0.2 kube2.local
po/etcd2 1/1 Running 0 7d 10.36.0.2 kube3.local
po/galera-ss-0 1/1 Running 0 1d 10.44.0.4 kube2.local
po/galera-ss-1 1/1 Running 1 1d 10.36.0.5 kube3.local
po/galera-ss-2 1/1 Running 0 1d 10.44.0.5 kube2.local
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
pv/datadir-galera-0 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-0 4d
pv/datadir-galera-1 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-1 4d
pv/datadir-galera-2 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-2 4d
NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS AGE
pvc/mysql-datadir-galera-ss-0 Bound datadir-galera-0 10Gi RWO 4d
pvc/mysql-datadir-galera-ss-1 Bound datadir-galera-1 10Gi RWO 4d
pvc/mysql-datadir-galera-ss-2 Bound datadir-galera-2 10Gi RWO 4dEn este punto, nuestro Galera Cluster que se ejecuta en StatefulSet se puede ilustrar como en el siguiente diagrama:
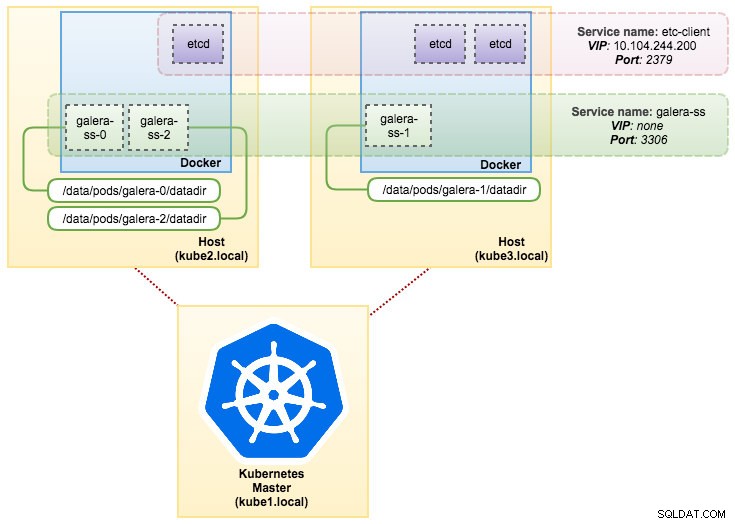
La ejecución en StatefulSet garantiza identificadores consistentes como nombre de host, dirección IP, ID de red, dominio de clúster, DNS de pod y almacenamiento. Esto permite que el Pod se distinga fácilmente de los demás en un grupo de Pods. El volumen se mantendrá en el host y no se eliminará si el pod se elimina o se reprograma en otro nodo. Esto permite la recuperación de datos y reduce el riesgo de pérdida total de datos.
En el lado negativo, el tiempo de implementación será N-1 veces (N =réplicas) más porque Kubernetes obedecerá la secuencia ordinal al implementar, reprogramar o eliminar los recursos. Sería un poco complicado preparar el PV y los reclamos antes de pensar en escalar su clúster. Tenga en cuenta que actualizar un StatefulSet existente actualmente es un proceso manual, donde solo puede actualizar spec.replicas en este momento.
Conexión al servicio de clúster y pods de Galera
Hay un par de formas de conectarse al clúster de la base de datos. Puede conectarse directamente al puerto. En el ejemplo del servicio “galera-rs”, usamos NodePort, exponiendo el servicio en la IP de cada Nodo en un puerto estático (el NodePort). Se crea automáticamente un servicio ClusterIP, al que se enrutará el servicio NodePort. Podrá ponerse en contacto con el servicio NodePort, desde fuera del clúster, solicitando {NodeIP}:{NodePort} .
Ejemplo para conectarse al Galera Cluster externamente:
(external)$ mysql -udb_user -ppassword -h192.168.55.141 -P30000
(external)$ mysql -udb_user -ppassword -h192.168.55.142 -P30000
(external)$ mysql -udb_user -ppassword -h192.168.55.143 -P30000Dentro del espacio de la red de Kubernetes, los pods pueden conectarse a través de la IP del clúster o el nombre del servicio internamente, que se puede recuperar con el siguiente comando:
$ kubectl get services -o wide
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
etcd-client 10.104.244.200 <none> 2379/TCP 1d app=etcd
etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd0
etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd1
etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd2
galera-rs 10.107.89.109 <nodes> 3306:30000/TCP 4h app=galera-rs
galera-ss None <none> 3306/TCP 3m app=galera-ss
kubernetes 10.96.0.1 <none> 443/TCP 1d <none>En la lista de servicios, podemos ver que Galera Cluster ReplicaSet Cluster-IP es 10.107.89.109. Internamente, otro pod puede acceder a la base de datos a través de esta dirección IP o nombre de servicio usando el puerto expuesto, 3306:
(etcd0 pod)$ mysql -udb_user -ppassword -hgalera-rs -P3306 -e 'select @@hostname'
+------------------------+
| @@hostname |
+------------------------+
| galera-251551564-z4sgx |
+------------------------+También puede conectarse al NodePort externo desde el interior de cualquier módulo en el puerto 30000:
(etcd0 pod)$ mysql -udb_user -ppassword -h192.168.55.143 -P30000 -e 'select @@hostname'
+------------------------+
| @@hostname |
+------------------------+
| galera-251551564-z4sgx |
+------------------------+La conexión a los pods de backend se equilibrará según corresponda según el algoritmo de conexión mínima.
Resumen
En este punto, ejecutar Galera Cluster en Kubernetes en producción parece mucho más prometedor en comparación con Docker Swarm. Como se discutió en la última publicación del blog, las inquietudes planteadas se abordan de manera diferente con la forma en que Kubernetes organiza los contenedores en StatefulSet (aunque todavía es una función beta en v1.6). Esperamos que el enfoque sugerido ayude a ejecutar Galera Cluster en contenedores a escala en producción.



