La dirección IP virtual es una dirección IP que no corresponde a una interfaz de red física real. Flota entre múltiples interfaces de red y solo una interfaz activa mantendrá la dirección IP para tolerancia a fallas y movilidad. ClusterControl utiliza Keepalived para proporcionar integración de direcciones IP virtuales con balanceadores de carga de bases de datos para eliminar cualquier punto único de falla (SPOF) en el nivel del balanceador de carga.
En esta publicación de blog, le mostraremos cómo ClusterControl configura la dirección IP virtual y qué puede esperar cuando se produce una conmutación por error o una conmutación por recuperación. Comprender este comportamiento es vital para minimizar cualquier interrupción del servicio y suavizar las operaciones de mantenimiento que deben realizarse ocasionalmente.
Requisitos
Hay algunos requisitos para ejecutar Keepalived en su red:
- El protocolo IP 112 (Protocolo de redundancia de enrutador virtual - VRRP) debe ser compatible con la red. Algunas redes deshabilitan la compatibilidad con VRRP, especialmente las comunicaciones entre VLAN. Verifique esto con el administrador de la red.
- Si usa multidifusión, la red debe admitir la solicitud de multidifusión (use ip a | grep -i multicast). De lo contrario, puede usar unidifusión a través de unicast_src_ip y unicast_peer opciones El uso de multidifusión es útil cuando tiene un entorno dinámico como un entorno de nube o cuando la asignación de IP se realiza a través de DHCP.
- Un conjunto de instancias de VRRP debe usar un virtual_router_id único valor, que no se puede compartir entre otras instancias. De lo contrario, verá paquetes falsos y es probable que rompa el cambio maestro-respaldo.
- Si está ejecutando en un entorno de nube como AWS, probablemente necesite usar un script externo (sugerencia:use la opción "notificar") para disociar y asociar la dirección IP virtual (IP elástica) para que sea reconocida y enrutable por el enrutador.
Implementación de Keepalive
Para instalar Keepalived a través de ClusterControl, necesita dos o más balanceadores de carga instalados o importados en ClusterControl. Para el uso de producción, recomendamos encarecidamente que el software del balanceador de carga se ejecute en un host independiente y que no se ubique junto con los nodos de la base de datos.
Después de tener al menos dos balanceadores de carga administrados por ClusterControl, para instalar Keepalived y habilitar la dirección IP virtual, simplemente vaya a ClusterControl -> seleccione el clúster -> Administrar -> Equilibrador de carga -> Keepalived:
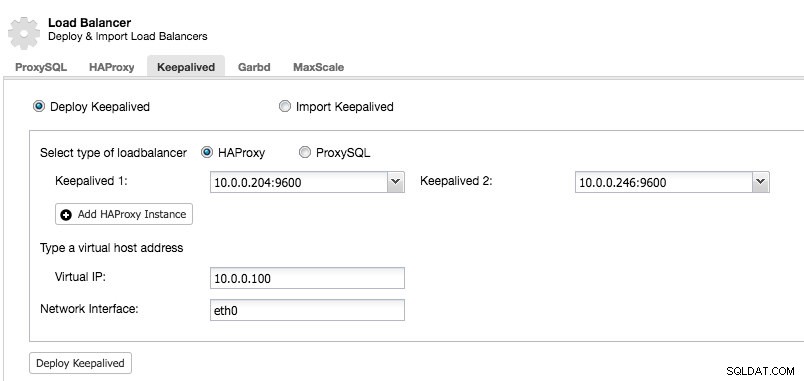
La mayoría de los campos se explican por sí mismos. Puede implementar un nuevo conjunto de Keepalived o importar instancias de Keepalived existentes. Los campos importantes incluyen la dirección IP virtual real y la interfaz de red donde existirá la dirección IP virtual. Si los hosts usan dos nombres de interfaz diferentes, especifique el nombre de interfaz del host Keepalived 1 y luego modifique manualmente el archivo de configuración en Keepalived 2 con un nombre de interfaz correcto más adelante.
Instancia VRRP
Al momento de escribir este artículo, ClusterControl v1.5.1 instala Keepalived v1.3.5 (según el sistema operativo del host) y lo siguiente es lo que está configurado para la instancia de VRRP:
vrrp_instance VI_PROXYSQL {
interface eth0 # interface to monitor
state MASTER
virtual_router_id 51 # Assign one ID for this route
priority 100
unicast_src_ip 10.0.0.246
unicast_peer {
10.0.0.204
}
virtual_ipaddress {
10.0.0.100 # the virtual IP
}
track_script {
chk_proxysql
}
# notify /usr/local/bin/notify_keepalived.sh
}ClusterControl configura la instancia de VRRP para comunicarse a través de unidifusión. Con unicast, debemos definir todos los pares de unicast de los otros nodos Keepalived. Es menos dinámico pero funciona la mayor parte del tiempo. Con la multidifusión, puede eliminar esas líneas (unicast_*) y confiar en la dirección IP de multidifusión para el emparejamiento y la detección de host. Es más simple, pero los administradores de red suelen bloquearlo.
La siguiente parte es la dirección IP virtual. Puede especificar varias direcciones IP virtuales por instancia de VRRP, separadas por una nueva línea. El equilibrio de carga en HAProxy/ProxySQL y Keepalived al mismo tiempo también requiere la capacidad de vincularse a una dirección IP que no es local, lo que significa que no está asignada a un dispositivo en el sistema local. Esto permite que una instancia del balanceador de carga en ejecución se vincule a una IP que no es local para la conmutación por error. Por lo tanto, ClusterControl también configura net.ipv4.ip_nonlocal_bind=1 dentro de /etc/sysctl.conf.
La siguiente directiva es track_script , donde puede especificar el script para el proceso de verificación de estado que se explica en la siguiente sección.
Comprobaciones de salud
ClusterControl configura Keepalived para realizar comprobaciones de estado examinando el código de error devuelto por track_script. En el archivo de configuración de Keepalived, que por defecto se encuentra en /etc/keepalived/keepalived.conf, debería ver algo como esto:
track_script {
chk_proxysql
}Donde llama a chk_proxysql que contiene:
vrrp_script chk_proxysql {
script "killall -0 proxysql" # verify the pid existence
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}El comando "killall -0" devuelve el código de salida 0 si hay un proceso llamado "proxysql" ejecutándose en el host. De lo contrario, la instancia tendría que degradarse y comenzar a iniciar la conmutación por error como se explica en la siguiente sección. Tenga en cuenta que Keepalived también admite componentes de Linux Virtual Server (LVS) para realizar comprobaciones de estado, donde también es capaz de equilibrar la carga de conexiones TCP/IP, similar a HAProxy, pero eso está fuera del alcance de esta publicación de blog.
Simulación de conmutación por error
Para los componentes de VRRP, Keepalived utiliza el protocolo VRRP (protocolo IP 112) para comunicarse entre las instancias de VRRP. El valor de prioridad más alto de un MAESTRO significa que el maestro siempre tendrá el privilegio más alto para mantener la dirección IP virtual, a menos que configure la instancia con "no preferencia". Usemos un ejemplo para explicar mejor el flujo de conmutación por error y conmutación por recuperación. Considere el siguiente diagrama:
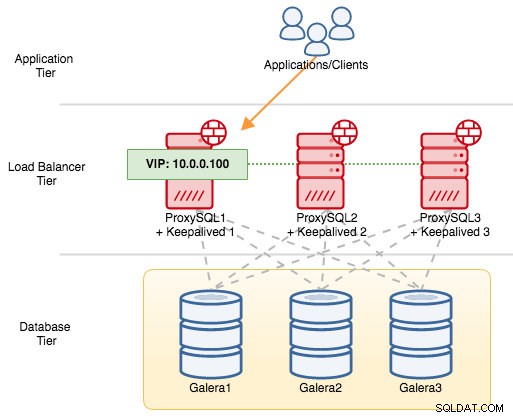
Hay tres instancias de ProxySQL frente a tres nodos MySQL Galera. Cada host ProxySQL está configurado con Keepalived como MAESTRO con el siguiente número de prioridad:
- ProxySQL1 - prioridad 101
- ProxySQL2:prioridad 100
- ProxySQL3 - prioridad 99
Cuando Keepalived se inicia como MAESTRO, primero anunciará el número de prioridad a los miembros y luego se asociará con la dirección IP virtual. A diferencia de la instancia BACKUP, solo observará el anuncio y solo asignará la dirección IP virtual una vez que haya confirmado que puede elevarse a MASTER.
Tenga en cuenta que si elimina el proceso "proxysql" o "haproxy" manualmente mediante el comando de eliminación, el administrador de procesos de systemd intentará recuperar de forma predeterminada el proceso que se detuvo sin gracia. Además, si tiene activada la recuperación automática de ClusterControl, ClusterControl siempre intentará iniciar el proceso incluso si realiza un apagado limpio a través de systemd (systemctl stop proxysql). Para simular mejor la falla, le sugerimos al usuario que desactive la función de recuperación automática de ClusterControl o simplemente apague el servidor ProxySQL para interrumpir la comunicación.
Si apagamos ProxySQL1, la dirección IP virtual se conmutará por error al próximo host que tenga mayor prioridad en ese momento en particular (que es ProxySQL2):
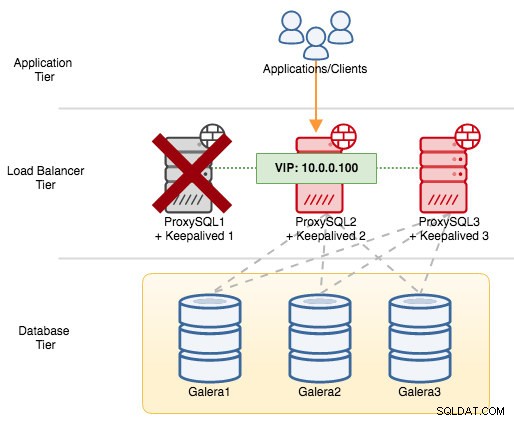
Vería lo siguiente en el syslog del nodo fallido:
Feb 27 05:21:59 proxysql1 systemd: Unit proxysql.service entered failed state.
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: /usr/bin/killall -0 proxysql exited with status 1
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: VRRP_Script(chk_proxysql) failed
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Changing effective priority from 103 to 101
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Received advert with higher priority 102, ours 101
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Entering BACKUP STATE
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) removing protocol VIPs.Mientras estaba en el nodo secundario, sucedió lo siguiente:
Feb 27 05:22:00 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) forcing a new MASTER election
Feb 27 05:22:01 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Transition to MASTER STATE
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Entering MASTER STATE
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) setting protocol VIPs.
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Sending/queueing gratuitous ARPs on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 avahi-daemon[346]: Registering new address record for 10.0.0.100 on eth0.IPv4.En este caso, la conmutación por error tomó alrededor de 3 segundos, con un tiempo máximo de conmutación por error de intervalo + advert_int . Detrás de escena, el punto final de la base de datos ha cambiado y el tráfico de la base de datos se enruta a través de ProxySQL2 sin que las aplicaciones lo noten.
Cuando ProxySQL1 vuelva a estar en línea, forzará una nueva elección MAESTRA y tomará el control de la dirección IP debido a una mayor prioridad:
Feb 27 05:38:34 proxysql1 Keepalived_vrrp[12589]: VRRP_Script(chk_proxysql) succeeded
Feb 27 05:38:35 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Changing effective priority from 101 to 103
Feb 27 05:38:36 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) forcing a new MASTER election
Feb 27 05:38:37 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Transition to MASTER STATE
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Entering MASTER STATE
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) setting protocol VIPs.
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Sending/queueing gratuitous ARPs on eth0 for 10.0.0.100
Feb 27 05:38:38 proxysql1 avahi-daemon[343]: Registering new address record for 10.0.0.100 on eth0.IPv4.Al mismo tiempo, ProxySQL2 se degrada a sí mismo al estado BACKUP y elimina la dirección IP virtual de la interfaz de red:
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Received advert with higher priority 103, ours 102
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Entering BACKUP STATE
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) removing protocol VIPs.
Feb 27 05:38:36 proxysql2 avahi-daemon[346]: Withdrawing address record for 10.0.0.100 on eth0.En este punto, ProxySQL1 vuelve a estar en línea y se convierte en el equilibrador de carga activo que atiende las conexiones de aplicaciones y clientes. VRRP normalmente se adelantará a un servidor de menor prioridad cuando un servidor de mayor prioridad se conecte. Si desea que la dirección IP permanezca en ProxySQL2 después de que ProxySQL1 vuelva a estar en línea, use la opción "nopreempt". Esto permite que la máquina de menor prioridad mantenga el rol maestro, incluso cuando una máquina de mayor prioridad vuelve a estar en línea. Sin embargo, para que esto funcione, el estado inicial de esta entrada debe ser RESPALDO. De lo contrario, notará la siguiente línea:
Feb 27 05:50:33 proxysql2 Keepalived_vrrp[6298]: (VI_PROXYSQL): Warning - nopreempt will not work with initial state MASTERDado que, de forma predeterminada, ClusterControl configura todos los nodos como MASTER, debe configurar la siguiente opción de configuración para la respectiva instancia de VRRP en consecuencia:
vrrp_instance VI_PROXYSQL {
...
state BACKUP
nopreempt
...
}Reinicie el proceso Keepalived para cargar estos cambios. La dirección IP virtual solo se conmutará por error a ProxySQL1 o ProxySQL3 (según la prioridad y qué nodo esté disponible en ese momento) si la verificación de estado falla en ProxySQL2. En muchos casos, bastará con ejecutar Keepalived en dos hosts.